INTRODUCTION TO LORA FOR LLMs
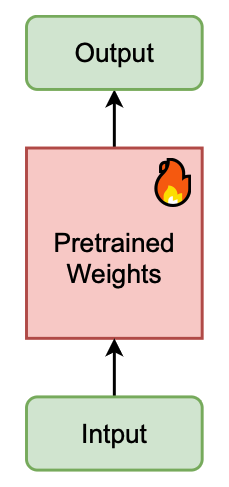
Full Fine-Tuning
모델의 모든 가중치를 업데이트하므로 막대한 자원이 필요함
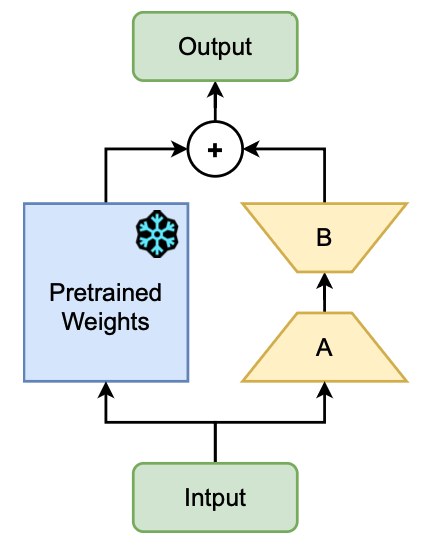
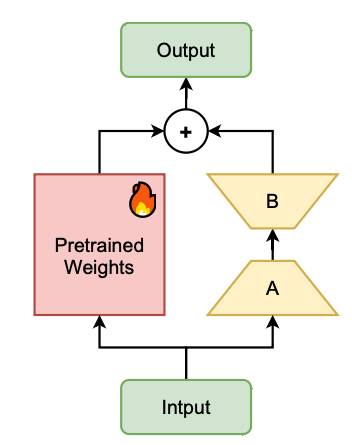
LoRA
모델의 성능을 유지하면서 학습해야 할 파라미터 수를 줄이는 데 효과적
저랭크 행렬 (A,B)를 가중치 업데이트 과정에 삽입함으로써 효율적인 파인튜닝을 가능하게 하며, 기본 모델은 그대로 유지됨
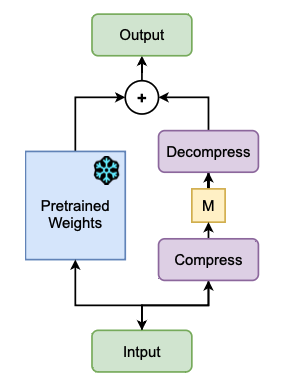
MoRA
기존 LoRA의 저랭크 제약 업데이트 대신 정사각형 행렬을 이용한 고랭크 방식
메모리 집약적인 작업에서 더 나은 성능을 보이며, 특정 상황에서 고랭크 업데이트가 더 복잡한 관계를 포착할 수 있음
게이트 유닛 방식(SoRA)
기존 LoRA는 고정된 랭크의 저랭크 행렬을 사용하였음. 하지만 다양한 입력과 태스크에서 고정 랭크가 최적이 아닐 수 있음. 이를 해결하기 위해, 게이트 유닛을 활용하여 랭크를 동적으로 조절함.LoRA 구조에 게이트 함수를 추가하여, 각 차원별로 랭크 활성화 유무를 결정함
Delta 업데이트 방식(Delta LoRA)
두 개의 저랭크 행렬 곱의 델타()를 이용해, 와 같이 저랭크 행렬뿐 아니라 기존 사전학습된 가중치까지 업데이트하는 방식으로 다운스트림 task에서의 표현 학습 한계를 극복하는 데 기여함
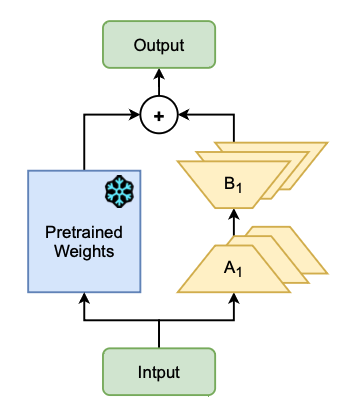
MELoRA
가벼운 저랭크 어댑터 쌍 를 여러 개 도입하고, 각 쌍은 모델의 은닉 표현 공간에서 서로 다른 subspace를 캡처함. 추론 시 아래와 같은 방식으로 어댑터를 가중 평균하여 조합함여기서 가중치 는 학습되거나 입력 / task에 따라 동적으로 예측됨.
