Introduction
SOTA Neural Network Architectures의 발견은 전문가의 노력이 필요하다.
최근에는 아키텍처 설계의 수동 프로세스를 자동화하는 알고리즘 솔루션 개발에 대한 관심이 증대하고 있다. Automatically Searched Architectures ( 이하 자동 검색 아키텍쳐 )는 이미지 분류 및 객체 감지와 같은 작업에서 매우 경쟁력 있는 성능을 달성했다.
현존 최고 아키텍쳐 검색 알고리즘은 뛰어난 성능이지만 계산적인 소모가 있다.( Computationally demanding )
예를 들어 CIFAR-10 및 ImageNet을 위한 최첨단 아키텍처를 얻으려면 2000 GPU days의 강화 학습 또는 3150 GPU days가 소모되는 진화 알고리즘이 필요했습니다.
속도 향상을 위한 여러 방식의 접근이 제안되었지만, 근본적인 문제인 Scalability 는 남아있다.
속도 향상을 위한 기존 여러 접근
1. Imposing a Particular Structure of the Search Space
2. Weights or Performance Prediction for each individual architectures
An inherent cause of inefficiency for the dominant approaches is the fact that architecture search is treated as a black-box optimization problem over a discrete domain, which leads to a large number of architecture evaluations required.
e.g. based on RL, evolution, MCTS, SMBO or Bayesian optimization
본 논문은 다른 각도에서 문제에 접근하고, DARTS(Differentiable ARchiTecture Search)로 명명된 효율적인 아키텍쳐 검색 방법을 제안한다.
개별 아키텍쳐 후보군을 검색하는 대신, 검색 공간을 연속적으로 완화하여 아키텍쳐가 GD에 의한 유효성 검사셋 성능과 관련해 최적화 될 수 있도록 한다.
비효율적인 블랙박스 검색과 대조되는 그래디언트 기반 최적화의 데이터 효율성을 통해 DARTS는 훨씬 적은 계산 리소스를 사용하여 최신 기술로 경쟁력 있는 성능을 달성할 수 있습니다. 또한 ENAS보다 성능이 뛰어납니다.
특히 DARTS는 Controller, HyperNetworks 또는 Performance Predictor를 포함하지 않기에 기존 접근 방식보다 간단하지만 컨볼루션 아키텍처와 순환 아키텍처를 모두 처리할 수 있을 만큼 충분히 Generic하다.
Continuous Domain 내에서의 아키텍쳐 검색은 새로운 것은 아니지만 몇 주요 차이점이 있다.
이전 작업들이 filter shapes, Convolution Network의 branching patterns과 같은 아키텍쳐의 특정 측면에의 fine-tuning 이었지만,
DARTS는 Rich Search Space내에서의 복잡한 그래프 토폴로지 (complex graph topologies)를 사용하여 고성능 아키텍쳐 빌딩 블럭을 학습할 수 있다.
또한 DARTS는 특정 아키텍처 제품군에 국한되지 않으며 컨볼루션 및 순환 네트워크 모두에 적용할 수 있다.
본 논문 Sec3 실험에서 DARTS는 3.3M의 매개변수를 이용해 CIFAR-10에서 2.76 ± 0.09% 테스트 오류를 달성하는 컨볼루션 셀을 설계하였다.
which is competitive with the state-of-the-art result by regularized evolution obtained using three orders of magnitude more computation resources.
동일한 컨볼루션 셀도 ImageNet(Mobile Setting)으로 전송할 때 26.7%의 top-1 오류를 달성하며, 이는 최상의 RL 방법에 필적한다 (Zoph et al., 2018).
DARTS는 PTB(Penn Treebank)에서 55.7 테스트 복잡도를 달성하는 Recurrent Cell을 효율적으로 검색하여, Extensively tuned된 LSTM과 NAS 및 ENAS를 기반으로 하는 기존의 모든 Automatically Searched Cells를 능가했다.
Contributions Summarised
-
bi-level 최적화를 기반으로 미분 가능한 네트워크 아키텍처 검색을 위한 새로운 알고리즘을 소개한다. 본 알고리즘은 컨볼루션 아키텍처와 순환(Recurrent) 아키텍처 모두에 적용할 수 있다.
-
Image Classification 및 Language Modelling Task에 대한 광범위한 실험을 통해서 그라디언트 기반 아키텍처 검색이 CIFAR-10에서 매우 경쟁력 있는 결과를 달성하고 Penn TreeBank (이하 PTB)에서 최신 기술을 능가한다는 것을 보여준다.
이는 지금까지 최고의 아키텍처 검색 방법이 미분할 수 없는 검색 기술을 사용했다는 점을 고려하면 매우 흥미로운 결과다. e.g. RL 또는 진화 알고리즘 기반 -
미분할 수 없는 Search Technique과 대조적으로, 그래디언트 기반 최적화의 사용으로 인해 놀라운 효율성 향상을 달성했습니다.
