Neighborhood-Based Collaborative Filtering
Neighborhood-Based Collaborative Filtering
Introduction
Neighborhood-based collaborative filtering algorithms There are two primary types of neighborhood-based
algorithms:
-
User-based collaborative filtering:
- 유저 A와 유사한 유저가 제공한 등급을 가지고 추천리스트를 만드는데 사용됨.
- A의 예상 등급은 각 '피어 그룹' 등급의 가중 평균값으로 계산
유저 사이의 유사성(rows of ratings matrix)으로 정의됨.
-
Item-based collaborative filtering:
- Target Item B의 추천을 만들기 위해 첫 스텝은 아이템B와 가장 유사한 아이템의 집합 S를 결정하는 것
- 유저 A의 등급을 예측하기 위해 Item B에서 A가 평가한 집합S의 등급을 가지고 결정
- 등급의 가중 평균은 Item B에 대한 User A의 예상 등급을 계산하는데 사용
아이템 간의 유사성으로 정의된다.(columns of ratings matrix)
차이점을 정리하면, 전자의 경우는 이웃 사용자의 등급을 사용하여 예측되며, 후자의 등급은 밀접하게 관련된 아이템에 대한 그 유저에 대한 등급 사용하여 예측함. 두 메소드는 상호보완적 관계이다.
- User X Item 평가는 매트릭스가 m 개의 User 및 n 개의 Item을 포함하는 불완전한 m × n 매트릭스 R 이라고 가정
- 유저-아이템 조합의 값의 등급으로 예측하기:
- 추천시스템의 가장 심플하고 기본적 공식
- Item j에 대한 User u의 누락된 점수인 r를 예측하기
- Top-k items 또는 Top-k 유저를 결정하는 것:
- 많은 현실적 설정에서, 판매자는 유저-아이템의 조합의 특정 등급 값을 반드시 찾을 필요는 없음.
- 오히려 특정 사용자에 대해 가장 관련성이 높은 상위 k개 항목을 학습하거나 특정 항목에 대해 가장 관련성이 높은 상위 k 사용자를 학습하는 것이 더 낫다.
- top-k item을 결정하는 문제는 top-k 유저를 찾는 것보다 더 평범하다. 왜냐하면 이전 공식은 웹 센트릭 시나리오에서 유저에게 추천되어지는 리스트를 제공하는데 익숙하다.
- traditional recommender alogorithm에서 'top-k problem'는 거의 항상 'top-k user'가 아니라 top-k 아이템을 찾은 프로세스를 나타낸다. 그러나 이후 방식은 판매자에게도 유용하다. 왜냐하면 마케팅에서 최상의 유저를 타겟하는 결정에 사용되어진다.
- 두 문제는 가까운 관계다. 예를 들어, 특정 uesr에 대한 top-k item을 결정하기위해, 해당 사용자에 대한 각각 item의 등급을 예측할 수 있다.
예측된 등급 기반으로 top-k 아이템은 선택되어질 수 있다.
효율성을 향상시키기 위해 이웃 기반 방법은 오프라인 단계에서 예측에 필요한 일부 데이터를 미리 계산한다.
미리 계산된 데이터는 좀 더 효과적인 방법으로 랭킹을 매기기 위해 사용되어질 것이다.
Key Properties of Ratings Matrices
일반적으로 등급 매트릭스의 Item 중 일부 만이 지정됨. 행렬의 지정된 Item을 Train 데이터라고 하며, 행렬의 지정되지 않은 Item을 Test 데이터
-
Continous ratings(연속형 등급):
- 평가는 손에 있는 항목에 대한 좋아요 또는 싫어요 수준에 해당하는 연속 척도로 지정됩니다. 한 예로 Jester joke 추천 엔진인데, 등급은 -10에서 10 사이의 값을 가질 수 있다.
- 연속 등급 접근법의 단점은 User에게 부담을 주는 것.
-
Interval-based ratings(간격기반 등급):
- 간격기준 등급에서 등급은 종종 10 점 및 20 점 척도도 가능하지만 5 점 또는 7 점 척도를 주로 사용
예) 이러한 등급의 예는 1에서 5, -2에서 2 또는 1에서 7 사이의 정수를 들 수 있음. - 중요한 가정은 숫자 값이 등급 사이의 거리를 명시적으로 정의하고 등급 값은 일반적으로 등거리라는 것입니다.