- Fixed Ensemble : 모든 LoRA 어댑터의 출력을 평균/합산
- Learned Gating : 게이트 유닛 등을 통해 각 LoRA 어댑터의 기여도를 학습함
이 구조는 전체 파라미터 수는 적게 유지하면서도 높은 효과적인 랭크를 유지할 수 있으며, 과업 요구에 따라 특정 어댑터를 강조하거나 억제하는 유연성을 가짐
ALoRA
ALoRA는 적응 과정에서 랭크를 동적으로 조정함으로써 더 유연한 접근 방식을 제시하며, 튜닝 가능한 파라미터 수는 유지하면서 성능을 향상시킴
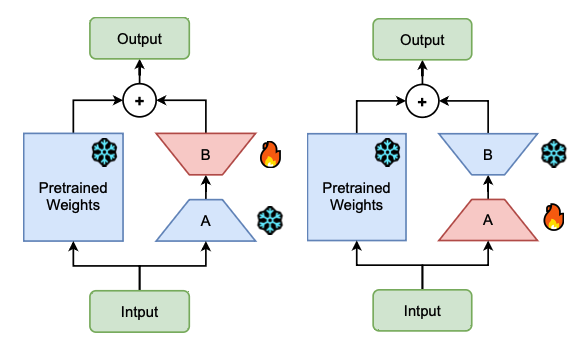
LoRA-FA & LoRA-FB
LoRA-FA와 LoRA-FB는 메모리 효율적인 파인튜닝 기법으로, 각 LoRA 층에서 projection-down 가중치는 고정하고 projection-up 가중치만 업데이트함으로써 성능 손실 없이 메모리 사용을 최적화함.
Dynamic LoRA
게이팅 메커니즘을 도입하여, Transformer 층 전반에 걸쳐 어댑터 강도를 조절함. 정적인 저랭크 투영에 의존하는 대신, 각 층 에서 입력 에 따라 adaptation term을 동적으로 조정하는 gate 를 학습함. 이 메커니즘은 저랭크 적응의 적용 여부를 조건부로결정할 수 있게 하여, 계층별, 예제별로 적응 용량을 보다 효율적으로 할당 가능
CoRA
공유 서브스페이스 관점을 사용함. 각 task의 어댑터가 모든 task에 걸쳐 공유되는 global latent space 안에 있다고 가정하고, task t에 대해 다음과 같이 적응 가중치를 정의함는 모든 task에서 공유되고, 는 task specific 스케일링 행렬임. 이 구조는 제한된 서브스페이스 안에서 저랭크 변환을 수행함으로써 task간 정렬을 유도하고, multi-task나 few-shot 설정에서 일반화 능력을 향상시킴. 즉, 표현 공간을 공유함으로써 task간 효율성과 호환성을 촉진함
LoRA의 작동 원리와 한계를 수학적으로 설명하는 연구들이 등자하였으며 특히 NTK(Neural Tangent Kernal) 관점에서 LoRA가 비정상적 최소값을 피함을 확인되었음. ➡️ 기존 full fine-tuning은 파라미터 공간이 크고 복잡해서, spurious local minima에 빠질 확률이 높았음. 반면, LoRA는 저랭크 구조로 파라미터 공간을 제약하므로 학습 과정이 더 단순하고 평탄한 최적화 지형을 가짐
NTK?
딥러닝 모델이 매우 크고, 학습률이 작을 때, 모델의 학습 과정을 일종의 선형 모델로 근사할 수 있음. 이떄 그 선형 근사를 정의하는 것이 NTK이다.
➡️ 딥런이 모델을 복잡한 비선형 모델로 보지 않고, 학습 과정만큼은 선형 시스템처럼 이해하려는 수학적 기법
즉, NTK는 모델이 어떻게 파라미터를 바꿔서 손실을 줄이는지를 수학적으로 설명해 줌
Spurious Local Minima(비정상적 지역 최솟값)
진짜 정답이 아닌데 최적처럼 보이는 학습 결과
현재 남아 있는 도전 과제는
1. 효율성 vs 성능 간의 트레이드오프
2. 다양한 작업에의 범용성
3. LoRA의 이론적 이해 부족
4. 모델의 해석 가능성
5. 지식 증류, 양자화, 압축 기법과의 연계 필요성
BACKGROUND AND FOUNDATIONS OF LORA TECHNIQUES
LoRA는 LLM을 효율적으로 파인튜닝하는 방법으로 널리 사용됨. 단순한 구조와 우수한 성능 덕분에 주목받고 있으며, 언어 모델을 넘어 범용 기반 모델(다양한 task에 폭넓게 적용 가능한 사전 학습된 LLM)로 까지 적용 범위가 확장됨.
