LoraRetriever
Abstract
LoRA는 모듈화되어 있고 플러그 앤 플레이 방식으로 다양한 도메인 특화 LoRA를 통합하여 LLM의 성능을 향상시킬 수 있음. 실제 환경에서는 LLM이 다양한 작업을 포함한 프롬프트를 받으며, 사용 가능한 LoRA의 pool은 동적으로 변화하는 경우가 많음
이러한 간극을 해소하기 위해 LoraRetriever라는 '검색 후 구성' 프레임워크를 제안함. 이 프레임워크는 입력 프롬프트에 따라 LoRA들을 적절히 검색하고 조합할 수 있도록 설계되어 있음.
LoraRetriever는 다음 세 가지 주요 구성 요소로 이루어져 있음
1. 주어진 입력에 적합한 LoRA들을 식별하고 검색하는 단계
2. 검색된 LoRA들을 효과적으로 통합하기 위한 전략 수집
3. 다양한 요청을 수용할 수 있도록 효율적인 배치 추론 구현
Introduction
기존 연구 한계
-
학습 단계에서 LoRA 선택이 고정되어 있어, 시간이 지나면서 계속 확장될 수 있는 LoRA Pool을 다루기에는 유연성이 부족함.
-
LoRAhub와 AdapterSoup은 특정 다운스트림 작업을 위한 LoRA 조합을 시도하지만, 이들 방법은 모든 작어베 단일한 조합 방식을 적용하는 일괄적 접근이므로 실제 다양한 요청을 반영하는 데 한계가 있음
이러한 문제를 해결하고자 본 논문에서는 ChatGPT와 Gemini처럼 다양한 사용자 요청이 혼합된 혼합 작업 시나리오를 탐구함. LLM은 다양한 작업을 하나의 모델로 해결할 수 있는 통합된 솔루션을 제공하지만, 일부 특수 작업에서는 여전히 성능이 저하될 수 있음. ➡️ 이럴 때 LoRA의 통합이 매우 중요한 역할을 함!
논문에서 제안하는 비전은 아래 그림에 나와 있듯이, 새로운 LoRA 모듈이 추가 및 업데이트됨에 따라 지속적으로 기능을 향상시킬 수 있는 다중 LoRA 제공 프레임워크임. 이 프레임워크는 LoRA의 플러그 앤 플레이 특성을 활용하여 다양한 요청에 대해 개인화된 서비스를 제공할 수 있음.
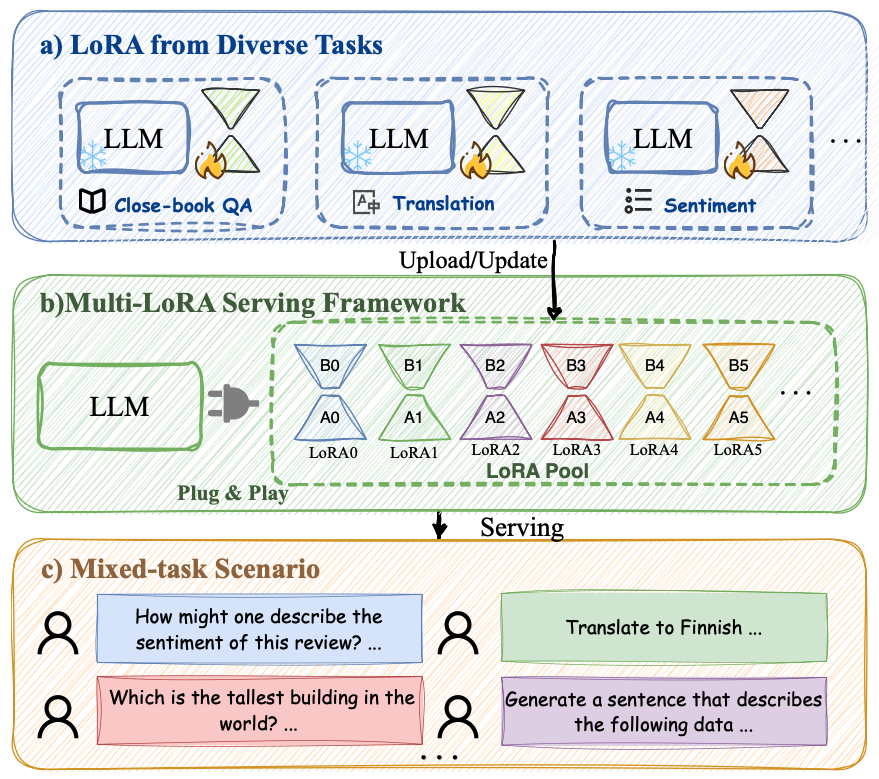
LoraRetriever의 세 가지 핵심 요소
1. 입력 인식 기반 LoRA 검색 ( Input-aware LoRA Retrieval )
