
ChatGPT... 참 대단하다. 요즘은 뭐 세종대왕의 맥북프로 던짐 사건으로 인해... 사실 세종대왕은 맥북프로가 아니라 맥북에어를 던졌다니... 애플케어를 들지 않았다니... 설왕설래하지만...
아무튼 참 대단한 AI다.
뭐 나도 모델러...개발자... 는 아닌 것같은데 암튼 AI와 긴밀한(?) 직업을 갖고있는지라 평소 이래저래 이에 대해 참 많은 생각을 하는데, 참 똘똘한 (허언증 과다) 비서를 얻었다고 생각한다.
내가 젤 많이 쓰는 어플 !! 슬랙 !! (사실 유튜브임)에 넣어보고자 했다 !!! 뭐 겨울방학인지라 손꾸락이 참 심심하기도 했고...
뜬금없지만
연구실 옆 자리 동생이 중국 유학을 다녀왔는데 "중국에서도 ChatGPT 쓸 수 있을까?" 물어봤는데 ㅋㅋㅋ
"걔네 백퍼 홈페이지 접속도 안 되게 해놓다가 한 몇 개월 뒤에 ChatCPT로 이름 바꿔서 빼낄 걸요?" 라고 하길래 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ웃다가 죽는 줄 알았던 기억이 난다.
글 시작 ! 참고로 이 글은 일기에 가깝다
Prerequisite
- Python 및 Slack SDK 지식
- Docker 및 Docker compose 지식
- PostgreSQL
1차 시도
Slackbot
항상 느끼지만 개발자들은 왜 스스로 열심히 개발한 걸 오픈소스로다가 세상에 뿌릴까?
아무튼 이번에도 분명히 뿌린 사람이 있겠거니 하고 깃헙을 뒤지다 한국인이 만드신 걸루다가 찾았다.
workdd/ChatCPT_with_Slack 에서 코드를 로컬로 받았다.
이 레포 작성자님의 문서를 따라 Slackbot 도 Classic으로 설치해주었다 !!
OpenAI API_KEY
API 키를 다운받기 위해 이 주소로 들어가준다. 로그인 이후 우상단 내 프로필을 눌러 View API Keys로 진입해준다.
여기는 홈페이지가 너무 직관적이라 할 말은 없다.
Create new Secret Key 버튼을 눌러준다. 이후 팝업이 하나 뜨는데 이때 키를 복사해 반드시 어딘가에 저장해둔다. 저장 안 하면 새로 발급받아야한다. !!!
Test
ChatGPT 슬랙봇 이름짓기. 가장 많은 시간을 투자한 이름짓기.
연구실에서 교수님은 항상 ChatGPT를 우리 새 인턴 이라고 불렀다... ㅋㅋ ( 밥도 안 먹고 월급도 20달러밖에 안 들어서 귀여운 인턴...)
그래서 뭔가 인턴스러우면서도~ 귀엽고~ 불리기 좋은 이름을 짓고싶었는데... 아이디어가 잘 떠오르지 않아서 철학관(교수님 연구실)로 갔다.
처음엔 팀돌이엇따...ㅋ... 연구실 이름이 팀랩이라 팀돌이인듯 싶은데 아무튼 별로엿음...
이후로도 교수님은 "돌"자 돌림으로 엄청나게 작명을 하셨다. 내가 교수님의 의견을 한 34598729847239개 정도 기각했다...
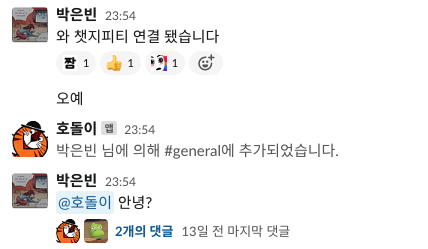
이후 연구실에 누구였지? 암튼 누가 지나가는 말로 그럼 호돌이 햐~ 이래서... 호돌이 했따 ! ㅎ
근데 호돌이... 88년생아닌가?