- Reducing the cost of architecture discovery to a few GPU days
-
DARTS가 CIFAR-10 및 PTB에서 학습한 아키텍처를 각각 ImageNet 및 WikiText-2로 전이할 수 있음을 보여준다.
Differentiable Architecture Search
2.1: 아키텍처(또는 그 안의 셀)에 대한 계산 절차가 directed acyclic graph(방향성 비순환 그래프)로 표현되는 Search Space에 대한 일반적인 형태를 설명한다.
2.2: 아키텍처와 가중치의 joint optimization를 위한 미분 가능한 학습 목표로 이어지는 Search Space에 대한 simple continuous relaxation scheme을 도입한다.
2.3:알고리즘을 계산적으로 실현 가능하고 효율적으로 만들기 위한 approximation technique을 제안한다.
Search Space
본 논문에서는 최종 아키텍쳐의 빌딩 블록으로 computation cell을 찾는다. 학습된 셀은 stacked(누적)되어 Convolution Network 혹은 재귀적으로 연결되어 Recurrent Network를 형성할 수도 있다.
셀은 N개 노드의 Ordered Sequence 로 구성된 방향성 비순환 그래프이다. 각 노드 는 latent representation(잠재 표현)이고, 각 방향의 엣지 ()는 를 변환하는 일부 operation 과 연결된다.
셀에 두 개의 입력 노드와 단일 출력 노드가 있다고 가정할 때,
컨볼루션 셀의 경우 입력 노드는 이전 two layers의 셀 출력으로 정의된다.
순환 셀의 경우 현 단계의 입력과 이전 Step에서 가져온 state로 정의된다. 셀 출력은 all the intermediate nodes의 축소 연산 (e.g. concatenation)을 적용한다.
두 노드 간의 lack of connection을 나타내기 위해 특별한 zero operation도 포함된다. 따라서 셀을 학습하는 작업은 가장자리에서 작업을 학습하는 것으로 축소된다.
(The task of learning the cell therefore reduces to learning the operations on its edges.)
Continuous Relaxaion and Optimization
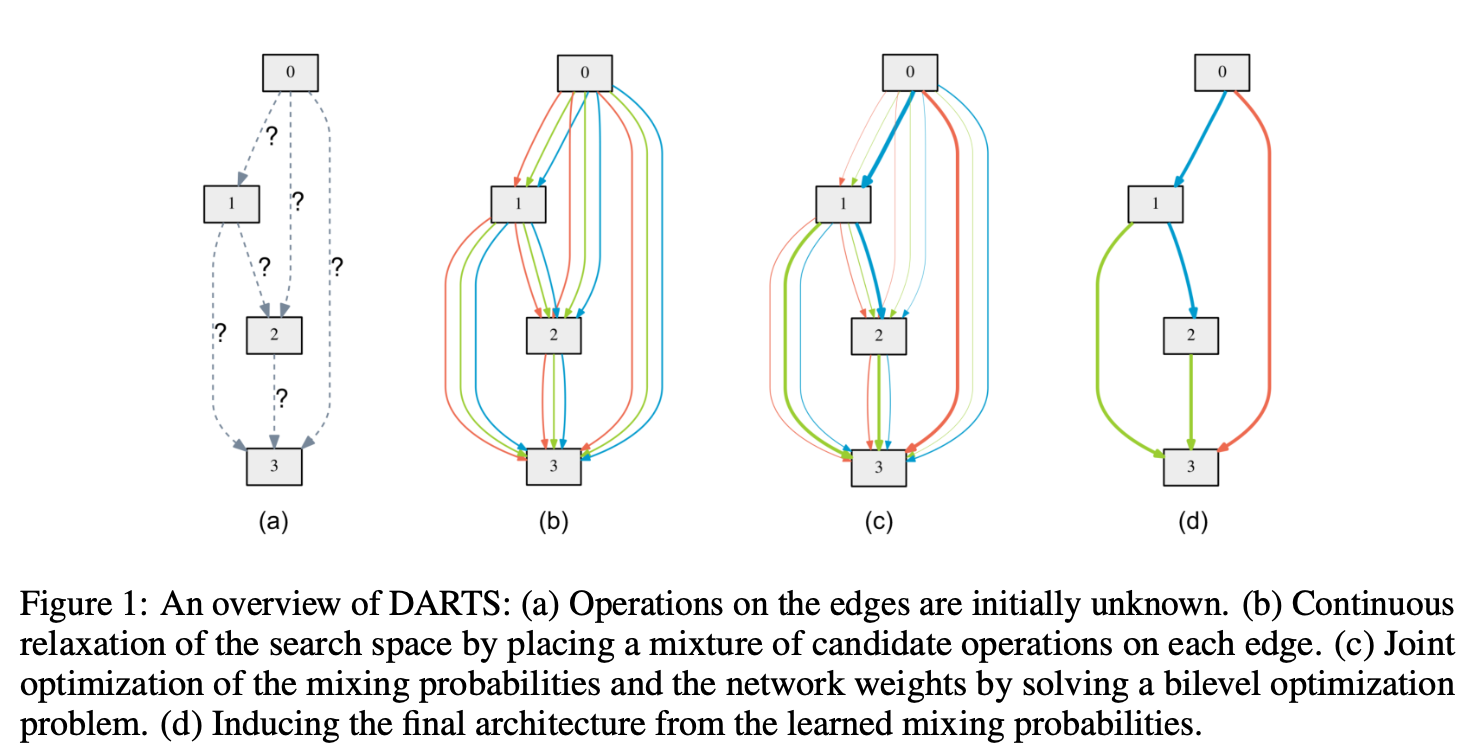
를 Operation 의 후보 집합이라고 두며 (e.g., convolution, max pooling, zero) 여기서의 각 연산은 에 적용할 일부 function 을 나타낸다.