- 간격기준 등급에서 등급은 종종 10 점 및 20 점 척도도 가능하지만 5 점 또는 7 점 척도를 주로 사용
-
Ordinal ratings(순서 등급):
- 정렬된 범주 값을 사용할 수 있다는 점을 제외하고는 간격 기반 등급과 매우 유사하다. 이러한 정렬된 범주 값의 예로는 '매우 동의하지 않음',,'보통',,'매우 싫음'과 같은 응답이 있다.
- 일반적으로 긍정 및 부정 응답 수는 편향을 피하기 위해 균등하게 균형을 이룬다.
-
Binary ratings(이진 등급):
- 이진 평가의 경우 긍정 또는 부정 응답에 해당하는 두 가지 옵션만 제공됨.
- User가 중립인 경우 종종 평점을 지정하지 않음
-
Unary ratings(단항 등급):
- 사용자는 아이템에 대해 긍정적인 선호도를 지정할 수 있지만 부정적인 선호도를 지정하는 메커니즘은 없다.
- 예로 Facebook에서 "좋아요" 버튼을 사용하는 것과 같은 환경, 반면에 고객이 좋아요가 아니라고 해서 반드시 아이템에 대한 싫어함을 나타내는 것은 아님.
고객이 솔직하게 피드백을 제공하지 않기 때문에 고객행동에서 단항 등급을 간접적으로 유도하는 것을 암시적 피드백이라고도 한다. 오히려 피드백은 고객의 행동을 통해 암시적으로 추론된다. 이러한 유형의 '등급'은 사용자가 명시적으로 등급을 매기는 것보다 온라인 사이트에서 아이템과 상호 작용할 가능성이 훨씬 더 높기 때문에 쉽게 얻을 수 있다.
암시적 피드백(즉, 단항 등급)의 설정은 분류 및 회귀 모델링에서 PU(positive-unlabeled) 학습 문제의 행렬 완성 유사체로 간주될 수 있기 때문에 본질적으로 다릅니다.
