실험 및 결과는 적지 않았습니다
Architecture Search based on Reinforcement Learning
RL 기반 방법론들은 validation accuracy 를 reward 로 보고, 네트워크의 각 파트들을 action 으로 본다. 여러번의 action 을 통해 네트워크를 정의하고 나면 학습을 통해 reward 를 얻을 수 있으며, 이 값으로 action 을 생성하는 policy 를 학습한다. State 는 각 시점까지 완성된 네트워크의 구조라고 할 수 있으나, 이를 명시적으로 사용하지 않고 policy 를 RNN 으로 디자인함으로써 implicit 하게 가져간다. 이러한 policy RNN 을 controller 라고 하며, 컨트롤러가 생성한 네트워크의 구조를 child network 라 부른다.
NASNet: Learning Transferable Architectures for Scalable Image Recognition
RNN: Recurrent Neural Network
💡 Cell이란?
Hidden layer에서 activation function을 통해 결과를 내보내는 노드
이전 값을 기억하는 메모리 역할을 하기에 메모리 셀 (or RNN 셀) 이라고도 명명된다.
순환신경망(RNN)은 Skip Connection을 사용하여 F(x) -> H(x)가 아닌 F(x) -> F(x) + x 로 결과를 내뱉는다. 이는 w8 layer를 통해 나온 결과 x와 이전 결과 F(x)를 더해 출력한다는 의미이다. ( 재귀적 활동 )
RNN은 입력과 출력의 길이를 다르게 설계 할 수 있다. 그러므로 입출력의 길이에 따라 RNN의 형태가 달라진다.
Controller RNN
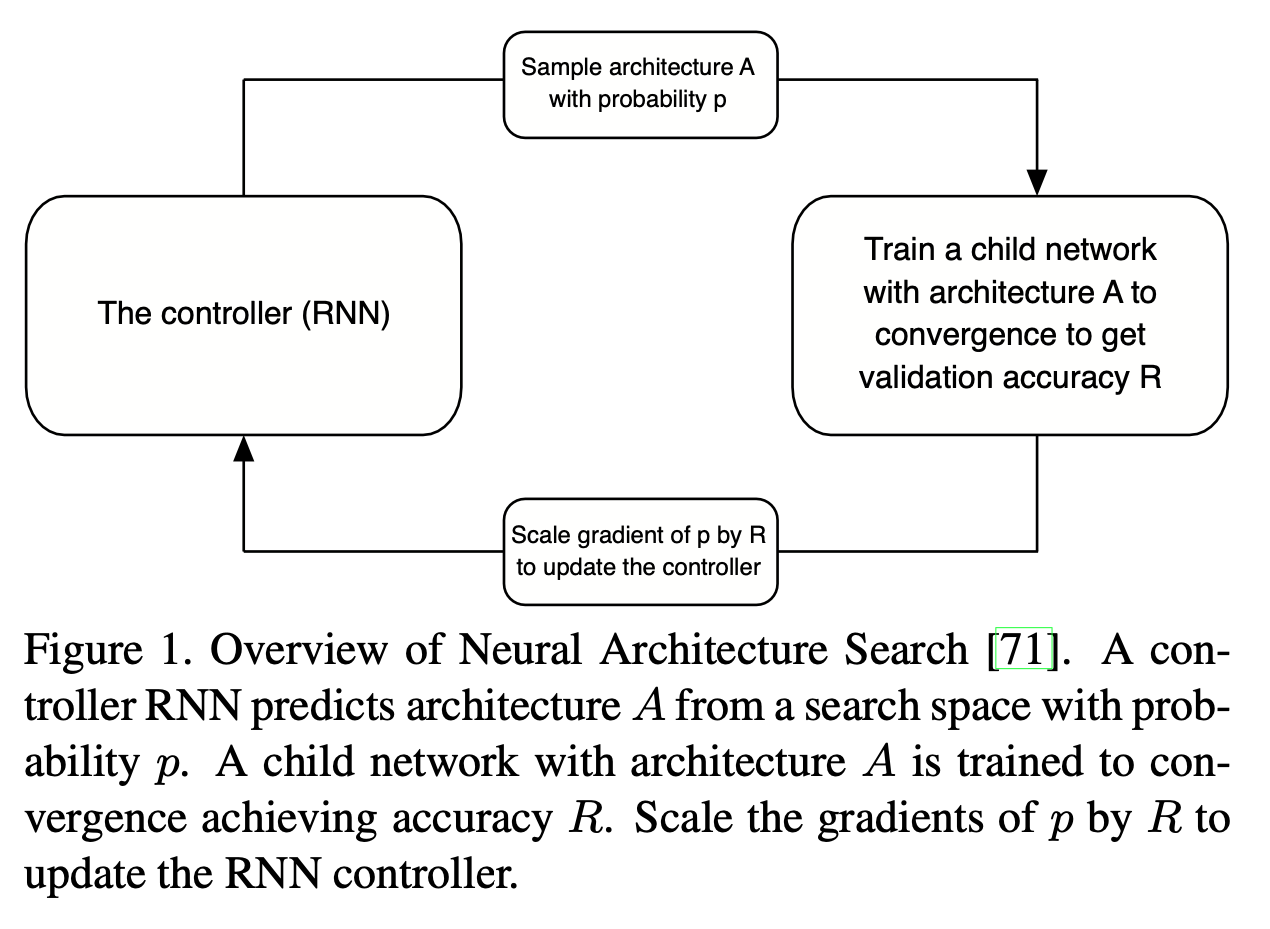
Architecture를 결정하는 요소를 예측하는 Controller RNN(RL: Agent)은
Validation Accuracy를 Reward로 하여 RNN Controller 를 학습시킨다.
이 과정을 반복하여 controller는 향상된 구조를 생성할 수 있게 학습된다.
NAS

https://arxiv.org/abs/1611.01578
Dimension
Search Space
알고리즘이 탐색을 수행하는 공간
Search Space의 모든 원소는 유효한 네트워크 구조를 가진다.
최소 구성 단위 정의: 하기한 원소로 구성된 ops의 조합으로 생성된다.
Primitive Operations
1. Convolution
2. Pooling
3. Concatenation
