Introduction
- 기존의 모델은 Encoder로 CNN을 사용(feature map 생성)
- CNN은 downsample로 인해, 연산이 진행될 수록 해상도, 세분성이 약화됨
- 이를 해결하기 위해 decoder를 개선하는 여러 시도가 있었음
- Encoder 자체의 backbone을 ViT로 적용하는 DPT를 제안
- 2행의 문제가 해결됨
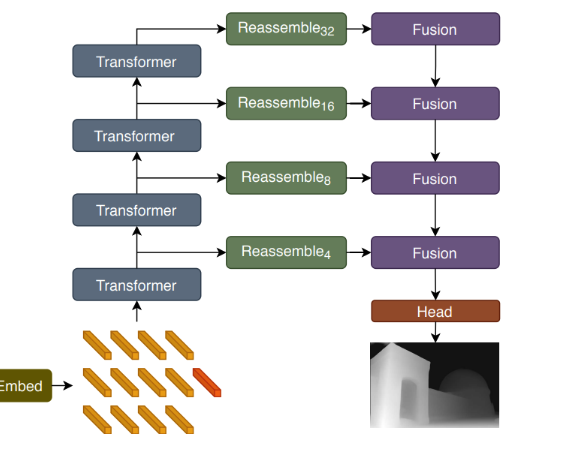
Architecture
ViT Encoder
- ViT의 구조를 거의 그대로 따름(차이점 후술)
- 전역적인 정보를 포함하는 readout Token 존재
- 다음 세 가지의 여러 버전이 존재
- ViT-Base: 패치 기반 임베딩 절차를 사용하고 12개의 transformer 레이어를 사용 (D=768)
- ViT-Large: 패치 기반 임베딩 절차를 사용하고 24개의 transformer 레이어와 더 넓은 feature 크기 D를 사용 (D=1024)
- ViT-Hybrid: ResNet50을 사용하여 이미지 임베딩과 12개의 transformer 레이어를 계산 (입력해상도의 1/16배에서 feature 추출)
patch_size: p =16
Q: Resnet50은 CNN 아닌가?
A: CNN이 맞지만, 트랜스포머와 함께 사용되며, 기존 cnn backbone보다 최저해상도가 두배 높다.
decoder에서 업샘플링을 통해 극복