사용자의 입력을 문장 임베딩을 통해 적절한 LoRA와 정렬하며, 이를 LoRA 검색을 위한 instruction fine-tuning을 통해 정밀하게 조정함. 이를 통해 LLM의 학습 및 추론과 분리된 유연한 LoRA 라우팅 메커니즘을 구축함2. LoRA 조합 ( LoRA Composition )
검색된 LoRA들을 조합하는 방식으로 두 가지 전략 사용
- LoRA Fusion : 여러 LoRA 파라미터를 평균 내어 하나의 통합 모델 구성
- Mixture of LoRAs : 여러 LoRA 모듈을 동시에 활성화하고, 각 서브모듈의 출력을 평균. 이를 통해 top-k LoRA 조합을 수행하여, 정확한 LoRA 검색률을 높이고, 유사한 작업의 LoRA를 통합함으로써 보지 못한 작업에 대한 일반화 성능도 향상시킴
3. 배치 추론 ( Batch Inference )
기존 입력 기반 LLM 추론 방식은 배치 처리를 지원하지 않거나 효율이 떨어졌음. 본 논문에서는 배치 샘플마다 고유한 LoRA 매핑 행렬을 생성하여, 효율적인 행렬 곱 연산을 통해 각 요청이 해당하는 LoRA를 활성화하면서도 배치 처리 효율을 유지할 수 있게 함
Preliminaries
Problem Formulation
mixed-task scenario를 형식적으로 정의함
기존의 LLM 이 주어졌을 때, 우리는 k개의 LoRA 집합 를 보유하고 있다고 가정 ( 각 LoRA 는 특정 작업 에 대해 훈련되었음 )
혼합 작업 입력은 다음과 같이 정의할 수 있음
혼합 작업 시나리오에서, 태그가 없는 입력 이 주어졌을 때, 서비스 과정은 다음과 같이 표현됨
- : LLM의 원래 파라미터
- : 입력 기반 LoRA 검색 함수, 즉 입력 에 적합한 LoRA 집합 를 반환
- : LoRA 조합 함수, 검색된 LoRA들을 LLM에 플러그인 형식으로 통합하여 최종 출력을 생성함
LoraRetriever Framework
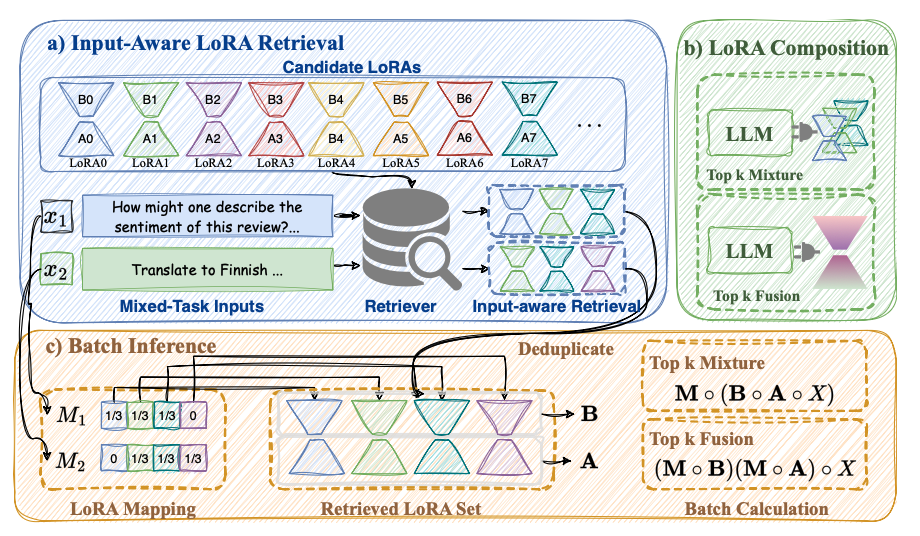
a ) Input-Aware LoRA Retrieval
이 프레임워크는 어떤 입력 문장이 들어오면, 그 문장을 가장 잘 처리할 수 있는 LoRA를 자동으로 찾아주는 기술임.