LoRA는 파인튜닝 시 계산량 및 메모리 사용량 절감, 모델 성능 유지 또는 향상을 목표로 하고 있으며, 기본적인 LoRA는 한계가 있으므로 MoRA, Delta-LoRA 등 다양한 변형이 발전 중임.
LoRA 계열 기법은 모두 행렬 분해 기반의 업데이트 전략을 사용한다. 이들은 지시문 튜닝, 수리 추론, 지속적 사전학습 등 다양한 작업에 적용되어 효율성과 성능을 동시에 입증하였음. 이러한 기법의 핵심 장점은 메모리 사용량과 계산량을 현저히 줄이면서, 성능을 유지하거나 오히려 향상시킬 수 있다는 점이다.
하지만 저랭크 업데이트의 구조적 제약으로 인해, 일부 복잡하거나 정밀한 작업에서는 성능 병목이 발생할 수 있으며, 이러한 문제를 해결하기 위해 MoRA를 통해 고랭크 행렬을 사용하여 표현력을 강화하기도 하였음.
이런 확장에는 계산 비용 증가가 따르므로, 효율성과 성능 사이의 균형 조절이 매우 중요하다.
현재까지의 기법들은 실용적 성능은 뛰어나지만, 저랭크 근사가 왜 효과적인지에 대한 이론적 설명은 아직 부족하며 최근 연구들은 이들 메커니즘을 수학적, 해석적으로 설명할 수 있는 프레임워크 마련을 시도하고 있음.
더 큰 모델과 다양한 도메인에서 LoRA가 견고하게 작동하도록 일반화하는 것이 핵심 과제이며 이들 기법의 내부 작동 원리에 대한 이론적 통찰을 심화시켜, 더욱 신뢰할 수 있는 기술로 발전시켜야 함. 실용적 측면에서는 전이학습, 메타학습 등 넓은 응용 영역과의 연결성이 부각됨.
OVERVIEW OF LoRA METHODS FOR FINE-TUNING
LoRA는 훈련 파라미터 수를 줄일 수 있다는 점에서 높이 평가되지만, 전체 성능은 단순한 구조적 효율성 이상에 달려 있음. 특히, 모델 크기가 커질수록 메모리 사용량이 중요한 과제가됨. 이를 해결하기 위해 LoRA-FA, MoRA와 같은 기법이 고안되어 메모리 소비를 줄이면서도 성능을 유지함
또한 연구자들은 하이퍼파라미터 튜닝에도 주목하고 있음. 랭크 크기, 학습률 등 주요 하이퍼파라미터 선택은 저랭크 적응 성능에 큰 영향을 미치며, 이에 따라 저랭크 적응 특성에 맞춘 최적화 전략이 다수 제안되었음. GeLoRA, CoRA, RoRA
이러한 방식들은 정형화된 일률적 접근 대신, task 별로 맞춤형 전략을 가능하게 하며, 저랭크 적응이 점차 다양하고 유연한 방향으로 진화하고 있음을 보여줌.
보통 LoRA는 가중치 행렬을 SVD 또는 랜덤 SVD 등을 통해 저랭크로 근사하는 방식을 사용함. MoRA는 정사각행렬로 고랭크 업데이트를 구현하며, ALoRA는 AB-LoRA 라는 새로운 방법을 통해 각 LoRA 랭크의 중요도를 추정하고 불필요한 랭크를 동적으로 제거함. LoRA-FA는 projection-down은 고정하고, projection-up만 업데이트하여 활성화 메모리를 줄이며, 하이퍼파라미터 최적화는 NoMAD 알고리즘을 사용함. 지식 증류나 프루닝 기법들도 효율성 향상을 위해 연구되고 있음.
