Partitioning
논리적으로 1개 존재하는 테이블을 물리적으로 여러 개의 테이블로 나누어 관리하는 방법. 어떤 데이터가 어느 파티션에 포함되는 지는 "파티션 키"를 통해 결정됨.
애플리케이션의 관점에선 단일 테이블로 보이지만, 실제로는 여러 개의 작은 테이블로 나뉘어져 있음.
"애플리케이션 관점에선 단일 테이블"
애플리케이션 개발 중에 서로 다른 파티션에 대해 각기 다른 쿼리를 작성하게 하거나 다른 DAO로 접근하게 하는 것은 안된다는 의미로 보임.
파티셔닝은 DB 사용자가 설정한 규칙에 따라 데이터를 특정 파티션에 할당한다. 이때 이 규칙을 구성하는 것은 파티셔닝 함수와 사용자가 설정한 표현식이다.
파티셔닝 함수의 결과는 파티션을 지정하는 정수 값으로 반환된다.
현재 글에서 설명하는 파티셔닝은 수평적 파티셔닝으로 MySQL 8.4 부터는 Vertical Partitioning을 지원하지 않는다고 한다.
또한 스토리지 엔진에 대한 내용이 나오는데 웬만하면 InnoDB를 사용하면 된다는 취지의 내용으로 보인다.
다만, Default Storage Engine에 의한 오류를 방지하기 위해 table을 생성할 떄는 항상 ENGINE 옵션으로 지정하는 습관을 들이는게 좋다.
파티셔닝과 함께 테이블을 생성하는 구문
CREATE TABLE table_name (
column1 data_type PRIMARY KEY,
column2 data_type,
...
)
ENGINE = InnoDB -- InnoDB or NDB storage engine is required
PARTITION BY partitioning_type (expression_or_column)
PARTITIONS number_of_partitions (
[PARTITION partition_name VALUES LESS THAN (value) | VALUES IN (value_list) | ...]
);특이한 제약 사항
파티셔닝 조건에 사용되는 컬럼은 모든 PK, Unique 조건에 대해 모두 들어가야 한다.
CREATE TABLE tnp (
id INT NOT NULL AUTO_INCREMENT,
ref BIGINT NOT NULL,
name VARCHAR(255),
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
);위와 같은 테이블은 파티셔닝 될 수 없다.
서로 다른 파티션에 같은 UNIQUE 값이 존재할 수 있기 떄문이다
파티션에 들어갈 행의 수를 제한하기 위해 MIN_ROWS, MAX_ROWS 옵션을 사용할 수도 있다.
참고자료 : https://dev.mysql.com/doc/refman/8.4/en/partitioning-overview.html
왜 쓰는가?
-
쿼리 성능 향상 - 필요없는 데이터 스킵.
하나의 테이블 만으로 조회할 경우 인덱스에 의해서만 조회가 이루어지기 때문에 (혹은 table full scan) 대상이 될 가능성 없는 튜플들을 스킵하지 못함. 그러나 파티셔닝을 할 경우 많은 데이터들을 스킵하고 대상이 있을 파티션만 조회하기 때문에 더 효율적이다. -
Delete에 의한 오버헤드 제거 - 로그, 인덱스 재계산 스킵.
만약 이력 데이터를 저장한다면 오랜 기간이 지난 데이터들을 한 번에 제거할 필요가 있음. (다시 쓸 일이 없다면..) Drop partition으로 매우 빠른 삭제가 가능함. delete를 하게 된다면 바이너리 로그에 변경 내역을 기록하게 되며, 삭제에 의해 인덱스를 업데이트해야해서 오버헤드가 발생함.
파티셔닝 종류
-
Range partitioning
값의 범위를 기반으로 파티션을 분할함. 이력을 기록하는 테이블에 자주 사용됨. 시간별 조회에 좋음.
단점 : 핫 파티션 문제. (최신 이력 파티션에만 쓰기 연산이 집중) -
List partitioning
컬럼에 대한 값 별로 파티션을 나눔. 범주별로 깔끔하게 분리할 수 있음.
단점 : 특정 값을 가진 데이터가 더 많을 경우 해당 파티션에 연산이 집중됨. 새로운 값이 추가되거나 제거되면 파티션도 증가/삭제 되어야 함. -
Hash partitioning
키 값에 해시 함수를 적용해 파티션 키로 사용. 데이터를 파티션 별로 균등하게 나눌 수 있음.
단점 : 범위 조회에 매우 비효율적이며, 파티션을 늘리거나 줄일 경우 재해싱이 필요함. -
Composite Partitioning
여러 파티셔닝을 복합적으로 적용함. 예를들어 시간별로 Range partitioning하고 다른 컬럼으로 Hash partitioning.
시간별 조회 + 연산 균등화에 좋음.
단점 : 설계, 운영 시 복잡도가 증가함.
파티션 인덱싱
- 로컬 인덱스 : 파티션 별로 인덱스를 만들어 사용하는 방법. 관리가 편함.
- 글로벌 인덱스 : 전체 파티션에 대한 인덱스를 만듦. 특정 쿼리에 대해 효율적 but 설계/운영 복잡도가 증가함.
보통 로컬 인덱스 + Range partitioning을 이용해 운영하는게 현실적임.
체크 리스트.
- 파티션 키는 자주 필터링 되는 조건이어야 함.
다른 컬럼을 통해 조회시 파티셔닝하는 이점이 감소함. - 너무 많은 파티션은 피해야 함. - 관리 비용 증가, 쿼리 속도 저하.
보통 1개 파티션 당 크기 설정. - 핫 파티션에 의한 쓰기 집중 -> Composite Partitioning으로 해소할 수 있음.
- 조인/유니크 제약에 대한 사항을 확인해야 함.
예시
CREATE TABLE ti (id INT, amount DECIMAL(7,2), tr_date DATE)
ENGINE=INNODB
PARTITION BY HASH( MONTH(tr_date) )
PARTITIONS 6;- ti 테이블을 생성하면서 tr_date의 월 데이터에 대한 해시로 6개의 파티션을 생성함.