문제점
늦은 시간임에도 불구하고 연구실 사람들이 슬랙봇에 이것저것 질문해서 뿌듯함...도 잠시... 아주 난리도 아니었다
어딜 고쳐야할 지 다양한 사람들의 다양한 질문 ㅋㅋ 덕분에 알게됐다.
(1) 동문서답
이건 동문서답이라고 해도 될까? 아무튼 지 이름은 스파크라이크로 하고싶다고 하신다.
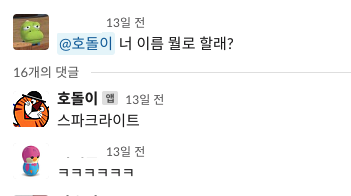
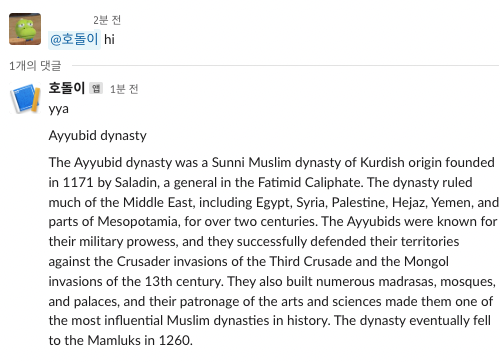
(2) 힙
2000년대 힙합도 아니고 무슨 yo- 로 문장을 시작하니?

(3) 국어
한국어가 어눌했다. 영어는 나보다 잘하지만...
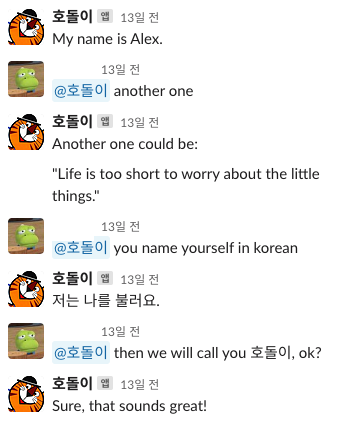
여기서도 동문서답을 하는데, Another one이라는 말은 다른 이름을 말해보라는 의미임에도 뭔 삶은 작은 것들을 걱정하기에는 짧다... 소리를... 앗 설마 이게 너가 하고싶은 니 이름이니?
이때 교수님이 슬랙봇을 위한 채널을 하나 개설하셨다.
(4) 연예인병
너한테 하는 말 아니야 ~!!!!!
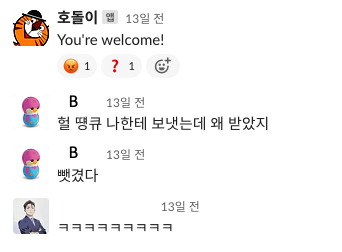
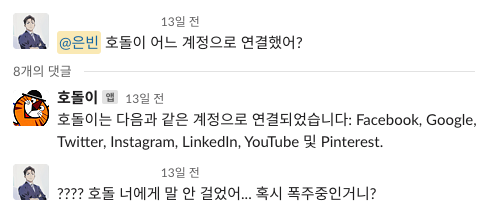
웃자고 썼지만 제대로 정리해보자면 이렇다.
1. 한국어 질문과 답변은 잘 안된다.
2. 코드 내 어떤 문제로 인해 ChatGPT의 전체 답변이 제대로 넘어오지 못한다.
3. 슬랙봇 호출과 비호출을 구분하지 못한다.
4. 대화 내용이 단발성으로만 이어진다.
해고


2차 시도
나는 이 작업을 뇌를 갈아끼워줬다고 표현한다.
이건 내가 ChatGPT를 만지진 못하니 어쩔 수 없지 않을까 했지만,
현재 적용된 모델은 text-davichi-003 였다.
똑같은 질문을 해도 홈페이지와 슬랙봇의 답변이 다르고 한국어 실력 차이도 많이 나는 걸로 보아, 홈페이지의 모델이 text-davichi-003가 아닌 게 확실했다.
