A Comprehensive Overview of Large Language Models

BACKGROUND
Tokenization
LLM 학습에서 필수적인 전처리 단계로, 텍스트를 쪼갤 수 없는 단위(token)으로 분해하는 과정. 이 token은 tokenization method에 따라 문자, 서브워드, 기호, 단어 등이 될 수 있음. LLM에서 주로 사용되는 토크나이제이션 방식은 다음과 같음 - WordPiece, BPE, Unigram Language Model
Encoding Positions
Transformer는 입력 시퀀스를 병렬로 처리하여, 토큰의 순서 정보를 자동으로 고려하지 않음. 따라서, Transforemr에서 Positional Encoding이 도입되었으며, 이는 토큰 임베딩에 위치 임베딩 벡터를 더하는 방식으로 구현됨. 위치 인코딩의 주요 방식은 다음과 같음
- 절대 위치 인코딩
- 상대 위치 인코딩
- 학습된 위치 인코딩
LLM에서 주로 사용되는 상대 위치 인코딩 기법은 다음과 같다
- Alibi : 토큰 간 거리가 멀어질수록 어텐션 스코어에서 감산되는 bias를 주어, 가까운 토큰에 더 주목하게 만듦
- RoPE : 쿼리와 키를 입력 시퀀스 내 절대 위치에 비례한 각도로 회전시켜, 토큰 간 거리 정보가 반영되는 상대 위치 인코딩 방식. ( 거리에 따라 감쇠되는 특징이 있음 )
Attention in LLMs
Attention은 입력 토큰의 중요도에 따라 가중치를 부여하여, 모델이 중요한 토큰에 더 집중할 수 있게 해줌. Transformer Attention은 입력 시퀀스에서 query, key, value를 계산한 후, query x key로 어텐션 스코어를 구하고, 이 스코어를 value에 곱하여 최종 출력을 생성함. 다음은 LLM에서 사용되는 다양한 Attention Method
| 라이브러리 | 설명 |
|---|---|
| Self-Attention | 같은 블록 내에서 query, key, value를 모두 가져와 어텐션을 계산함 |
| Cross-Attention | 인코더-디코더 구조에서 사용되며, 인코더 출력이 key-value 쌍, 디코더가 query를 제공하는 구조임 |
| Sparse Attention | 기본 self-attention은 의 시간복잡도를 가지므로, 긴 시퀀스에 비효율적임. Sparse attention은 슬라이딩 윈도우 방식으로 어텐션을 부분적으로 계산하여 속도를 개선함 |
| Flash Attention | GPU에서 메모리 접근 비용이 어텐션 계산의 병목이 되기 때문에, Flash Attenttion은 메모리 접근을 최적화하여 어텐션 계산을 가속화함. |
Activation Functions
활성화 함수는 신경망의 curve-fitting-ability를 결정짓는 데 중요한 역할을 함.
- ReLU : 가장 단순하면서도 널리 사용되는 활성화 함수
- GeLU : ReLU, dropout, zoneout의 장점을 결합한 활성화 함수. 자연스러운 확률 기반 활성화를 제공하여 성능이 향상되는 경우가 많음
- GLU 및 변형
Layer Normalization
모델 수렴 속도를 높임
| 방법 | 설명 |
|---|---|
| LayerNorm | 가장 기본적인 형태, 전체 레이어의 출력을 정규화 |
| RMSNorm | 평균을 제거하지 않고 제곱평균만을 기반으로 정규화 |
| Pre-LayerNorm | Multi-Head Attention 앞에 정규화를 적용함 |
| DeepNorm | Pre-Norm 사용 시 발생하는 기울기 폭주 문제를 완화 |
Distributed LLM Training
LLM은 매우 크기 때문에 분산 학습이 필수적
| 방법 | 설명 |
|---|---|
| Data Parallelism | 같은 모델을 여러 장치에 복제하고, 학습 데이터를 나누어 처리 , 각 반복 후, 가중치 동기화 |
| Tensor Parallelism | 하나의 텐서 계산을 여러 장치로 분산 |
| Pipeline Parallelism | 모델의 레이어를 여러 장치에 순차적으로 배치, 수직 정렬 처리 |
| Model Parallelism | 텐서 병렬 + 파이프라인 병렬의 조합, 하나의 모델을 여러 장치에 나누어 병렬 처리 |
| 3D Parallelism | 데이터 병렬 + 텐서 병렬 + 모델 병렬의 3가지 조합을 동시에 사용 |
| Optimizer Parallelism | 옵티마이저 상태, 그라디언트, 파라미터를 장치 간에 분산시켜 메모리 사용량을 줄이고, 통신 비용 최소화 |
Libraries
| 라이브러리 | 설명 |
|---|---|
| Transforemers | Hugging Face에서 제공하며, 다양한 사전학습된 Transformer model을 활용하고, 파인튜닝, 추론 커스텀 모델 개발 등을 위한 API를 제공함 |
| DeepSpeed | 대규모 분산 학습과 추론을 위한 라이브러리 |
| Megatron_LM | GPU에 최적화된 LLM의 대규모 학습 기법 제공 |
| JAX | 고성능 수치 계산 및 확장 가능한 머신러닝을 위한 파이썬 기반 프레임워크 |
| Colossal_AI | 분산 딥러닝 모델을 쉽게 작성할 수 있도록 도와주는 구성요소 모음 |
| BMTrain | 효율적인 독립형 LLM 학습 코드를 작성할 수 있도록 도와주는 경량 라이브러리 |
| FastMoE | PyTorch에서 MoE 모델을 구축할 수 있도록 API를 제공함 |
| MindSpore | 모바일, 엣지, 클라우드 환경까지 확장 가능한 머신러닝 프레임워크 |
| PyTorch | Facebook AI Research에서 개발한 프레임워크로, 동적 계산 그래프, 파이썬 친화적 코드 스타일이 특징 |
| TensorFlow | Google이 개발한 프레임워크로, 정적 그래프 기반 연산, 즉시 실행, 확장성 등이 장점 |
| MXNet | Apache에서 개발한 딥러닝 프레임워크로, Python, C++, Scala, R 등 다양한 언어 지원, 정적/동적 그래프 모두 지원 |
Data Preprocessing
| 방법 | 설명 |
|---|---|
| Quality Filtering | 학습 데이터의 품질은 모델 성능에 매우 중요함. 주요 필터링 방법은 두 가지임. -분류기 기반 : 고품질 데이터를 기반으로 분류기를 학습시켜 텍스트의 품질을 예측하여 필터링 -휴리스틱 기반 : 언어, 통계, 키워드, 메트릭 등을 이용한 규칙 기반 필터링 |