4. Element-wise addition
5. Skip Connection
원소가 정의되면 Search Space의 크기로 4가지 분류 방법을 정의내릴 수 있다.
- Search Space Perspective
- Entire Structure Search
- Cell-Based Structure Search
- Hierarchical Structure Search
- Network Morphism based Structure Search
Search Strategy
Search Strategy는 Search Space의 정의와 목표에 따라서 여러 방법으로 나뉜다.
또한 Strategy를 구상할 때는 Exploration-Exploitation Trade-off 관계를 반드시 유념해야 한다.
Exploration: 전반적인 공간 탐색
Exploitation: 좋은 지점 개척
Performance Esimation Strategy
TBU.
Desc.
딥러닝 네트워크 구조 자동 탐색 방식을 Neural Architecture Search (NAS)라고 한다.
- NAS Dimension은 Search Space, Search Strategy, Performance Estimation Strategy로 나뉜다.
본 논문은 강화학습을 이용한 NN 구조 탐색 방법을 소개한다. 이번 포스트의 주제가 되는 NASNet이나 다른 AutoML 연구에 초석이 되는 논문이다.
NAS는 모델 구조 전체를 search space 로 설정하며 validation loss 등을 objective function 으로 갖는다.
즉, Search Space를 탐색 후 objective function 최적화를 목적으로 한다.
We use a recurrent network to generate the model descriptions of neural networks and train this RNN with reinforcement learning to maximize the expected accuracy of the generated architectures on a validation set. On the CIFAR-10 dataset
RNN Controller는 각 layer를 탐색하며 구체적으로 architecture 를 구성하며 ( output: Variable-length string), 이를 타겟 데이터셋 ( CIFAR-10 )으로 학습 시킨다. Agent는 Validation Accuracy 기댓값이 최대화되도록 parameter 를 최적화 한다.