개별 PARTITION 구문은 ENGINE 옵션을 제각각 설정할 수 있음. 다만 파티셔닝을 지원하는 엔진으로 지정해야함. INNODB, NDB 정도가 유효함.
파티션 추가, 제거
range 파티션 제거
ALTER TABLE TABLE_NAME DROP PARTITION p2010, p2020;range 파티션 추가
ALTER TABLE TABLE_NAME ADD PARITION
(PARTITION p2020 LESS THAN ('2030-1-31 00:00:00');range 파티션 - 범위 밖의 값
MAXVALUE를 사용해서 범위 밖의 값이 들어갈 파티션을 만들 수 있음.
CREATE TABLE TABLE_NAME (
...
) PARTITION BY RANGE(YEAR(hired_at))
PARTITIONS 10 (
...
PARTITION pmax VALUES LESS THEN MAXVALUE
);만약 위와 같다면, 새로운 파티션 추가시 PMAX를 쪼개야하는 경우도 발생함. 예를들어 2030년 ~ 2035년에 대한 파티션을 추가해야할 경우 다음과 같음.
REORGANIZE와 INTO가 있음.
ALTER TABLE employees_p
REORGANIZE PARTITION p2030 INTO (
partition p2035 values less than (2036),
partition pmax values less than MAXVALUE
);리스트 파티셔닝 - 새로운 값 추가
리스트 파티션은 범주에 없는 값이 포함된 데이터가 삽입되면 에러가 발생함. 새로운 값이 추가된다면 다음과 같이 파티션을 추가함.
ALTER TABLE t
ADD PARTITION (
PARTITION p_us VALUES IN ('US')
);MAXVALUE는 오직 RANGE PARTITIONING에서만 사용 가능함.
해쉬 파티셔닝 - 파티션 추가
해쉬 파티셔닝의 경우 파티션 스케일이 변하면 반드시 REHASHING이 발생하게됨.
ALTER TABLE t COALESCE PARTITION 2; -- 파티션 2개 줄이기
ALTER TABLE t ADD PARTITION PARTITIONS 2; -- (버전/상황에 따라 동작/제약 있음)실험
구성
MySQL 버전 : 8.0.41
Host OS : Windows 11
실험용 데이터 볼륨 : 1000만 행
실험 내용
Paritioning(Range Partitioning)과 일반 인덱싱의 쿼리 성능 비교.
실험
1. Dummy data 생성하기
파이썬 프로그램 작성하여 더미 데이터를 생성하도록 코딩하였음. 결과는 csv 파일로 출력하고 사용자가 명령행 인자로 준 라인수, 컬럼 구성 대로 데이터를 생성함
2. 테이블 생성하기
파티셔닝을 사용하는 테이블, 파티셔닝을 사용하지 않는 테이블을 만들고 데이터를 입력함. CSV 파일이므로 LOAD DATA INFILE 구문을 사용하여 입력함.
-- 파티셔닝 적용한 테이블
create table employees_p(
id bigint,
first_name varchar(30) not null,
last_name varchar(30) not null,
hired_at datetime not null,
age int not null,
weights decimal(10,1) not null,
primary key(id, hired_at),
constraint P_CONST_HIRE_DATE check(hired_at > '1949-12-31'),
index idx_hired_at(hired_at),
index idx_age(age),
index idx_name(last_name, first_name)
) ENGINE = InnoDB
partition by range(year(hired_at))
partitions 8 (
partition p1950 values less than (1960),
partition p1960 values less than (1970),
partition p1970 values less than (1980),
partition p1980 values less than (1990),
partition p1990 values less than (2000),
partition p2000 values less than (2010),
partition p2010 values less than (2020),
partition p2020 values less than (2030)
);
-- 파티셔닝 없는 테이블
create table employees_np(
id bigint,
first_name varchar(30) not null,
last_name varchar(30) not null,
hired_at datetime not null,
age int not null,
weights decimal(10,1) not null,
primary key(id, hired_at),
constraint NP_CONST_HIRE_DATE check(hired_at > '1949-12-31'),
index idx_hired_at(hired_at),
index idx_age(age),
index idx_name(last_name, first_name)
) ENGINE = InnoDB;3. SQL 실행
A. 범위 조회(파티셔닝의 대표 장점: pruning)
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM employees_X
WHERE hired_at >= '2015-01-01' AND hired_at < '2016-01-01';X = np / p
파티션 테이블은 사용한 partitions 정보(EXPLAIN 출력)와 실행 시간이 줄어드는지 관찰
- 파티셔닝