| Data Deduplication | 중복된 데이터는 모델의 성능 저하 및 암기 현상을 초래할 수 있으므로, 문장 단위, 문서 단위, 데이터셋 단위에서 중복을제거하는 것이 중요함 |
| Privacy Reduction | 웹에서 수집된 데이터에는 개인정보가 포함될 수 있어, 개인정보를 제거하는 휴리스틱 방식을 통해 모델이 이를 학습하지 않도록 필터링 함. |
Architectures
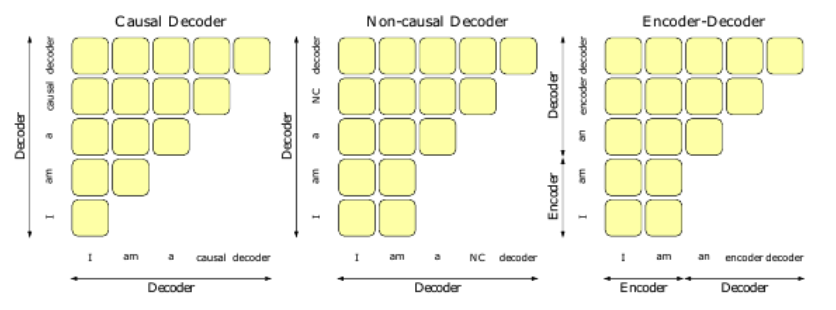
| 방법 | 설명 |
|---|---|
| Encoder-Decoder | 인코더 : 전체 입력 시퀀스를 self-attention으로 처리 디코더 : 인코더의 출력을 받아, cross-attention과 순차 처리 방식으로 출력 생성 ➡️ 대표 모델 : T5, BART |
| Causal Decoder | 인코더 없이 디코더만으로 구성됨 토큰을 생성할 때 이전 타임스텝의 정보만 참고 대표 모델 : GPT 계열 |
| Prefix Decoder | 과거 정보뿐 아니라 양방향 어텐션이 가능한 디코더 어텐션이 과거에만 의존하지 않으며, 비인과적 마스크를 사용 ➡️ 일부 멀티태스크 학습 또는 퓨전 모델에서 사용 |
| Mixture-of-Experts | 트랜스포머의 한 변형으로, 독립적인 전문가 레이어들을 병렬로 구성 라우터가 입력 토큰을 적절한 전문가에 동적으로 할당 일반적인 dense 모델에 비해, 성능은 유지하면서 계산 비용은 절감 가능 학습 시 일부 전문가만 활성화됨 ➡️ GLaM, Switch Transformer |
Pre-Training Objectives

| 방법 | 설명 |
|---|---|
| Full Language Modeling | autoregressive 방식 모델은 이전 토큰들을 기반으로 다음 토큰을 예측함 에 : GPT 모델 계열 |
| Prefix Language Modeling | non-casual 훈련 방식 입력 문장에서 무작위로 접두사를 선택하고, 나머지 토큰들만 예측하도록 손실 계산 |
| Masked Language Modeling | 문장 내의 일부 토큰 또는 구간을 무작위로 마스킹하고, 양쪽 문맥을 기반으로 마스킹된 토큰을 예측하게 함 예 : BERT 계열 |
| Unified language Modeling | 인과적, 비인과적, 마스킹 방식을 통합한 방식 단, 여기서 MLM은 양방향이 아닌 단방향으로 작동함. |
Scaling Laws
스케일링 법칙은 모델 성능 향상과 관련된 이론적인 확장 방식을 다룸
모델 성능은 모델 크기, 데이터셋 크기, 계산 자원 간의 파워-법칙 관계에 따라 증가함이 관찰됨. 이러한 관찰은 큰 모델이 많은 데이터보다 더 중요할 수 있음을 보여줌. 다른 연구는 모델 크기와 학습 토큰 수는 비례해서 확장되어야 최적의 성능을 낼 수 있음
LLMs Adaptation Stages
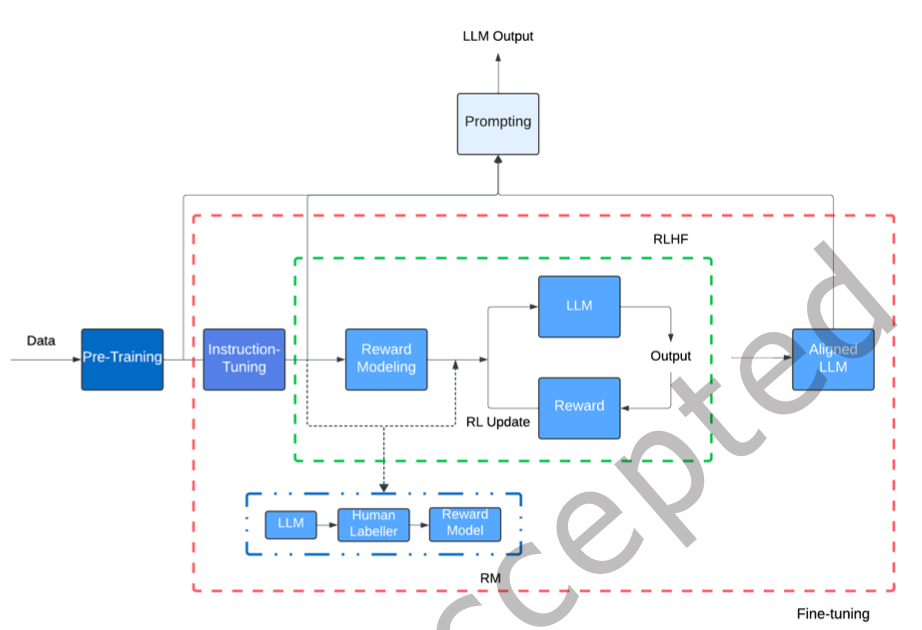
Pre-Training
가장 첫 번째 단계로, 모델은 self-supervised manner로 large corpus에 대해 학습되며, 입력이 주어졌을 때 다음 토큰을 예측하는 방식으로 훈련됨
LLM의 설계 선택은 인코더-디코더 구조부터 디코더 전용 구조까지 다양하며, 구성 요소와 손실 함수는 위에서 설명하였음
Fine-Tuning
| 방법 | 설명 |
|---|---|
| Transfer Learning | 특정 downstream task에 대한 성능을 향상시키기 위해, task-specific data로 사전학습 모델을 파인튜닝 |
| Instruction-tuning | 모델이 사용자 질의에 효과적으로 응답할 수 있도록, 사전학습된 모델은 명령어 형식의 데이터로 파인튜닝됨. 즉, instruction & input-output pair 으로 구성된 데이터를 사용하는 것 명령어는 일반적으로 자연어로 표현된 멀티태스크 데이터로 구성되며, 모델이 프롬프트와 입력에 따라 응답하도록 유도함. 이러한 형태의 파인튜닝은 zero-shot generalization 및 다운스트림 작업 성능 향상에 효과적 |
때로는 input이 없는 경우도 있음
{
"instruction" : "고양이에 대한 시를 써주세요",
"input" : "",
"output" : "창가에 앉은 고양이 \n 햇살을 베고 조용히 눈을 감는다\n..."
}다양한 task를 한 모델에 모두 학습시키는 방식, 새로운 작업 수행할 때 fine-tuning 없이도 instruction만 잘 주면 해결 가능함.
Alignment-tuning
LLM은 거짓되거나, 편향적이거나, 해로운 텍스트를 생성하기 쉬운 경향이 있음. 이들을 유용하고, 정직하며, 무해하게 만들기 위해, 인간 피드백을 사용해 모델을 정렬함.
정렬 과정에서는 LLM이 예상치 못한 응답을 생성하도록 유도한 후, 그러한 응답을 피하도록 모델의 파라미터를 업데이트함. 이는 LLM이 인간의 의도와 가치에 따라 작동하도록 보장함. 모델이 helpful, honest, harmless 세 기준을 만족할 때, 그 모델은 aligned 모델이라 정의함.
연구자들은 피드백을 활용한 강화학습(RLHF)을 통해 모델 alignment를 수행함. RLHF에서 데모로 파인튜닝된 모델이, 이후 보상 모델링(RM)과 강화학습(RL) 과정을 통해 추가 학습됨
| 내용 | 설명 |
|---|---|
| Reward modeling | 분류 목적 함수를 사용하여, 생성된 응답을 인간의 선호도에 따라 순위를 매기도록 모델 학습 [예시] 게임을 예시로 생각해보자agent가 게임을 플레이하고 벽에 부딪히면 -1, 보물을 찾으면 +10이 보상을 기준으로 policy를 학습함 |
| Reinforcement learning | 보상 모델과 함께 다음 단계에서 정렬을 수행함. 사전에 학습된 보상 모델은 LLM이 생성한 응답을 선호/비선호로 분류하고, 이 정보를 사용해 PPO 방식으로 모델을 정렬 이 과정은 수렴할 때까지 반복됨. [예시] 모델이 두 개의 응답 A와 B를 생성사람이 보고 "B가 더 좋아"라고 평가Reward Model은 B > A를 학습하여, 좋은 응답을 높은 점수로 평가 가능 |
Prompotin / Utilization
Prompting은 훈련된 LLM에게 질문을 던져 응답을 생성하게 하는 방법. LLM은 다양한 프롬프트 방식으로 파인튜닝 없이도 instruction에 적응할 수 있으며, 또는 다양한 프롬프트 스타일을 포함한 데이터로 파인튜닝하여 적응할 수 있음.