최종적으로는 성능 측정을 하여 (Validation Acc, loss etc. ) 이를 Agent의 Reward 화 시킨다. 서술한 사이클은 하나의 Episode로 취급된다.
각각의 layer를 탐색하여 결과를 도출하므로 각 layer는 다른 convolution filter를 가진다. 이는 모든 layer는 동일하지 않은 구조라는 뜻이다.
해당 논문에서는 800개의 GPU을 사용하여 28일 동안 진행하였다.
이는 하나의 episode에 많은 시간이 소요되었다는 걸 알 수 있고, 학습에 필요한 시간 및 자원의 한계점을 명확히 보였다.
NASNet
NASNet은 NAS의 후행 연구로써 기존 NAS 방법은 유지하면서 새로운 Search Space를 찾는다. Normal / Reduction Cell로 명명된 구조를 예측한 후, 이 cells를 반복적으로 쌓아 Network를 구성한다.
하여 선행 연구에 비해 탐색 공간이 줄어들어 시간 및 비용이 크게 감소하였다.
(단, NASNet은 CNN만을 한정하여 NAS를 효과적으로 디자인하는 것을 제안하였다.)
본 논문에서는 선행연구인 NAS와 같이 전체 Network를 탐색하지 않고, Convolution Cell을 탐색하며, 해당 Cell의 조합으로 Architecture를 설계한다.
NAS와 동일하게 Controller RNN을 Agent로 모델 구조를 찾는다.