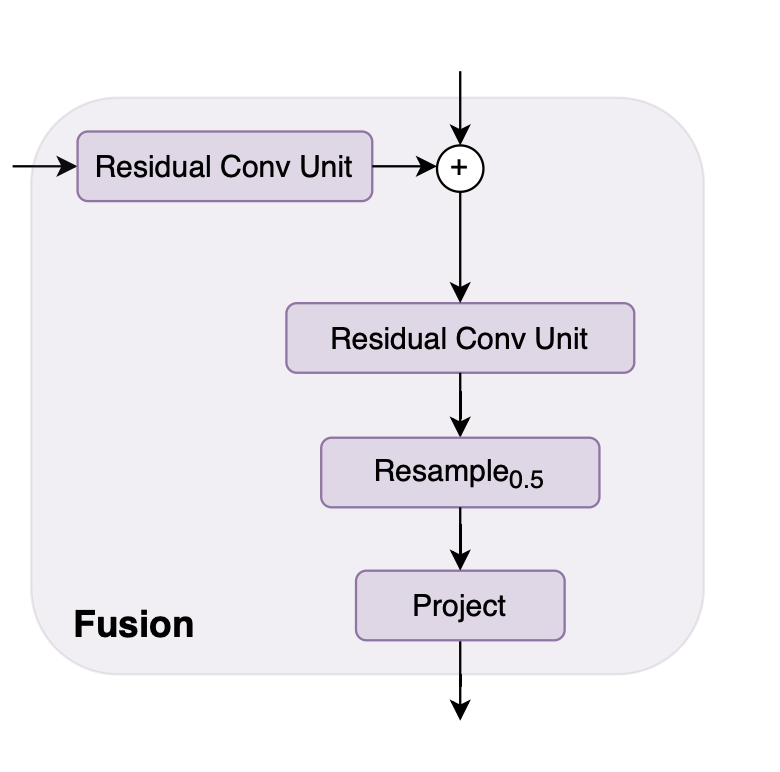
Convolutional Decoder
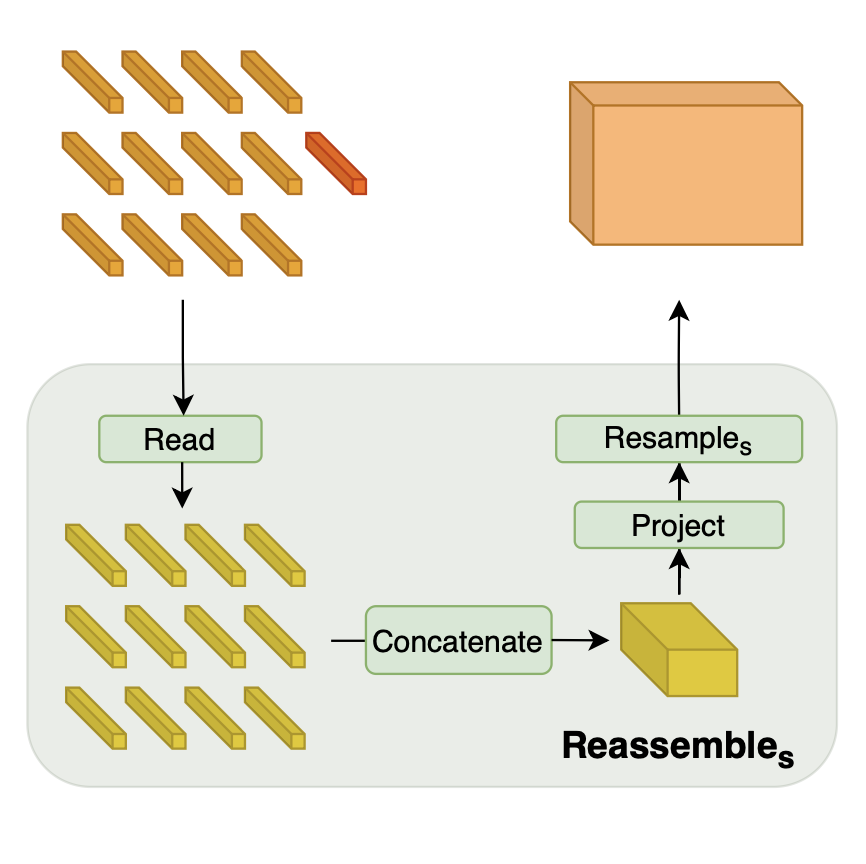
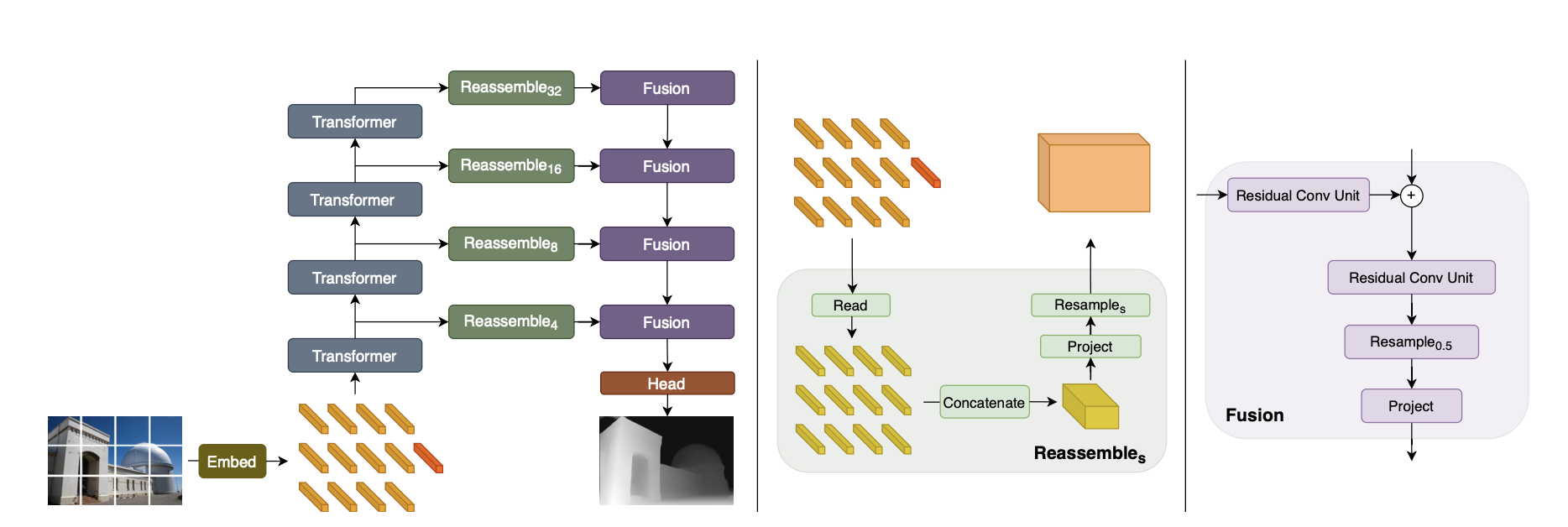
1. Read
개의 토큰을 개의 토큰 집합에 매핑
이때, Readout 토큰의 정보를 어떻게 활용할 지에 대해, 3가지로 접근함
- mlp의 경우, Linear Layer와 GELU non-linearity를 이용하여 원래 원래 차원인 D로 project함
2. Spatial Concatenating
개의 토큰을, 초기 이미지 위치에 맞추어 로 재구성
Q: Positional Encoding과 관련이 있나?
A: 관련 없다. 이 작업은 처음 패치를 flatten고 배치된 순서대로 재구성할 뿐이다.
3. Resampling
- 우선, 1x1 convolution으로 채널 수를 에서 로 조정 (입력채널의 가중합)
- 이후 원본 이미지 size에 맞게 strided conv, strided transpose conv를 이용하여 비율을 조정
Q: DPT 에서는 p=16이니까, 입력 사이즈와 맞추려면 strided transpose conv를 이용하여, 키우기만 해야하는 것 아닌가? (1x1 -> p=s)
A: 그냥 p = s로 맞추는 것. 입력 사이즈 = 출력사이즈 과정은 후술
4. From to (p = 16)
...