한계점
- LoRA는 표준 환경에서 full fine-tuning 만큼의 성능을 항상 보장하지 않음
- LoRA는 여전히 메모리 효율성이 과제로 남아 있으며, 이를 해결하기 위한 방법들은 성능을 저하시킬 수 있거나 계산 복잡도를 증가시킬 수 있음
- ALoRA처럼 적응 과정에서 내재 랭크를 동적으로 조절하는 기법은, 그 의미와 실제 적용 가능성을 완전히 이해하기 위해서는 추가적인 연구가 필요
TECHNICAL DEEP DIVE INTO LoRA ALGORITHMS
초기 LoRA는 고정된 가중치 층에 저랭크 행렬만 삽입하여 학습하는 구조였지만 이후 연구들은 확장성, 유연성, 과업 적응력을 높이기 위해 다양한 확장 기법을 제안함. 이러한 관점은 LoRA가 단순한 고정 전략을 넘어, 표현력, 효율성, 제어 가능성 사이의 다양한 트레이드오프를 포함하는 설계 공간으로 진화하고 있음을 시사함.
이러한 진화는 SoRA와 Delta-LoRA같은 새로운 방법들의 등장으로 구체화되고 있음
SoRA는 게이트 유닛을 도입하여 입력 특징이나 그래디언트 통계에 따라 각 층의 저랭크 행렬의 랭크를 동적으로 조절함. 이 유닛은 proximal gradient method로 훈련되며, 복잡한 task에 대해서는 선택적으로 모델 용량을 증가시키는 유연성을 제공하고, 전체적으로는 희소성을 유지하여 파라미터 효율성을 확보함. 또한, 구조적 pruning과 저랭크 분해의 장점을 결합한 스케줄러 기반 학습 방식을 사용하여 중요한 랭크만 유지함.
Delta-LoRA는 단순히 LoRA의 저랭크 행렬만을 업데이트하는 것이 아닌, 기존의 사전학습된 가중치까지 변경함. 이 방식은 고정된 저랭크 모듈의 병목을 회피하고, temporal dynamics를 반영함으로써, 학습 신호가 어댑터뿐 아니라 기저 모델 전체로 확산될 수 있음. 실험 결과에 따르면, 이 방식은 특히 데이터가 적은 환경에서 더 빠른 수렴과 우수한 downstream task 전이 학습 성능을 보여줌.
이 두 기법은 저랭크 구조를 다양한 보조 메커니즘과 결합함으로써, 모델의 적응 용량에 대한 제어 능력을 크게 향상시키는 추세를 보여줌.
problem
1️⃣ 확장성임. SoRA는 희소성 정규화, 게이트 유닛, 스케줄러 등으로 인해 훈련 복잡도가 증가하고 깊은 트랜스포머 구조에서는 학습 안정성과 하이퍼파라미터 민감성 이슈가 발생하였음.
2️⃣ 이론적 기반 부족
직관적으로는 타당해 보일 수 있지만, 동적 랭크 선택이나 델타 기반 업데이트가 모델의 일반화 행동이나 용량 제어에 어떤 영향을 미치는지 아직 명확하지 않음. 저랭크 적응이 언제, 왜 효과적인지를 설명할 수 있는 분석 도구가 부족하여 이러한 방법들을 체계적으로 향상시키는 데 한계가 존재
3️⃣ 도메인 이동, 적대적 상황에서 다양한 데이터셋과 도메인 전반에서의 견고함을 보장하는 것이 어려움
COMPARISON OF LORA WITH FULL FINE-TUNING: PERFORMANCE AND TRADE-OFFS
LoRA
LoRA는 full fine-tuning에 비해 학습해야 할 파라미터 수를 크게 줄일 수 있으므로, 메모리와 연산 자원이 제한된 응용 사례에서 매력적임.
LoRA는 기본 모델의 일반화 능력을 유지하는 데 탁월하므로 모델이 OOD에 노출되는 상황에서 강점을 보임. 또한, catastrophic forgetting을 완화하고, 일반적인 작업 성능을 유지하는 데 효과적임.
Full Fine-Tuning
표현력이 많이 요구되고 모델 가중치에 대해 더 깊고 task specific한 조정이 필요한 작업에서는 full fine-tuning이 더 좋은 경우가 많음.
모델 성능과 파라미터 효율성 간의 트레이드오프는 저랭크 적용 기법 설계에서 두드러짐.