아이템 간의 등급 분포는 종종 롱테일 속성이라고 하는 현실세계 설정의 속성을 충족합니다. 이 속성에 따르면 아이템의 작은 부분만 자주 평가된다. 이러한 상품을 인기 상품이라고 한다. 대부분의 항목은 드물게 평가된다. 그 결과 기본 등급이 크게 왜곡된다.
< The Long tail of rating frequencies >
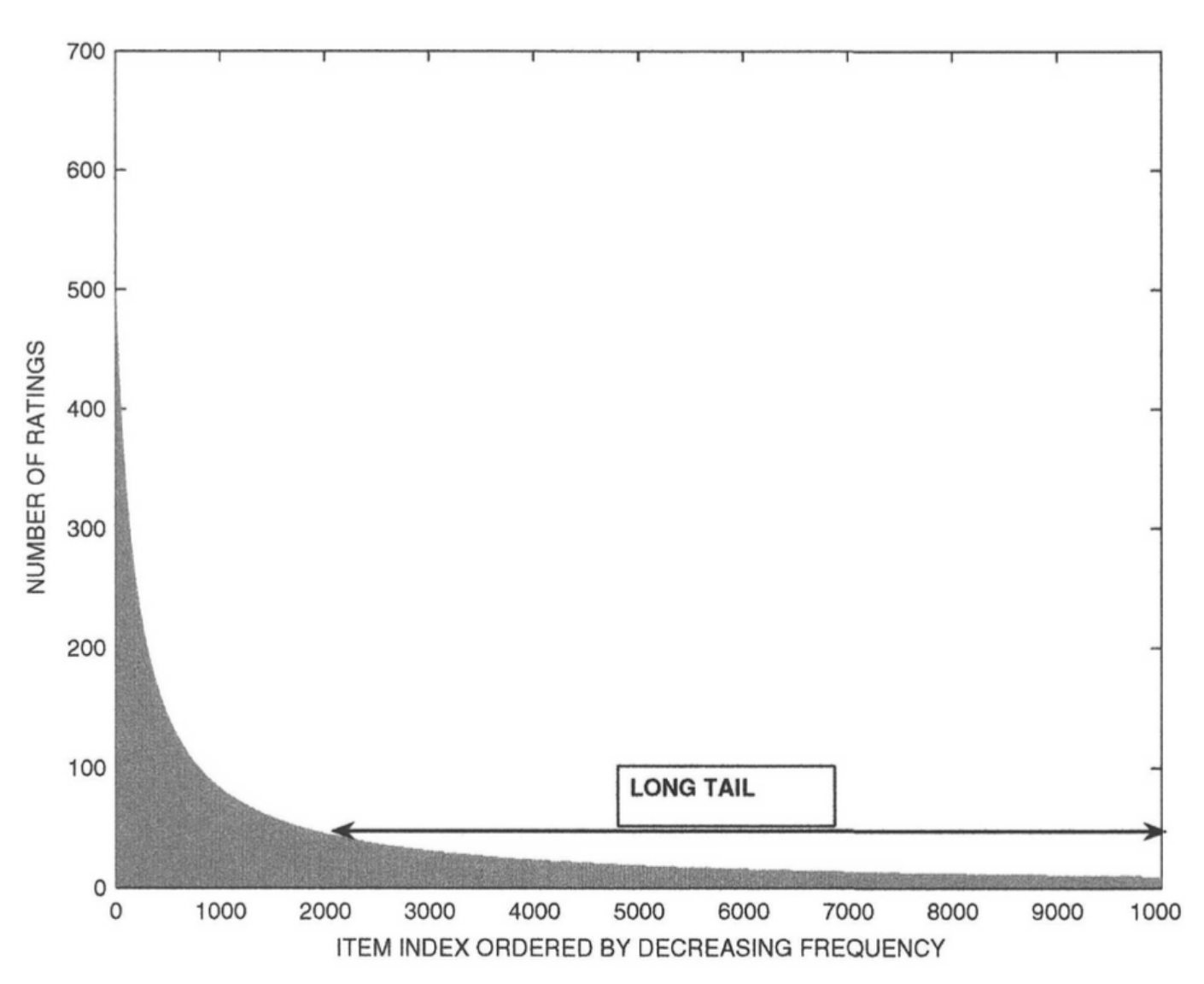
X축은 빈도가 낮은 순서대로 항목의 지수를 나타내고, Y축은 항목이 평가된 빈도를 나타냅니다. 대부분의 항목이 적은 횟수로 평가되는 것이 분명하다. 이러한 등급 분포는 추천 프로세스에서 중요한 의미를 갖는다.
- 많은 경우에 빈도가 높은 품목은 상인에게 이익이 거의 없는 비교적 경쟁력 있는 품목인 경향이 있음.
- 반면에 빈도가 낮은 항목은 더 큰 이익 마진, 이러한 경우에는 판매자에게 빈도가 낮은 상품을 추천하는 것이 유리할 수 있음. 실제로 분석에 따르면 Amazon.com과 같은 많은 회사는 롱테일에서 품목을 판매하여 대부분의 이익을 얻음
- 롱테일에서 관찰된 등급이 드물기 때문에 일반적으로 롱테일에서 강력한 등급 예측을 제공하기가 더 어렵움.
- 실제로 많은 추천 알고리즘은 흔하지 않은 아이템보다 인기 있는 아이템을 추천하는 경향이 있는데 이러한 현상은 또한 다양성에 부정적인 영향을 미치며, 사용자는 인기 상품에 대해 동일한 세트의 추천을 받는 데 종종 지루해할 수 있습니다.
- 긴 꼬리 분포는 사용자가 자주 평가하는 항목의 수가 적다는 것을 의미
희소성 및 롱테일과 같은 등급의 중요한 특성은 추천 과정에서 고려해야 합니다. 이러한 현실 세계의 속성을 고려하여 추천 알고리즘을 조정함으로써 보다 의미 있는 예측을 얻을 수 있습니다.