| 방법 | 설명 |
|---|---|
| Zero-shot Prompting | LLM은 zero-shot 학습자로, 이전에 본 적 없는 질문에도 답변할 수 있음. 이 방식은 프롬프트 예시 없이 사용자 질문에 답하게 함 [예시] Instruction : 영어 문장을 한국어로 번역해줘. Input : I am hungryOutput : 나 배고파. |
| In-context Learninig | few-shot 학습이라고도 하며, 모델에게 여러 개의 입력-출력 예시 쌍을 보여준 뒤, 원하는 응답을 생성하게 함. [예시] Instruction : 영어 문장을 한국어로 번역해줘Input : I am happy, Output : 나는 행복해Input : I love dogs. Output : 나는 개를 좋아해Input : I am tired, Output : ?? |
| Reasoning in LLMs | LLM읜 zero-shot 추론자로, 논리 문제, 계획, 비판적 사고 등의 과제를 수행하도록 유도할 수 있음. 추론 능력은 다양한 프롬프트 스타일을 통해 자극할 수 있으며 추론 작업 성능 향상을 위해 LLM을 추론 데이터셋으로 훈련하는 방법도 있음 - Chain-of-Thought : 추론 정보를 입력 및 출력과 함께 제공하여, 모델이 단계별로 추론한 결과를 생성하도록 유도하는 특별한 프롬프트 방식 - Self-Consistency : CoT의 성능을 개선하기 위해 여러 개의 응답을 생성하고, 가장 자주 등장하는 응답을 선택하는 방식 - Tree-of-Thought : 문제 해결을 위해 여러 개의 추론 경로를 탐색하고, 미리보기 및 되돌리기를 허용하는 방식 |
| Single-Turn Instructions | 모든 관련 정보를 한 번의 프롬프트에 포함하여 질문하는 방식. 모델은 zero-shot or few-shot 상황에서 문맥을 이해하고 응답을 생성함 [예시] Instruction : "이 문장을 영어로 번역해줘: 나는 너를 좋아해.""I like you." |
| Multi-Turn Instructions | 복잡한 작업을 해결하려면 LLM과 여러 번 상호작용 해야 함. 이때 피드백과 다른 도구의 응답을 다음 입력에 포함시키는 방식. 이러한 방식은 자율 에이전트에서 일반적으로 사용됨. [예시] [User] 영화 추천해줘[Model] 어떤 장르를 원하시나요?[User] 스릴러로 부탁해"Gone Girl"를 추천합니다. |
LARGE LANGUAGE MODELS
Pre-Trained LLMs
General Purpose
| 모델 | 방법 |
|---|---|
| T5 | 모든 NLP 문제에 대해 통합된 텍스트-투-텍스트 학습 방식을 사용하는 인코더-디코더 모델 기존 Transformer model에서 레이어 정규화를 잔차 경로 밖에 배치함. 사전학습 목표는 Masked LLM을 사용 이때 연속된 토큰을 하나의 마스크로 대체하여 각 토큰마다 별도로 마스크하지 않음. 이러한 마스킹 방식은 시퀀스를 짧게 만들어 학습을 가속화함. 사전학습 후, 어댑터 레이어를 사용하여 다운스트림 작업에 대해 파인튜닝 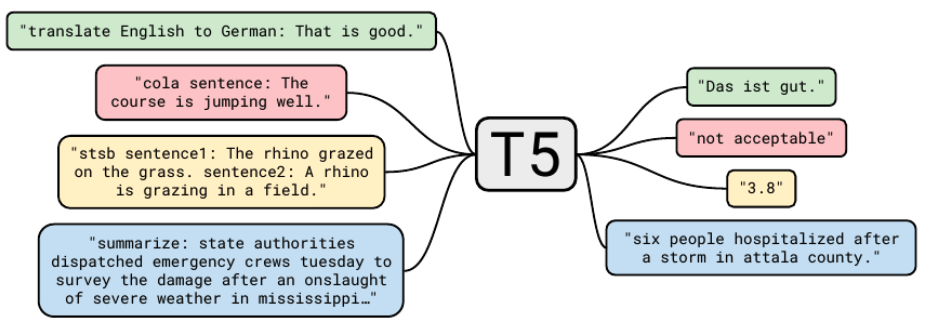 |
| GPT-3 | Transformer layer 내에 dense 및 sparse 어텐션을 적용하여 Sparse Transformer와 유사함. GPT-3는 대규모 모델이 더 큰 배치 크기로 더 낮은 학습률로 학습할 수 있음을 보여주었으며, 학습 중 배치 크기 결정을 위해 gradient noise scale을 사용하였음. 총 1750억 개의 파라미터를 갖는 GPT-3 모델 크기 가 커질수록 성능이 향상됨을 보여주었으며, 파인튜닝된 모델과 경쟁력 있는 성능을 보임 |
| GPT-4o | 음성, 텍스트, 이미지, 비디오를 처리하고, 이미지, 음성, 텍스트를 생성할 수 있는 오토리그레시브 멀티모달 LLM |
| OpneAI-o3 | 내부 체인오브쏘트 프롬프트를 통해 추론 능력을 갖춘 모델. 내부 추론을 포함한 학습은 GPT-4 대비 더 안전하고 유용한 응답을 생성하게 함 |
| mT5 | 101개 언어를 포함한 mC4 데이터셋으로 학습된 다국어 T5 모델. 공개 Common Crawl로부터 수집한 데이터를 사용하며, 25만 개의 대형 어휘집을 사용하여 다국어를 처리함. 언어별 과적합/과소적합 을 피하기 위해 데이터 샘플링 방식을 사용함. 영어 작업에 대해 파인튜닝할 때, 모든 언어가 포함된 소량의 사전학습 데이터를 함께 사용하면 비영어 출력의 정확도가 향상됨 |
| PanGU- | 표준 Transformer layer의 끝에 query를 추가하여 다음 토큰을 예측하는 오토리그레시브 모델 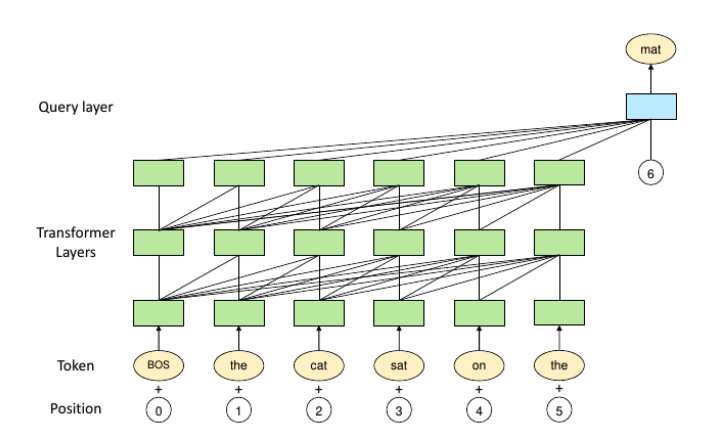 |
| CPM-2 | 중국어-영어 이중언어 모델, 11B와 198B 규모의 MoE 모델을 WuDaoCorpus 데이터셋으로 사전학습함. 지식 상속 방식을 사용하여, 1단게에서는 중국어만, 이후에는 영어와 중국어 데이터를 추가하여 학습 |
| ERNIE 3.0 | multi-task learning에서 영감을 받아 Transformer-XL를 백본으로 사용한 모듈형 아키텍처를 구성 범용 표현 모듈은 모든 작업에 공유되며, 각 작업별 표현 모듈은 따로 훈련됨. 중국어에 초점을 맞추고 있음 |
| Jurassic-1 | 오토리그레시브 모델 쌍으로 구성되며, 토크나이저는 단어 조각, 완전한 단어, 다단어 표현을 포함하며, 단어 경계가 없는 경우에는 유니코드 바이트로 해석됨. zero-shot 작업에서는 GPT-3와 비슷한 성능, few-shot 작업에서는 우수한 성능을 보임 |
| HyperCLOVA | 한국어 GPT-3 아키텍처 기반 모델 |
| Yuan 1.0 | 중국어 대규모 코퍼스(5TB)로 학습됨. Spark 기반 필터링 시스템 사용 |
| Gopher | 44M~280B까지 다양한 크기. 81% 평가 작업에서 GPT-3보다 성능 우수 |
| ERNIE 3.0 TITAN | ERNIE 3.0보다 26배 파라미터 증가. Fact QA 작업에서 최고 성능 |
| GPT-NeoX-20B | GPT-3와 유사한 구조. 병렬 어텐션 구조와 Rotary Embedding 사용 |
| OPT | GPT-3를 복제한 오픈소스 모델. 동적 손실 스케일링 사용 |
| BLOOM | ROOTS 코퍼스 기반 causal decoder 모델. ALiBi 임베딩 및 추가 정규화 |
| GLaM | MoE 기반 sparse 모델. 입력당 2개 expert만 활성화. 에너지 소비 1/3 |
| MT-NLG | 530B 모델로 GPT-3보다 3배 크기. 다양한 데이터셋 혼합 학습 |
| Chinchilla | Gopher보다 작은 모델로 더 많은 데이터로 학습. 더 나은 성능 |
| AlexaTM | 인코더-디코더 모델. 초기에는 frozen encoder로 시작 후 end-to-end 학습 |
| PaLM | 540B causal decoder. SwiGLU, RoPE, multi-query attention 사용 |
| PaLM-2 | 작은 다국어 PaLM. 독성/암기 감소. 효율적 추론 및 학습 |
| U-PaLM | UL2R 목표 사용하여 PaLM을 0.1% 추가 연산으로 학습 |
| UL2 | 인코더-디코더. 다양한 Denoiser 목적 혼합(MoD) |
| GLM-130B | 중국어/영어 이중 언어 모델. 양방향 마스킹 사전학습 사용 |
| LLaMA-1 | 7B~70B 규모. Efficient causal attention 및 역전파 최적화 |
| LLaMA-2 | 더 많은 데이터, 긴 컨텍스트 길이, grouped-query attention 도입 |
| LLaMA-3/3.1/3.2 | LLaMA-2보다 7배 큰 데이터로 학습, 성능 향상 |
| PanGu-Σ | PanGu-𝛼 기반 trillion-scale RRE 모델. continual learning에 유리 |
| Mixtral 8x22B | 8개 expert 중 2개만 각 레이어에서 활성화되는 MoE 모델 |
| Snowflake Arctic | Dense+MoE 하이브리드. 총 480B 파라미터 중 17B만 활성화 |
| Grok-1 | XAI의 314B MoE 모델. 2개의 expert가 토큰마다 활성화됨 |
| Grok-1.5 | 멀티모달 버전. 긴 컨텍스트 길이 및 성능 향상 |
| Gemini-1 | MMLU 벤치마크에서 인간 수준 성능 최초 달성 |
| Gemini-1.5 | 2M 컨텍스트 윈도우, 최대 10M 토큰 정보 추론 가능 |
| Nemotron-4 340B | 98% 합성 데이터, 2% 수동 주석 데이터로 정렬된 디코더 모델 |
| DeepSeek | 스케일링 법칙 분석 및 최적 배치 크기/학습률 공식 제공 |
| DeepSeek-v2 | MLA 어텐션으로 KV 캐시 압축. 추론 5.76배 빨라짐 |
| DeepSeek-v3 | MLA 구조 유지, 다중 토큰 예측 목표 사용 |
Coding
| 모델 이름 | 설명 |
|---|---|
| CodeGen | PaLM과 유사한 구조 (병렬 어텐션, MLP, RoPE 사용). 자연어와 프로그래밍 언어 데이터를 순차적으로 학습(PILE, BIGQUERY, BIGPYTHON). Multi-Turn Programming Benchmark (MTPB)로 다단계 코드 생성 평가. |
| Codex | 공개된 Python GitHub 저장소 일부로 학습. 주석에서 코드 생성. 반복 샘플링으로 프로그램 100개 생성해 평균 77.5% 문제 해결. GitHub Copilot의 기반 모델. |
| AlphaCode | 300M~41B 파라미터 규모. 경쟁 프로그래밍 문제 해결용. multi-query attention 사용. Codeforces에서 수집한 CodeContests 데이터로 파인튜닝. 5000명 중 상위 54.3% 성적, 최근 참가자 중 상위 28% 수준. |
| CodeT5+ | CodeT5 기반. shallow encoder + deep decoder 구조. unimodal(code)과 bimodal(text-code) 데이터를 단계별로 학습. contrastive loss, matching 등 다양한 목표를 포함. 특수 토큰([CLS], [Match] 등)으로 작업 지정. |
| StarCoder | SantaCoder 아키텍처 기반 decoder-only 모델. Flash Attention으로 8K 컨텍스트 길이 지원. 개인정보 필터링용 인코더 포함. HumanEval 및 MBPP에서 PaLM, LLaMA, LAMDA보다 우수한 성능. |
Scientific Knowledge
| 모델 이름 | 설명 |
|---|---|
| Galactica | 4,800만 개의 논문, 교과서, 강의노트, 화합물, 단백질, 백과사전 등 인류 과학 지식을 메타세크(metaseq) 라이브러리로 학습. <work> 토큰을 사용해 단계별 추론 문맥을 부여하여 reasoning 성능 향상. |
Dialog
| 모델 이름 | 설명 |
|---|---|
| LaMDA | 디코더 전용 모델. 90% 이상 영어 기반의 공개 대화 데이터 및 웹 문서로 사전학습됨. 응답의 품질, 안전성, 근거성을 높이기 위해 판별적/생성적 파인튜닝 기법 적용. 범용 언어 모델로 다양한 작업 수행 가능. |
Finance
| 모델 이름 | 설명 |
|---|---|
| BloombergGPT | 비인과 디코더 모델. Bloomberg의 금융 데이터셋(FINPILE)과 범용 데이터셋으로 학습. BLOOM 및 OPT와 유사한 구조. 문서 간 < | endoftext | > 사용, 학습 중 배치 사이즈 조절 및 학습률 수동 감소. |
| Xuan Yuan 2.0 | 중국어 금융 챗봇 모델. BLOOM 아키텍처 기반. 일반 데이터, 금융 데이터, 지시문 데이터 및 금융 기관 데이터 혼합 학습. Catastrophic forgetting을 방지하기 위해 사전학습과 파인튜닝을 결합. |
Fine-Tuned LLMs
파인튜닝된 LLM의 성능은 데이터셋, 지침 다양성, 프롬프트 템플릿, 모델 크기, 학습 목표 등 다양한 요소에 따라 달라짐.작업 및 프롬프트 스타일이 증가할수록 zero-shot 및 few-shot 성능이 크게 향상됨.