Search space를 연속적으로 만들기 위해, 가능한 모든 작업에 대해 categorical choice of a particular operaion을 소프트맥스로 완화합니다.
노드 쌍의 가중치 mixing operation에서 차원의 벡터 로 매개변수화-parameterized 된다.
이후 아키텍쳐 서치 task는 fig1처럼 연속 변수(continuous variables) 집합을 학습하게끔 축소된다.
검색이 끝나면, 각 mixed operation 를 가장 가능성 있는 연산으로 대체하여 (i.e., ) Discrete Architecture를 얻을 수 있습니다. ( as the (encoding of the) architecture.)
After relaxation, 본 논문의 목표는 all the mixed operations (e.g. w8s of the convolution filters) 내에서 아키텍쳐 와 가중치 의 공동 학습이다.
validation set 성능이 보상이나 적합성이 되는 RL이나 진화 알고리즘을 사용한 아키텍쳐 서치와 유사하게 DARTS는 val loss 를 최적화 하지만, Gradient descent 사용을 목표로 한다.
, 로 훈련과 검증 손실을 나타낸다. 두 손실은 아키텍처 α와 네트워크의 가중치 w에 의해 결정된다.
아키텍처 검색의 목표는 검증 손실 을 최소화하는 를 찾는 것이다. 여기서 아키텍처와 관련된 가중치 는 학습 손실을 최소화 하여 얻는다.
이것은 α를 상위 수준 변수로, w를 하위 수준 변수로 사용하는 이중 수준 최적화 문제(Anandalingam & Friesz, 1992; Colson et al., 2007)를 의미한다.
nested formulation은 gradient-based 하이퍼파라미터 최적화에서도 발생한다. 이는 아키텍처 α가 학습률과 같은 스칼라 값 하이퍼파라미터보다 상당히 높지만 아키텍처 α가 하이퍼파라미터의 특수 유형으로 간주될 수 있다는 의미에서 관련이 있고 최적화하기가 더 어렵다.

Approximate Architecture Gradient
Architecture Gradient를 정확히 평가하는 것은 비용이 많이 드는 내부 최적화로 인해 금지될 수 있기에 본 논문에서는 다음과 같은 simple approximation scheme을 제안한다.
w: 알고리즘에 의해 유지되는 현재 가중치
ξ: 내부 최적화 단계에 대한 학습률
수렴할 때까지 훈련하여 내부 최적화(방정식 4)를 완전히 풀지 않고 단일 훈련 단계만 사용하여 w를 조정하여 w*(α)를 근사하는 것입니다.
관련 기술은 모델 전송(Finn et al., 2017), 기울기 기반 하이퍼파라미터 튜닝(Luketina et al., 2016) 및 풀린 생성적 적대 네트워크(Metz et al., 2017)를 위한 메타 학습에 사용되었습니다.
방정식 6은 w가 이미 내부 최적화에 대한 로컬 최적이고 따라서 인 경우 로 감소합니다.
The iterative procedure is outlined in Alg. 1.
현재 최적화 알고리즘에 대한 convergence guarantees을 알지 못하지만 실제로는 ξ를 적절하게 선택하여 fixed point에 도달할 수 있다.
또한 가중치 최적화를 위해 모멘텀이 활성화되면 방정식 6의 1단계 전개 학습 목표가 그에 따라 수정되고 모든 분석이 여전히 적용된다는 점에 주목합니다. ?
대략적인 아키텍처 기울기(방정식 6)에 chain rule을 적용하면
여기서 은 one-step forward model에 대한 가중치를 나타낸다. 위의 표현식은 두 번째 항에 expensive matrix-vector product을 포함한다.
다행히도 finite difference approximation를 사용하여 복잡성을 상당히 줄일 수 있다.
이 작은 스칼라 값이며
일 때,
finite difference를 평가하려면
w에 대한 2개의 forward passes와
α에 대한 2개의 backward passes만이 필요로 하며,
이로 인해 complexity은 O(|α||w|)에서 O(|α| + |w|)로 감소된다.