파티션 : p2010
인덱스 : range 스캔
읽을 행의 수 : 253214개
분석 결과 :'-> Aggregate: count(0) (cost=76885 rows=1) (actual time=75.4..75.4 rows=1 loops=1)\n -> Filter: ((employees_p.hired_at >= TIMESTAMP\'2015-01-01 00:00:00\') and (employees_p.hired_at < TIMESTAMP\'2016-01-01 00:00:00\')) (cost=51464 rows=254214) (actual time=0.0855..71.6 rows=131504 loops=1)\n -> Covering index range scan on employees_p using idx_hired_at over (\'2015-01-01 00:00:00\' <= hired_at < \'2016-01-01 00:00:00\') (cost=51464 rows=254214) (actual time=0.0826..58.8 rows=131504 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Covering Index Range Scan | 254,214 | 131,504 | 0.0826 ~ 58.8 | idx_hired_at 인덱스 범위 스캔 |
| 2 | Filter (WHERE 조건 적용) | 254,214 | 131,504 | 0.0855 ~ 71.6 | 범위 조건 필터 적용 |
| 3 | Aggregate (COUNT) | 1 | 1 | 75.4 ~ 75.4 | 최종 집계 결과 반환 |
- 파티셔닝 X
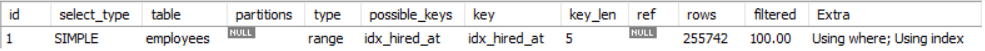
파티션 : 없음
인덱스 : range 스캔
읽을 행의 수 : 255742개
분석 결과 :'-> Aggregate: count(0) (cost=77129 rows=1) (actual time=40.7..40.7 rows=1 loops=1)\n -> Filter: ((employees.hired_at >= TIMESTAMP\'2015-01-01 00:00:00\') and (employees.hired_at < TIMESTAMP\'2016-01-01 00:00:00\')) (cost=51555 rows=255742) (actual time=0.0544..36.9 rows=131504 loops=1)\n -> Covering index range scan on employees using idx_hired_at over (\'2015-01-01 00:00:00\' <= hired_at < \'2016-01-01 00:00:00\') (cost=51555 rows=255742) (actual time=0.0526..23.7 rows=131504 loops=1)\n'
단계별 분석:
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Covering Index Range Scan | 255,742 | 131,504 | 0.0526 ~ 23.7 | idx_hired_at 인덱스 범위 스캔 |
| 2 | Filter (WHERE 조건 적용) | 255,742 | 131,504 | 0.0544 ~ 36.9 | 범위 조건 필터 적용 |
| 3 | Aggregate (COUNT) | 1 | 1 | 40.7 ~ 40.7 | 최종 집계 결과 반환 |
의견 :
둘 다 Covering Index Range Scan이 발생함. hired_at이라는 컬럼에 현재 인덱스가 생성되어 있기 때문임. 예상한 결과로는 Partitioning된 경우가 근소하게 빠를 것 같았으나 실제로는 단일 테이블이 더 빨랐음.
B. 범위 + 정렬 + LIMIT
EXPLAIN ANALYZE
SELECT *
FROM employees_X
WHERE hired_at >= '2018-01-01' AND hired_at < '2019-01-01'
ORDER BY hired_at DESC
LIMIT 100;- 파티셔닝

