Proximal Policy Optimization Algorithms
내용이 많이 길겠지만 세세하게 설명해서 어쩔 수 없었습니다. 나중에 중요 내용만 정리해서 다시 올려보겠습니다
사전 지식
Policy gradient
강화학습에서 policy란 "어떤 상황에서 어떤 행동을 수행 할지를 확률적으로 결정하는 규칙"이다.
즉, 상태 에서 행동 를 할 확률이 이며, 는 정책을 결정하는 파라미터이다.좋은 policy를 찾는게 목표이고, 이를 위해서 파라미터()를 업데이트해야 함. 이때 필요한 것이 policy gradient로 "policy가 좋아지는 방향"을 알려주는 gradient를 구하는 것임.
trajectory
agent가 환경에서 시작 ~ 끝까지 경험한 상태(), 행동(), 보상()들의 집합
Advantage function
- : 상태 에서 행동 를 했을 때 기대되는 총 보상
- : 상태 에서 평균적으로 기대되는 총 보상
Background : Policy Optimization
Policy Gradient Methods
가장 일반적으로 사용되는 gradient estimator는 다음과 같은 형태를 가짐
- : trajectory(에피소드) 안에서의 timestep
- : 상태 에서 행동 를 할 확률
- : 특정 행동을 할 확률이 커지도록 파라미터를 어떻게 바꿔야 할지 알려주는 방향
- : 그 행동이 얼마나 좋은지 나타내는 advantage function의 추정값
- : 실제 경험으로부터 얻은 평균
각 에서 를 모든 스텝에 대해 평균을 내면 가 됨.
trajectory가 2개, 각 3 step으로 구성되어 있다면 총 6개 값의 합을 6으로 나누면 된다.
즉, 이 수식은 정책을 업데이트할 때, 잘한 행동(advantage가 큰 행동)은 확률을 크게, 못한 행동은 작게 하자라는 규칙을 표현했음
실제 구현과정에서 자동미분(autograd)을 사용하기 위해서 목적 함수를 아래와 같이 정의한다
위 목적 함수를 미분하면 와 동일하다.
⚠️ 목적 함수 를 동일한 trajectory을 사용하여 여러번 최적화 단계를 수행하게 되면, 정책이 trajectory에 맞춰지게 되는 overfitting이 발생하게 된다. 그래서 새로운 trajectory를 수집했을 때 정책이 전혀 안 맞는 방향으로 튈 수도 있다.
그러면 동일한 trajectory를 사용안하면 되는거 아닌가?
물론 과적합 문제는 줄어들겠지만, 데이터 효율이 너무 떨어져 학습이 비실용적이게 된다. 예시로 100만 step 데이터를 모으고 단 한 번만 학습하면 데이터 낭비가 심하다 그래서 보통 같은 trajectory를 "몇 번은" 학습에 재사용하게된다.
Trust Region Methods(TRPO)
TRPO는 정책 업데이트의 크기 제약 하에서 목적 함수를 최대화함
- : 새 정책이 옛날 정책에 비해 행동 를 얼마나 더 자주/덜 자주 하려는지 나타내는 비율
평균(기대값)을 최대화하려면
- 인 시점들에 대해 를 키워서 비율을 크게 만들고,
- 인 시점들에 대해 를 줄여서 비율을 작게 만들면
각 항의 값들이 커지거나(덜 작아지거나)해서 전체 평균이 커짐
TRPO는 두 가지 방식을 채택한다
1️⃣ Constraint 방식
hard constraint :
KL_divergence가 보다 작아야한다는 제약 조건을 통해서 새로운 정책과 옛날 정책이 너무 달라지지 않게 막는다.
2️⃣ Penalty 방식
이처럼 KL divergence를 penalty로 넣는다.
는 KL을 얼마나 강하게 억제할지 정하는 계수이다.
- 가 작은 경우, 정책이 너무 크게 변할 위험
- 가 큰 경우, 정책이 거의 안 변함
⚠️ penalty 방식은 다양한 문제 전반 또는 학습 과정에서 특성이 변하는 단일 문제 내에서도, 잘 동작하는 하나의 값을 선택하기 어렵다
그래서 TRPO는 패널티 방식이 아닌 hard constraint 방식을 사용한다.
⭐️ Clipped Surrogate Objective
라고 하자.
- : 변화 없음 ()
- : 새 정책이 옛날보다 이 행동을 더 자주 선택
- : 새 정책이 옛날보다 이 행동을 덜 선택함을 나타낸다
원래의 surrogate objective (LCPI)는 다음과 같다
하지만 제약 없이 최적화하려면 가 너무 커지거나 작아져 정책이 확 튀어버리게 된다.
> 0 이면 좋은 행동이므로, 수식을 크게 만들기 위해서 를 무한히 크게 만들고자 를 엄청 키우게 됨. 는 반대로 이해하면 된다.
⭐️ 그래서 Cliping을 통해 PPO는 이러한 문제를 해결한다.
PPO는 값을 일정 구간에서 clipping(잘라버린다)
- : 가 1에서 너무 멀어지면 정책이 확 바뀌게되어 위험하므로 범위 밖으로 나가도 이득이 더 늘어나지 않게 잘라 버린다.
수식은 다음과 같이 해석된다
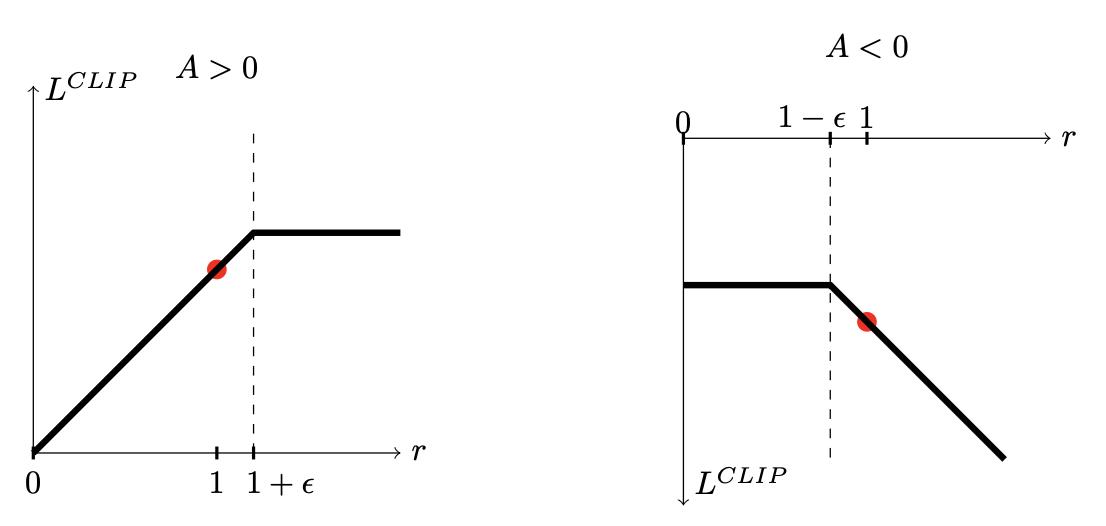
- (좋은 행동) : 를 크게 만들 수록 가 커지지만, 부터는 더 키워도 이득이 늘지 않도록 잘라 상한을 둔다
- (나쁜 행동) : 를 작게 만들수록 목적식이 좋아지는데, 부터는 더 줄여도 이득이 늘지 않도록 하한을 둔다
숫자 예시
unclipped = 1.5, clipped는 가 로 잘려서 1.2
최종은 로 더 크게 올려도 보상 증가가 없다
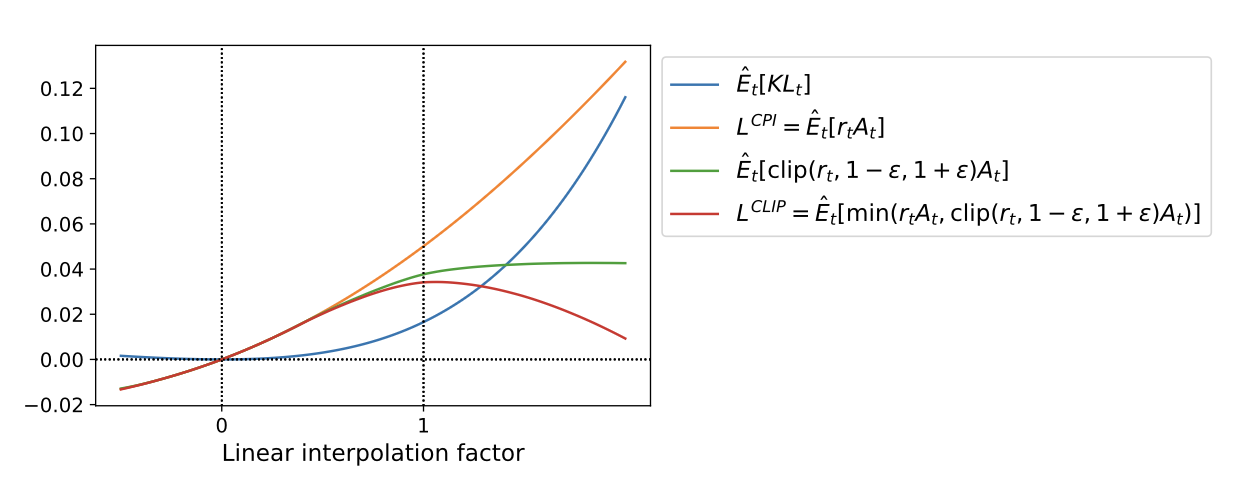
- 파란색 : 새 정책과 예전 정책의 KL divergence, 오른쪽으로 갈수록 정책이 확 바뀌면서 KL이 급격히 커짐
- 주황색 : 제약이 없는 surrogate objective로 업데이트를 크게 하면 계속 값이 커짐
- 초록색 : 일정 구간 이상에서는 평평해져서 더 이상 값이 안 커짐
- 빨간색 : PPO의 목적 = min(주황색,초록색) 그래서 항상 주황색보다 낮거나 같음. 업데이트가 너무 크면 값이 떨어지게 만들어 과도한 업데이트를 억제함
Adaptive KL Penalty Coefficient
clipped surrogate objective의 대안으로 사용하거나 또는 더하여 사용한다.
이 알고리즘의 가장 단순한 구현에서는, 각 정책 업데이트에서 다음 단계를 수행함
-
여러 epoch의 미니배치 SGD를 사용하여 KL-penlaty objective를 최적화함
-
TRPO의 penalty 방식과 달리 학습 중 실제 KL 값인 를 측정해서, 조건에 따라 를 다르게 적용하였음.
업데이트된 는 다음 정책 업데이트에서 사용된다. 이 방식으로, 가끔 KL divergence이 와 크게 다른 정책 업데이트가 발생하기도 하지만, 이는 드물고 는 빠르게 조정이 된다. 위에서 사용한 파라미터 1.5, 2 는 경험적으로 선택된 것이지만, 알고리즘은 그것들에 민감하지 않다. 의 초깃값 또한 하이퍼파라미터지만, 알고리즘이 이를 빠르게 조정하므로 실제로는 중요하지 않음.
Algorithm

전체 흐름은 아래 예시와 같다
1. iteration 1 시작
- actor 10명이, 각자 환경에서 200 step씩 실행 총 2000 데이터 모음
- 각 timestep에서 advantage 값 계산
- surrogate loss를 만들어서 미니배치 학습
- 학습이 끝나면 정책 업데이트
- iteration 2
- 새로운 정책으로 다시 환경 실행, 데이터 수집 반복
| 알고리즘 | 해석 |
|---|---|
| 1. 큰 반복 루프 | 학습은 여러 번의 iteration으로 진행됨 한 iteration = (데이터 수집 + 모델 업데이트) 한 사이클 |
| 2. 병렬 actor 수만큼 반복 | N개의 actor를 동시에 돌려 데이터를 수집함 각 actor는 환경을 T timestep만큼 플레이함 |
| 3. 데이터 수집 | 각 actor는 현재 정책 를 사용하여 T번 행동 그 과정에서 상태, 행동, 보상들을 저장 수집한 trajectory로부터 advantage 추정치 를 계산 |
| 4. 정책 업데이트 | 총 데이터는 actor가 N명이고, 각자 T step을 했으므로 NT개의 데이터 포인트가 모임 이 데이터로 surrogate loss를 구성 그 다음 미니배치 SGD/Adam으로 K번(epoch) 학습 즉, 같은 데이터셋을 여러 번 반복 학습 미니배치 크기 M은 최대 NT까지 가능 |
| 5. 정책 갱신 | 최적화를 끝내고 나면, 새로운 파라미터 를 얻음 이제 로 갱신 다음 iteration부터는 새로운 정책으로 환경을 탐험 |
Loss 함수
PPO에서 최종으로 사용하는 objective loss는 3가지 항목을 더한 것이다
- : 정책을 업데이트할 때 사용하는 PPO의 핵심 policy loss
- :상태 에서 예측한 가치 와 정답의 차이를 줄이는 제곱 오차
- : entropy bonus, 정책이 너무 한 가지 행동만 고집하지 않고, 탐색을 유지하도록 도와주는 항
- : 가중치
Adavantage Estimator
Advantage는 특정 행동이 평균보다 얼마나 좋은지 나타내는 값!
Finite-horizon method
T 길이 구간에서 얻은 보상들과 마지막 상태의 가치 예측을 합쳐 advantage를 추정함. 즉, 지금 행동이 이후의 보상과 비교했을 때 얼마나 이득인지 계산하는 것
PPO는 보통 한 번에 고정된 길이 T 만큼만 샘플을 모아 계산함(즉, 에피소드를 끝까지 안 볼 수 있음). 이 때 마지막 상태를 라고 할 때, ① 이 지점에서 에피소드가 완전히 끝났다면, 앞으로 받을 보상이 없으므로 으로 둔다. ② 만약 아직 에피소드가 안끝났는데 샘플링만 T에서 끊은 것이라면, 이후 보상을 못 봤으므로 모델의 예측()를 써서 나머지를 부트스트랩함. 이렇게 를 사용하면, 짧은 구간만 보고도 "그 이후의 미래"를 적당히 매꿔서 계산할 수 있음.
Generalized advantage estimation ➡️ 보통 PPO에서 사용하는 방법
- : finite-horizon 방식과 같아짐
- : variance를 줄이고 안정성을 높임
즉,는 파라미터로 bias-variance trade-off를 조절할 수 있음
Experiments
Comparison of Surrogate Objectives
No clipping or penalty :
Clipping :
KL penalty (fixed or adaptive) :
실험 세팅
| setting | 설명 |
|---|---|
| 벤치마크 환경 | OpenAI Gym의 MuJoCO 물리 시뮬레이터 기반 7개의 로보틱스 태스크 |
| 학습 스텝 수 | 각 태스크마다 100만 타임스텝 |
| 탐색한 하이퍼파라미터 | 클리핑 계수(), KL penalty 관련 |
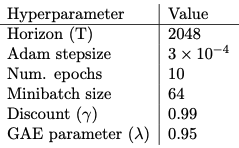
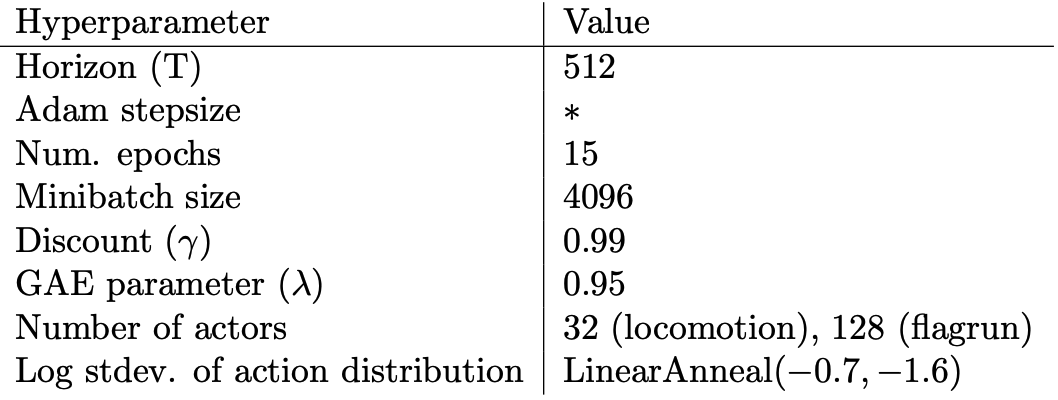
기타 하이퍼파라미터는 아래와 같다
정책 네트워크 구조
- MLP, 은닉층 2개, 각 64 유닛
- 활성홤수 : tanh
- 출력 : 가우시안 분포의 평균(mean)