First-order Approximation
ξ = 0일 때, 방정식 7의 2차 도함수는 사라진다. 이 경우 아키텍처 기울기는 로 주어지며, 이는 현재 w가 w*(α)와 같다고 가정하여 검증 손실을 최적화하는 단순 heuristic에 해당합니다.
표 1과 2의 실험 결과에 따라 속도 향상을 가져오지만 경험적으로 더 나쁜 성능을 나타냅니다. 다음에서 우리는 ξ = 0의 경우를 1차 근사로 지칭하고, ξ > 0을 갖는 Gradient formulation을 2차 근사로 지칭한다.
Deriving Discrete Architectures
개별 아키텍처에서 각 노드를 형성하기 위해,
이전의 모든 노드에서 수집된 all non-zero candidate operations 중에서 상위 k개의 가장 강력한 작업(개별 노드의)을 유지합니다. The strength of an operation는 로 정의된다.
Derived(파생된) 아키텍처를 기존 작업의 아키텍처와 비교할 수 있도록 컨볼루션 셀에 대해 k = 2를 사용하고 순환 셀에 대해 k = 1을 사용한다.
zero operations은 두 가지 이유로 위의 항목에서 제외한다.
1. 기존 모델과의 공정한 비교를 위해 노드 당 정확히 k개의 0이 아닌 들어오는 엣지가 필요하다.
2. 제로 연산의 logits을 증가시키면 결과 노드 표현의 규모에만 영향을 미치고 배치 정규화의 존재로 인해 최종 분류 결과에 영향을 미치지 않기 때문에 제로 연산의 강도가 과소 결정된다.
Experiments and Results
CIFAR-10 및 PTB에 대한 본 논문의 실험은 Architecture Search(Sec 3.1)과 Evaluation(Sec 3.2)의 두 단계로 구성된다.
첫 번째 단계에서는 DARTS를 사용하여 셀 아키텍처를 검색하고, 검증 성능을 기반으로 최상의 셀을 결정한다.
두 번째 단계에서는 이러한 셀을 사용해 더 큰 아키텍처를 구성하고 처음부터 훈련하고 테스트셋에서의 성능을 확인한다. 또한 ImageNet 및 WikiText-2(WT2)에서 각각 평가하여 CIFAR-10 및 PTB에서 학습한 최상의 셀의 Transferability을 조사한다.
Architecture Search
Searching For Convolutional Cells on CIFAR-10
에 포함되는 Ops
- 3 × 3 및 5 × 5 separable convolution
- 3 × 3 및 5 × 5 dilated separable convolution
- 3 × 3 max pooling
- 3 × 3 Average pooling
- identity 및
- 0
모든 작업은 Stride = 1(if applicable)이며, Spatial Resolution를 유지하기 위해 컨볼루션 피쳐 맵이 채워집니다. 우리는 ReLU-Conv-BN 순서를 convolutional 연산에 사용하며, each separable convolution은 항상 두 번 적용된다.
본 논문에서의 컨볼루션 셀은 N = 7개의 노드로 구성되며, 그 중 출력 노드는 모든 중간 노드의 depthwise concatenation로 정의된다 (입력 노드 제외). 나머지 설정은 Zoph et al.을 따릅니다. (2018); Liu et al. (2018a); Realet al. (2018), 여기에서 네트워크는 여러 셀을 함께 쌓아서 형성된다.
셀 k의 첫 번째 노드와 두 번째 노드는 각각 셀 k - 2 및 셀 k - 1의 출력과 동일하게 설정하고, 필요에 따라 1 × 1 컨볼루션을 삽입한다. 네트워크 전체 깊이의 1/3과 2/3에 위치한 셀은 입력 노드에 인접한 모든 연산이 stride 2인 reduction cell 이다. 따라서 아키텍처 인코딩은 (, )이며, 여기서 은 모든 normal cells에서 공유되고 는 모든 reduction cells 에서 공유된다.
Searching for Recurrent Cells on PTB
set of available ops 에는 linear transformations와 tanh, relu, sigmoid activations, identity mapping 및 zero op 중 하나가 포함된다.
Recurrent cell은 N = 12개의 노드로 구성된다.
가장 첫 번째 중간 노드는 두 개의 입력 노드를 선형으로 변환하고 결과를 합산한 다음 ENAS 셀에서 수행된 것처럼 tanh activation functions를 통해 얻는다(Pham et al., 2018b).
The rest of the cell is learned.
다른 설정은 ENAS와 유사하며, 각 작업은 highway bypass로 향상되고(Zilly et al., 2016) 셀 출력은 모든 중간 노드의 평균으로 정의됩니다.
ENAS에서와 같이 각 노드에서 배치 정규화를 활성화하여 architecture search 중 gradient explosion을 방지하고, architecture evaluation 중에는 비활성화 한다.
Recurrent Network는 단일 셀로만 구성됩니다. 즉, Recurrent Architecture 내에서 Repetitve Patterns을 가정하지 않는다.