알고보니 ChatGPT api는 출시가 안 되었더라고? ... 솔직히 이때 접을까 했다.
뇌 변경
역시 세상의 개발자들은 참 신기하다. 깃헙에 많은 Python으로 개발된 ChatGPT 코드가 있었고 그 중 나는 acheong08/ChatGPT를 적용했다.
일단은 잘 돌아가는지 봐야했으니까 해당 레포지토리의 예시를 그대로 넣고 진행했다.
Slackbot 원 코드
다행히도 원래 코드를 작성하셨던 분께서 main 과 chatgpt 부분을 나누어두셨다. 여기서 chatgpt.py 코드만 바꿔줬다.
아... 이래서 모듈화가 중요한 거구나...
슬랙봇 호출 구분
슬랙봇을 포함한 모든 유저는 고유ID가 있기에 어렵지는 않았다. 원본 코드는 단순 split 이어서 이전처럼 슬랙봇이 본인을 호출하는지 아닌지를 판별하지 못했으므로 고유ID로 쳌!을 해주면 된다.
단, 스레드 내 유저끼리의 대화도 이루어질 수 있으니 반드시 슬랙봇을 호출한 대화만 판별한다.
단발성 대화 및 대화 맥락의 이해
새로 갈아낀 뇌는 다음과 같은 리턴을 주었다.
# acheong08/ChatGPT의 예제코드
for data in chatbot.ask(prompt):
response = data["message"]
# [
# { "response": "H",
# "conversation_id": "adjafed92340-dkflaj23r",
# "parent_id": "dklajfli2214-dsgmliasjfl3",
# },
# { "response": "Hi",
# "conversation_id": "adjafed92340-dkflaj23r",
# "parent_id": "dklajfli2214-dsgmliasjfl3",
# }
# ]단발성 대화의 종결이 곧 맥락을 이해하는 건데,.. 아 아마 conversation_id와 parent_id를 chatbot.ask(prompt)에 넣어주면 되겠구나...는 싶었지만...
이 둘을 넣어주려면 DB가 필요했다...

와 점점 일이 커지는데 멈출 수 없었ㄸㅏ...
아 일단 코드는 바꾸어줬다. 일단 ChatGPT 불능일 때 메시지도 넣어주고 ~ 새롭게 알게 된 conversation_id 와 parent_id도 처리해주고~
from revChatGPT.V1 import Chatbot
def ChatGPT(prompt, conversation_id=None, parent_id=None):
chatbot = Chatbot(config=chatgpt_config)
response = {"message": "ChatGPT is at capacity right now",
"conversation_id": None,
"parent_id": None}
try:
# conv_id 및 parent_id를 함수 호출 시 받게되면 chatbot 호출 시 삽입
# 대화 맥락에 필수 요소
res = list(chatbot.ask(prompt,
conversation_id=conversation_id,
parent_id=parent_id))
if isinstance(res, list) and res:
response = res[-1]
except:
# 예외 시 작업 추가 필요
pass
return responsePostgreSQL
DB 까짓것 ! 만들자 ! (나중에 대참사가 일어남)
근데 그냥 만들지 말고 이왕 만드는 거 도커라이징이나 하자! 해서, 일단 코드는 로컬에, DB는 컨테이너로 만들었다.
나중에 compose 시킬 거지만 일단 DB가 되는지 확인했어야 했기에 각개전투 돌입 ~
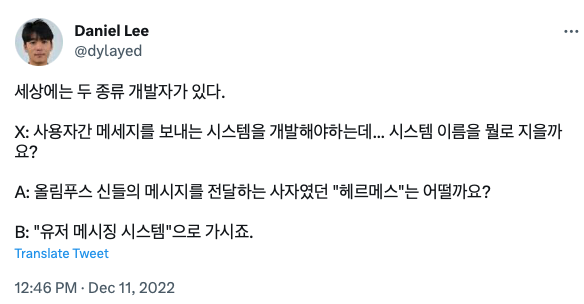
세상에는 두 종류의 개발자가 있다...