LoRA의 저랭크 행렬의 랭크를 높이면 특정 작업에서 성능이 향상될 수 있지만, 연산 부하 또한 증가하게 됨.➡️ 메모리 제약이 있는 환경이나 추론 지연 시간이 중요한 응용 사례에서 특히 문제
이러한 문제를 해결하기 위해 RoRA와 같은 기법에서 학습률 스케줄링과 스케일링 계수 보정 등의 최적화 전략이 개발되었음. 이러한 조정은 성능을 희생하지 않으면서 계산 부담을 줄이는 데 기여함. LoRA-FA는 일부 갖우치를 고정하고 활성화를 재계산함으로써 메모리 사용량을 최적화하지만, 모든 경우에 성능 향상을 보장하지 않음.
LoRA와 Full fine-tuning은 task 성능에서 유사할 수 있지만, 가중치 행렬의 SVD는 구조적으로 매우 다른 형태를 보이며, 이를 통해 두 방식이 본질적으로 다른 해에 수렴하고 있음을 시사함.

다양한 기법들의 지속적인 개선 및 효율성과 과업 특화 성능 간의 간극을 메우기 위한 새로운 기술의 개발이 LLM 파인튜닝의 발전을 위한 핵심 요소가 될 것임.
ADVANCED LoRA TECHNIQUES : ROBUST ADAPTATION, SPARSE FINE-TUNING, AND HYBRID APPROACHES
기존 LoRA는 효율적이지만, 복잡한 task나 고정된 랭크 구조에 한계가 존재하였음. 최근 연구는 LoRA의 한계를 넘기 위해 희소성, 동적 랭크, 하이브리드 구조를 활용하여 효율성과 성능의 동시 확보가 목표임
주요 advance LoRA는 다음과 같음
RoSA
저랭크 구성 요소와 sparse 구성 요소를 결합함.
Robust PCA를 이용하여 안정성과 적응력 확보
LoRA보다 복잡한 task에서 우수한 성능
SoRA
게이트 유닛을 통해 랭크를 동적으로 선택
sparsifying 스케줄러를 통해 파라미터 유지 여부의 영향 평가
LoRA보다 더 높은 유연성과 파라미터 절감 하에서의 성능 향상 가능성
CoRA
common subspace를 활용
LoRA의 파라미터 수와 계산 비용을 줄임
특히, sparse 기반 및 하이브리드 접근에 대한 탐구가 중심이 되고 있으며,최근 연구에서 희소 LLM을 위한 효율적인 저랭크 적응 기법, 저랭크 적응의 베이지안 재파라미터화를 통한 강건하고 효율적인 파인튜닝을 탐구하므로써, 강건성과 일반화 능력의 중요성을 강조함.
하지만 여전히 남아 있는 문제는
1️⃣ 성능 트레이드오프임. 이러한 기법들은 파라미터 수와 메모리 사용 면에서는 효율적이지만, 복잡한 과업에서는 전체 파인튜닝에 미치지 못하는 경우가 많음.
2️⃣ 적절한 적응 기법을 선택하는 것. 작업 특이성, 데이터셋 크기, 모델 구조, 배포 제약조건 등 다양한 요소에 따라 달라짐
3️⃣ 매우 큰 모델에 대한 적용과 도메인 및 작업 간 일반화
저랭크 업데이트가 내부 모델 표현과 어떻게 상호작용하고 이를 어떻게 제어하거나 강화할 수 있는지를 탐구하는 것은 향후 중요한 연구 방향이며 앞으로는 보다 적응형이며 이론적으로 기반이 탄탄한 저랭크 기법들이 LLM 파인튜닝 전략의 다음 단계를 주도할 가능성이 큼.
최근 기법에서 나타난 동적으로 조정 가능한 랭크, 희소성 인식 스케줄, 신뢰도 기반 적응은 더 유연하고 맥락 인식적인 설계로의 전환을 예고하며 이러한 방법들이 성숙함에 따라 빠른 도메인 적응과 자원 효율성이 중요한 응용 사례에서 LLM의 확장성을 보다 지속 가능한 방식으로 달성할 수 있을 것으로 기대됨.
LoRA의 영향은 모델 효율성을 넘어, 기계 번역, 요약, 대화 시스템 등 다운스트림 task에도 확장되고 있으며, 궁극적으로, LoRA의 성공은 단지 실험적 성능 향상뿐만 아니라, 이 기술을 신뢰할 수 있고, 일반화 가능하며, 해석 가능한 NLP 시스템에 어떻게 통합할 수 있는지에 달려 있음.