Architecture Evaluation
Final Evaluation를 위한 아키텍처를 결정하기 위해서 DARTS를 다른 random seeds로 4번 실행하고,
짧은 기간동안 처음부터 학습하여 얻은 검증 성능을 기반으로 최상의 셀을 선택한다. (CIFAR-10에서 100 epoch 및 PTB에서 300 epoch)
이는 최적화 결과가 initialization-sensitive할 수 있기 때문에 recurrent cells에 특히 중요하다(Fig 3).
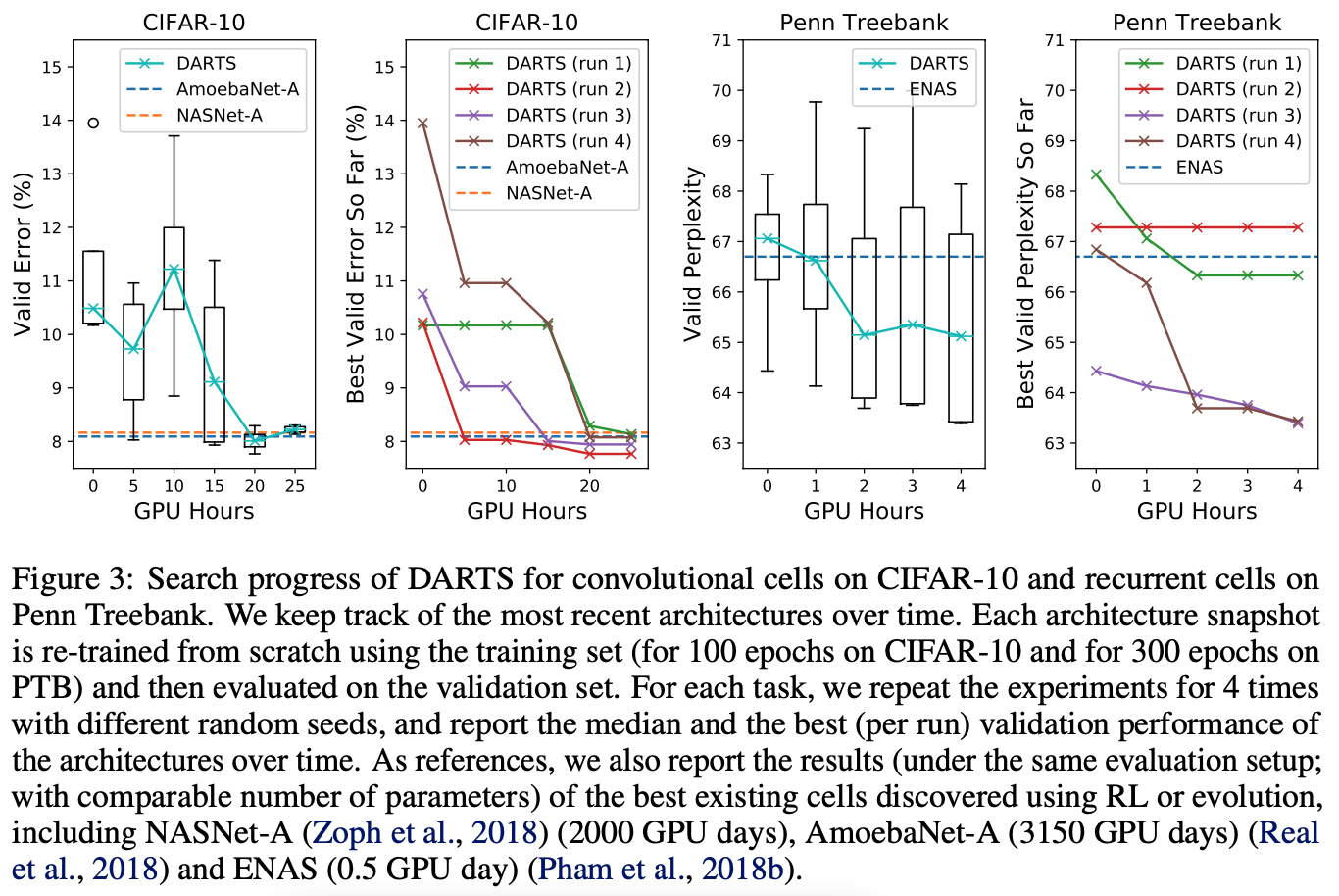
선택한 아키텍처를 평가하기 위해 w8s를 무작위로 초기화하고(검색 프로세스 중에 학습된 가중치는 폐기됨), 처음부터 학습하고, 테스트 세트에서 성능을 보고한다.
(테스트 세트는 아키텍처 Search or Selection에 사용되지 않은 데이터.)
More details (Sec. A.2.1 및 A.2.2.)
CIFAR-10 및 PTB 외에도 ImageNet(mobile setting) 및 WikiText-2에서 각각 평가하여 최상의 컨볼루션 셀(CIFAR-10에서 검색) 및 순환 셀(PTB에서 검색)의 Transferability을 추가로 조사했습니다.
