Direct Preference Optimization : Your Language Model is Secretly a Reward Model [DPO논문 리뷰]
LLM은 대규모 데이터를 학습하면서 능력을 획득한다. 하지만 안에는 원하지 않는 지식이나 행동도 들어 있다.
- 코딩 보조 모델은 프로그래밍 실수를 알아차리고 이것을 고칠 수 있어야하지만, 코드를 생성할 때는 고품질 코드를 더 잘 생성하도록 해야 한다.
- 어떤 잘못된 지식을 많은 사람들이 믿고 있어도, 모델은 이러한 잘못된 사실을 진실처럼 말하면 안된다
그래서 모델은 광범위한 지식과 능력 중에서 원하는 응답과 행동을 선택하는 것은 중요하다.
기존의 언어 모델 훈련 과정
① 대규모 텍스트 데이터로 unsupervised pretraining을 한다
② 사람이 원하는 행동을 모델에 주입하는 preference learning을 수행한다.
그렇다면 어떤 preference learning이 있을까?
① SFT(Supervised Fine-Tuning) : 사람이 직접 "좋은 답변"을 시연하고, 모델이 그 답변을 따라하도록 학습
② RLHF : human preference dataset에 보상 모델을 학습시키고, 그 다음 RL을 사용하여 언어 모델 정책을 최적화하여 원래 모델에서 과도하게 멀어지지 않으면서 높은 보상이 할당된 응답을 생성하도록 한다.
⚠️ RLHF는 강력하지만, SFT보다 복잡하고, 훈련 비용이 훨씬 높고 과정도 번거로움
그래서 이 논문은 DPO 방식을 제안한다.
사전지식(RLHF)
RLHF 파이프라인은 다음 세 가지 단계로 이루어진다
1. SFT
2. preference sampling & 보상 학습
3. RL 최적화
SFT
RLHF는 pre-trained LM을 관심 있는 downstream task에 대해 고품질 데이터로 supervised leanring과 함께 fine-tuning하면서 시작한다. 이를 통해 모델 를 얻는다.
Reward Modeling Phase
SFT 모델에게 프롬프트 로 질의하여 답변쌍 을 생성함. 그런 다음 이 쌍은 human labelers에게 전달되어 labeler는 좋은 답변 하나만 투표한다(). 이 때 선호된 응답, 비선호된 응답. 이러한 선호는 우리가 접근할 수 없는 latent reward model(진짜 사람 마음속 점수) 에 의해 생성된 것으로 가정한다. preference를 모델링하기 위해서 Bradley-Terry(BT) 모델을 사용한다.
BT 모델은 human preference distribution 을 다음과 같이 쓸 수 있다고 가정함.
에서 샘플링된 static dataset of comparisons 에 접근할 수 있다고 가정할때, 우리는 reward model 를 파라미터화하고 최대우도법으로 파라미터를 추정할 수 있다.(진짜 사람 마음속 점수는 알 수 없으므로 신경망을 사용하여 근사한다.)
문제를 이진 분류로 구성하면 negative log-likelihood loss는 다음과 같다
즉, winner의 보상이 loser보다 높아지도록 학습한다.
LM의 맥락에서, network() 는 종종 SFT 모델()로 초기화되며, 최종 트랜스포머 층 위에 단일 스칼라 보상 값을 예측하는 선형 층을 추가한다. 낮은 분산의 보상 함수를 보장하기 위해, 모든 에 대해 이 되도록 보상을 정규화 하였음.
RL Fine-Tuning Phase
RL phase는 학습된 보상 함수가 LM에 피드백을 제공하는 데 사용됨. 최적화는 다음과 같다
- : 새로 학습할 정책
- : 기준이 되는 정책 (보통 )
- : KL divergence
- : KL penalty weight (로부터의 편차를 제어하는 파라미터) - 와 가깝게 유지, 작으면 멀게 유지
이 제약은 모델이 보상 모델이 정확한 분포에서 너무 멀리 벗어나는 것을 방지하고, 생성 다양성을 유지하며, 모드 붕괴를 방지하기 위해 사용된다. 언어 생성은 단어 하나 하나를 선택하는 discrete(이산) 과정이므로, 미분이 불가능하다. 그래서 일반적인 gradient descent 방식 대신, RL을 써서 "점수 잘 받은 샘플"의 확률을 높이면서 학습을 하게 된다. 그래서 보상 함수를 아래와 같이 구성하고, PPO를 사용하여 최대화한다.