MODULAR AND PLUG-AND-PLAY LoRA FOR MIXED TASKS AND DYNAMIC SCENARIOS
LLM을 다양하고 변화하는 task 요구에 적응시키기 위해서, 단순히 파라미터 효율적일 뿐 아니라 모듈형이며 유연한 방식이 필요함.
full fine-tuning과 초기 저랭크 기법들은 일반적으로 고정된 task 맥락과 정적인 어댑터 구조를 전제로 하므로, multi-task나 동적인 환경에서 확정성에 한계가 있음.
최근 연구는 모듈형 및 플러그 앤 플레이형 저랭크 적응 방법에 초점을 맞추고 있음. task에 따라 선택적으로 삽입, 교체, 조합이 가능한 adapter를 설계하는 것을 목표로 함.
전체 모델을 재훈련하거나 중복시키지 않고도, 입력 분포의 변화와 task 복잡성에 따라 LLM을 어떻게 유연하게 적응시킬 수 있을까?
이는 monolithic 방식에서 compositional한 파인튜닝으로의 전환을 의미함.
아래 표는 설계 철학, 파라미터 구조, 업데이트 전략, 과업 민감도, 모듈성 등 여러 측면에서 비교한 것임.

비록 이러한 기법들이 점점 정교해지고 있지만, 여전히 해결되지 않은 주요 과제들이 존재함
1️⃣ 현재 접근 방식들은 어댑터 배치 및 선택에 있어 경험적 휴리스틱에 과도하게 의존하고 있음
2️⃣ 일반화와 task 특이성 사이의 균형 유지가 쉽지 않음
3️⃣ 플로그 앤 플레이 방식에서 어댑터 수가 많아지거나 상호작용이 예측 불가능해질 경우, 계산상의 이점이 오히려 상쇄될 수 있음
4️⃣ 모듈형 저랭크 적응이 왜 그리고 언제 효과적인가에 대한 이론적 기반은 여전히 부족함
미래 방향은 단일 어댑터의 정교화보다는, 여러 어댑터를 상황에 맞게 조합/전환/우회할 수 있는 '컨트롤러 프레임워크'개발이 미래의 핵심 방향임.
입력 특징과 과업 요구를 분석하여 상황에 따라 적절한 어댑터를 선택하거나 조합하며 동적 경로 설정으로 특정 모듈은 활성화하고, 일부는 우회하거나 억제함. self-supervised signals또는 proxy objectives 학습 방식을 통해 성능과 효율성 트레이드오프를 자율적으로 최적화함.
또한 모듈형 어댑터는 언어나 모달리티에 특화된 지식을 내포할 수 있으며 컨트롤러는 언어나 도메인에 따라 적절한 어댑터 경로를 자동 선택할 수 있음 이는 모듈형 파인튜닝의 범용성과 확장성을 크게 높임.
⭐️ 이러한 방향성은 저랭크 적응의 미래가 더 정교한 어댑터를 설계하는 데 있지 않고, 더 단순한 어댑터를 보다 지능적으로 조율하는 데에 있다는 점을 시사함.
APPLICATIONS OF LoRA IN REAL-WORLD SCENARIOS: CHALLENGES AND OPPORTUNITIES
고정된 랭크를 사용하는 LoRA로는 매우 큰 모델이나 복잡한 작업에서 성능이 떨어지므로, MoRA, SoRA, MELoRA 같이 작업에 따라 조절할 수 있는 구조로 진화하고 있다. 하지만, 실시간 처리, 복잡한 입력, 모델 크기 증가에 따라 성능을 유지하는 데 어려움을 겪고 있으며 저랭크 방식들은 여전히 다양한 task에 적응하는 데 한계가 있음.
그러므로, 향후 연구는 하드웨어에 맞춘 스케줄링 & 저랭크 적응의 더 나은 통합 & 모델 크기와 task 복잡성에 따라 확장 가능한 자가 적응형 랭크 할당 방법 개발에 집중해야할 필요가 있음.