이후 Accuracy가 R에 수렴할 때까지 학습을 진행한다.
Policy Gradient를 사용하여 Agent의 가중치를 업데이트 한다.
Policy Gradient: 정책 경사
Policy: State에 대한 Action의 조건부확률
경사하강법 (Gradient Descent) 를 이용하여 Policy 함수를 학습하는 방법이며, Policy를 구성하는 Parameter를 Control하여 Reward를 최대화하는 방향으로 구현된다.
Objective Functiond의 Gradient를 따라서 Parameter를 조금씩 변경해가면서 정책을 업데이트 한다.
PPO: Proximal Policy Optimization
TBU.
Block
5 Prediction Steps
- Step 1. Select a hidden state from , ( OR from the set of hidden states created in previous block. - hidden state 선택
- Step 2. Select a second hidden state from the same options as in Step 1 - step1과 동일하게 두 번째 hidden state 선택
- Step 3. Select an Operation to apply to the hidden state selected in Step 1 - step1에 선택된 hidden state에 적용할 연산 선택
- Step 4. Select an Operation to apply to the hidden state selected in Step 2 - step2에 선택된 hidden state에 적용할 연산 선택
- Step 5. Select a method to combine the outputs of Step 3, 4 to create a new hidden state - 3, 4의 출력값을 결합할 방법 선택 ({Element-wise Addition|Concatenation})
➡️ Result: 1 Block
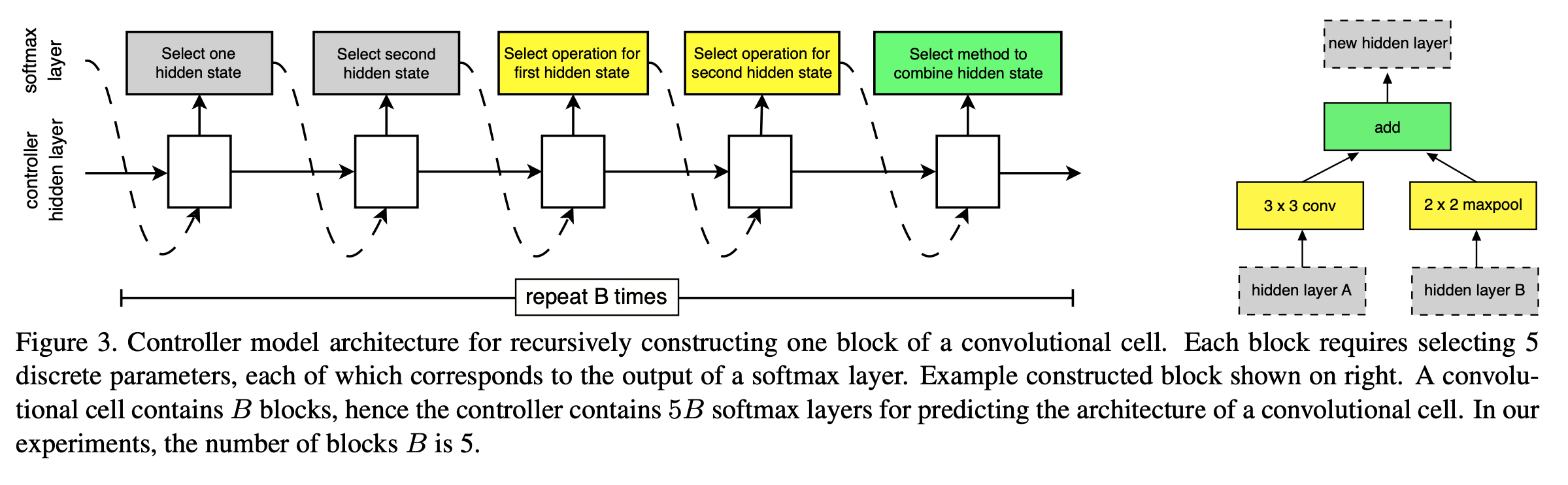
Controller RNN은 초기 hidden state가 주어지면 이후 Convolution cell 구조를 재귀적으로 예측한다.
하나의 Cell은 B개의 block으로 구성된다.
각 Block은 2개의 hidden layer를 받고 이에 Operations을 적용하며, 이후 결과를 {Element-wise Addition|Concatenation}한다.
hidden layer 2개, Operation 2개, Combine Method 1개 -> 총 5개의 hyperparameter가 하나의 Block으로 정의된다.
본 과정은 하나의 Block 생성 과정이며, 5번 반복을 통해 하나의 Cell을 생성한다
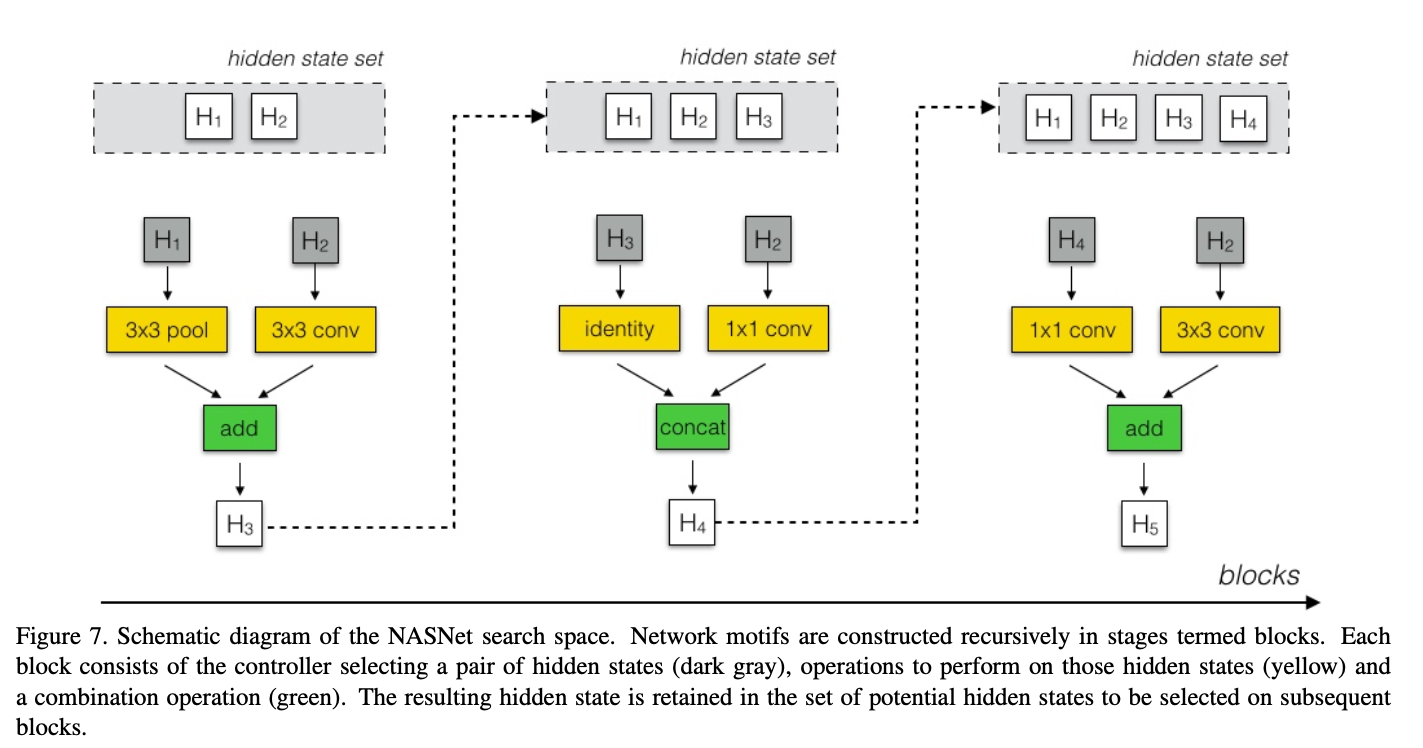
Set of Ops

Convolutional Cells
NASNet-A
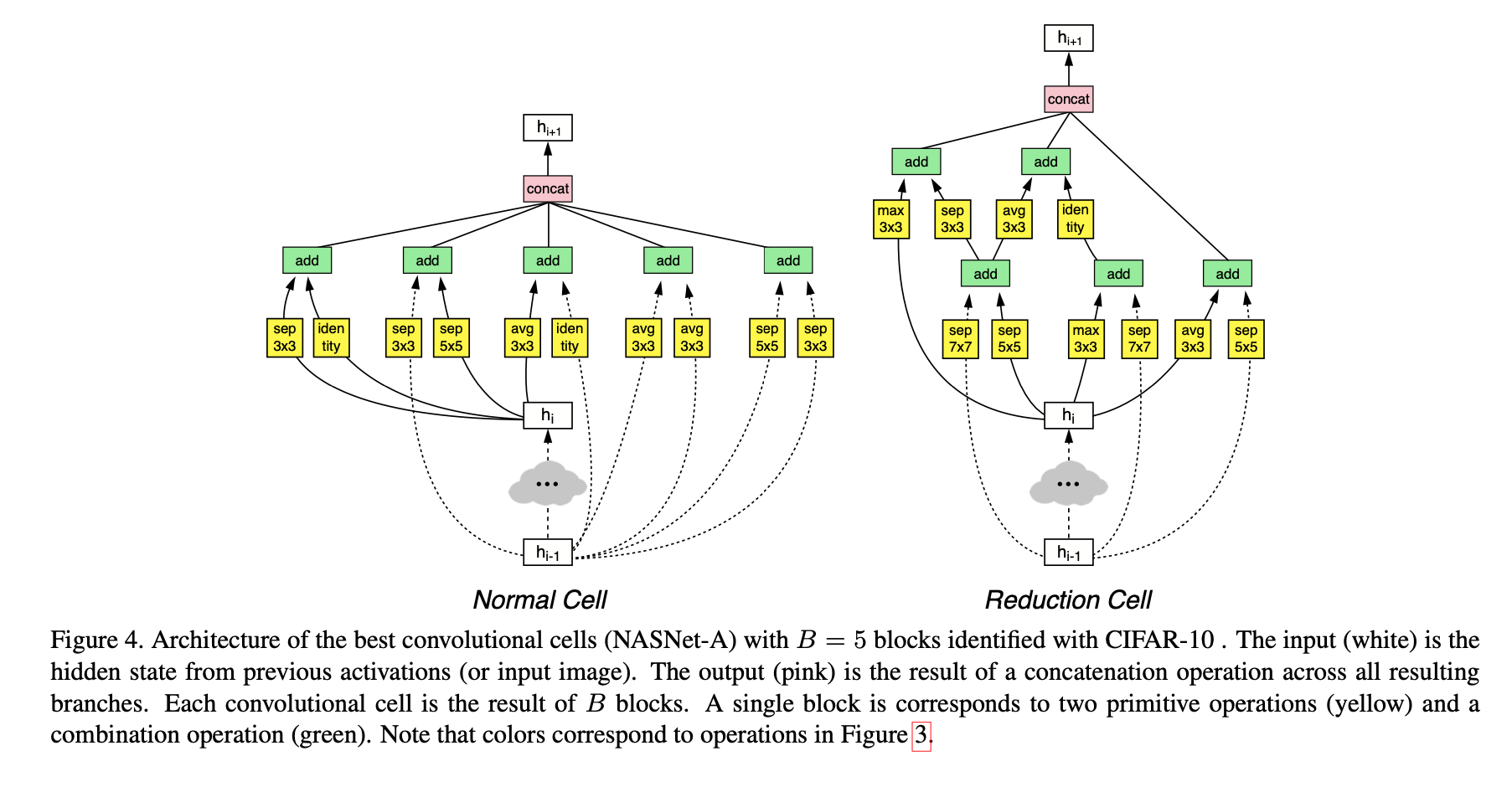
Normal Cell
in/output의 width, h8의 크기가 (dimension) 동일한 feature map을 생성하는 Convolution cell
Stride 값은 항상 1을 가진다.
Reduction Cell
output의 dimenstion이 input의 1/2인 feature map을 생성하는 Convolution cell
Stride 값은 {1|2}를 가진다.
Stride값이 1인 경우는 해당 block의 input값으로 (같은 cell의 다른 block의 output을 사용하는 경우 ) 이다.
최종적으로 RNN Controller는 Block 개를 생성한다. (Normal / Reduction)
Architecture
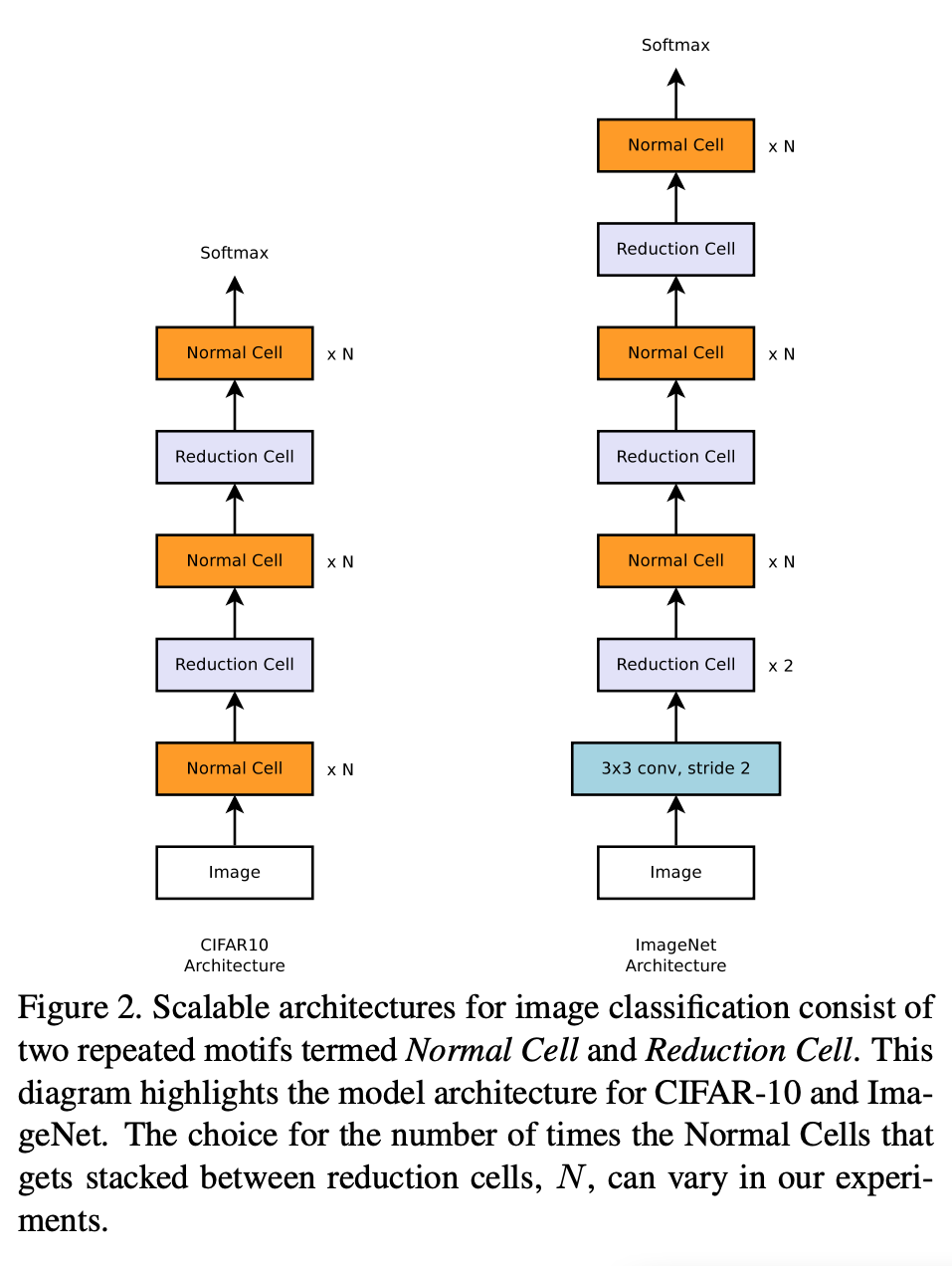
NASNet은 전체 Architecture가 미리 정의되어 있다.
Normal 및 Reduction Cell은 정의되어있지 않으며 강화학습으로 정의된다.