- 정책 네트워크와 가치 함수는 파라미터를 공유하지 않음 value loss의 계수 은 무의미
- 엔트로피 보너스도 사용하지 않음
실험 방법
- 각 알고리즘 변형을 7개 환경 모두에서 3개 랜덤 시드로 실행
- 점수 산정
- 학습 마지막 100 episode의 평균 총 보상 계산- 환경별로 점수 보정을 함 무작위 정책 = 0점, 최고 성능 정책 = 1점
- 모든 환경 / 실험 평균 최종 스칼라 점수
주요 결과

Comparison to Other Algorithms in the Continuous Domain
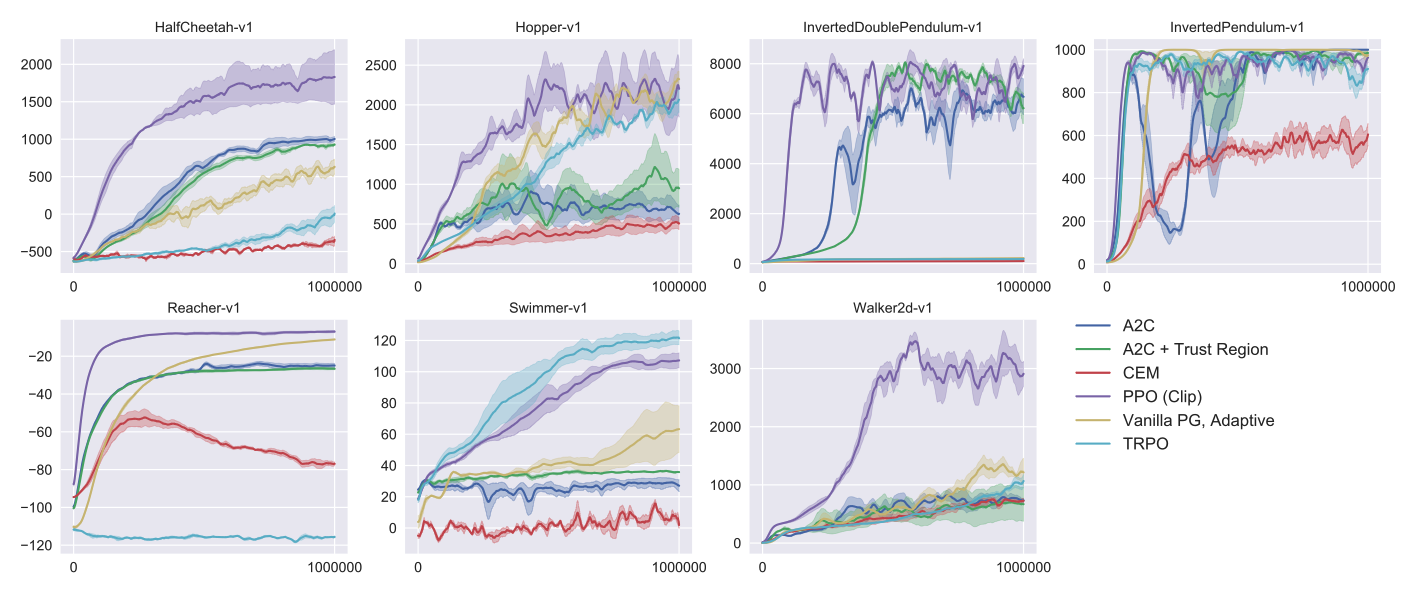
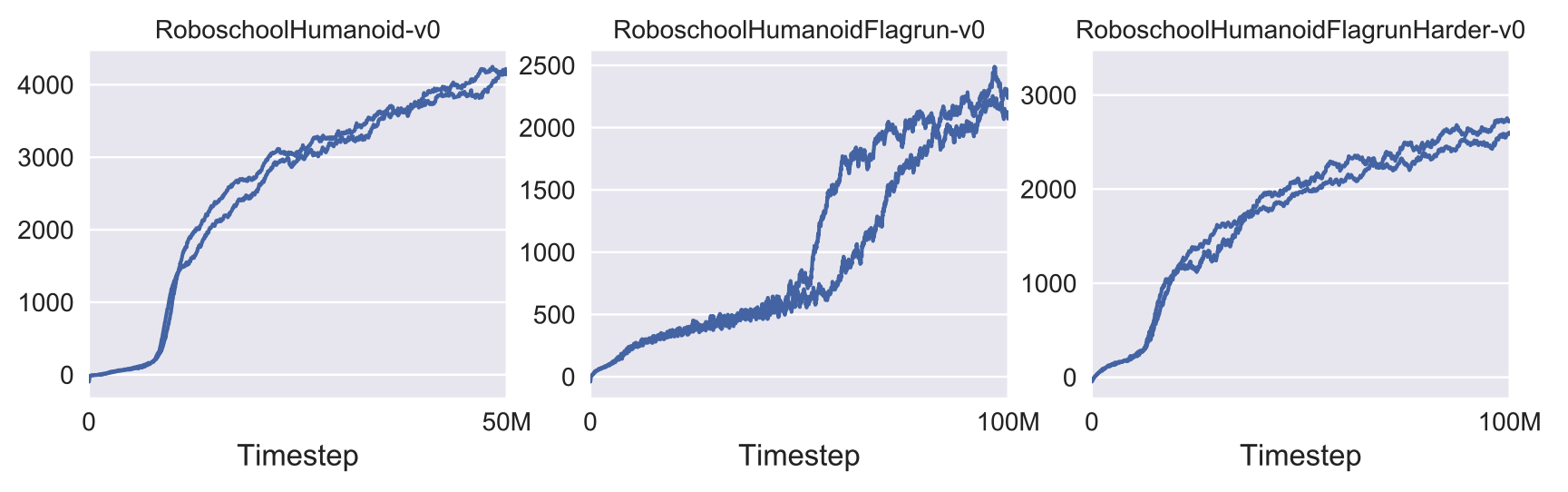
Showcase in the Continuous Domain : Humanoid Running and Steering
| 3가지 과제 | 설명 |
|---|---|
| RoboschoolHumanoid | 전진 보행만 |
| RoboschoolHumanoidFlagrun | 목표 위치가 매 200 timestep마다 혹은 목표에 도달할 때마다 무작위로 바뀜 |
| RoboschoolHumanoidFlagrunHarder | 로봇이 큐브에 맞으면 땅에서 일어나야 함 |
학습된 정책으로 동작하는 휴머노이드의 스틸컷

세 가지 과제에 대한 학습 곡선
하이퍼파라미터 설정은 다음과 같다
즉, PPO는 단순 로봇 달리기뿐 아니라, 목표 변경,큐브 충돌, 넘어졌다 일어나기 같은 복잡한 연속 제어 문제에서도 잘 작동함을 보여주었음
Comparison to Other Algorithms on the Atari Domain

PPO를 Atari 49개 게임에 적용하여, 기존 강력한 정책기반 방법인 A2C, ACER와 비교하였다. 네트워크 구조는 동일하게 맞추었으며, 각자 최적의 하이퍼파라미터를 사용했다. 성능은 ① 전체 학습 기간 동안의 에피소드 평균 보상(빠른 학습을 잘 측정) ② 학습 마지막 100 에피소드의 ㅍ여균 보상(최종 성능을 잘 측정) 두 관점에서 진행하였다.