기존 방식의 한계
- MoE 기반 기법
LoRA 선택이 모델이 처음 학습될 때 고정 ➡️ 새로운 LoRA가 추가되면, 기존 방식은 이전에 학습된 LoRA를 고려할 수 없으므로 일반화 성능이 낮음- 문장 임베딩 기반 검색 방식
입력 문장과 LoRA를 같은 공간에서 임베딩하지 못함 ➡️ 서로 비교가 불가 ➡️ 검색 성능이 떨어짐
instruction fine-tuning을 통해 LoraRetriever를 학습할 것을 제안함. 대규모 LoRA 풀에서 입력 샘플에 적합한 LoRA를 검색할 수 있도록 설계됨
LoraRetriever는 주어진 입력 샘플에 대해 방대한 LoRA pool에서 적절한 LoRA들을 검색할 수 있는 시스템이다.
1️⃣ LoRA 임베딩 방식 ➡️ LoRA를 하나의 벡터로 만들자
LoRA는 모델의 일부 모듈이므로 비교 가능한 "문장"이나 "벡터"가 아님
그래서 우리는 LoRA가 훈련된 Task의 문장들을 대표 샘플로 선택하고, 이 문장들에 instruction을 붙여 임베딩한 후, 그 임베딩의 평균값을 LoRA 전체를 대표하는 벡터로 사용함
각 LoRA 모듈 는 해당 도메인의 무작위 샘플 m개를 사용하여 다음과 같이 임베딩됨
- 문장 임베딩 모델 :
- 입력 시퀀스 :
- 임베딩을 위한 instruction : I
- 입력 임베딩 :
2️⃣ 입력 문장과 LoRA의 유사도 계산
입력 문장 를 instruction과 합쳐서 임베딩하고, LoRA 임베딩과 cosine similarity로 유사도를 계산함
3️⃣ Instruction Fine-Tuning : 검색기 학습
LoRA 검색기의 성능을 향상시키고 보지 못한 LoRA에 대한 일반화 능력을 강화하기 위해, 임베딩 모델()를 instruction fine-tuning 방식으로 일부 작업에 대해 학습시킴
Contrastive 데이터로 임베딩 모델을 학습시키고, contrastive loss를 기반으로 유사도를 조절해서, 같은 Task의 문장은 가깝게, 다른 Task는 멀게 만듦
새로운 샘플에 접근할 필요를 줄이기 위해, 이미 LoRA 임베딩에 사용된 샘플들을 학습 데이터로 활용함.
① 학습에 사용할 작업 집합
이를 위해 서로 다른 개의 학습 작업을 고려하며, 이는 다음과 같이 표현됨
전체 작업 중 일부만 선택하여 실제 환경에서 새로운 LoRA가 점진적으로 추가되는 상황을 가정함
② 샘플 쌍 생성
학습 데이터셋 는 pair 형태의 샘플 로 구성됨
- : 작업 에서 추출된 입력 샘플
- : 동일 작업 에서 무작위로 선택된 양의 샘플
각 양의 샘플 쌍을 보완하기 위해, 다음과 같이 개의 음의 샘플 을 무작위로 선택
이 때 는 반드시 외부의 작업에서 선택되어야 하며, 다음 조건을 만족해야함
이러한 학습 과정은 contrastive loss를 통해 수행됨.