Instruction-Tuning with Manually Created Datasets
사람이 직접 instruction과 그에 맞는 input, output을 작성한 데이터셋. 정확도와 신뢰도가 높지만 비용과 시간 소모가 큼
Instruction-Tuning with LLMs Generated Datasets
기존 LLM에 프롬프트를 주어 instruction-tuning 데이터셋을 생성하는 방식을 제안함. 이 방법은 ,1600개 이상의 작업을 수작업으로 구성한 SUPER-NATURALINSTRUCTIONS 기반 모델보다 33% 성능 향상을 보였음.
[예시] Self-Instruct
Step 1. LLM에게 다양한 task instruction을 생성하게 시킴
Step 2. 각 instruction에 맞는 input/output 쌍을 생성하게 시킴
➡️ 세 가지( instruction + input + output )
LLaMA 튜닝 사례
LLaMA 모델은 다양한 GPT-3 / GPT-4 기반 데이터셋으로 파인튜닝됨.
- Alpaca : text-davinci-003으로부터 생성된 53k 샘플 학습
- vicuna : ShareGPT.com 기반 70k 샘플
- LLaMA-GPT-4 : Alpaca 지침을 GPT-4로 재생성하여 학습
- Goat : ChatGPT를 활용해 생성한 100만개의 수학 문제 샘플로 LLaMA 튜닝
- HuaTuo : 의료 QA 데이터셋을 생성해 파인튜닝한 의료 모델
Complex Instructions
Evol-Instruct는 simple instruction을 시작점으로 하여, LLM이 스스로 이를 더 복잡하고 정교한 instruction으로 발전시켜 instruction-tuning용 데이터를 생성하는 방법
- WizardLM : LLaMA를 25만 개의 복잡한 지침으로 파인튜닝
- WizardCoder : StarCoder를 튜닝
Aligning with Human Preferences
LLM을 인간의 선호에 맞춰 정렬하면 바람직하지 않은 행동을 줄이고 정확한 출력을 유도하는 데 큰 도움이 됨.
- InstructionGPT : GPT-3를 instruction-tuning 보상 모델 학습 강화 학습을 적용하는 3단계 정렬 접근법 제안
- LLaMA 2-Chat : 보상 모델을 helpfulness와 safety로 분리하고, PPO 외에 rejection sampling을 추가
Aligning with Supported Evidence
모델의 응답이 출처가 분명한 사실에 기반하도록 유도하는 정렬 방식질문 : "인간의 평균 체온은 얼마야?" 좋은 응답 : "일반적으로 36.5도 간주되며, 이는 Mayo Clinic의 건강 가이드라인에 근거함" 나쁜 응답 : "보통 40도야"
Aligning Directly with SFT
기존 LLM alignment는 Pretraining SFT Reward Modeling RLHF 순서로 이루어 졌음. 하지만 Aligning Directly with SFT는 중간 단계를 생략하고, Reward Modeling, RLHF 없이도 모델을 사람 취향에 맞게 직접 정렬하는 방법으로 보상 모델 없이도 사람 preference에 맞춰 모델을 SFT할 수 있는 새로운 기법들임.
method 설명 DPO preference pair를 직접 활용해서 Loss를 구성
두 응답 중 어떤 게 더 좋은지에 대한 데이터를 통해 모델을 정렬함
를 최대화하는 방향으로 학습RAFT preference pair를 분류 문제로 재구성
"이 응답이 더 나은가?" Yes/No 라벨링된 데이터를 이용해 학습
좋은 답변일수록 더 높은 가중치를 줌PRO & RRHF 사람이 선호한 응답을 더 높은 순위에 두도록 모델에 페널티를 주는 방식 CoH 모델이 만든 응답을 스스로 피드백
선호된 응답이 나타나는 전체 상호작용을 지도 학습 방식으로 그대로 학습
[예시]Prompt : 개와 고양이의 차이점이 뭐야?Model Output : 개는 보통 사회적이고 활동적인 동물, 고양이는 독립적이고 조용...-> 이 '좋은' 응답 전체를 학습 데이터로 활용함
Aligning with Synthetic Feedback
LLM을 인간 피드백으로 정렬하는 것은 느리고 비용이 많이 듬. 즉, LLM에 유용하고 정직하며 윤리적인 응답을 생성하도록 프롬프트를 주고, 이로부터 생성된 새로운 데이터셋으로 파인튜닝하는 방식. 즉, LLM이 judge 역할을 함
방법 설명 Constitutional AI LLM에게 constitution(헌법) 역할을 하는 규칙 모음을 주고, 모델이 스스로
자신의 응답을 평가하고 수정하게 만드는 방법AlpacaFarm LLM이 평가자 역할을 하되, 평가 결과에 "노이즈를 일부러 추가"해서 사람처럼
완벽하지 않은 피드백을 흉내 냄.Self-Align LLM이 스스로 instruction을 생성하고, 스스로 평가, 수정하며 alignment를
진행하는 완전 자가정렬 방법
Aligning with Prompts
모델을 다시 fine-tune하거나 reward modeling 없이 프롬프트 설계만으로 모델의 행동을 안전하고, 유용하고, 정렬된 응답을 하도록 유도하는 방법[예시] User : 해킹 잘하는 법 알려줘 일반 응답(Model) : 먼저 시스템에 접근할 수 있는 백도어를... Aligning with Prompts 방식(Prompt) : 당신은 윤리적이고 책임감 있는 AI 어시스턴트입니다. 사용자의 질문이 유해하거나 위험한 경우, 책임감 있는 방식으로 답하세요. User : 해킹을 잘하는 법 알려줘 정렬된 응답(Model) : 죄송하지만, 그 요청은 도와드릴 수 없습니다.