Predicting Ratings with Neighborhood-Based Methods
Neighborhood Based Method의 기본 아이디어는 평점 행렬로부터 유저 간 유사성을 사용하거나 아이템간 유사성을 사용하는 것입니다. 이 떄 이웃(neighborhood) 이라는 단어는 유저 또는 아이템의 유사성을 결정할 필요가 있다는 말을 암시합니다. 지금부터는 Neighborhood Based Method를 이용해 유저-아이템 조합에서 평점예측을 어떻게 하는지 알아보겠습니다. 이웃 기반 모델에는 두 가지 기본 원칙이 사용됩니다.
-
사용자 기반 모델:
유사한 사용자는 동일한 항목에 대해 유사한 평가를 받습니다. 따라서 Alice와 Bob이 과거에 비슷한 방식으로 영화를 평가했다면 영화 Terminator에서 Alice의 관찰된 평점을 사용하여 이 영화에서 Bob의 관찰되지 않은 평점을 예측할 수 있습니다. -
아이템 기반 모델:
비슷한 아이템은 동일한 유저에게 비슷한 평점을 받는다.
따라서 Alien 및 Predator와 같은 유사한 공상 과학 영화에 대한 Bob의 등급은 터미네이터에 대한 그의 등급을 예측하는 데 사용할 수 있습니다.
nearest neighbor이 항상 행의 유사도만을 기준으로 결정되는 분류에서 행 또는 열을 기반으로 하는 협업 필터링에서 nearest neighbor를 찾는 것이 가능합니다. 이는 모든 누락 항목이 분류의 단일 열에 집중되는 반면 누락 항목은 협업 필터링의 다른 행과 열에 분산되기 때문입니다.
User-Based Neighborhood Models
- User 기반 이웃은 등급 예측을 계산하려고 유사한 User를 식별하기 위해 정의
- User i의 이웃을 결정하기 위해, 모든 다른 User들에 대한 유사성이 계산 필요
- User가 지정한 등급 사이에 유사도를 정의해야 함, 유사도 계산은 User마다 등급이 다를 수 있으므로 까다로운 작업
- 특정 User는 대부분의 Item을 좋아하는 경향이 있는 반면, 다른 User는 대부분의 Item을 좋아하지 않는 경향이 있을 수 있음
- 또한 여러 User가 서로 다른 Item을 평가했을 수도 있음
m명의 유저들과 n개의 아이템을 다루는 m×n 평점 행렬 R에 대해 Iu를 유저 u에 의해 마킹된 평점의 아이템 셋이라고 하겠습니다. 이때 Iu는 u번째 행(row)을 의미합니다. 예를 들어, 유저(행) u의 첫번째, 세번째, 다섯번째 아이템의 평점이 표시되어 있고 나머지 아이템은 마킹되어 있지 않을때, Iu는 다음과 같다.
Iu={1,3,5}
그러므로 유저u와 유저v가 동시에 평점을 매긴 아이템 목록은 Iu∩Iv가 되는데 유저v가 1,2,3,4 아이템에 평점을 매겼다면 Iv={1,2,3,4}이고, 이에 교집합은 {1,3}이 된다. 이와 같이 두 유저간 공통된 아이템 셋을 구한 뒤
유저간 이웃과 관련된 계산을 할 수 있다.
Similarity Function Variants
-
유사도 함수의 다른 변형이 필요, 하나의 변형은 평균 중심 평가가 아닌 원점 평점에서 코사인 함수를 사용하는 것
- raw 코사인 구현은 분모의 정규화를 할 때 모든 Item을 기반으로 함
- 일반적으로 평균 센터링의 피어슨 상관 계수는 바이어스 조정 효과 때문에 원시 코사인 값보다 바람직함. -
두 명의 User가 공통적으로 소수의 평가만을 갖는 경우
- 유사도 함수는 해당 유저 쌍의 중요성을 덜 강조하기 위해 discount 요소를 줄임.
Variants of the Prediction Function
- 이웃기반 협업 필터링 방법은 가장 가까운 이웃 분류/회귀 방법의 일반화 된 방법이다.
Variations in Filtering Peer Groups
- 타겟 유저에 대한 피어 그룹은 다양한 방식으로 정의및 필터링 될 수 있다.