학습은 positive는 유사도 높게, negative는 유사도 낮게 만드는 방향으로 진행
- : 임베딩 간 코사인 유사도
- : softmax 온도 파라미터
4️⃣ 검색 단계
모든 LoRA 후보 중 입력 와 유사도가 높은 개의 LoRA 를 선택하게 됨
LoRA Composition
입력 에 대해 상위 k개의 LoRA 를 검색한 후, 이들 LoRA를 LLM의 파라미터 와 함께 통합하게 됨. 다음 두 가지 LoRA 조합 전략을 통해 수행됨
Mixture of LoRAs
선택된 여러 LoRA들의 각 서브모듈에서 나오는 출력을 집계하는 방식
, 각 각 n개의 LoRA에서의 서브모듈을 나타내는 집합
Fusion of LoRAs
각 LoRA의 파라미터 자체를 결합하여 하나의 통합된 LoRA를 생성하는 대안적 조합 전략
각 LoRA 의 파라미터를 라고 할 때, 융한된 LoRA의 파라미터 은 다음과 같이 정의됨여러 LoRA 파라미터(BA)의 평균값을 사용하여 하나의 LoRA처럼 작동하도록 함
Batch Inference of Multiple LoRAs
한 번에 여러 입력 문장을 처리할 때, 각 문장마다 다른 LoRA들을 선택할 수 있고, 이들을 효율적으로 동시에 계산하기 위한 구조를 만듣 과정임.
입력 배치
- : 배치 크기 (문장 개수)
- : 시퀀스 길이 (문장 길이)
- : 샘플 차원 (임베딩 차원)
1️⃣ 각 입력마다 선택된 LoRA들 정리
각 입력 와 그에 대해 검색된 LoRA 집합 에 대해, 배치 내의 모든 LoRA를 중복을 제거한 통합된 고유한 집합 로 모음. 결과적으로 는 개의 고유한 LoRA를 포함하며, 이다.
2️⃣ 매핑 벡터 만들기
각 샘플 에 대해, 해당 샘플이 사용하는 LoRA가 에서 어떤 인덱스에 위치하는지를 나타내는 - 차원의 매핑 벡터 를 생성함(즉, 어떤 LoRA를 사용했는지 알려주는 길라잡이)
이러한 LoRA 매핑 벡터들을 모으면 전체 배치의 LoRA 매핑 행렬 가 됨.
3️⃣ LoRA 서브모듈 파라미터 정리
LoRA 서브모듈의 파라미터는 A와 B로 표시되며, 배치된 LoRA 집합 내에서 이들을 연결하여 다음과 같은 형태를 얻음
✅ 두 가지 방식의 추론!
Mixture of LoRAs 방식의 배치 추론 과정은 다음과 같이 수식화할 수 있음
Fusion of LoRAs 방식의 배치 추론 과정은 다음과 같음
Experiments
Evaluation Framework
Base Moel & LoRA Configuration
• Model : Llama-2-{7b, 13b}
• Flan-v2 데이터셋의 일부를 선택하여, NLU, NLG을 포함하는 다양한 task에 대해 총 48개 LoRA 학습
• 이 작업들은 총 10개의 고유한 태스크 클러스터로 그룹화할 수 있음
• 각 LoRA는 Alpaca 포맷을 따르며, 로 설정하여 학습함.