More details (Sec. A.2.3 및 A.2.4.)
Results Analysis
The CIFAR-10 Results for Convolutional Architectures
특히 DARTS는 3배 적은 계산 리소스를 사용하면서 최신 기술(Zoph et al., 2018; Real et al., 2018)과 유사한 결과를 달성했다.
i.e. 1.5 or 4 GPU days vs 2000 GPU days for NASNet and 3150 GPU days for AmoebaNet
또한 Search Time이 약간 더 길면서 DARTS는 error rate은 비슷하지만 parameters가 적은 셀을 발견하여 ENAS를 능가했다(Pham et al., 2018b).
Search Time이 긴 것은 셀 선택을 위해 검색 과정을 4번 반복했기 때문이지만, 발견된 아키텍처의 성능이 초기화에 크게 의존하지 않기 때문에 이 방법은 컨볼루션 셀에서는 덜 중요하다(Fig 3).
This practice is less important for convolutional cells however, because the performance of discovered architectures does not strongly depend on initialization.
Alternative Optimization Strategies
bilevel optimization의 필요성을 더 잘 이해하기 위해, coordinate descent을 사용하여 traning 및 validations set의 합집합에 대해 α 및 w가 Jointly Optimized되는 단순 검색 전략을 조사했다.
결과로 나온 최상의 컨볼루션 셀(4개 실행 중)은 3.1M parameters를 사용하여 4.16 ± 0.16% 테스트 오류를 생성했으며 이는 Random search 보다 나쁘다.
두 번째 실험에서는 사용 가능한 모든 데이터(traning + validation)에 대해 SGD를 사용하여 w(without alteration)와 동시에 α를 최적화했다.
결과로 나온 최상의 셀은 3.0M 매개변수를 사용하여 3.56 ± 0.10% 테스트 오류를 생성했다.
우리는 이러한 휴리스틱으로 인해 α(analogous to byperparameters)가 훈련 데이터에 과적합되어 일반화가 제대로 이루어지지 않았을 것이라는 가설을 설립했다.
Note that α is not directly optimized on the training set in DARTS.
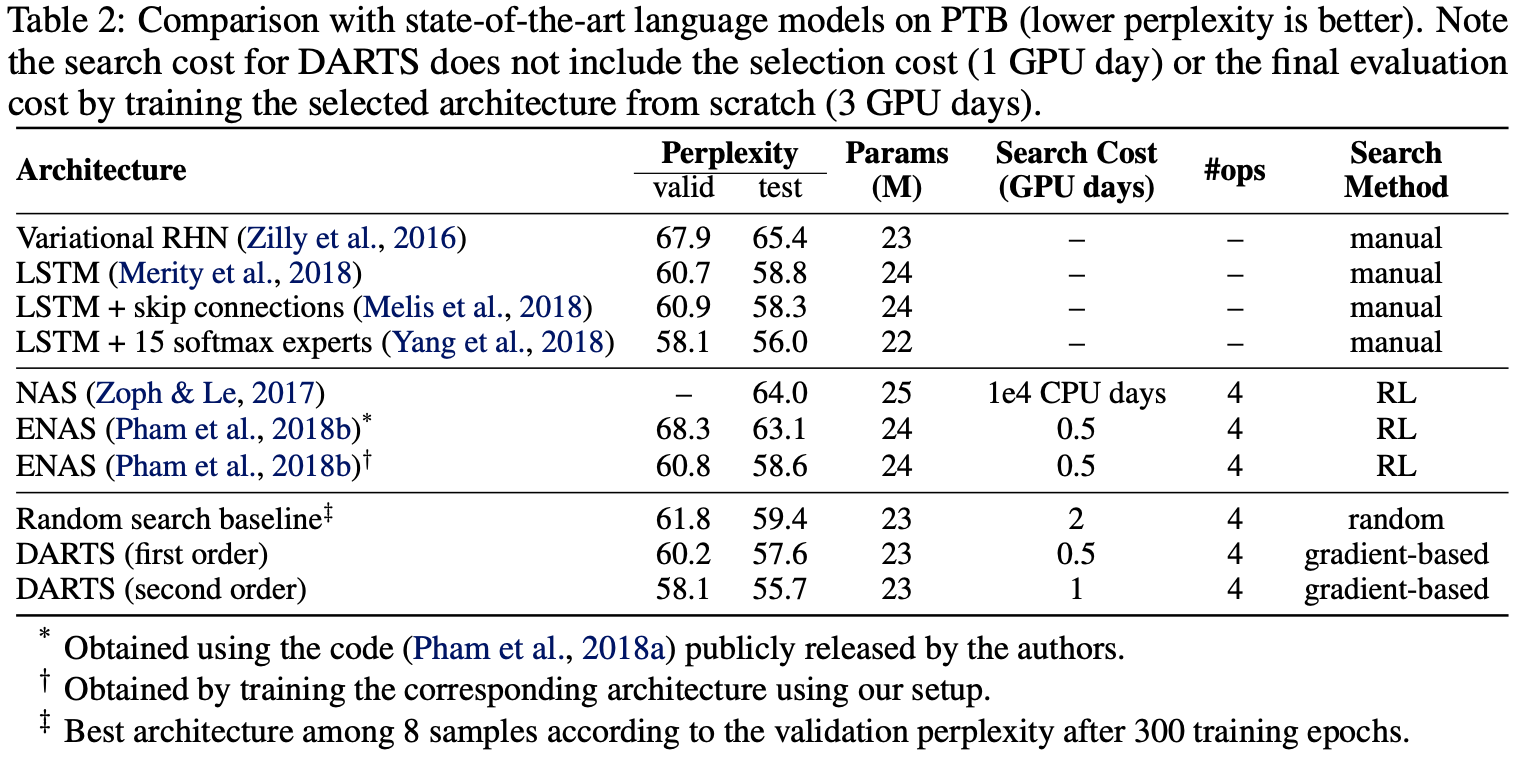
Table 2 presents the results for recurrent architectures on PTB, where a cell discovered by DARTS achieved the test perplexity of 55.7.