저랭크 적응 기법은 NLP 작업을 넘어 더 넓은 영역으로 확장되고 있음
- 컴퓨터 비전
- 멀티모달 학습
- 세말한 적응이 요구되는 기타 대형 모델 환경
하지만, 확장성, customization, adaptability와 같은 과제는 단순한 기술 문제를 넘어 훈련 프레임워크, 하드웨어 최적화, 추론 파이프라인 전반에 걸친 시스템 차원의 접근이 필요하며 이러한 도전 과제들을 해결함으로써, 저랭크 적응은 효율적이고 효과적인 머신러닝의 미래에서 핵심적인 역할을 수행하게 될 것이며, 다양한 응용 분야에 LLM을 광범위하게 배포할 수 있는 기반이 될 것임.
ANALYSIS OF LEAREND SOLUTIONS : SPECTRAL PROPERTIES, GENERALIZATION BEHAVIORS, AND INTRUDER DIMENSIONS
스펙트럼 분석에 따르면 LoRA와 Full Fine-TUning이 만들어내는 가중치 행렬은 본질적으로 다르며, 이는 일반화 행동에 깊은 영향을 미침
LoRA로 학습된 모델은 일부 task에서 유사한 성능을 보일 수 있지만, OOD task에서는 intruder dimension의 존재로 일반화 성능이 떨어질 수 있음. intruder dimension은 task와 관련된 특성과 일치하지 않는 방향성을 가지며, 이는 OOD 성능을 저해할 수 있음을 시사함
➡️ 이러한 점은 중요한 트레이드오프를 강조함. LoRA는 훈련 파라미터 수를 줄이지만, full fine-tuning에 비해 일부 일반화 능력을 희생할 수 있다는 점. full fine-tuning은 모델의 전체 스펙트럼 가중치를 사용하는 반면, LoRA는 제한된 저랭크 하위공간만을 활용하기 때문임.
스펙트럼 특성을 활용한 일반화 오류 분석은 적응 전략에 따라 모델의 행동이 어떻게 달라지는지를 이해할 수 있는 이론적 틀을 제공함.
침입 차원의 영향은 여전히 활발히 연구되는 주제이며, 동적 랭크 조정, MELoRA와 같은 앙상블 방식이 복잡도를 증가시키는 대신 더 나은 일반화 능력을 제공할 수 있는 잠재적 해결책으로 여겨짐. 하지만 이들 방법은 계산 비용이 더 많이 들 수 있다는 단점도 동반함
LoRA 모델 파인튜닝에서 하이퍼파라미터 튜닝, 특히 랭크 크기와 학습률 조절은 중대한 도전 과제로 남아 있음. 랭크, 학습 시간, 일반화 성능 간의 최적 균형을 찾는 것은 아직 해결되지 않은 문제이며, 모델 크기가 커질수록 이 균형을 맞추는 데 필요한 복잡성도 커짐.
향후, 이러한 파라미터들을 훈련 중 자동으로 조절할 수 있는 더욱 강건한 알고리즘 개발이 요구되며, 침입 차원의 영향을 최소화하고, 저랭크 적응 기법의 확장성과 일반화 능력을 향상시키기 위해 하이퍼파라미터 최적화에 집중할 것으로 보임.
효율성, 일반화, 계산 비용 간의 트레이드오프는 저랭크 적응에 대한 지속적인 연구의 필요성을 부각시키며, 그 핵심은 다음과 같은 영역에 대한 이해를 확장하는 데 있음. 스펙트럼 특성, task-specific adaptation, 침입 차원의 영향
이러한 문제를 해결함으로써, 저랭크 적응의 잠재력을 완전히 실현할 수 있을 것이며, 더 광범위한 응용 분야에서 효율적이고 확장 가능한 파인튜닝이 가능하게 할 것임.
FUTURE DIRECTIONS AND OPEN CHALLENGES IN LoRA RESEARCH
분석된 논문들 전반에서 공통적으로 강조되는 주제는 효율성과 확장성이며, 저랭크 적응 기법은 파라미터 효율적인 파인튜닝을 가능하게 하는 기술로 인정받고 있음. 또한, 적응성과 일반화 능력에 대한 중요성도 반복적으로 등장함.