Mixed Task Evaluation Dataset
48개의 LoRA를 학습하는 데 사용된 각 작업의 테스트 세트에서 무작위로 50개 샘플을 선택하였음. 그 후, 이 샘플들을 혼합하고 셔플하여 총 6,000개의 샘플로 구성된 통합 데이터셋을 생성하였음
Baseline Methods
- MOE : 입력에 따라 여러 모듈을 선택해서 사용하는 구조
- SMEAR : 동적으로 여러 어댑터를 조합하는 방식
- AdappterSoup : 여러 Adapter 모듈을 학습해두고, 추론 시 가중 평균하여 사용하는 방식
- LoRAhub : 사전 훈련된 여러 LoRA 모듈을 모아둔 허브 형태의 접근
평가 지표
- Struct to Text
ROUGE-1, ROUGE-2, ROUGE-L- Translation
BLEU 점수를 사용하여 평가- NLU
각 방법의 Exact Match Accuracy를 기준으로 성능을 평가
Main Result
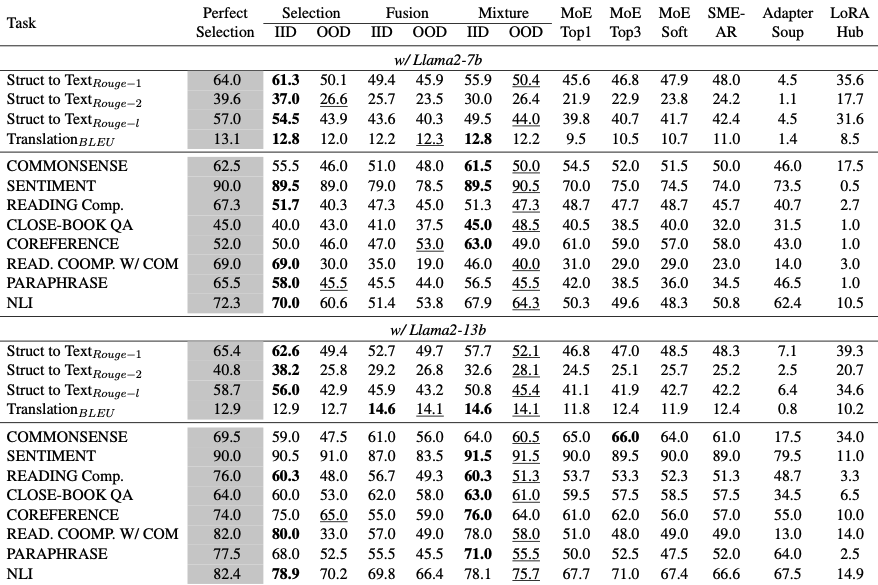
Mixed task evaluation 결과는 위 이미지와 같음.
각 작업 클러스터에 대한 평균 성능을 제시하고, 또한 LoraRetriever의 OOD 환경에서의 효과성도 평가하였음.
OOD 설정에서는, 각 샘플에 대해 해당 LoRA를 마스킹하여 LoraRetriever가 이상적인 LoRA를 검색하지 못하도록 제한함
1) LoraRetriever는, input-aware retrieval & composition을 수행하며, 특정 다운스트림 작업에 초점을 맞춘 기존 기준 모델들보다 확연히 우수한 성능을 보였음
2) IID 환경 : Mixture Selection > Fusion
- IID 환경에서는 LoraRetriever가 높은 정확도의 top-1 선택을 수행할 수 있기 때문에, Selection과 Mixture 결과가 유사함
- 서로 다른 작업은 본질적으로 이질적이기 때문에, 단순히 top-k LoRA의 파라미터를 평균하는 Fusion 방식은 부적합함
3) OOD 환경 : Mixture > Selection Fusion
실제 정답 LoRA는 마스킹하여 사용 불가
- OOD 상황에서는 Selection이 관련된 LoRA를 검색할 수 없게 되어 성능이 크게 하락함
- Mixture는 유사한 작업의 LoRA 성능을 활용하여 OOD 작업을 처리할 수 있어, 성능 저하를 완화시킴
4) MoE 및 SMEAR 기법은 LoraRetriever보다 성능이 낮았음
task에 따라 LoRA를 선택하거나 구성하지만, 구조적으로 선택이 고정되어 있거나, 새로운 LoRA가 추가될 때 적응하지 못하므로 LoRA가 자주 바뀌는 실사용 환경에서는 효과가 떨어짐
5) AdapterSoup는 혼합 작업 환경에서도 다운스트림 작업에 적절한 LoRA를 일관되게 검색하지만, 검색된 LoRA가 각 요청에 맞춘 개인화를 제공하지 못해, 각 작업에 대한 최적 성능을 보장하지 못함
6) LoRAhub는 혼합 작업 시나리오에서 완전히 비효율적인 것으로 나타났음
- 첫째, LoRAhub의 조합 방식은 무작위로 선택된 LoRA에 의존하므로 관련성이 낮을 수 밖에 없음
- 이질적인 작업이 혼합되어 있을 경우, 파라미터 최적화 방향이 충돌하게 되어, 결국 파라미터 융합이 완전히 실패하는 결과로 이어짐
Analysis
Performance of Retriever
Huggingface에서 널리 사용되는 기성 문장 임베딩 모델들과 비교하였음.