이는 mixture of softmaxes 으로 강화된 SOTA 모델과 동등하며, manually 또는 automatically로 발견되는 다른 아키텍처보다 우수하다.
본 논문에서의 automatically searched cell은 extensively tuned LSTM보다 성능이 우수하며, 하이퍼파라미터 검색 외에 아키텍처 검색의 중요성을 보여준다.
In terms of efficiency, 전체 비용(총 4회 실행)은 1 GPU day 이내로 ENAS와 비슷하고 NAS보다 훨씬 빠릅니다.
Random search는 Search Space Design의 중요성을 반영하는 컨볼루션 모델과 순환 모델 모두에서 경쟁력이 있다는 점을 확인했다.
그럼에도 불구하고, 비슷하거나 더 적은 검색 비용으로 DARTS는 두 경우 모두에서 무작위 검색보다 significantly improve할 수 있다.
(2.76 ± 0.09 vs 3.29 ± 0.15 on CIFAR-10; 55.7 vs 59.4 on PTB).
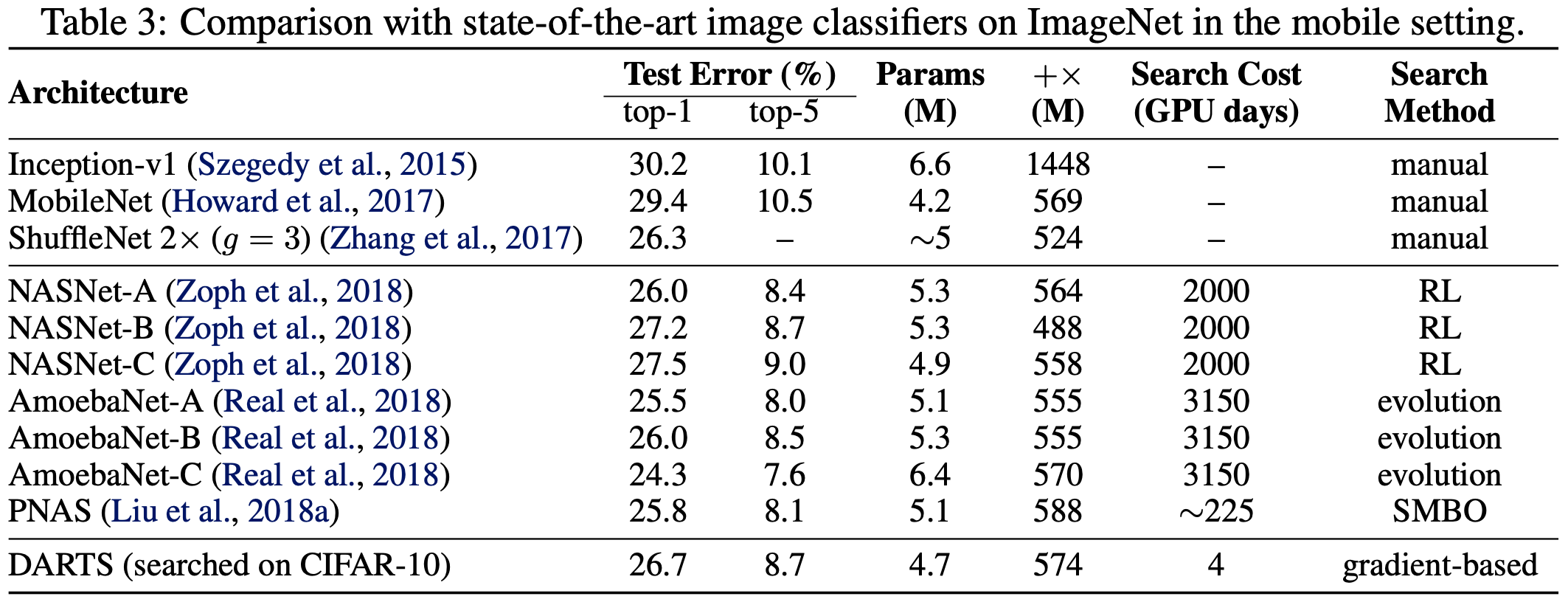
Table 3의 결과는 CIFAR-10에서 학습된 셀이 실제로 ImageNet으로 전송될 수 있음을 보여준다.