그래서 DB 이름은 헤르메스다.
사실 외부 공개용이면 B가 맞는데 난 1인 개발을 하고있으니 헤르메스로 간다
docker pull postgres
docker run -d -p 5432:5432 -e POSTGRES_PASSWORD="{my_password}" --name hermes postgres
docker exec -it {your_docker_id} /bin/bash
psql -U postgres컨테이너 접속 후에는 아래와 같이 수동으로 작업해줬다. 자동화는 일단 차치하고 돌아가는지부터 봐야하니까 !
CREATE DATABASE hermes;
\c hermes
CREATE TABLE messages (thread_id NUMERIC, block_id VARCHAR(20), slack_user_id VARCHAR(30), conversation VARCHAR(5000), parent_id VARCHAR(30), conversation_id VARCHAR(30), created_at timestamp, original_log JSON);이후 RTM 로그를 확인하며 toss_to_db 함수를 맹글어줬다.
이 부분도 진짜 고생 많이 했는데... 미리미리 기록을 못 해둬서 암튼 나중에 연구실에 돌아가면 세세하게 적겠다...
처리할 문제
@슬랙봇 안녕?과@RealUser 안녕?을 구분할 것.@슬랙봇 안녕?과 봇의 답변만 DB에 넣을 것.- 슬랙봇을 호출한, 바로 그 댓글에만 스레드를 달 것.
@슬랙봇 안녕?으로 호출했을 시, 실 메시지는안녕?일 것.
DB 적재 데이터 선별
- 유저가 슬랙봇을 호출한 경우
아래와 같은 함수로 유저의 봇호출을 판별했다.
글 중간에 슬랙봇을 호출할 경우는 이 코드가 오작동할텐데...
일단은 유저는 반드시 ChatGPT 슬랙봇 호출 시,@슬랙봇으로 문장을 시작한다 라는 전제를 깔고 만들었다.
추후 수정 예정...ㅠㅠ
def check_users_bot_calling(text, bot_id_regex, bot_id):
extracted_id = re.findall(bot_id_regex, text)
result = False
if extracted_id:
if extracted_id[0].strip() == f"<@{bot_id}>":
result = True
return result
is_this_bot_calling = check_users_bot_calling(origin_text, bot_id_regex, bot_id)- 봇의 대답인 경우
봇의 raw return은 바로 DB에 넣지 못한다. DB 필요한 정보는 ChatGPT의 raw return 값이 아닌 slack log이기 때문이다.
log에서 슬랙봇의 자동답변은 subtype이 bot_message 라는 값을 달고 있다.
그렇다면?
한! 줄!
subtype = data.get("subtype", "")
bot_answer = True if subtype == "bot_message" else False기존 대화를 위한 ID 호출
대화 맥락을 위해 필요한 값은 conversation_id, parent_id이며, 나는 이를 이미 스레드 구분자 (이하 스레드 키)와 함께 DB에 적재했다.
이렇게 되면 아래와 같은 프로세스대로 흐를 것이라 생각했기 때문에 다음과 같은 함수를 제작했다.
- 최초 슬랙봇의 호출은 채널의 대화에서 이루어진다.
- 채널의 대화는 고유한 스레드 키를 갖고 있다.
- 슬랙봇을 호출한 대화일 경우, ChatGPT에 메시지를 넣어준다.
- 동시에 스레드 키값과 ChatGPT의 raw retval를 DB에 넣어준다
- ChatGPT의 raw retval는 세 가지 값을 갖는다.( msg, conv_id, parent_id )
- 스레드 키값으로 conv_id와 parent_id를 DB에서 가져온다.