LoraRetreiver를 학습할 때 사용된 작업의 비율이 성능에 어떤 영향을 주는지 분석하기 위해, 서로 다른 비율(%)의 작업으로 학습된 LoraRetriever 세 가지 버전을 실험하였음
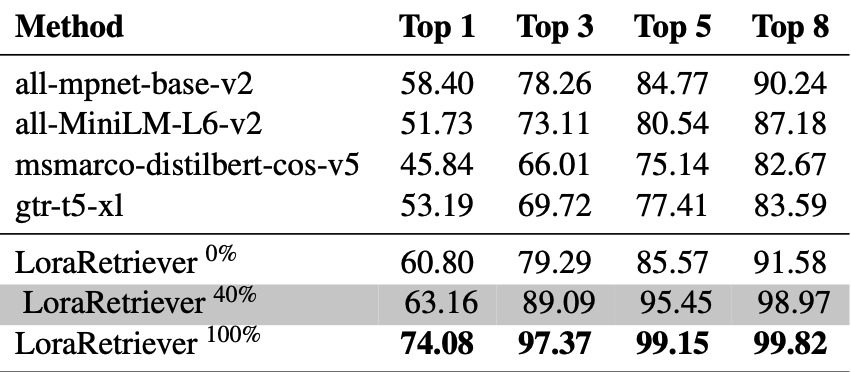
모델 이름 설명 all-mpnet-base-v2 대중적인 sentence embedding 모델 all-MiniLM-L6-v2 경량 sentence embedding 모델 msmarco-distilbert-cos-v5 ranking task에 특화된 모델 gtr-t5-xl T5 기반의 대형 모델 위 모델은 LoRA 검색용으로 별도 학습되지 않음
LoraRetriever k%는 전체 task 중 k%만 사용해서 instruction fine-tuning한 retriever를 나타냄
실험 결과, 특정 프롬프트로 문장 임베딩 모델을 안내하면, 일반적인 검색 모델보다 검색 성능이 향상됨을 확인할 수 있었으며 Instruction fine-tuning 이후, 검색기의 성능은 입력에 따라 적절한 LoRA를 검색하는 능력이 크게 향상되었음

LoRA pool의 동적 업데이트가 실제 서비스 중 발생하는 시나리오를 가정하고, 40%만 학습된 LoraRetriever를 사용하여 일반화 능력을 시뮬레이션 하였음
100%와 40%의 차이가 크기 않으므로, 뛰어난 일반화 능력 확인 가능
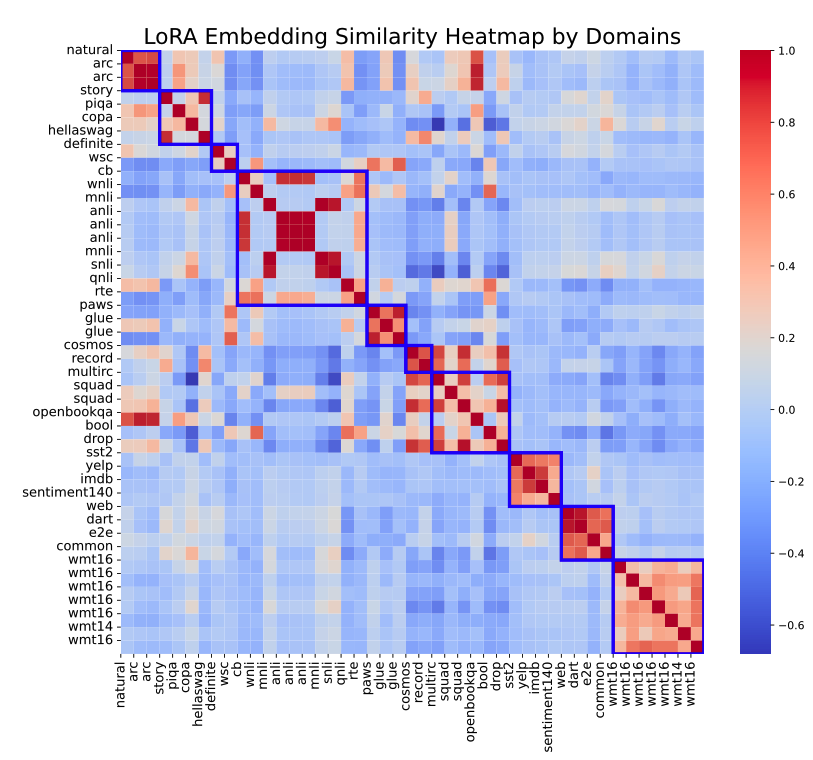
작업 간 임베딩 유사도를 히트맵 형태로 시각화한 것