Direct Preference Optimization
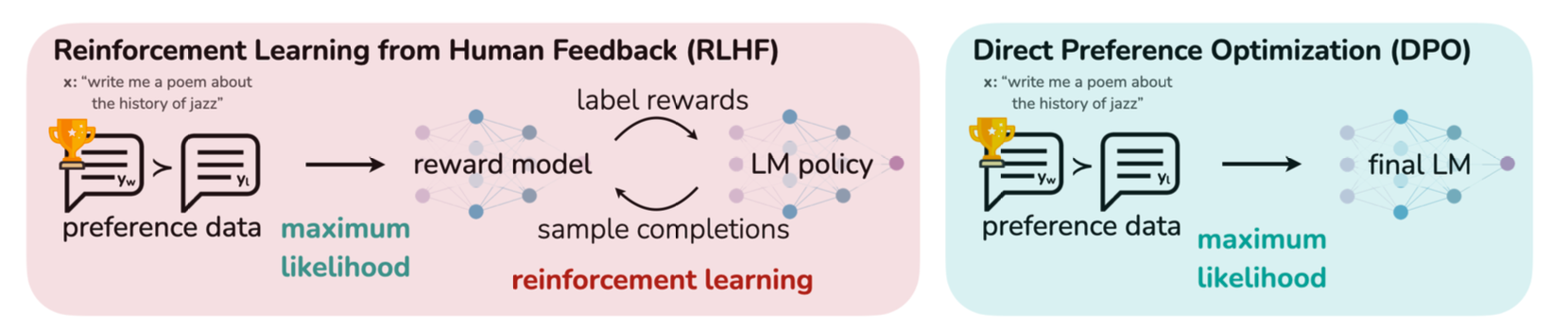
기존 RLHF 방법들은 보상 모델을 학습한 후 RL로 정책을 최적화하여 과정이 복잡하고 비용이 컸지만, DPO는 보상 함수를 parameterization하여서 최적 정책을 closed form(수학적으로 닫힌 형태)으로 바로 얻을 수 있었다. 즉, RL 학습 루프 자체가 필요 없다.
핵심 아이디어는 보상 함수를 최적 정책으로 가는 수학적 매핑을 활용하여 "보상 함수에 대한 손실"을 바로 "정책에 대한 손실"로 변환할 수 있었다.
DPO는 보상 모델을 따로 학습하지 않아도 되며, BT같은 인간 선호 모델을 기반으로 최적화가 가능하며, 결과적으로 정책 네트워크가 언어모델과 암묵적 보상 모델 역할을 동시에 수행하게 된다.
Deriving the DPO objective
그렇다면 어떻게 DPO가 RL없이 사람 선호를 최적화할 수 있을까?
기존 RLHF는 보상()를 크게 만들되, 와 너무 달라지지 않도록 KL constraint를 둔다. 이 문제의 optimal policy는 다음과 같은 형태로 정리된다.
여기서 는 분할 함수이다
즉, optimal policy는 참조 모델()에 보상()을 곱한 형태이다.
실제 보상 함수 의 MLE 추정치 를 사용하더라도, 여전히 분할 함수 를 추정하는 것은 비용이 많이들고, 실제로 활용하기가 어렵다.
⭐️ 하지만 DPO는 위 식을 재배열하여 reward를 최적 정책(), 참조 정책(),그리고 미지의 분할 함수()로 표현할 수 있다.
이 reparameterization을 ground-truth reward()와 그에 대응하는 optimal model() 에 적용할 수 있다.
위 식을 에 대입한 뒤, preference model 에 대입하면, 분할 함수는 상쇄되고, human preference 확률을 optimal policy()과 reference policy()만으로 표현할 수 있다. 따라서 BT 모델 하에서 최적 RLHF 정책 은 다음을 만족함
이제 보상 모델이 아닌 optimal policy의 관점에서 인간 선호 데이터를 표현했으므로, optimal policy 자리에 parameterized 정책()를 놓고, 사람이 고른 승자()를 맞히는 이진분류 maximum likelihood 문제로 바꿀 수 있다.
✅ 즉, DPO는 원래 보상 모델을 학습하던 과정을 수학적으로 "정책 확률 비율"로 치환해서, 선호 데이터만으로 정책을 바로 학습할 수 있도록 만든 방법임.
What does the DPO update do?
DPO의 손실 함수 의 매개변수 에 대한 그래디언트는 다음과 같다
- : reward estimator가 잘못 판단할수록 차이가 크므로 시그모이드 값이 커지게되어 업데이트가 강하게 일어남
- : 선호된 응답 의 확률을 더 크게 만드는 방향으로 업데이트
- : 비선호 응답 의 확률을 줄이는 방향으로 업데이트
- : LM()와 reference model()에 의해 암묵적으로 정의된 보상
직관적으로, 손실 함수()의 gradient는 의 likelihood는 증가시키고, 의 likelihood를 감소시킨다. 중요한 점은, 예제들이 가 을 얼마나 높게 평가하는지, 이는 KL constraint의 강도 에 의해 스케일링된다.
DPO outline
일반적인 DPO pipeline은 다음과 같다
1 ) 각 프롬프트 에 대해 sample completion 를 수행하고, 인간 선호로 라벨링하여 선호 오프라인 데이터셋 을 구성함
2 ) 를 최소화하기 위해서 주어진 와 로 LM인 를 최적화한다.
샘플을 생성하고 인간 선호를 수집하는 것보다, 공개적으로 이용 가능한 선호 데이터셋을 재사용하는 것이 시간과 비용 측면에서 바람직하다. 선호 데이터셋은 를 사용하여 샘플링되므로, 가능하다면 로 초기화한다.(선호 데이터셋이 분포에서 나온 응답 쌍을 기반으로 라벨링됐으니, 참조 분포 도 로 두면 데이터의 출처 분포와 기준 분포가 일치하게됨.) 하지만 가 이용 불가능할 경우, 선호된 응답 의 maximizing likelihood를 통해 를 초기화함. 즉,
Theoretical Analysis of DPO
Your Language Model Is Secretly a Reward Model
이 부분은 DPO에서 LM이 reward model 역할을 한다는 것을 수학적으로 정리한다.
RLHF는 reward model()를 따로 학습한다. 하지만 BT같은 reference model에서는 reward의 차이가 중요하다 (). 그러므로 같은 차이를 만드는 reward function은 여러 개 있을 수 있고, 이 때문에 reward model은 class 단위로만 정의된다
Definition
두 reward function 가 있을 때,
이면 equivalence class(동치류)라고 한다. 즉, reward function 값이 만큼 일정한 차이가 나면 같은 역할을 한다고 본다.
Lemma 1
Plackett-Luce / BT preference framework에서, 같은 class의 reward function은 똑같은 prference distribution을 만든다
Lemma 2
같은 equivalence class의 reward function은 constrained RL 문제에서 동일한 optimal policy를 만든다.
✅ equivalence class안의 정확한 하나의 reward fucntion이 아닌, equivalence class를 대표하는 임의의 reward function이면 충분하다!
Theorem 1
Plackett-Luce / BT model과 일관되는 모든 reward equivalence class는 , 다음 형태로 표현할 수 있음
어떤 reward function 가 optimal policy 를 유도한다 하자. 의 equivalence class에 속하는 reward function이 reparameterization을 통해 표현될 수 있음을 보인다.
연산자 는 단수히 reward function을 의 분할 함수()의 로그로 정규화한다
여기서 뒤에 빼준 항은 에만 의존하므로 는 의 equivalence class에 속하게되므로 원래 보상과 동등하게 사용이 가능함. 로 r을 대체하면
는 원하는 형태를 가진 의 equivalence class 내의 한 멤버를 산출하며, reparameterization해도 reward model의 일반성을 잃지 않는다.
그렇다면 DPO는 equivalence class 안에서 어떤 reward를 고를까?
이 조건은 분할 함수가 1이 되도록 보상을 정규화한 것이다. 즉, DPO는 여러 동등한 reward function 중에서도 위 조건을 만족하는 reward function을 선택한다
Instability of Actor-Critic Algorithms
DPO를 활용해서 PPO와 같은 RLHF에 사용되는 standard sactor-critic 알고리즘의 instability를 진단할 수 있다.
RLHF의 fine-tuning 단계에서 policy gradient 방법을 사용한다. 이때 목표는 학습 중 policy()가 optimal policy(:보상 모델 로 정의된 policy)에 가까워지도록 학습하는 것이다.
이는 다음 최적화 목적에 도달한다
위 최적화 식을 보면 정규화 항()이 붙는다. 이걸 soft value function이라 부른다. 이 항은 optimal policy 자체에는 영향을 주지 않지만,이 항이 없게되면 policy의 gradient의 분산이 커져 학습이 불안정해 진다.
그래서 기존 RLHF는 value function을 따로 학습해서 보정하거나 human completion을 baseline으로 삼아 정규화하였다.
하지만 DPO는 reparameterization으로 정규화 항을 없애 baseline 자체가 필요없어 안정적이다!
Experiments
Tasks
three different open-ended text generation을 탐구함. 모든 실험에서, 알고리즘은 preferences dataset 로 부터 policy를 학습한다.
In controlled sentiment generation
는 IMDB 데이터셋에서 영화 리뷰의 접두사이고, policy는 긍정적인 감정을 가진 를 생성해야 한다. 제어도니 평가를 수행하기 위해서, controlled evaluation을 위해서, pre-trained setiment classifier를 사용하여 생성물들 위에 preference pairs를 생성한다. 여기서 이다. SFT를 위해서 IMDB 데이터셋의 train split에서 리뷰에 대한 GPT-2-large를 수렴할 때까지 fine-tuning한다.
In summarization
는 Reddit의 포럼 게시물이고, policy는 게시물의 주요 요점을 요약하는 를 생성해야 한다. 여기서는 Reddit TL;DR 요약 데이터셋 & Stiennon et al.에 의해 수집된 human preference dataset(유사하게 훈련된 SFT 모델에서 나온 샘플)을 사용한다.
In single-turn dialogue
는 human query이며, 천체물리학에 대한 질문에서부터 관계 조언 요청까지 무엇이든 될 수 있다. policy는 사용자의 질의에 대해 유용한 응답 를 생성해야 한다. Anthropic Helpful and Harmless dialogue dataset(인간과 automated assistant 간의 170k 대화)을 사용했다. 각 transcript는 LLM에 의해 생성된 두 개의 응답 쌍으로 끝나며, 인간이 선호하는 응답을 나타내는 preference label이 함께 제공된다. 이 환경에서는 pre-trained SFT model이 사용 불가하므로, off-the-self LM을 preferred completions form에 대해 fine-tuning하여 SFT model을 생성함
Evaluation
in controlled sentiment generation 환경에서 각 알고리즘을 reference policy으로부터의 달성된 reward와 KL divergence의 경계선으로 평가한다. 이 경계선은 ground-truth reward function에 접근할 수 있으므로 계산이 가능하다.
하지만 real-world에서는 ground truth reward function이 알려져 있지 않으므로 알고리즘들을 summarization & single-turn dialogue 환경에서 summary quality & response helpfulness에 대해서 human evaluation으로 GPT-4를 사용하여, baseline policy에 대한 win rate로 평가한다.
summarization에서는, reference summaries를 test set에서의 baseline으로 사용함. dialogue에서는 preferred response를 baseline으로 사용함.
Methods
| Method | explain |
|---|---|
| Zero-shot | GPT-J(summarization) |
| Few-shot prompting | Pythia-2.8B(dialogue) |
| SFT | prference 데이터 없이 인간 답변이나 텍스트로만 지도학습 |
| Preferred-FT | chosen completion 에 대해 지도학습으로 fine-tuning |
| Unlikelihood | policy가 에 대한 확률은 maximize, 에 대한 확률은 minimize하도록 simply optimize한다. |
| PPO | preference data로부터 학습된 reward function을 사용함. |
| PPO-GT | controlled sentiment setting에서 사용 가능한 ground truth reward function으로부터 학습한다. |
| Best of N | SFT 모델로부터 N개의 응답을 샘플링하고, preference dataset으로부터 학습된 reward function에 따라 가장 높은 점수를 받은 응답을 반환함. |
How well can DPO optimize the RLHF objective?
RLHF에서 사용되는 KL-constrained reward maximization objective는 policy가 reference policy로부터 멀어지는 것을 제한하면서 reward의 활용을 균형 잡음. 따라서 알고리즘들을 비교할 때, 달성된 reward & KL 불일치도 고려해야함.(약간 더 높은 reward를 달성하더라도 훨씬 더 큰 KL를 달성하면 not necessarily desirable)
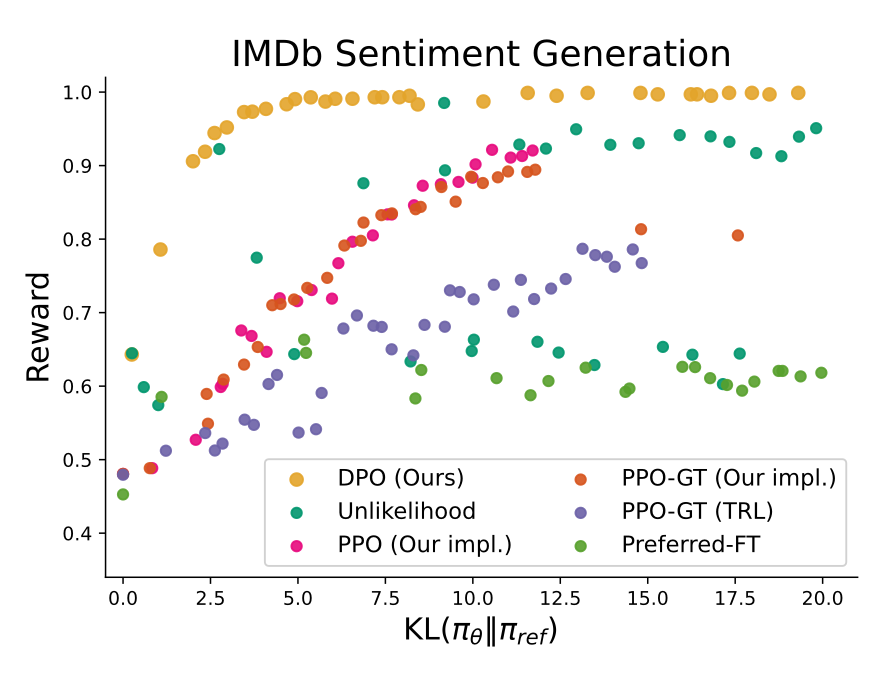
Frontier
여러 알고리즘을 다양한 하이퍼파라미터로 돌리면, 각각 (reward, KL)점이 하나씩 생김. 이 점들을 모두 찍었을 때, 다른 어떤 점보다 더 좋은 (reward, KL) 조합만 모은 경계선이 frontier임.
즉, 더 이상 개선 불가능한 최적의 trade-off 조합을 연결한 선을 말한다.
sentiment 환경에서 다양한 알고리즘들의 reward-KL frontier를 보여준다.
각 알고리즘마다 다른 하이퍼파라미터를 사용했음
| 알고리즘 | 하이퍼파라미터 |
|---|---|
| DPO | KL {3,6,9,12} |
| Unlikelihood | {0.05, 0.1, 1, 5}, {0.05,0.1,0.5,1} |
| preferred-FT | random seed |
true reward function 하에서 평균 보상과 reference policy 와 평균 시퀀스 레벨 를 계산하여 각 policy를 평가함
DPO가 가장 효율적인 frontier를 생성하는 것을 발견했다. 즉, DPO는 가장 높은 reward를 달성하면서도 여전히 낮은 KL을 달성한다. 이유는 다음과 같다
1️⃣ DPO와 PPO는 동일한 objective를 최적화하지만, DPO가 더 효율적이다
2️⃣ DPO는 PPO가 ground truth rewards에 접근할 수 있을 때조차 PPO보다 더 나은 frontier를 달성한다
Can DPO scale to real preference datasets?
summarization & single-turn dialogue에서 DPO의 fine-tuning 성능을 평가한다.
Summarization
summarization에서 자동 지표(ROUGE-기계가 요약 품질을 자동으로 점수 매기는 지표)로 평가하면 human preference와 잘 안 맞을 수 있으며, 이전 연구에서 human preference에 기반하여 PPO로 LM을 fine-tuning하면 더 효과적인 summarization을 제공한다는 것을 발견하였음.
Reddit TL;DL summarization dataset의 test split을 데이터로 사용하였음. baseline으로는 test split에 있는 completion(reference-human write)을 샘플링함.
test split에서 글을 하나 꺼내고 각 방법에 대해 temperature 값을 바꿔가며 요약을 생성한다. 이후 모델이 요약한 것과 reference 한쌍을 만들고, GPT-4에게 두 요약 중 더 나은 것을 고르게 함.(모델 요약이 나으면 win = 1, 아니면 win = 0) test split의 여러 프롬프트에 대해 같은 과정을 반복한뒤 로 평균 승률을 계산함.
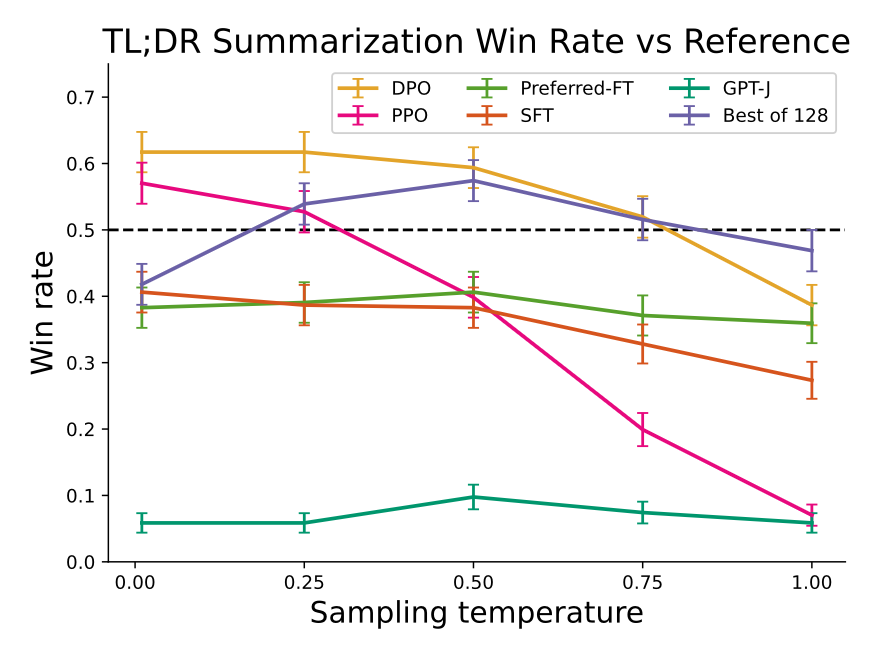
temperature
- : 어떤 입력 에 대해 LM이 생성한 다음 단어 y의 확률
- : 원래 확률에 라는 지수를 줌
- : 모든 후보에 대해 같은 연산을 하고, 그 합으로 나눠서 다시 전체 합이 1이 되도록 정규화
T가 작으면 : 큰 확률은 더 커지고 작은 확률은 더 작아짐 가장 가능성 높은 단어를 거의 항상 선택
T가 크면 : 큰 확률과 작은 확률의 차이가 줄어듦 낮은 확률 단어도 더 자주 선택하여 출력이 더 다양해짐
single-turn dialoue
Anthropic HH dataset의 test split에서 human-assistant iteraction one step으로 다양한 방법을 평가함.
GPT-4를 평가자로 사용하였고, 모델이 생성한 응답 vs 사람이 선호한 응답(prefered completion)을 비교하여 win rate를 계산함.
pre-trained Pythia-2.8B를 가져와 선택된 completion에 대해 Preferred-FT를 사용하여 reference model을 훈련하여 completion들이 모델의 분포 내에 있도록 한. DPO를 사용하여 훈련함.
| method | 설명 |
|---|---|
| Best of 128 Preferred-FT completions | Preferred-FT model에서 한 입력에 대해 128개의 답변을 뽑고, 그 중. 가장 좋은 것만 고름 |
| 2-shot prompting(Pythia-2.8B base model) | Pythia-2.8B라는 pre-trained LM에, 대화 예시 2개만 주고 답변을 생성하는 단순 방식 |
| PPO로 학습된 RLHF 모델 | ANthropic HH 데이터셋으로 PPO 학습된 공개 모델을 테스트했지만, 성능이 기본 Pythia-2.8B보다 못함 |
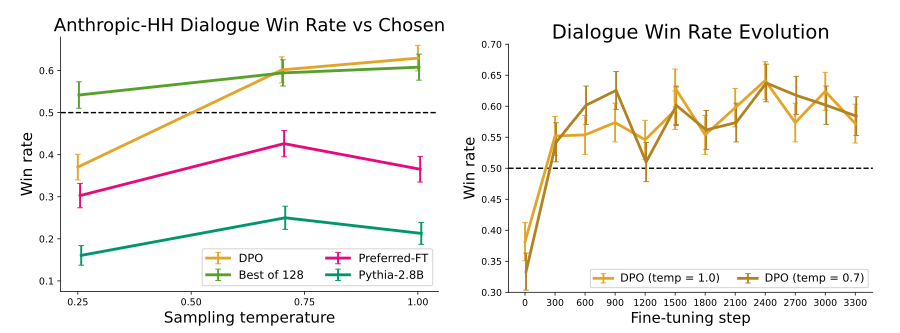
Generalization to a new input distribution
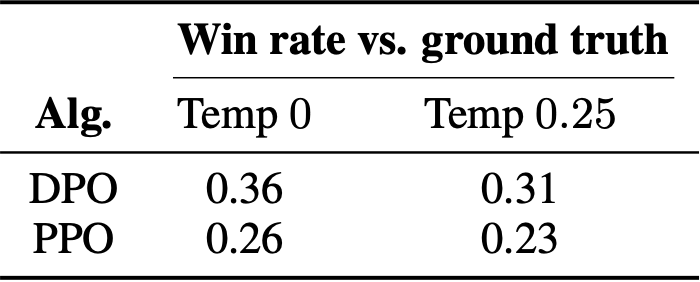
모델이 학습된 데이터(TL;DR, Reddit 포럼 요약)와는 다른 성격의 데이터를 줬을 때 (뉴스 기사 CNN/DailtyMail 요약) 여전히 잘 작동하는지 확인하기 위해서 distribution shift 실험을 하였음.
Reddit TL;DR summarization 실험에서 학습된 PPO와 DPO policy를 그대로 사용하였음.
평가 데이터로는 CNN/DailyMail 뉴스 요약 데이터셋의 test split을 사용하였고, TL;DR 실험에서 가장 성능이 좋았던 temperature를 그대로 적용하였다. GPT-4를 평가자로 설정하고, Reddit 실험 때와 동일한 프롬프트를 사용하되, "forum post"를 "news article"로만 바꿔 GPT-4가 요약 비교를 하였다.
Validation GPT-4 judgements with human judgments
우리는 실험에서 GPT-4를 평가자로 사용하였다. 하지만 이러한 의문이 생길 수 있다 "GPT-4 평가자의 판단이 사람의 판단과 일치할까?". 여기서 우리는 사람의 평가와 GPT의 평가를 직접 비교하는 검증 실험을 진행한다
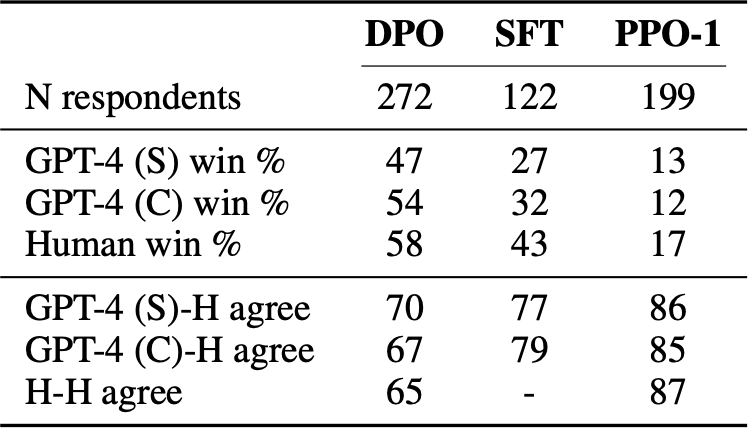
| 프롬프트 | 설명 |
|---|---|
| GPT-4 (s) | simple prompt 단순히 "어느 요약이 글의 핵심 정보를 더 잘 담고 있나?만 묻는 질문 인간보다 더 길고 반복적인 요약을 선호했음 |
| GPT-4(C) | concise prompt "어느 요약이 더 잘 요약했는지 + 더 간결한지도 함께 평가"하도록 요청 |
DPO, PPO, SFT 방법을 사용하여 세 가지 비교를 수행한다. 세 가지 방법 모두 그리디 샘플링된 PPO(최고 성능 temperature)와 비교된다.
결과는 두 프롬프트 모두에서 GPT-4가 인간 평가의 합리적으로 대체할 수 있음을 보여주었다. 전반적으로, GPT-4(c) 프롬프트가 일반적으로 인간을 더 잘 대표하는 win rate를 제공한다.