Summary
작은 데이터셋에서 architectural building blocks를 찾고, 더 큰 데이터셋에 전이하도록 한다. 본 논문에서는 CIFAR-10에서 최상위 컨볼루션을 검색한 후 ImageNet에 적용했다.
Normal Cell의 반복 횟수 N은 실험으로 찾을 수 있다.
Reduction Cell과 Normal Cell은 동일한 아키텍쳐를 가질 수 있지만, 경험적으로 개별 아키텍처로 나뉘는 게 이점이 있다는 걸 찾았다.
일정한 hidden state dimension을 유지하기 위해 Spatial activation size가 줄어들 때마다 출력의 필터 수를 두 배로 늘리는 방법을 사용한다.
각 Cell에 대한 Controller RNN의 예측은 B개의 블록의 그룹이며, 블록의 모든 요소는 softmax layer를 거친다.
Controller RNN 알고리즘은 새로 생성된 hidden state는 기존 hidden state 셋에 잠재적 입력으로 추가된다.
또한 RNN에 의해 제어되는 child network pool을 생성하기 위한 global workqueue system을 사용해 PPO 알고리즘으로 학습된다.
Conv Cell 학습 후 (1)셀 반복 수-N와 (2) 초기 필터 수를 탐색하며 최종 네트워크를 구축을 위한 작업을 진행한다.