DARTS가 최첨단 RL 방법보다 경쟁력 있는 성능을 달성하면서도 계산 리소스를 1000배 적게 사용한다는 점은 주목할 가치가 있다.
(three orders of magnitude less computation resources.)
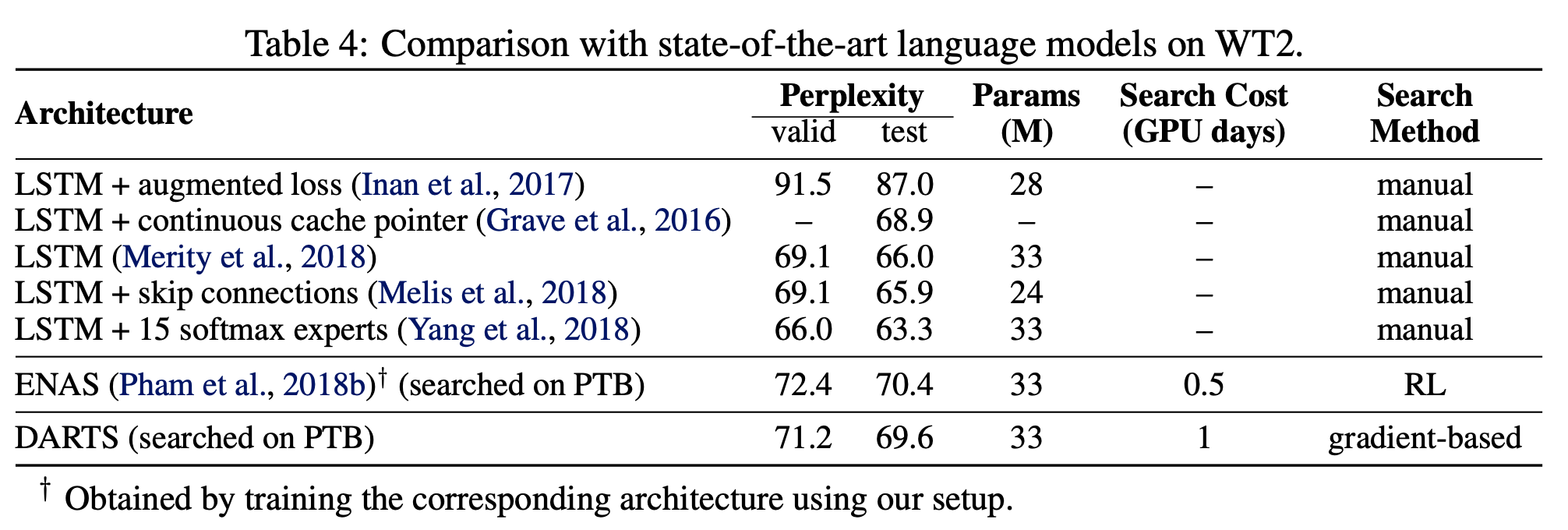
Table 4는 전체 결과가 PTB에 대해 Table 2에 제시된 것보다 덜 강력하지만, cell(identified by DARTS)이 ENAS보다 WT2로 더 잘 전이됨을 보여준다.
CIFAR-10과 ImageNet에 비해 PTB와 WT2 사이의 weaker transferability는 Architecture Search을 위한 소스 데이터 세트(PTB)의 크기가 상대적으로 작기에 이런 결과가 나올 수 있다.
The issue of Transferability는 Task of Interest에서 아키텍처를 직접 최적화하여 잠재적으로 우회할 수 있다.
Conclusion
본 논문은 Convolution과 Recurrent Network를 위한 간단하면서도 효율적인 아키텍처 검색 알고리즘인 DARTS를 제시한다.
By Searching in a continuous space, DARTS는 이미지 분류 및 언어 모델링 작업에 대한 SOTA Non-differentiable Architecture Search Methods와 일치하거나 몇 배의 놀라운 효율성 향상으로 성능을 능가할 수 있다다.
DARTS를 더욱 개선하기 위한 흥미로운 방향이 많이 있다.
예를 들어, 현재 방법은 continuous 아키텍처 인코딩과 derived discrete 아키텍처 간의 불일치로 인해 어려움을 겪을 수 있다.
이는 예를 들어 softmax temperature(with a suitable schedule)를 annealing하여 one-hot selection을 시행함으로써 완화될 수 있다.
Search Process 동안 학습된 one-shot model을 기반으로 하는 Performance-aware Architecture derivation schemes를 탐색하는 것도 흥미로울 것이다.