파티션 : p2010
인덱스 : range 스캔
읽을 행의 수 : 241086개
분석 결과 :'-> Limit: 100 row(s) (cost=133859 rows=100) (actual time=7.05..26.8 rows=100 loops=1)\n -> Index range scan on employees_p using idx_hired_at over (\'2018-01-01 00:00:00\' <= hired_at < \'2019-01-01 00:00:00\') (reverse), with index condition: ((employees_p.hired_at >= TIMESTAMP\'2018-01-01 00:00:00\') and (employees_p.hired_at < TIMESTAMP\'2019-01-01 00:00:00\')) (cost=133859 rows=241086) (actual time=7.05..26.8 rows=100 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Index range scan (reverse) | 241,086 | 100 | 7.05 ~ 26.8 | idx_hired_at 인덱스를 역방향으로 읽으며 2018년 범위에서 100건을 찾음 |
| 2 | Limit 100 | 100 | 100 | 7.05 ~ 26.8 | 100건 채우면 즉시 종료(early stop) |
- 파티셔닝 X

파티션 : p2010
인덱스 : range 스캔
읽을 행의 수 : 241086개
분석 결과 :'-> Limit: 100 row(s) (cost=285236 rows=100) (actual time=90.9..90.9 rows=100 loops=1)\n -> Index range scan on employees using idx_hired_at over (\'2018-01-01 00:00:00\' <= hired_at < \'2019-01-01 00:00:00\') (reverse), with index condition: ((employees.hired_at >= TIMESTAMP\'2018-01-01 00:00:00\') and (employees.hired_at < TIMESTAMP\'2019-01-01 00:00:00\')) (cost=285236 rows=262924) (actual time=90.9..90.9 rows=100 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Index range scan (reverse) | 262,924 | 100 | 90.9 ~ 90.9 | 2018년 범위에서 역방향으로 스캔하며 100건을 찾음 |
| 2 | Limit 100 | 100 | 100 | 90.9 ~ 90.9 | 100건 충족 시 종료 |
의견 :
이번 실행에선 ORDER BY 옵션을 주고 DESC 내림차순 정렬했기 때문에 reverse scan이 발생했음.
그리고 파티셔닝한 경우 26.8ms, 파티셔닝 하지 않은 경우 90.0ms로 성능차이가 크게 발생함.
파티셔닝 하지 않은 경우 첫 데이터 ~ 마지막 데이터까지 걸린 시간이 매우 짧은데, 아마 다른 부분에서 지연이 생긴듯.
여러번 수행해본 결과로도 역시 파티셔닝이 더 빨랐음. 캐싱 등에 의한 것으로 추측됨.
C. 파티션 키와 무관한 조회(장점이 거의 없거나 오히려 손해)
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM employees_X
WHERE age BETWEEN 30 AND 39;- 파티셔닝