동일한 작업 클러스터에 속한 작업들은 대호로 묶여 그룹화되어 있으며, 같은 도메인 내 작업들 간의 임베딩 유사도가 더 높게 나타나는 경향이 있음
이 결과 LoraRetriever의 임베딩이 작업 간 유사도를 반영하는 task embedding으로도 활용 가능하며, LoRA 검색에 효과적으로 사용될 수 있음을 시사
Impact of the number of Retrieved LoRA
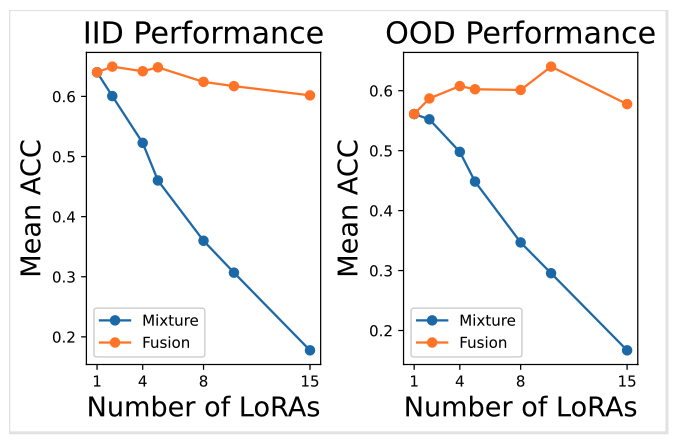
검색된 LoRA 수가 NLU 작업의 평균 정확도에 미치는 영향을 보여줌
Effectiveness of Batch Inference Strategy
다양한 배치 크기에서의 처리량을 비교하였음
- 처리량 : 혼합 작업 벤치마트에서 모든 요청에 대해 초당 처리되는 입력 및 출력 토큰 수로 정의됨
단일 LoRA와 비교했을 때의 연산 효율성에 초점을 맞추어 평가를 수행했음
전체 평가 데이터셋에 대해 실험을 진행하였고, 생성 길이 차이로 인한 성능 편차를 줄이기 위해 생성 결과 중 첫 번째 토큰까지만 생성하도록 제한함
실험은 NVIDIA A100 GPU, bfloat 16 정밀도를 사용하여 수행
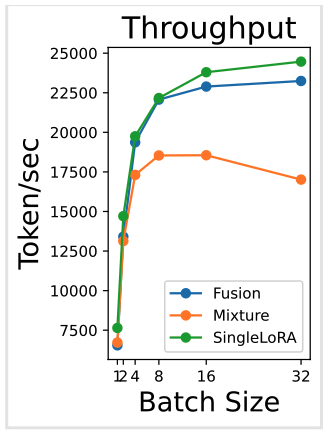
제안한 배치 추론 전략은 프레임워크의 처리량을 크게 향상시켰으며, 단일 LoRA 대비 소폭의 처리량 감소만 발생
Showcase
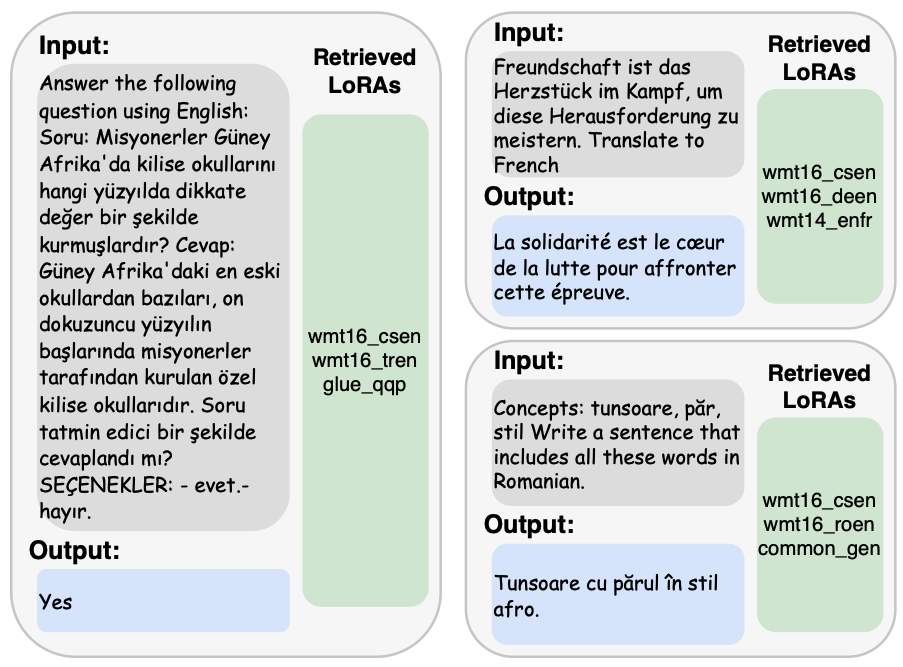
세 가지 예제 문제를 직접 구성하였고, 이 문제들은 단일 LoRA만으로는 직접 해결할 수 없어, 여러 기존 LoRA의 협력이 필수적인 상황을 나타냄
첫 번째 예시 : LoRA가 NLI와 번역 능력을 함께 요구하는 경우
- LoraRetriever는 터키어 이해를 위해 wmt16-tren LoRA, NLI 작업을 위해 glue-qqp LoRA를 각각 검색하여 통합 활용
두 번째 예시 : 독일어에서 프랑스어로 번역
- 데이터셋에는 독일어 ⇒ 프랑스어에 특화된 LoRA는 존재하지 않지만, wmt16-deen(독일어 ⇒ 영어), wmt14-enfr(영어 ⇒ 프랑스어) LoRA를 조합함으로써 간접적으로 독일어 ⇒ 프랑스어 번역을 수행할 수 있음
세 번째 예시 : 루마니어 번역과 텍스트 생성 기능의 결합
- 루마니아어 이해를 위해 wmt16-roen LoRA 사용
- 텍스트 생성을 위해 common-gen LoRA를 사용
Limitation
-
사용자 데이터 프라이버시 문제
사용자가 LoRA를 업로드할 때, 해당 LoRA 모델의 분포를 표현하기 위해 소량의 학습 데이터를 사용해야 함. 그러나 프라이버시에 민감한 상황에서는 이러한 데이터 기반 표현 방식이 현실적으로 어려울 수 있음. 향후 데이터 프라이버시를 보장하면서도, LoRA 파라미터와 샘플 분포를 임베딩 공간에서 정렬하는 방법에 대한 연구 필요 -
모델 아키텍처 통일성 문제
LoraRetriever 프레임워크는 동일한 모델 아키텍처 내 여러 LoRA를 협업시키는 경우에만 적용 가능. 하지만 실제 환경에서는 사용자마다 선택한 모델 아키텍처나 PEFT 방법이 서로 다를 수 있으며, 이러한 경우에도 적용 가능한 협업 메커니즘을 어떻게 설계할 것인지에 대한 연구가 필요