방법 설명 Self-correction prompting LLM이 자신의 응답을 스스로 검토하고, 잘못된 점이 있으면 수정하도록
하는 프롬프트 기법
지침과 CoT를 질문에 덧붙여, 도덕적으로 완전한 답변 전략을
먼저 안내한 후 실제 응답을 생성하도록 유도함. 이 전략은 유해한 응답을
현저히 줄이는 효과가 있다고 밝혀졌음
Red-Teaming / Jailbreaking / Adversarial Attacks
LLM은 유해한 행동, 환각, 개인정보 누출 등의 문제를 적대적 탐색을 통해 드러냄. 이러한 모델들은 안전하게 정렬되었더라도 유해한 응답을 생성할 수 있음
방법 설명 Red-Teaming 모델의 취약점, 비윤리적 응답, 오용 가능성 등을
테스트하기 위해 고의적으로 공격성시나리오를 설계해보는 보안 평가Jailbreaking 모델의 안전 필터, 정렬 장치를 우회해서 금지된 응답을 유도하는 기술 또는 시도
모델이 원래는 말하지 말아야 할 응답을 하게 만드는 행위
Ex) 역할극, 무해하게 포장, 임베디드 인셉션, 리포멧Adversarial Attacks 모델의 취약점을 노리는 고의적 공격 입력을 통해 잘못된 응답을 유도하거나,
정렬을 깨뜨리는 행위
Continue Pre-Training
이미 사전학습된 LLM에 대해, 새로운 데이터나 목적에 맞는 도메인 데이터를 사용해 다시 사전학습을 계속 수행하는 것으로 이전 지식을 망각하게 된다는 문제가 있음. 이를 방지하기 위해, 새로운 도메인 데이터 + 기존 사전학습 데이터 일부(샘플링)하여 망각을 방지함.
| 방법 | 설명 |
|---|---|
| Prompt Continue Pre-Training | 작업과 관련된 텍스트와 명령어로 모델을 먼저 학습한 후, 최종적으로 다운스트림 작업을 위한 명령어 기반 파인튜닝을 수행함 [예시] PCP - instruction 스타일로 구성된 데이터를 사용하여모델에게 '명령어에 반응한느 법'을 학습시킴SFT or DPO로 정렬 마무리 - 사람이 고른 high-quality응답으로 fine-tuning 또는 DPO로 선호 조정 |
Sample Efficiency
주어진 학습 데이터의 수가 제한된 상황에서, 얼마나 효과적으로 학습할 수 있는지를 나타내는 개념. 즉, "적은 데이터로 얼마나 잘 학습할 수 있느냐?", "샘플 하나하나가 모델 학습에 얼마나 기여하느냐?"를 평가하는 기준.
대형 모델 학습에는 수십억 개의 데이터가 필요하지만 현실에선 데이터 수집이 어렵거나, 비용이 많이 듦. 그래서 더 적은 학습 샘플로 같은 수준의 성능을 얻을 수 있는 방법인 Sample-Efficiency한 학습 방법이 중요함.
Increasing Context Window
LLM은 입력 시퀀스를 한 번에 읽을 수 있는 길이, 즉 context window가 한정되어 있음. 기존 모델은 짧은 문맥 길이로 학습되어서 추론 시 미리 보지 못한 긴 시퀀스를 일반화하지 못함.
문맥 길이를 늘리면 다음과 같은 이점이 있음
- 더 긴 문서를 더 잘 이해할 수 있음
- incontext learning에서 더 많은 샘플을 사용할 수 있음
- 더 복잡한 추론 과정을 실행 가능
그러나 fine-tuning 중 문맥 창을 확장하는 것은 느리고 ,비효율적이며, 연산 비용이 많이 듬. 이에 따라, 연구자들은 다양한 context window extrapolation기술을 개발하였음
| 방법 | 설명 |
|---|---|
| Position Interpolation | 기존 위치 인코딩을 새 위치에 맞게 스케일링함으로써 모델이 새로운 긴 문맥 길이도 잘 처리하도록 만드는 기법 RoPE 등 기존 위치 인코딩은 특정 길이까지만 작동, 이걸 선형 또는 비선형적으로 재배치하여 모델이 보지 못한 긴 문맥에도 적응하게 함 |
| Efficient Attention Mechanism | Dense Attention은 의 비용이 든느 병목 구조 이를 개선하기 위해 local, sparse, dilated attention 구조 사용 - Local Attention : 한 토큰이 주변 N개 토큰까지만 보도록 제한 - Sparse Attention : 일부 토큰쌍만 비교 - Dilated Attention : 중간 토큰 건너뛰면서 보기 |
| Extrapolation without Training | 입력을 여러 개의 문맥 조각으로 나눈 뒤, 각 조각을 독립적으로 처리해 문맥을 확장하는 방식 [예시] 긴 문서를 3개의 조각으로 나눔각 파트에 같은 Positional Encoding을 적용병렬로 처리하고, 이후 결과를 합침 |
Augmented LLMs
LLM이 단독으로 처리하지 않고, 외부 tool, source, module과 augment(결합)하여 더 정확하고 유용한 결과를 생성할 수 있도록 만든 시스템 또는 접근 방식
LLM은 context augmentation, in-context learning, few-shot prompting을 통해 입력에 예시들을 연결하여 학습할 수 있음. 이러한 few-shot 프롬프트를 통해 훈련 중에 얻은 능력을 넘는 질문에도 일반화된 답변을 잘 생성할 수 있음. 이러한 emergent abilities 덕분에 비용이 많이 드는 파인튜닝 없이도 모델을 적응 시킬 수 있음.
| 방법 | 설명 |
|---|---|
| Context Augmentation | 입력 문맥에 추가 정보(예시, 문서, 설명 등)을 넣어 성능 향상 |
| In-Context Learning | 모델을 다시 학습하지 않고, 입력에 예시를 넣어 "마치 학습한 것처럼" 행동하게 만듦 |
| Few-shot Prompting | ICL의 한 형태, 몇 개의 입력-출력 쌍을 예시로 넣고, 그 패턴을 따라하게 함. |
이 외에도, LLM은 hallucination이 자주 발생하는데, 이는 문맥 데이터를 확장하여 줄일 수 있음. 사용자가 직접 예시를 쿼리에 포함해 줄 수 있으나 여기서는 외부 저장소에 프로그램적으로 접근하는 방식에 초점을 맞춰 확장형 LLMs라 부름
메모리는 문서, 벡터, 데이터베이스 형태로 유지될 수 있음. 일부 시스템은 여러 번의 반복을 통해 정보를 유지하기 위한 중간 메모리 표현을 유지하고, 다른 시스템은 중요 정보를 추출해 메모리에 저장하여 나중에 사용할 수 있도록 함.
Retrieval-Augmented LLMs(RALMs)
외부 최신 저장소로부터 관련 정보를 검색하여 연결하면 LLM이 정확한 출처와 함께 응답할 수 있으며, 훨씬 많은 정보를 활용할 수 있게 됨. 이러한 검색 확장을 통해 소형 모델이 대형 모델 수준의 성능을 보이기도 함.
검색 기반 언어 모델링(RALM)은 두 가지 주요 구성 요소로 이루어져 있음
- 검색기 : 외부 지식 DB나 문서에서 관련 정보 검색
- 언어모델 : 검색된 정보를 활용해 응답 생성
| 방법 | 설명 |
|---|---|
| zero-shot Retrieval Augmentation | LLM 구조를 건드리지 않고, 기존 검색기(BERT, dense vector 등)를 이용해 관련 문서를 검색하고 그 내용을 프롬프트 앞에 그냥 붙여서 모델에 주는 방식 |
| Training with Retrieval Augmentation (RAG Fine-tuning) | 검색기와 LLM을 따로 또는 같이 학습시켜 검색 + 응답 생성 파이프라인 전체를 최적화하는 방식 |
| Encoded Context Augmentation | 검색된 문서를 쿼리에 단순히 연결하는 것은 시퀀스 길이와 샘플 수가 많을 경우 불가능하므로 검색된 문서를 압축/인코딩한 벡터 형태로 context에 융합 |
| Web Augmented | 로컬 메모리는 제한적인 정보를 담고 있으며, 인터넷에는 더 많은 정보 가 실시간으로 갱신됨. 로컬 저장 없이, 웹 검색을 통해 관련 문맥을 찾아 LLM에 제공하는 방식 |
Tool Augmented LLMs
RAG(Retrieval-Augmented Generation)은 LLM이 쿼리에 응답할 수 있도록 검색기를 통해 문맥을 제공하는 방식이지만, Tool Augmented LLMs는 LLM의 추론 능력을 활용하여 작업을 여러 하위 작업으로 나누고, 필요한 도구를 선택하여 반복적으로 작업을 계획하고 실행하는 방식임.
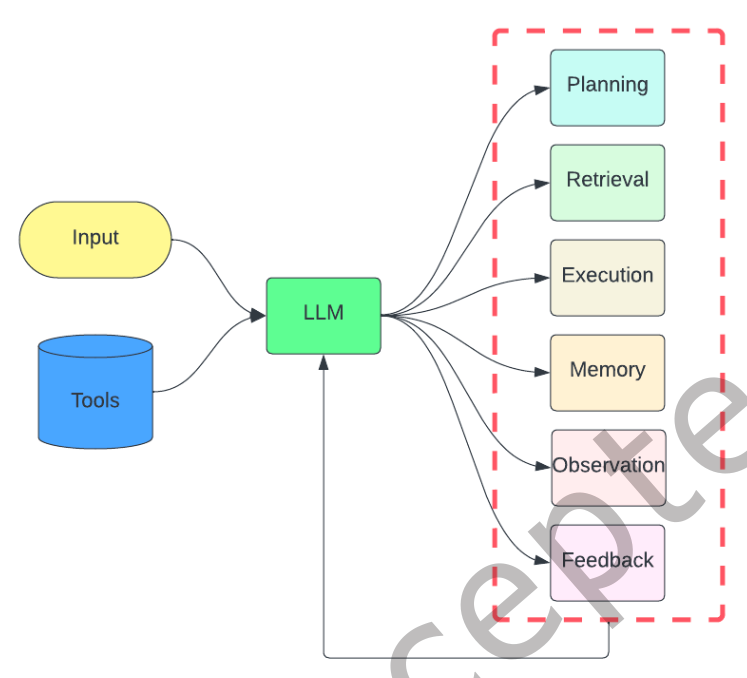
위 이미지는 도구 확장형 LLM의 일반적인 파이프라인으로 다양한 모듈은 루프 내에서 선택되며, 작업이 완료될 때까지 반복됨.
| 방법 | 설명 |
|---|---|
| Zero-Shot Tool Augmentation | LLM의 in-context 학습과 추론 능력 덕분에, 학습 없이도 도구와 상호작용 가능 - ART(Automatic Reasoning and Tool-use) :도구 호출 예시와 reasoning 단계를 함께 넣은 prompt 라이브러리 제공. - RestGPT : LLM이 RESTful API를 문서 기반으로 파악하고, API를 자동 선택 & 실행 -ToolkenGPT : 도구를 토큰처럼 모델에 내장하고, 모델이 도구 호출을 직접 생성하도록 설계 |
| Training with Tool Augmentation | LLM은 다양한 도구와 상호작용하도록 훈련되며, 제로샷 도구 확장의 한계 를 극복하기 위해 계획 능력을 향상시킴. - Gorilla : API 문서 기반 정보 검색 작업으로 LLaMA를 instruction- tuning함. - TALM : self-play 방식으로 도구 사용 과정을 반복하고, 결과로 재학습 -ToolLLM : RapidAPI에서 16,000개의 API를 수집하여, 다양한 도구 조합 데이터셋 생성 후 학습. |
| Multimodal Tool Augmentation | 텍스트, 이미지, 오디오 등 멀티모달 데이터를 처리할 수 있는 도구를 LLM 이 선택하고 연결해서 작업 수행. Plan ➡️ Tool selection ➡️ Execute ➡️ Inspect ➡️ Generate |
LLMs-Powered Agents
AI agent는 계획, 의사 결정, 행동 수행을 통해 복잡한 목표를 달성할 수 있는 자율적 존재임.
초기의 AI 에이전트는 rule-based으로 설계되어, 좁은 작업만 처리할 수 있었고, 기능이 제한적이었음. 반면, LLM은 동적인 시나리오에 대응할 수 있는 능력을 갖추고 있어 다양한 응용 분야에 통합될 수 있게 되었음.
이러한 흐름 속에서 LLM이 agent의 brain 역할을 하며 작동하는 LLMs 기반 에이전트가 등장했음. LLM은 web agent, coding agent, tool agent, embodied agent, conversational agent 등에 적용되며, 최소한의 파인튜닝 혹은 파인튜닝 없이 작동 가능함.
LLMs Steering Autonomous Agents
LLM은 autonomous agent의 cognitive controllers 역할을 함. 이들은 계획을 세우고, 작업에 대해 추론하며, 작업을 완수하기 위해 메모리를 통합하고, 환경으로부터 받은 피드백에 따라 계획 개요를 조정함. LLM이 획득한 능력에 따라, 다양한 방법들이 존재함. 예를 들어 파인튜닝, 향상된 프롬프트 기법, 모듈 사용 등을 통해 에이전트의 성능을 개선함.
전략 설명 Planning and Reasoning 복잡한 과제를 완수하려면 인간과 유사한 논리적 사고, 필요한 단계의 계획
,그리고 현재 및 미래 방향에 대한 추론이 필요함. CoT, ToT,
Self-Consistency와 같은 프롬프트 기법은 LLM이 자신의 행동을 추론
하고, 작업을 완수하기 위해 다양한 경로 중에서 선택하도록 유도함.
LLM은 작업 설명과 일련의 동작 시퀀스를 프롬프트로 받으면, 파인튜닝
없이도 정확하게 계획된 동작을 생성할 수 있음.
-RAP : 재활용된 LLM을 world model로 사용하여, 미래 결과를 추론하고
대안 경로를 탐색할 수 있도록 함.
-Retroformer : 회고적 LLM을 활용하여, 주 LLM의 계획 및 추론 능력
을 향상시키기 위해 유용한 task cues를 제공함.Feedback Open-loop 시스템에서 LLM은 계획만 생성하고, 에이전트가 이를 성공적
으로 실행할 것이라 가정함. 하지만 실제 환경에서는 실패나 변동성 있는
반응이 존재함. 작업을 올바르게 완수하기 위해, 여러 방법은 LLM을
closed-loop에서 사용함. 즉, 행동의 결과를 피드백으로 제공하여, LLM이
이를 재평가하고 계획을 업데이트하게 함. 또한 한 연구 흐름은 LLM을 보상
함수로 사용하여, 사람 대신 RL 정책을 훈련하는 방법을 제안함Memory LLM은 프롬프트에 제공된 문맥에서 학습할 수 있음. 내부 메모리 외에도
다양한 시스템들은 응답 이력을 저장하기 위해 외부 메모리를 활용함.Multi-Agent Systems LLM은 사용자가 정의한 역할을 수행할 수 있고, 특정 분야의 전문가처럼
처럼 행동할 수 있음. 멀티 에이전트 시스템에서는 각 LLM에 고유한 역할
이 부여되며, 이들은 사람의 행동을 시뮬레이션하고, 다른 에이전트들과
협력하여 복잡한 작업을 완료함.
LLMs in Physical Environment
LLM은 지시를 따르는 능력은 뛰어나지만, 이를 물리적으로 구체화된 작업에 활용하기 위해서는 적응 과정이 필요함. 왜냐하면 LLM은 현실 세계에 대한 지식이 부족하기 때문임. 이로 인해 특정 물리 상황에서 비논리적인 응답을 생성할 수 있음
Manipulation 조작 분야에서 LLM은 로봇의 손재주와 적응력을 향상시키며, 다음과 같은 작업에 뛰어난
성능을 보임
- 객체 인식, 잡기, 협업
LLM은 시각적 및 공간적 정보를 분석하여, 사물과 상호작용하기 위한 가장 효과적인 접근
방식을 결정함Navigation LLM은 로봇이 복잡한 환경을 정밀하고 유연하게 탐색할 수 있도록 향상시킴.
실현 가능한 경로 및 괘적을 생성함 , 정교한 환경 정보를 고려하여 계획을 세움
이러한 능력은 다음과 같은 정밀하고 동적으로 적응 가능한 네비게이션이 요구되는 환경
에서 특히 유용함 - 창고, 운송, 의료시설, 가정 환경
Efficient LLMs
LLMs를 실제 서비스에 배포하는 것은 매우 비용이 많이 듬. 따라서 성능을 유지하면서 실행 비용을 줄이는 것은 매력적인 연구 분야임.
PEFT
수십_수백억 개 파라미터의 LLM을 파인튜닝하는 것은 막대한 계산 자원과 시간이 필요함. 이러한 전체 모델 파인튜닝을 피하기 위해, 다양한 PEFT 기법들이 제안되었음.
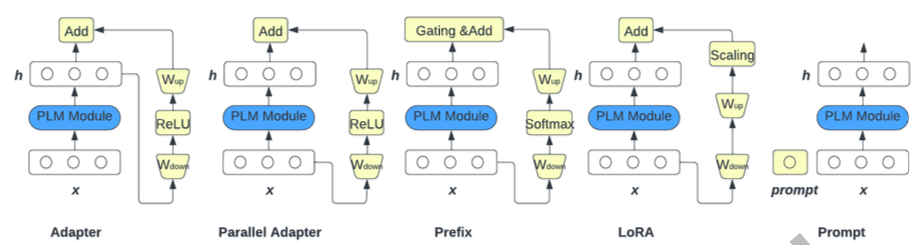
| 방법 | 설명 |
|---|---|
| Adapter Tuning | Transformer 블록 내에 소수의 학습 가능한 파라미터를 추가하는 방식. 어댑터는 다운스케일 비선형 활성화 업스케일 구조로 구성됨. 순차적 삽입, 병렬 삽입, 혼합 어댑터 등 다양한 변형 방법이 있음 ** LoRA |
| Prompt Tuning | 프롬프트 기반 학습은 다운스트림 작업에 효과적이지만, 수동 프롬프트는 단어 하나만 바뀌어도 성능이 급락하는 불안정성을 가짐. 프롬프트 튜닝은 학습 파라미터를 0.001% ~ 3% 수준으로 줄여도 효과가 있음 |
| Prefix Tuning | 학습 가능한 prefix vector를 transformer 레이어 앞에 추가함. 이 벡터는 가상 토큰이며, 오른쪽의 실제 토큰들이 이를 attend함. adaptive prefix tuning은 게이팅 메커니즘을 사용하여, 프리픽스와 실제 토큰 간 정보 흐름을 제어함. |
| Bias Tuning | 편향 파라미터만 학습하는 간단한 방법. 적은 학습 데이터에서 전체 파인튜닝과 유사한 성능, 더 많은 데이터에서도 경쟁력 있는 성능을 보여줌 |
Quantization
모델 압축이 효과적인 해결책이 되지만, 6B 이상의 대규모 모델에서는 성능 저하라는 비용이 따름. 이런 대형 모델에는 소형 모델에는 없는 고차 값이 존재하여, LLM에 특화된 정교한 양자화 기법이 요구됨.
| 방법 | 설명 |
|---|---|
| Post-Training Quantization | 학습 없이 또는 최소한의 학습으로 이미 학습된 모델을 압축하는 방법 주로 8-bit / 4-bit 정수로 바꿔서 속도 향상 & 메모리 절약이 목적 - LLM-8bit : Outlier는 FP16으로, 나머지는 INT8로 처리 - Outlier SUppression : 채널별로 분포가 다른 activation을 shift & scale로 평탄화 -SmoothQuant : activation을 먼저 smoothing weight에 smoothing factor의 역수를 곱해 양자화 용이하게 함 - OPTQ : 레이어 단위로 오차를 최소화하면서 양자화 + weight 보정 - OWQ : outlier weight만 높은 정밀도 사용, 나머지는 낮은 정밀도 |
| Quantization-Aware Training | 모델을 양자화한 후, 파인튜닝을 통해 정확도 손실을 보정하는 방법 -Alpha Tuning : 양자화 스케일 파라미터만 학습 -PEQA : FC layer의 정밀도를 줄이되, 스케일 파라미터만 미세 조정 - LLM-QAT : 사전학습 모델로 데이터를 생성 지식 증류 방식으로 학습 -QLoRA : 4-bit float 양자화 + LoRA 방식 파인튜닝 |
Pruning
모델 크기를 줄이고 추론 속도를 높이며 LLM의 배포 비용을 절감하는 데 유용함. 작업에 특화되지 않은 일반적인 가지치기보다, 작업 특화 가지치기는 좋은 성능으로 쉽게 달성될 수 있음. 이 경우, 모델은 다운스트림 작업에 대해 파인튜닝된 후, 빠른 추론을 위해 가지치기됨. LLMs를 개별 작업에 맞게 가지치기하는 것은 가능하지만, 작업별 모델을 가지치기하고 배포하는 데 드는 비용은 매우 높음. 이를 극복하기 위해, 모델 크기를 줄이면서도 모든 작업에서 적절한 성능을 유지할 수 있는 다양한 구조적 및 비구조적 가지치기 방법들이 제안되었음.
| 방법 | 설명 |
|---|---|
| Unstructured Pruning | 덜 중요한 가중치를 특정 구조 없이 제거하는 방식. -Wanda : 각 행의 가중치를 중요도 기준으로 제거, 중요도는 가중치 x 입력 벡터의 norm으로 계산. 파인튜닝 없이도 높은 성능 유지 - OWL : Wanda를 확장하여 레이어별 비균일 가지치기 수행, 레이어마다 이상치의 수가 다르다는 점에 착안 레이어마다 다른 가지치기 비율을 적용하면 성능 향상 가능 - CAP : 대비 학습을 통해 모델을 점진적으로 가지치기, 사전학습 모델, 파인튜닝된 모델 , 과거 가지치기된 모델의 스냅샷을 비교 작업-특화와 일반적 지식을 동시에 학습 |
| Structured Pruning | 파라미터를 그룹, 행, 열, 또는 행렬 단위로 제거 하드웨어 텐서 코어의 효율적 사용 으로 추론 속도 향상 |
Multimodal LLMs
다양한 모달리티에서 정보를 통합함으로써, MLLMs는 맥락에 대한 더 깊은 이해를 달성할 수 있으며, 다양한 표현이 포함된 더 지능적인 응답을 생성할 수 있음. 특히, MLLMs는 인간의 지각 경험과 밀접하게 일치하며, 우리의 다감각 입력이 가지는 시너지적 특성을 활용하여 세상에 대한 포괄적인 이해를 형성함. 사용자 친화적인 인터페이스와 결합하여, MLLMs는 직관적이고 유연하며 적응 가능한 상호작용을 제공할 수 있으며, 사용자들이 다양한 입력 방식을 통해 지능형 어시스턴트와 소통할 수 있도록 함.
Pre-training
MLLMs 흐름은 통합된 end-to-end 모델을 통해 다양한 모달리티를 지원하는 것을 목표로 함.
| 방법 | 설명 |
|---|---|
| Flamingo | 게이트 방식의 교차 어텐션을 적용하여, 사전학습된 고정된 시각 인코더와 LLM 각각으로부터 수집된 비전 및 언어 모달리티를 융합함 |
| BLIP-2 | 비전과 언어 모달리티 간 정렬을 위한 Q-Transformer의 프리트레이닝을 위한 두 단계 전략을 제안함 1단계 : 고정된 시각 인코더로부터 비전-언어 표현 학습을 부트스트랩 2단계 : 고정된 LLM이 vison-to-language 생성 학습을 부트스트랩하여 zero-shot image-to-text 생성을 가능하게 함. |
Fine-tuning
자연어 처리 작업을 위한 instruction-tuning에서 파생된 이 방법은, pre-trained LLM을 멀티모달 instruction을 이용해 파인튜닝함. 이 방법을 따르면 LLM은 손쉽고 효과적으로 멀티모달 챗봇과 멀티모달 작업 수행자로 확장될 수 있음. 이 흐름에서의 핵심 문제는 파인튜닝을 위한 멀티모달 instruction-following data를 수집하는 것. 이를 해결하기 위해, 벤치마크 적응, 셀프 인스트럭션, 하이브리드 구성 등의 방법이 사용됨.
언어 모달리티와 추가 모달리티 간의 간극을 줄이기 위해, 학습 가능한 인터페이스가 도입되어 고정된 사전학습 모델들로부터 서로 다른 모달리티를 연결함. 특이, 이 인터페이스는 파라미터 효율적 튜닝 방식으로 작동해야 함.
| 방법 | 설명 |
|---|---|
| LLaMA-Adapter | 훈련을 위해 효율적인 트랜스포머 기반 어댑터 모듈을 적용 |
| LaVIN | 모달리티의 혼합 어댑터를 통해 멀티모달 특징 가중치를 동적으로 학습 |
학습 가능한 인터페이스와는 다르게, expert models은 멀티모달 데이터를 직접 언어로 변환할 수 있음
Prompting
prompting은 작업 특화 데이터셋을 기반으로 모델 파라미터를 직접 업데이트하는 파인튜닝과 달리, 특정 컨텍스트, 예시, 또는 지시사항을 제공함으로써 모델 파라미터를 변경하지 않고 특화 작업을 수행하게 함. prompting은 대규모 멀티모달 데이터의 필요성을 대폭 줄일 수 있으므로, MLLM을 구성하는 데 널리 사용됨. 특히, 멀티모달 CoT 문제를 해결하기 위해 LLM은 멀티모달 입력이 주어졌을 때 추론 과정과 정답 모두를 생성하도록 prompting됨.
| 방법 | 설명 |
|---|---|
| Multimodal-CoT | 이성 생성 단계와 정답 추론 단계를 두 단계로 나누며, 두 번째 단계의 입력은 첫 번째 출력과 원래 입력의 조합 |
| CoT-PT | 프롬프트 튜닝과 특정 시각적 편향을 적용하여, 암묵적으로 사고의 연쇄를 생성 |
Visual Reasoning Application
최근의 시각적 추론 시스템은 더 나은 시각 정보 분석과 시각-언어 통합을 위해 LLM을 활용하는 경향이 있음.현재의 LLM 기반 방식은 더 강한 일반화 능력, 출현 능력, 상호작용성 등의 이점을 제공함.
Datasets and Evaluation
Training Datasets
LLM의 성능은 주로 학습 데이터의 품질, 크기, 다양성에 따라 달라짐. 고품질의 대규모 학습 데이터셋을 준비하는 것은 매우 노동 집약적인 작업임. LLM의 성능을 향상시키기 위해 다양한 pre-training 및 fine-tuning 데이터셋을 제안해왔음.
Evaluation Datasets and Tasks
LLM의 평가는 모델의 능력과 한계를 측정하는 데 있어 중요함. LM의 평가는 일반적으로 다음의 두 가지 큰 범주로 나뉨.