여러 논문에서 특정 다운스트림 작업에 대한 모델 적응성 향상과 다양한 과업 간 일반화 성능 향상을 주요 목표로 삼고 있음. 저랭크 근사와 그 응용은 현대 데이터 분석에서 근본적인 기술로 간주되며, 응용 분야도 NLP를 넘어, 컴퓨터 비전, 과학적 발견 등으로 확장되고 있음
하지만 다음과 같은 제약과 도전 과제가 남아 있음
- 확장성과 강건성
- 이론적 이해 부족
- 과업 다양성과 일반화 문제
- 효율성과 효과성 간의 균형 문제
특히, 복잡한 상황에서 저랭크 근사와 적응이 실제로 어떻게 작동하는지를 설명할 수 있는 더 깊은 이론적 통찰이 요구됨. 또한, 모델 일반화를 손상시키지 않으면서도 다양한 과업을 효과적으로 처리할 수 있는 능력 역시 여전히 도전 과제로 남아 있으며, 저랭크 적응 기법의 파라미터 효율성과 새로운 지식 학습 및 기억 능력간의 균형을 맞추는 것은 지속적인 연구 과제임.
궁극적으로, 저랭크 적응 연구는 다양한 도메인과 응용 분야와 밀접하게 연결되어 있으며, 지속적인 혁신과 탐색이 필요한 매우 중요한 영역임.
OUTLOOK FOR LoRA IN LLMs
LoRA 분야는 LLM의 효율성과 확장성 향상에 있어 놀라운 진전을 보여주었고, 사전학습된 모델을 다양한 task에 적응시키기 위한 유망한 방향을 제시하고 있음
LoRA는 성능을 유지하면서 훈련 가능한 파라미터 수를 줄이는 능력 덕분에 NLP를 포함한 다양한 분야에서 널리 채택되는 방법이 되었음. 최근 연구는 NTK 체제 내에서 LoRA가 spurious local minima을 제거하여 일반화 능력을 높인다는 이론적 근거를 더욱 확고히 하고 있음
LoRA의 성공은 여러 확장 기법의 개발로 이어졌으며, 이들은 표현력 향상 및 적응력 개선을 목표로함. 이러한 확장 기법들은 LoRA의 저랭크 접근이 효과적이라는 점을 인정하면서도, 고랭크 및 동적 적응 방식이 특히 더 많은 기억 용량이 필요한 과업에서 성능 향상을 제공할 수 있음을 보여줌
하지만 여전히 파라미터 효율성과 모델 표현련 간의 핵심적인 트레이드오프는 존재함. LoRA와 그 변형들은 훈련 파라미터 수를 줄이는 데는 성공했지만, 복잡한 task에서 일반화 능력을 손해 보는 경우가 있음.
다양한 LoRA 기법들을 더 큰 모델이나 복잡한 과업에 확장하는 문제는 반복적으로 등장하는 과제로 LoRA는 중간 규모 모델까지는 잘 확장 가능하지만, 몇몇 방법은 더 유연한 과업 간 일반화 성능을 제공하는 대신, 계산 비용이 더 덜어가는 단점도 있음
따라서 향후 연구에서 다음과 같은 방향의 확장성 문제 해결이 중요해질 것임
- 멀티태스크 학습
- 실시간 적응이 필요한 응용
- 스펙트럼 학습
- 적응형 랭크 할당
- 하드웨어 인식 최적화
효율성, 확장성, 적응성의 조합은 저랭크 적응을 기계 학습 발전의 핵심 기술 중 하나로 자리잡게 할 것이며, 이를 통해 더 강력하면서도 자원 효율적인 모델의 폭넓은 응용 및 배포가 가능해질 것임.
CONCLUSION
LoRA는 LLM을 파인튜닝하기 위한 효율적인 방법으로 부상했으며, 파라미터 복잡도를 줄이면서도 성능을 유지할 수 있는 기술로 자리매김했음. 하지만, task-specific knowledge를 완전히 포착하지 못하는 한계로, MoRA 및 Delta-LoRA와 같은 대안적 접근 방식이 등장하게 되었음. 이들은 고랭크 업데이트 및 동적 조정을 도입함으로써 이러한 한계를 보완하고자 함.
그럼에도 불구하고, 다음과 같은 여러 도전 과제들이 여전히 남아 있음
- 확장성
- task별 성능 편차
- 더 깊은 이론적 이해의 필요성
향후 연구는 이와 같은 과제들을 해결하면서, 저랭크 방식의 확장성, 효율성, 적응성을 더욱 향상시키는 데 집중해야 함. 이를 통해 다양한 응용 환경에 적합한 최적의 LLM 파인튜닝 전략을 구축할수 있을 것임.
