DPT
1.Vision Transformer for Dense Prediction [DPT]
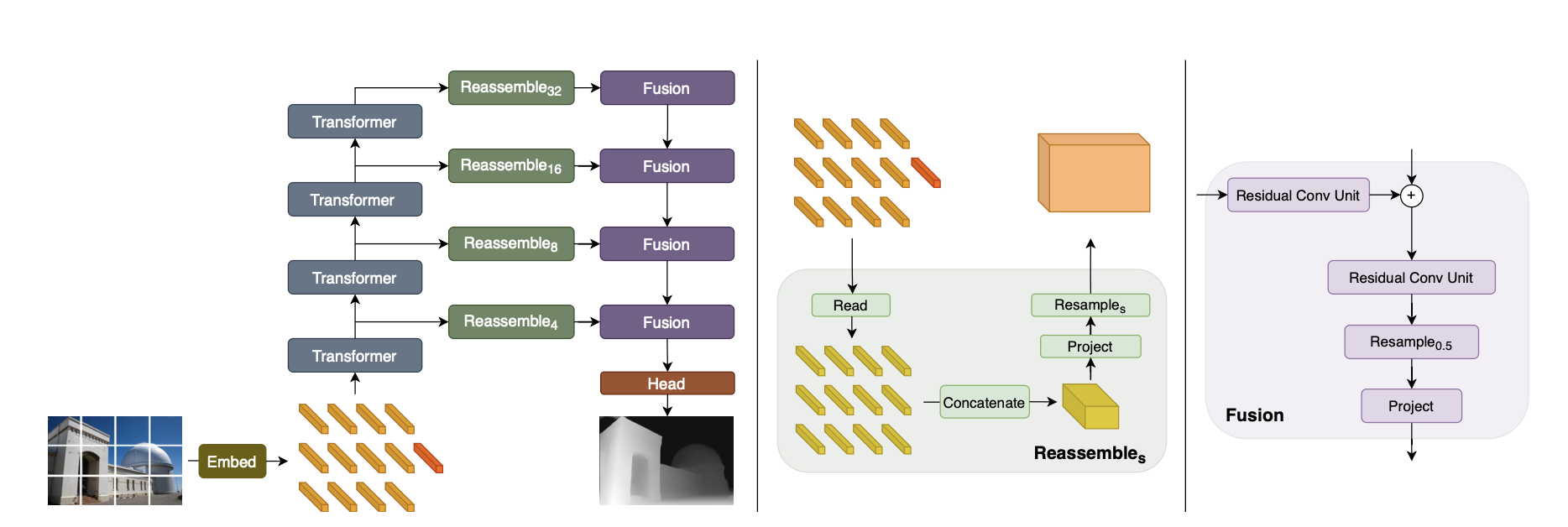
기존의 모델은 Encoder로 CNN을 사용(feature map 생성)CNN은 downsample로 인해, 연산이 진행될 수록 해상도, 세분성이 약화됨이를 해결하기 위해 decoder를 개선하는 여러 시도가 있었음Encoder 자체의 backbone을 ViT로 적용하
2024년 7월 22일
2.[Code]Vision Transformer for Dense Prediction (DPT) [1]

모델은 large, hybrid, (MiDas)가 있다. Hybrid의 경우 kitti, nyu 데이터를 위한 모델도 따로 준비가 돼있는 듯하다모델이 일단 정해지면,(h,w) 입력이미지 사이즈가 정해짐DPTDepthModel (후술) 클래스를 이용, 초기화backbon
2024년 7월 23일
3.[Code]Vision Transformer for Dense Prediction (DPT) [2]
[2] Model Layer 1. models.py 1.1 import 문 1.1.1 base_model.py BaseModel 클래스는 모델을 Load하는 역할 map_location=torch.device("cpu"): 우선 cp##### u에 로드 후, 이
2024년 7월 24일