파티션 : 모든 파티션
인덱스 : range 스캔
읽을 행의 수 : 1866824개
분석 결과 :'-> Aggregate: count(0) (cost=564370 rows=1) (actual time=538..538 rows=1 loops=1)\n -> Filter: (employees_p.age between 30 and 39) (cost=377687 rows=1.87e+6) (actual time=0.284..510 rows=1.01e+6 loops=1)\n -> Covering index range scan on employees_p using idx_age over (30 <= age <= 39) (cost=377687 rows=1.87e+6) (actual time=0.278..454 rows=1.01e+6 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Covering Index Range Scan | 1.87e+6 | 1.01e+6 | 0.278 ~ 454 | idx_age에서 30~39 범위를 인덱스만으로 스캔 |
| 2 | Filter | 1.87e+6 | 1.01e+6 | 0.284 ~ 510 | 조건 적용(사실상 인덱스 범위와 동일) |
| 3 | Aggregate (COUNT) | 1 | 1 | 538 ~ 538 | 최종 카운트 1행 반환 |
- 파티셔닝 X

파티션 : 없음
인덱스 : range 스캔
읽을 행의 수 : 2029210개
분석 결과 :'-> Aggregate: count(0) (cost=611735 rows=1) (actual time=417..417 rows=1 loops=1)\n -> Filter: (employees.age between 30 and 39) (cost=408814 rows=2.03e+6) (actual time=0.151..385 rows=1.01e+6 loops=1)\n -> Covering index range scan on employees using idx_age over (30 <= age <= 39) (cost=408814 rows=2.03e+6) (actual time=0.149..319 rows=1.01e+6 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Covering Index Range Scan | 2.03e+6 | 1.01e+6 | 0.149 ~ 319 | idx_age에서 30~39 범위를 인덱스만으로 스캔 |
| 2 | Filter | 2.03e+6 | 1.01e+6 | 0.151 ~ 385 | 조건 적용(실제로는 인덱스 범위와 거의 동일) |
| 3 | Aggregate (COUNT) | 1 | 1 | 417 ~ 417 | 최종 count 결과 1행 반환 |
의견 :
최종 결과로 출력된 실행과정은 둘 다 동일했음.
파티셔닝된 경우, 파티션 키와 age가 무관하기 때문에 모든 파티션을 검색했고, 이로인해 오버헤드가 발생했을 가능성이 높음. 현재 각 파티션마다 별도의 인덱스가 생성되어 있기 떄문임.
결과적으로 파티셔닝 안한 경우가 더 빨랐음.
D. 특정 한 사람/키 조회(인덱스가 있으면 차이 거의 없음)
EXPLAIN ANALYZE
SELECT *
FROM employees_p
WHERE id = 1234567;- 파티셔닝

파티션 : 전체 파티션
인덱스 : 동등 비교
읽을 행의 수 : 1개
분석 결과 :'-> Index lookup on employees_p using PRIMARY (id=123456789) (cost=1.1 rows=1) (actual time=0.0887..0.0887 rows=0 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Index lookup on employees_p using PRIMARY (id=1234567) | 1 | 1 | 0.0391..0.0541 | PK로 단건 조회 성공, 1행 반환 (빠른 포인트 조회) |
- 파티셔닝 X

파티션 : 없음
인덱스 : 인덱스(PK)로 즉시 조회
읽을 행의 수 : 1개
분석 결과 :'-> Rows fetched before execution (cost=0..0 rows=1) (actual time=200e-6..300e-6 rows=1 loops=1)\n'
단계별 분석 :
| 단계 | 실행 노드 | 옵티마이저 추정 rows | 실제 rows | 실제 시간(ms) | 설명 |
|---|---|---|---|---|---|
| 1 | Rows fetched before execution | 1 | 1 | 0.0002..0.0003 | 실행 전 상수/확정 row 미리 조회 (매우 빠름) |
의견 :
파티셔닝 X인 테이블은 생성할 때, hired_at과 같이 PK를 설정하지 않았었음. (데이터 로드 시간 문제로 기존 테이블 활용하였기 때문임.)
따라서 사실상 쿼리 실행시 검색 대상이 확정되었음. 그래서 거의 시간이 걸리지 않음.
반면, 파티셔닝된 테이블은 hired_at과 같이 인덱스가 생성되었고, 파티션 여러곳에 접근했기 때문에 금나큼 시간이 더 걸린것으로 추정됨. (파티셔닝 기준은 hired_at이기 때문인듯)
E. 오래된 데이터 삭제(파티셔닝의 큰 장점: DROP PARTITION)
비파티션(느릴 수 있음):
-- 예: 1990년 이전 삭제
DELETE FROM employees_np
WHERE hired_at < '1990-01-01';파티션(대량 삭제가 메타작업으로 끝나는 경우 많음):
ALTER TABLE employees_p DROP PARTITION p1950, p1960, p1970, p1980;-
파티셔닝

삭제된 파티션 : p1950, p1960, p1970, p1980
삭제 시간 : 0.067s -
파티셔닝 X

삭제된 파티션 : 없음
삭제 시간 : 359.984s
의견 :
삭제 시간은 비교가 무의미할 정도로 차이가 컸다.
특히 Delete 문으로 삭제할 경우 rollback을 위해 로그를 기록하며, 전체 테이블에서 삭제 대상을 일일이 스캔하여 찾아야하기 때문에 아주 오래 걸린 것으로 보인다.이력 데이터의 경우에는 실제 운영에서 아주 많이 저장될 수 있는데, 이때 단일 테이블로만 관리할 경우 특정 시간대 이력 삭제시 커넥션이 끊기는 문제도 발생할 수 있으며 lock에 의한 문제도 발생 가능할 것이다.
예전에 이런 데이터를 저장하기 위해 여러 테이블을 사용할까 했는데 앞으로는 반드시 파티셔닝 활용이 필요해보인다. (또는 샤딩)
F. 인덱스 재구성/유지보수(파티션별 관리의 이점/비용)
예를 들어 idx_age를 제거/재생성:
ALTER TABLE employees_X DROP INDEX idx_age;
ALTER TABLE employees_X ADD INDEX idx_age(age);파티션 테이블은 내부적으로 “파티션별 인덱스” 운영이 되면서 비용 양상이 달라질 수 있음
-
파티셔닝

삭제 인덱스 : age
재생성 시간 : 12.438s -
파티셔닝 X

삭제 인덱스 : age
재생성 시간 : 8.672s
의견 :
파티셔닝의 경우 여러 파티션 각각에 대해 인덱스를 만들어야해서 오래걸린것으로 추정됨. 반명 단일 테이블은 역시 한 번만 생성하면 되기 때문에 둘의 데이터 수가 동일하고 분포가 일정하다면, 단일 테이블이 더 빠른것 같음.

글좀 써주세요