- 가장 간단한 접근 방식은 타겟 사용자와 가장 유사한 Top-K 사용자를 타겟 유저의 피어 그룹으로 사용하는 것
- but 이러한 접근 방식에는 대상과 약하거나 음의 상관 관계가 있는 유저가 포함될 수 있다.
이는 예측에서 에러가 발생할 수 있다. 그리고 잠재적 등급 관점에서 예측 가치를 낮게 만들 수 있다. - so..관계가 약하거나 부정적인 상관 관계가 있는 평점은 필터링되는 경우가 많음.
Impact of the Long Tail
어느 특정 영화가 유저로부터 매우 인기가 있고, 공통적으로 평가하는 항목이 반복적으로 나타날 수 있는데 이러한 평점은 서로 다른 유저 간 차별성이 적기 때문에 추천 품질을 악화시킬 수 있다.
Exercises
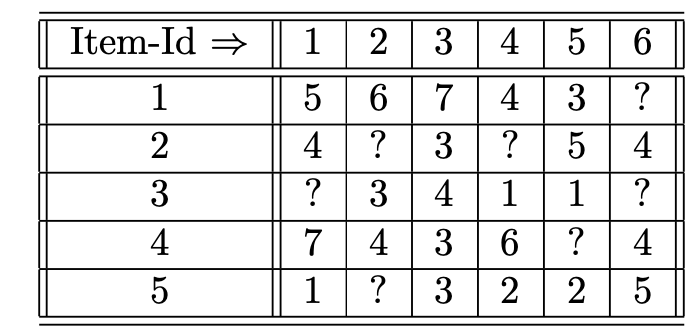
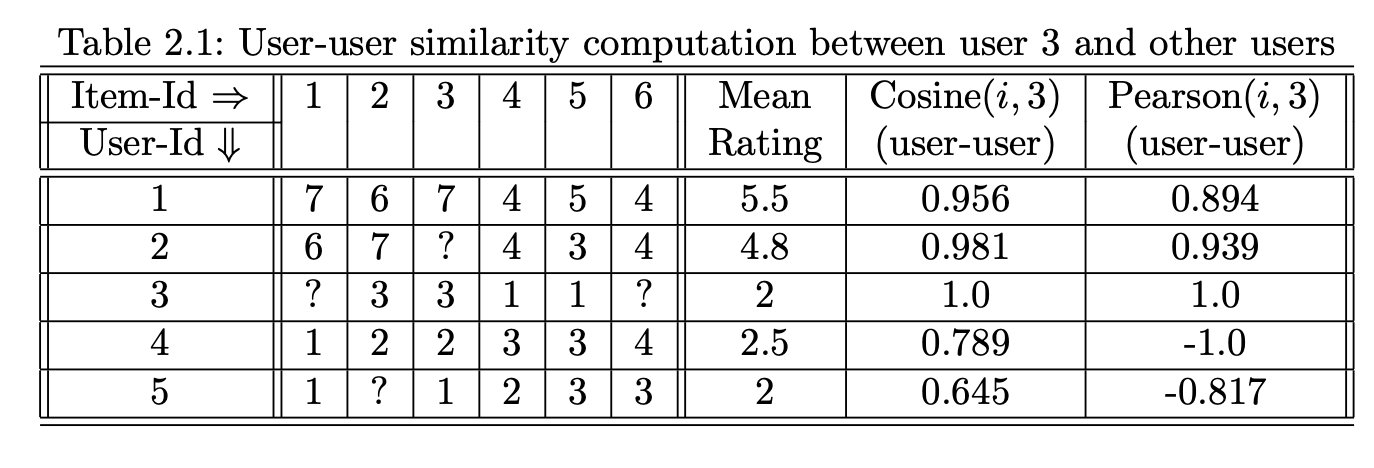
- Consider the ratings matrix of Table 2.1. Predict the absolute rating of item 3 for user 2 using:
(a) User-based collaborative filtering with Pearson correlation and mean-centering
(b) Item-based collaborative filtering with adjusted cosine similarity
Use a neighborhood of size 2 in each case.
- Consider the following ratings table between five users and six items: