엄청 러프하게 적어 앞뒤가 안 맞을 수 있음
데이터독 소개
누구나 언제 어디에든 사용할 수 있는 observability 및 보안 플랫폼
많은 데이터를 수집, 분석해 트러블 슈팅을 돕는다. 여러 데이터를 연계해 분석하여 효과적으로 모니터링이 가능하다.
19년부터 ux > 보안까지 확장해나가고 있으며, 시스템 가시성 및 보안까지 커버가 가능하다.
Datadog에서 지원하는 FE 모니터링
1. js
2. android
3. ios
4. react native
5. flutter
6. android tv
7. tvOS
k8s 트렌드
조사 대상의 96%가 k8s 이용, 검토중이라고 하며 79%가 k8s기반 플랫폼 서비스를 이용한다고 밝혔다. 또한 k8s 유저의 90% cloud-managed service 이용 중이었다
- CNCF Annual survey
컨테이너 환경 및 k8s 사용의 지속적 증가 및 다양한 기술 스택 이용으로 모니터링 협업의 비용 증가
k8s 모니터링 best practice w/ Datadog
전통적 모니터링 방식으로는 모니터링이 불가능해짐
k8s 라이프사이클은 동적이다. 평균적으로 3일 이내 소멸/재생성 된다. 하여 모든 메트릭과 로그를 저장 후 노이즈를 제거한다. 사용자 중심의 서비스 단위 모니터링이 필요한다. SRE 관점에서 의미없는 알림을 받지 않도록 최소화해야한다. 이후 장애분석을 원할히 해야한다.
k8s 모니터링의 어려움
- 복잡한 리소스 모니터링
- 수많은 익스포터로 인한 유지보수 비용 증가
- 로그 중앙화 플랫폼 구축 및 유지 보수
- k8s은 필수. 환경이 커지면 유지보수 비용 증가. 로그 유실 방지 대첵을 세워야 함. 자체 구축보다 호스트방식의 pod을 권장한다.
- 복잡해진 분산 트랜잭션 모니터링
- k8s 도입으로 복잡성이 증가하였음.
오픈소스의 도입은 유지보수 등이 어려움. (업데이트, 스토리지 유지 등)
모니터링을 위한 리소스 비용도 무시할 수 없는 금액임.
k8s 모니터링을 보다 쉽게
saas방식으로 모든 부분을 통합하고 구축, 유지보수가 필요 없음.
기본적으로 k8s 환경의 obserbility 를 제공한다.
Demo
k8s 다양한 리소스 현황 파악 가능
특정 팟에 대한 현황 매니페스트, 리소스, 발생 로그, 연관된 트레이스를 확인 할 수 있음.
APM 연동이 가능하며, 여기서는 하나의 req에 대한 트레이스가 나오고, 이에 종속된 span도 확인할 수 있음
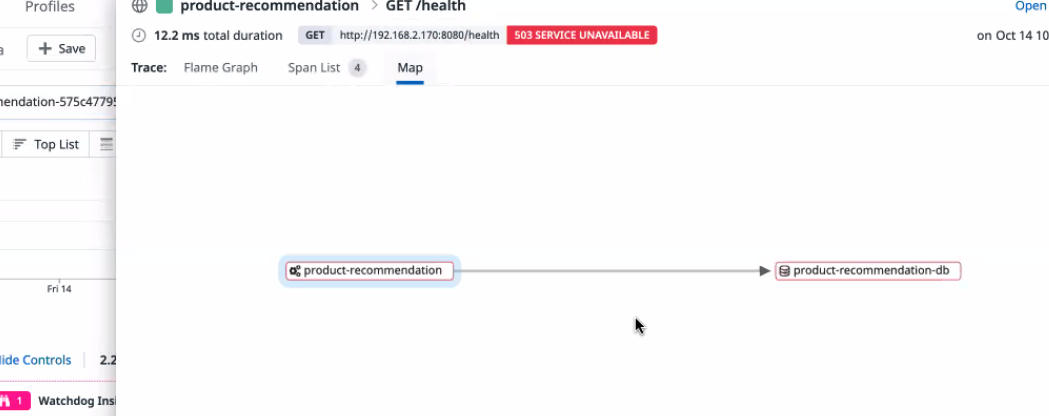
리퀘스트에 따라 서비스의 실행 시간도 확인이 가능 -> 로그로 즉각적 이동도 가능
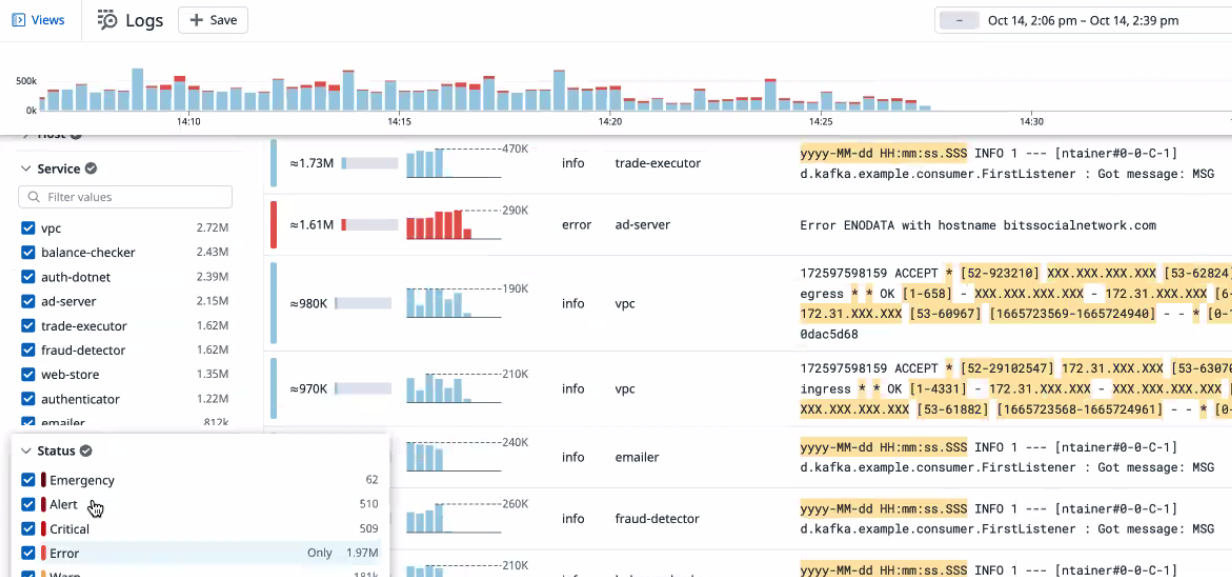
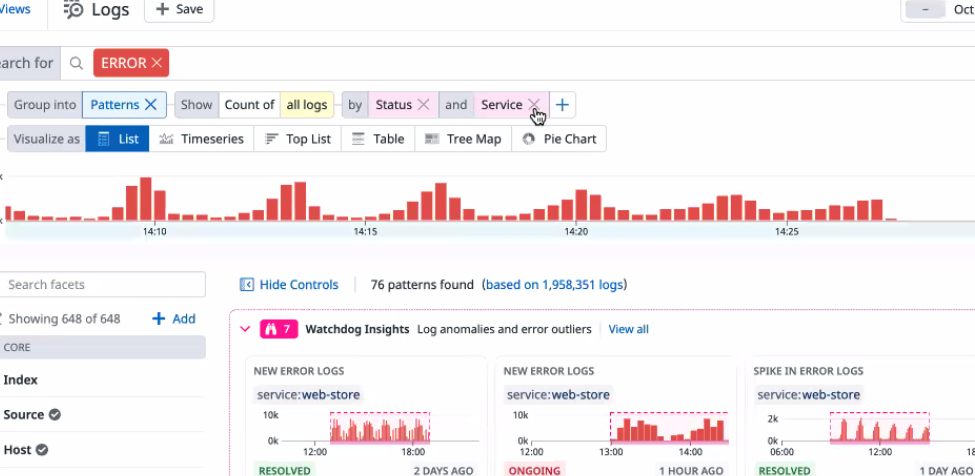
또한 로그의 패턴화가 가능하다. 가장 이슈가 되는 부분부터 개선해나갈 사항을 확인할 수 있다.
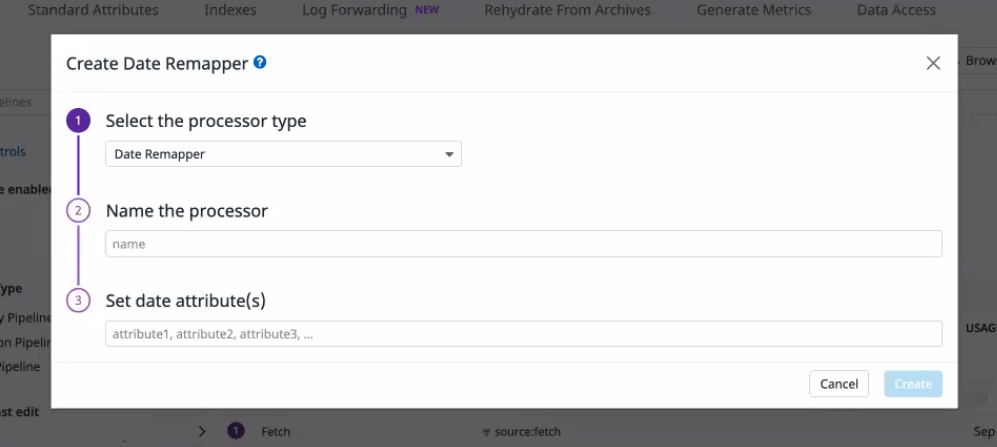
로그 표준화를 위한 전처리 부분을 파이프라인을 통해 일원화 할 수 있다.
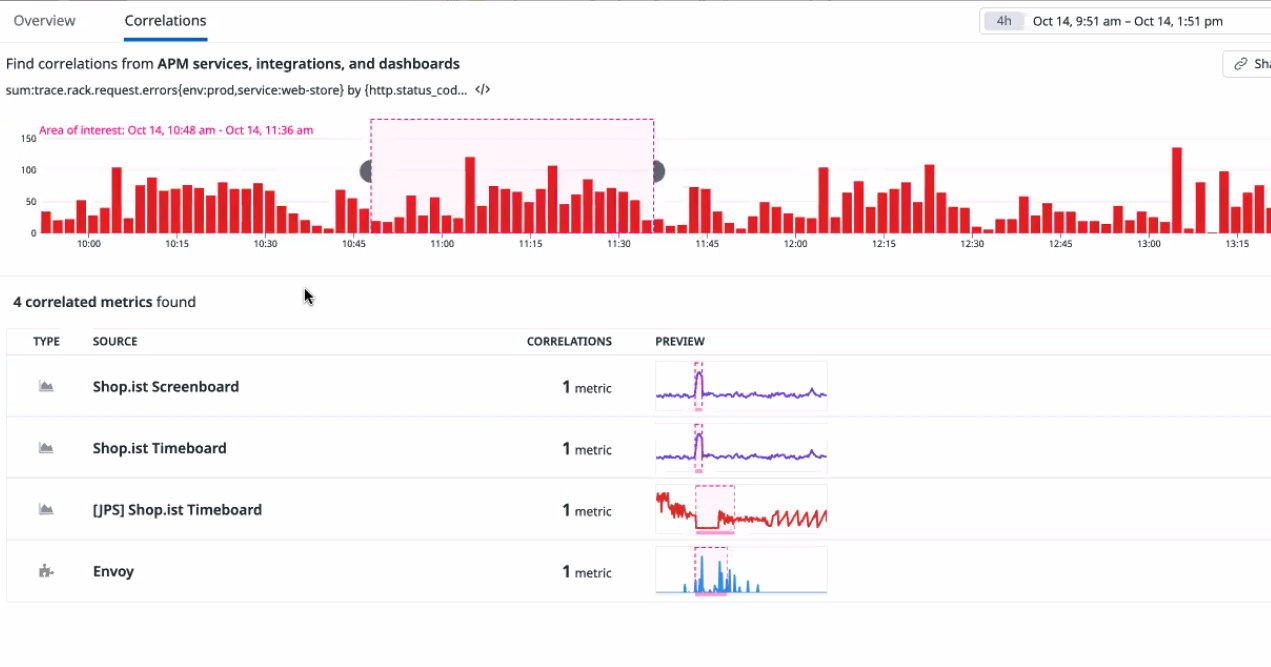
서비스 트러블슈팅 시 개발 서비스 이슈 파악은 correlations 확인
연관된 다른 서비스에는 문제가 없었는지까지 확인이 가능하다.
본 트랜드와 비슷한 추이를 갖고 있는 부분을 ml로 확인해 찾아낼 수 있음
로그 연계분석 > 보안 플랫폼으로써도 SIEM 에서도 확인이 가능하다.
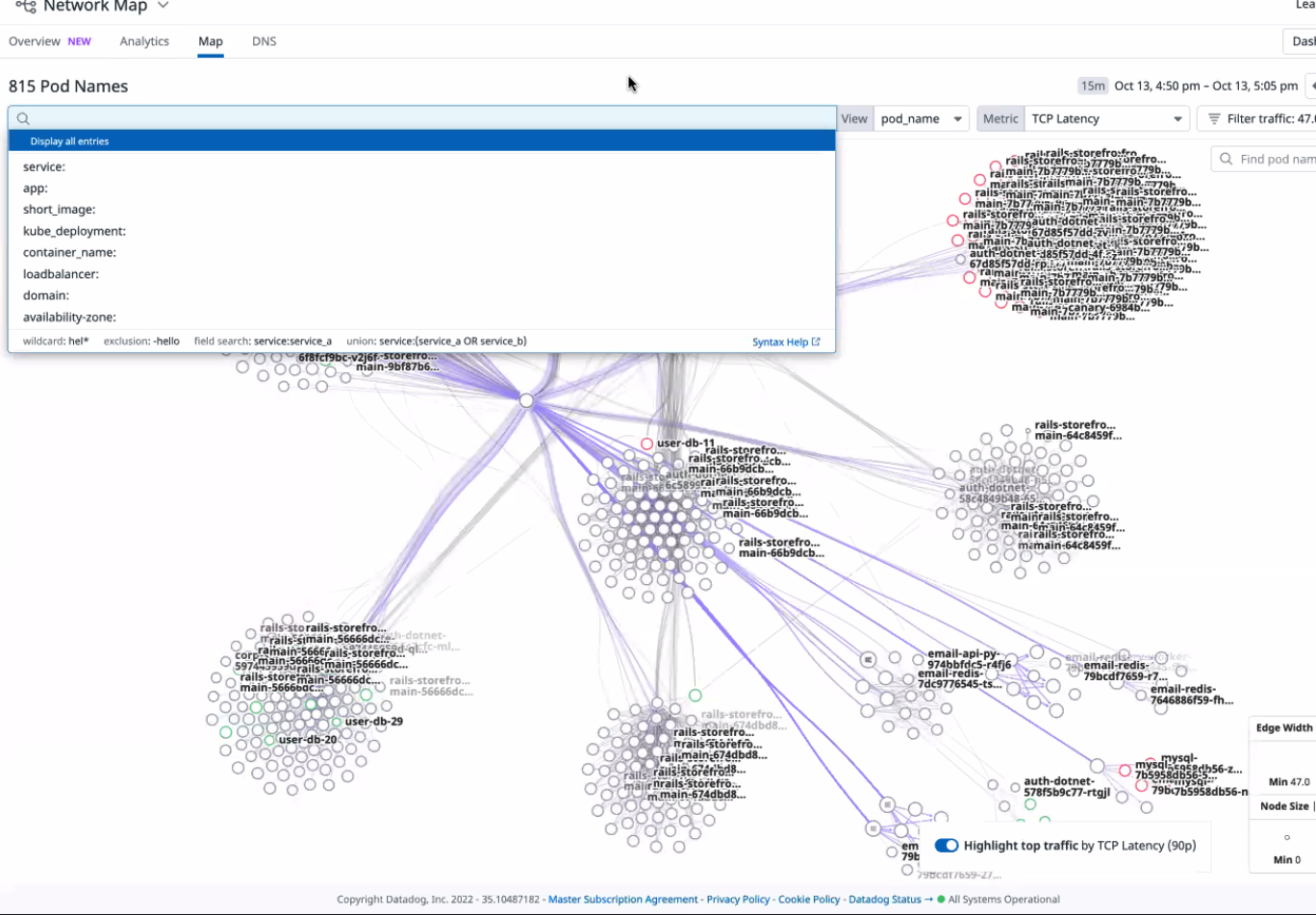
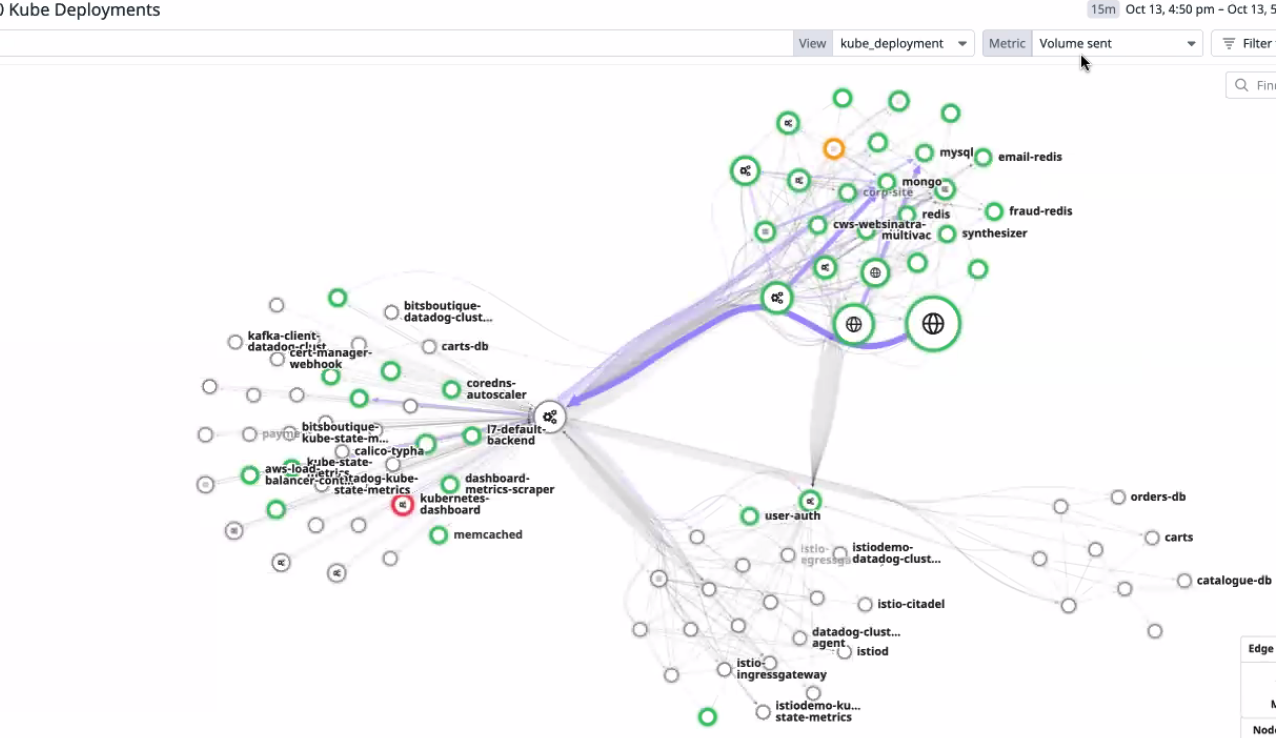
디플로이먼트 간의 연계를 확인할 수 있다. 여러 서비스 노드의 트래픽을 확인할 수 있음
태그를 기반으로 네트워크 트래픽 확인이 가능하다.
멀티클라우드 환경에서도 클라우드 관계를 확인할 수 있고, zone 별로 연관관계까지 분석 및 레포팅이 가능하다.
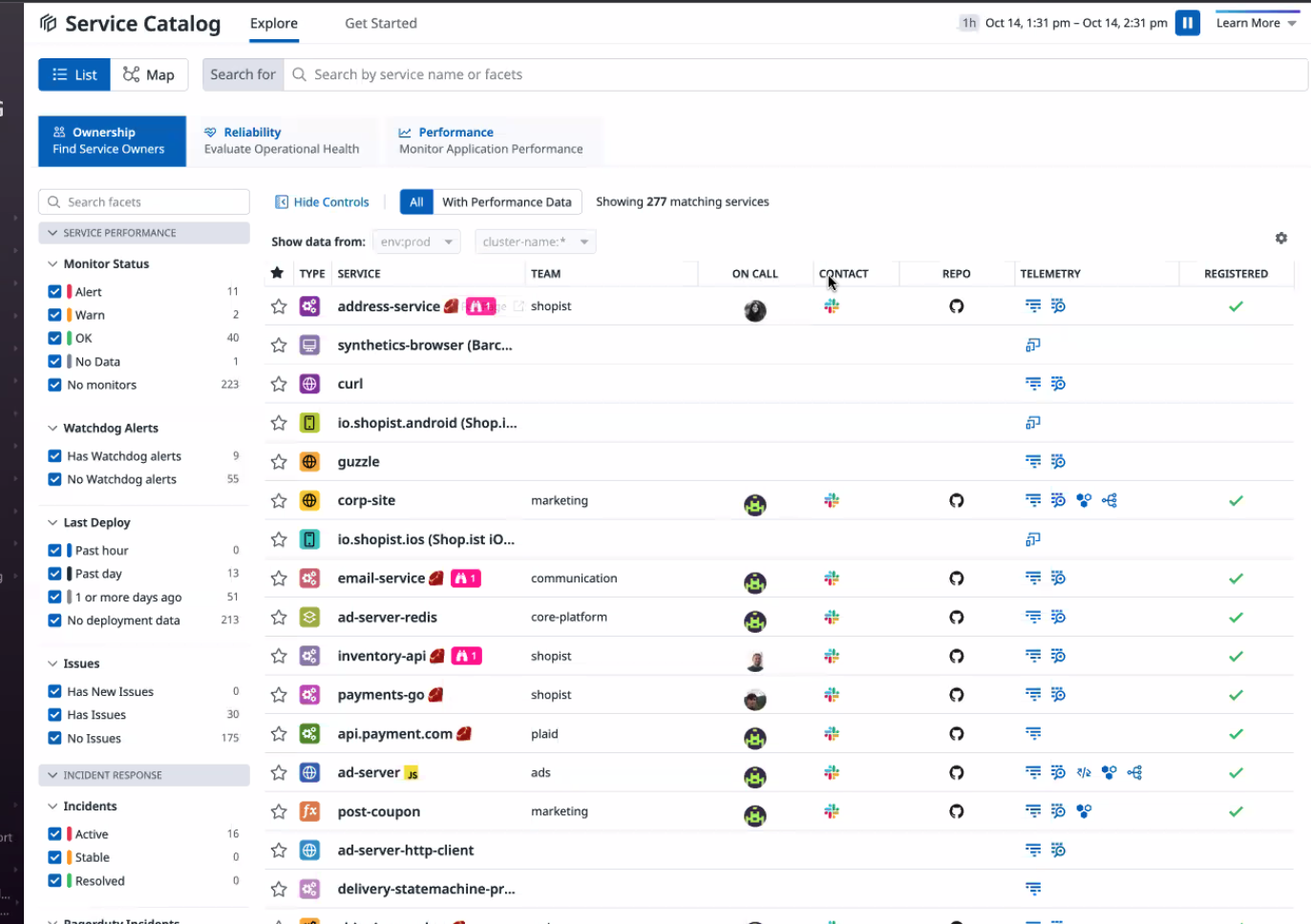
SI 관점에서의 데이터독 활용
Ownership: 서비스 별로 팀, 슬랙, 레포지토리를 지정할 수 있음.
Reliability: 배포주기, 이슈, 서비스 가용성 알림, 모니터링 알림도 확인할 수 있음
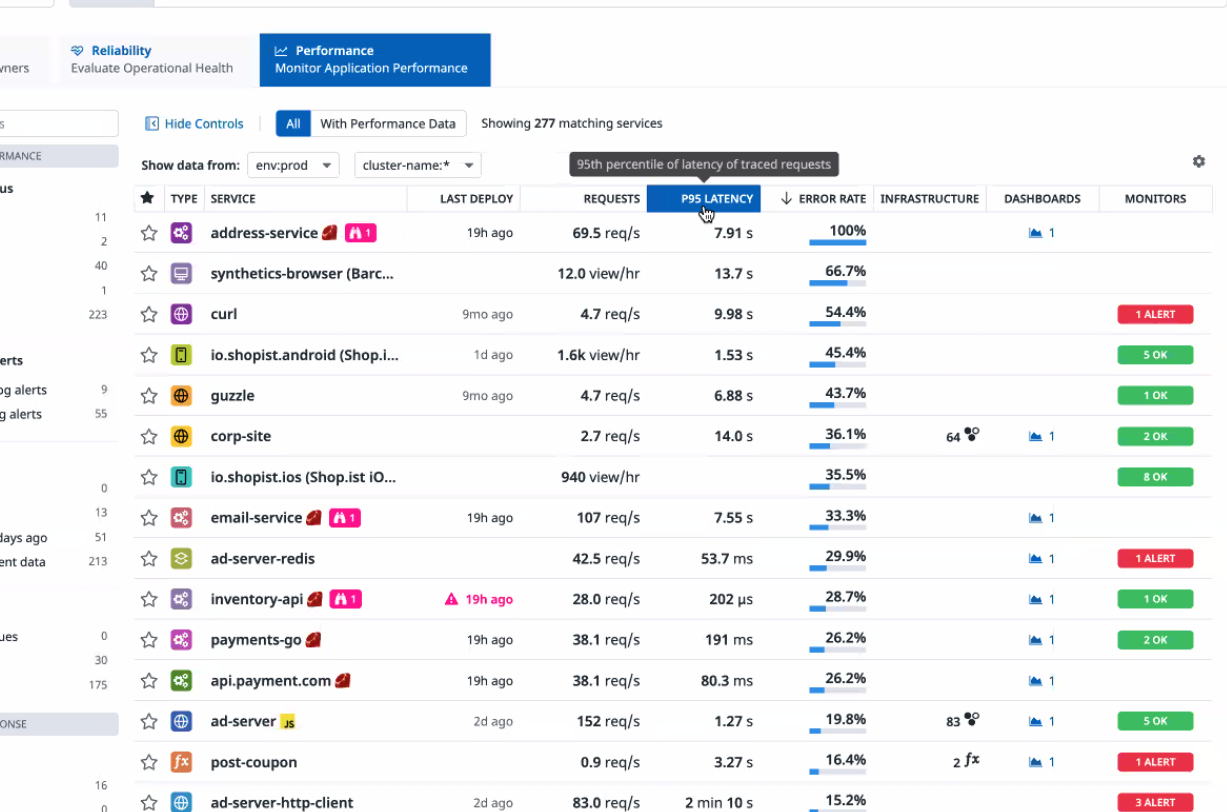
Performance: 지연시간, 에러율, 서비스 가동률(팟 n개) 등 서비스를 한눈에 확인 가능
Alarm
host, metric, 기반으로 모두 지원하고 있음
Anomaly: 레이턴시의 특이사항이 발생 시 알람을 받게끔도 가능하며
Forecast:
outlier: 카프카 클러스터에서 튀는 값을 확인할 수 있음
composite: 조건 별 알람 설정 기능
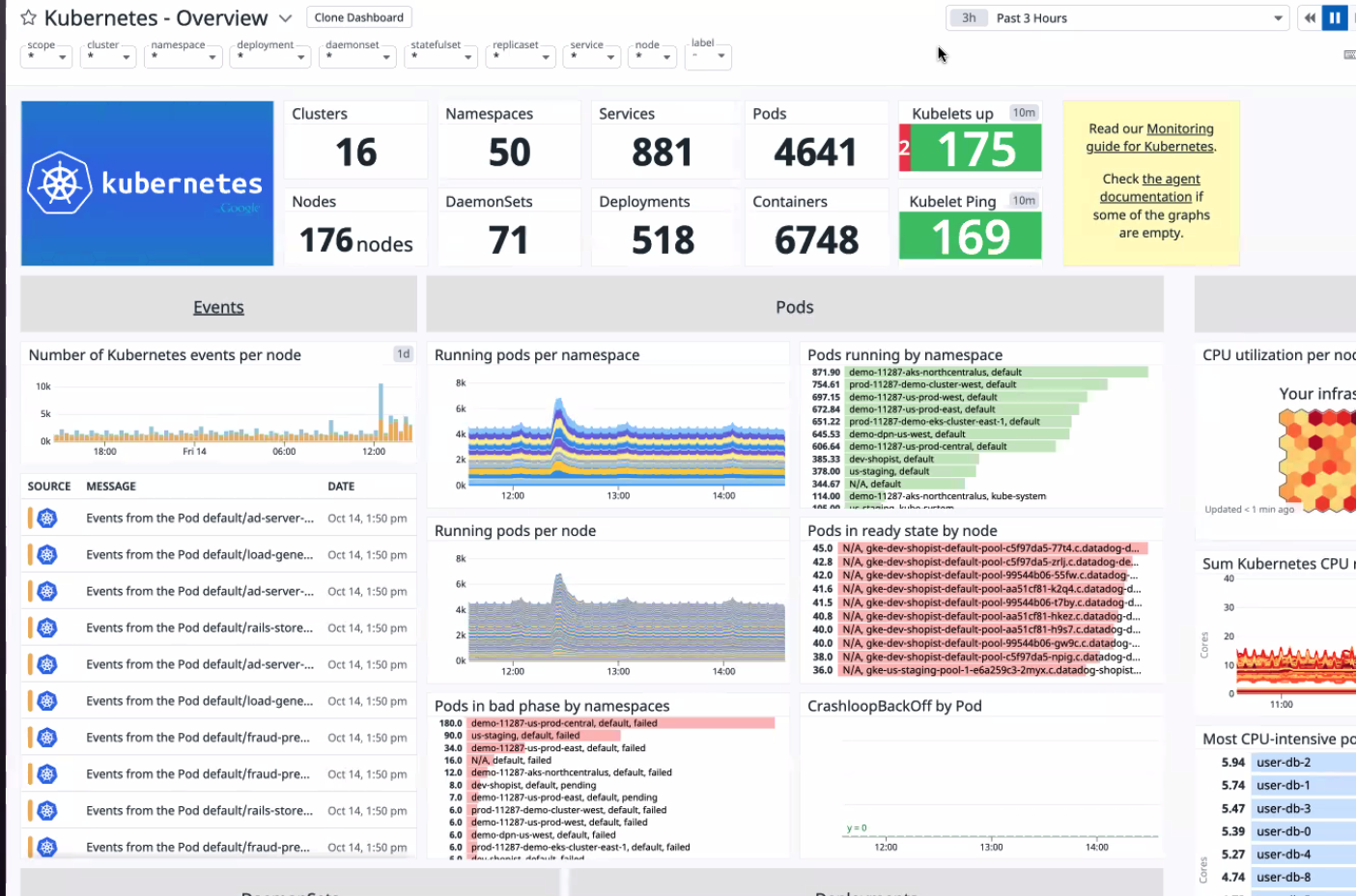
k8s overview
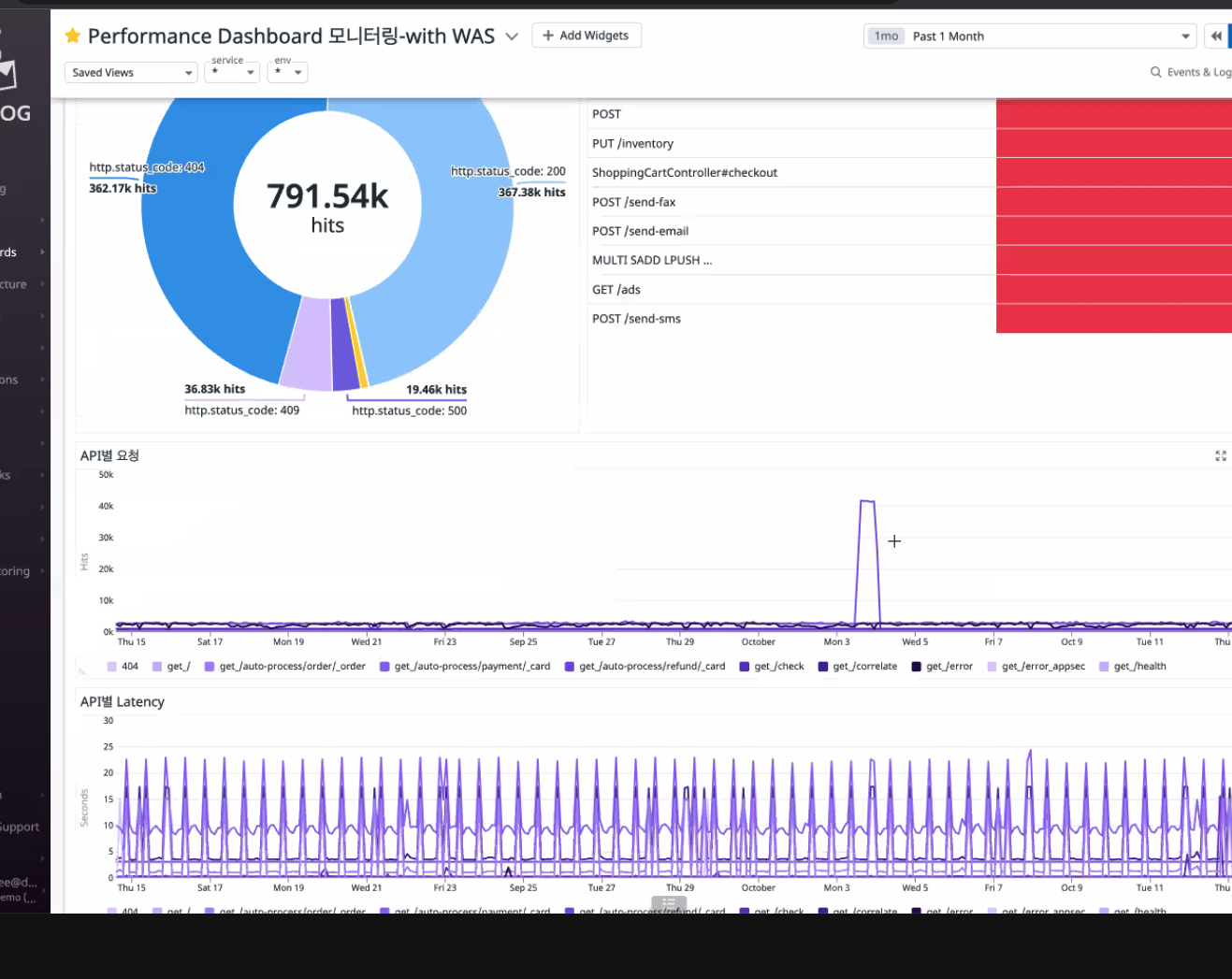
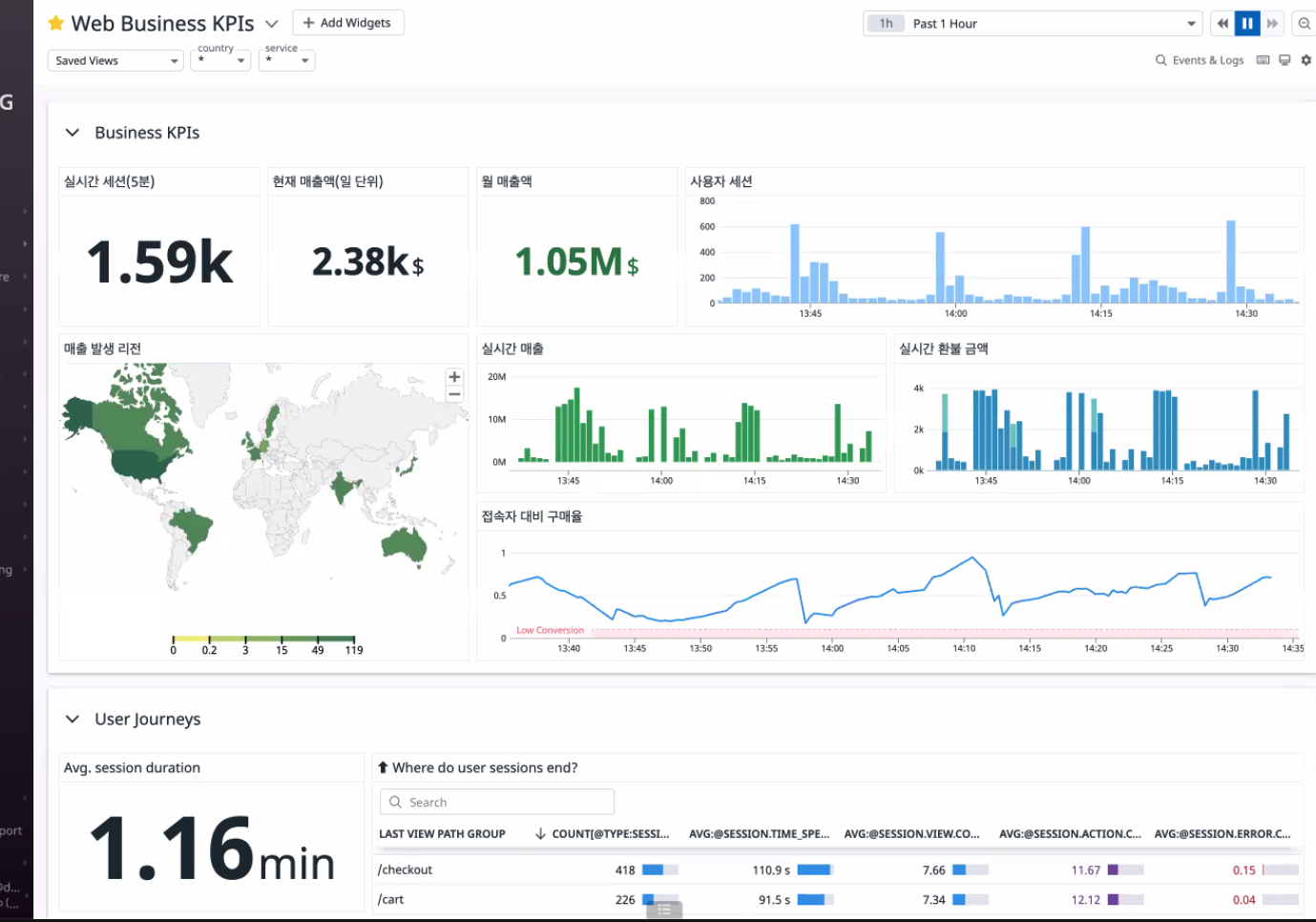
ux, log 데이터를 BI툴로도 사용할 수 있게끔 제공된다.
데이터독이 데이터독을 사용하는 법
모니터링 알람 우선순위
- 자주 변경될 수 있는 알람에 대해 테라폼으로 관리하고 있다.
- 실제로 크리티걸한 부분은 핵심 api(실패), 인증서 체크 (15일 이내)
- 데이터베이스, 카프카 등 중요 메트릭과 gateway 사용량 등을 정의한다
- 로우레벨의 경우 서비스 실무팀과는 연결되지 않고 오퍼레이터 팀에 알림이 간다. 이는 리소스 관점에서 런북을 제공한다. 실 서비스 이슈는 아니라는 점 ! >> 실 서비스 실무팀에는 알림이 가지 않음
- percentail 을 찾거나 정확한 임계칠르 구성하여 알람 순위를 설정한다.
SRE 그리고 포스트모템, 런북 활용
서비스 카탈로그를 활용한다, 담당자, 채널, 레포 다 등록하고 있고,
포스트모템을 이용해 무슨일이 일어났는지, 어떤 영향을 끼쳤는지, 왜 일어났는지. 의미있는 이슈만을 작성하고 있음

쿠버네티스 주요 메트릭
...