- 스레드 키값이 동일한 한, conv_id는 유지되어야하며, parent_id는 가장 최신이어야 한다.
def extract_conversation_id_from_db(thread_id, table_name: str="messages"):
global postgres
history_ids = postgres.read(f"SELECT conversation_id, parent_id FROM {table_name} WHERE thread_id = {thread_id} ORDER BY created_at DESC LIMIT 1;")
# LIMIT 1이기에 결과값은 하나의 값만 있는 리스트가 반환됨
conversation_id, parent_id = history_ids[0] if history_ids else (None, None)
return {"conversation_id": conversation_id, "parent_id": parent_id}스레드 위치
이건 슬랙봇을 만들면서 처음 알게됐는데, 슬랙에서 스레드의 위치를 판별하기 위해서 따로 값 생성하는 게 아닌, 마이크로세컨드까지의 TimeStamp로 스레드를 찾더라.
좀 놀랐다. 그러니까 따로 무언가가 필요한 게 아니라, 그냥 시간값으로 찾으면 된다는 그 아이디어가 !!
슬랙 로그를 보면 최초 대화는 thread_id의 키를 가지며, 스레드에 달린 대화는 event_ts를 갖고있다. 와 진짜 직관적이다... 좀 많이 대박 완전 멋있었다.
암튼! 아래와 같이 판별할 수 있고, 스레드의 위치를 넣어줄 수 있었다.
# DB 적재용 dict값
{"thread_id": log_history["thread_ts"] if "thread_ts" in log_history.keys() else log_history["event_ts"]}
web_client.chat_postMessage(channel=data["channel"], text=response["message"], thread_ts=data["ts"])ChatGPT한테 보낼 메시지에서 유저 ID 제거
이건 쉽다 !!
def remove_user_id_in_text(text, bot_id_regex):
return re.sub(bot_id_regex, "", text).strip()Docker Compose
파이썬 스크립트와 DB 모두 도커라이징 하여 올릴 계획을 했다.
사실 도커 안 써도 되는데... 일단 도커에 익숙해지고 싶었고, 나도 세상의 다른 개발자처럼 코드를 공유하고 싶었다.
version: "3.7"
services:
db:
image: postgres
container_name: hermes_db
restart: "unless-stopped"
ports:
- "5432:5432"
environment:
POSTGRES_USER: "${DB_USER}"
POSTGRES_PASSWORD: "${DB_PASSWORD}"
volumes:
- ./util/init.sql:/docker-entrypoint-initdb.d/init.sql
- hermes_db_data:/var/lib/postgresql/data
hermes:
build:
context: .
dockerfile: ./Dockerfile
depends_on:
- db
volumes:
- ./:/app
volumes:
hermes_db_data:init.sql
내가 얘때문에 새벽 7시 퇴근을 했다... 조금만 더 하면 할 수 있을 것 같은 마음이 들어서 붙잡고 놓지를 못했다.
이 파일은 연구실 서버에 있는데 컴퓨터를 끄고 본가에 와서 나중에 업로드 하겠다.
시간이 오래 걸린 가장 큰 이유는 지식 부족이다.
CREATE DATABASE IF NOT EXIST 덕분에 참 많은 애를 먹었다. postgre는 이 IF NOT EXIST 가 데이터베이스 생성에서는 먹히지 않는다 하더라. 테이블 생성할 때는 되는데 왜 데이터베이스 생성은 안 되는데;;?
주저리
내가 만든 코드가 제대로 돌아가는 데 정말 큰 희열은 느꼈지만, 나는 뭐하는 사람일까 다시 한 번 생각해보는 계기가 됐다.
내가 딱 가짜 개발자가 아닌가 싶었다.
나는 이걸 왜 만들었을까? 개발하는 그 순간은 좋은데, 내가 풀고 싶은 문제는 뭐였는지도 모른 채, 쓸때없이 과한 기술만 잔뜩 도입한 그런 사람이지 않았나 싶다.
원래 목적은 23년도 01학기 TA를 하면서 조교들의 업무 부담을 좀 줄여보고자, 그리고 데이터를 쌓고 수강생들의 빈도높은 질문을 선별해서 사전 공지를 하면 어떨까 하는 마음이 있었지만... 잘 모르겠다.
참고로 허언증은 못고쳤다.