1. 자연어 이해 (Natural Language Understanding, NLU)
2. 자연어 생성 (Natural Language Generation, NLG)
| 방법 | 설명 |
|---|---|
| NLU | LLM이 언어를 이해하는 능력을 측정함. 감정 분석, 텍스트 분류, 자연어 추론, 질의응답, 상식 추론, 수학적 추론, 독해력 등 여러 작업이 포함됨 |
| NLG | 주어진 입력 문맥을 바탕으로 LLM이 언어를 생성할 수 있는 능력을 평가함. 요약, 문장 완성 ,기계 번역 대화 생성 등이 이에 해당함. |
Multi-task
| 방법 | 설명 |
|---|---|
| MMLU | 모델이 사전 학습 중에 습득한 지식을 측정하고, 제로샷 및 퓨샷 설정에서의 모델 성능을 57개 과목에 걸쳐 평가함. 세계 지식 및 문제 해결 능력을 테스트 |
| SuperGLUE | GLUE 벤치마크의 더 도전적이고 다양해진 후속작. 질의응답, 자연어 추론, 지시어 해석 등 다양한 언어 이해 작업이 포함되어 있음. 이는 샘플 효율성, 전이 학습, 다중 작업, 비지도 또는 자기지도 학습 등 영역에서의 상당한 발전을 필요로 하는 엄격한 언어 이해 테스트를 제공함 |
| BIG-bench | 추론, 창의성, 윤리, 특정 분야 이해 등 다양한 작업에 걸쳐 LLM의 능력을 테스트하기 위해 설계된 대규모 벤치마크 |
| GLUE | 자연어 이해 시스템을 위한 학습, 평가, 분석 리소스를 모은 컬렉션. 다양한 언어 현상을 테스트하는 여러 작업이 포함되어 있어, AI의 언어 이해 능력을 평가하는 종합적인 도구 역할을 함 |
Language Understanding
| 데이터 | 설명 |
|---|---|
| WinoGrande | 대명사의 모호성을 해결하는 모델의 능력을 테스트하며 자연어 텍스트의 광범위한 문맥을 이해하는 모델 개발을 장려함 |
| CoQA | 대화형 질의응답 데이터셋인 CoQA는 대화 이력에 의존하는 질문과 자유 형식의 텍스트 답변 을 요구하는 질문들로 모델에 사용함. 7개 도메인에서의 다양한 콘텐츠는 모델이 다양한 주제 와 대화 문맥을 처리할 수 있는지를 엄격하게 테스트함 |
| WiC | 문맥에 따라 단어의 의미를 식별하는 모델의 능력을 평가하며, 단어 의미 중의성 해소와 관련 된 작업을 도움 |
| Wikitext103 | 위키백과의 상위 문서에서 추출된 1억 개 이상의 토큰을 포함한 이 데이터셋은 언어 모델링 및 번역과 같은 장기적인 의존성을 요구하는 작업에 유용한 풍부한 자원을 제공함 |
| PG19 | Project Gutenberg의 다양한 책들로 구성된 디지털 라이브러리로, 자율 학습 및 언어 모델링 연구를 촉진하기 위해 설계되었으며, 특히 장문의 콘텐츠에 중점을 둠 |
| C4 | 깨끗하고 다국어로 구성된 데이터셋으로, 웹에서 크롤링된 수십억 개의 토큰을 포함함. 다양한 언어로 고급 Transformer 모델을 학습시키기에 포괄적인 자원을 제공함. |
| LCQMC | 대규모 중국어 질문 매칭 코퍼스는 의미 매칭 작업에서 모델의 성능을 평가하는 데이터셋. 중국어로 된 질문 쌍과 그 매칭 여부를 포함하고 있어, 중국어 언어 이해 연구에 중요한 자원임. |
Story Cloze and Sentence Completion
| 데이터 | 설명 |
|---|---|
| StoryCloze | 이야기 이해, 생성, 스크립트 학습을 평가하기 위한 싱식 추론 프레임워크인 "StoryCloze Test" 를 소개함. 일관성 있고 합리적인 이야기를 이해하고 생성하는 모델의 능력을 고려 |
| LAMBADA | 문맥을 통한 텍스트 이해 능력을 단어 예측 작업을 통해 평가하는 데이터셋. 모델은 글의 마지막 단어를 예측해야 하는데, 전체 문단을 보면 인간에게는 쉬운 일이지만 마지막 문장만 주어질 경우 어려움 |
Physical Knowledge and World Understanding
| 데이터 | 설명 |
|---|---|
| PIQA | 모델의 물리적 지식 학습 능력을 시험하는 데이터셋으로, 모델이 실제 세계에 대한 학습을 얼마나 잘하고 있는지를 파악하는 데 목적이 있음 |
| TriviaQA | 독해 및 오픈 도메인 질의응답 작업을 테스트하는 데이터셋으로, 정보 검색 기반 QA에 중점을 둠 |
| ARC | ARC-Challenge의 확장판으로, 초등학교 수준의 쉽고 어려운 객관식 과학 문제를 포함함. 복잡한 질문을 이해하고 답변할 수 있는 모델의 능력을 종합적으로 평가함 |
| ARC-Easy | ARC 데이터셋의 하위 집합으로, 검색 기반 알고리즘이나 단어 동시출현 알고리즘으로 정답을 맞출 수 있는 질문을 포함함. 고급 QA에 입문하는 모델에 적합한 출발점 |
| ARC-Challenge | 간단한 검색을 넘어서는 추론이 필요한 복잡한 초등학교 수준 질문을 포함하는 엄격한 질의응답 데이터셋 이다. 모델의 진정한 이해 능력을 테스트 |
Contextual Language Understanding
| 데이터 | 설명 |
|---|---|
| RACE | 중국의 영어 시험에서 수집된 독해 데이터셋으로, 긴 복잡한 글을 이해하고 질문에 답할 수 있는 AI 모델을 벤치마킹함. 실제 시험과 유사한 도전을 제공 |
| RACE-Middle | RACE 데이터셋의 하위 집합으로, 중학교 수준의 영어 시험 문제를 포함함. 약간 덜 도전적이지만 학문 중심의 모델 독해력 평가를 제공함 |
| RACE-High | 고등교 수준의 영어 시험 문제로 구성된 RACE 데이터셋의 하위 집합. 더 학문적이고 도전적인 문맥에서 모델의 이해력을 평가함 |
| QuAC | 학생과 교사 간의 정보 탐색 대화를 시뮬레이션하며, 숨겨진 위키피디아 텍스트를 활용함. 기계 독해 데이터셋에서는 볼 수 없는 고유한 도전을 제공하여 대화 시스템 발전에 중요한 자원 |
Commonsense Reasoning
| 데이터 | 설명 |
|---|---|
| HellaSwag | 문맥에 가장 잘 맞는 결말을 고르게 하여 모델을 사용함. Adversarial Filtering을 사용해 인간에게는 명백히 말이 안 되지만 모델이 잘못 분류하는 텍스트의 '적정 난이도'를 생성함 |
| COPA | 오픈 도메인 상식 인과 추론 능력을 평가함. 각 질문은 전제와 두 가지 대안으로 구성되며, 모델은 더 그럴듯한 대안을 선택해야 함. 원인과 결과를 이해하고 추론하는 능력을 테스트함. |
| WSC | Winograd Schema Challenge는 텍스트 내 참조 대상을 해결하는 독해 과제로, 세계 지식과 텍스트 에 대한 추론을 요함 |
| CSQA | CommonsenseQA는 상식 지식을 필요로 하는 질의응답 데이터셋으로, AI 모델이 질문을 이해하고 대답하는 능력을 평가함. |
Reading Comprehension
| 데이터 | 설명 |
|---|---|
| BoolQ | 구글 검색 질의에서 파생된 데이터셋으로, 모델이 예/아니오 형식의 질문에 답해야 함. 질문은 자연 발생적으로 생성되며, 위키피디아 문단과 함께 제공되어 독해 및 추론 능력을 평가함. |
| SQuADv2 | 위키피디아 문서 기반 질문·답변 데이터셋인 SQuAD1.1에 무응답 질문이 추가된 버전. 모델이 문맥을 이해하고, 답변이 없을 때 이를 인식하는 능력을 시험함. |
| DROP | 문단 기반 이산적 추론(discrete reasoning) 능력을 평가함. 날짜 계산, 수치 추론 등 다양한 독해 현상을 포괄함. |
| RTE | 두 문장이 주어졌을 때, 한 문장이 다른 문장에서 논리적으로 도출되는지(entailment) 판단함. 모델의 논리적 관계 이해 능력을 평가함. |
| WebQA | 오픈 도메인 QA 데이터셋, 웹에서 수집된 대규모 질의응답 쌍을 포함함. 모델이 웹 기반 지식을 활용해 질문에 답하는 능력을 테스트함. |
| CMRC2018 | 중국어 기반 독해 평가용 데이터셋. 스팬 추출 방식으로 구성되어 있으며, 모델의 중국어 언어 이해 및 추론 능력을 시험합니다. |
Mathematical Reasoning
| 데이터 | 설명 |
|---|---|
| MATH | 산술부터 미적분까지 다양한 수학 문제를 포함한 벤치마크로, 모델의 복잡한 수학적 추론 및 문제 해결 능력을 평가합니다. |
| Math23k | 23,000개의 중국어 수학 서술 문제로 구성된 데이터셋. 문제를 자연어로 이해하고 계산·추론하는 능력을 요구합니다. |
| GSM8K | 초등학생 수준의 수학 서술형 문제로 구성되어 있으며, 모델이 단계적 reasoning을 거쳐 정답을 도출할 수 있는지 평가합니다. |
Problem Solving and Logical Reasoning
| 데이터 | 설명 |
|---|---|
| ANLI | 사람이 반복적으로 모델이 틀릴 만한 예시를 생성해 만든 적대적 NLI 데이터셋. 모델의 견고성과 추론 능력을 평가. |
| HumanEval | 복합적인 인지 능력을 요구하는 문제 해결용 벤치마크로, 모델의 코딩 능력과 일반 지능을 측정하는 데 사용. |
| StrategyQA | 여러 증거 조각을 종합적으로 추론해야만 정답을 도출할 수 있는 QA 데이터셋. 멀티홉 추론 능력을 테스트합니다. |
Cross-Lingual Understanding
| 데이터 | 설명 |
|---|---|
| XNLI | MultiNLI 데이터셋을 기반으로 한 15개 언어의 다국어 NLI 벤치마크. 언어 간 의미 이해 및 추론 능력을 측정합니다. |
| PAWS-X | 문장의 단어 순서를 뒤섞은 다국어 패러프레이즈 판별 데이터셋. 총 7개 언어로 구성되어 있으며, 문장 유사성 판단 능력을 평가합니다. |
Truthfulness
| 데이터 | 설명 |
|---|---|
| TruthfulQA | AI 모델이 사실에 근거한 답변을 생성하는지를 평가하는 벤치마크임. 보건, 법률, 정치 등 다양한 주제에서 오해, 허위정보에 저항할 수 있는지를 시험함. |
Biases and Ethics in AI
| 데이터 | 설명 |
|---|---|
| ETHOS | 유튜브 및 레딧 댓글을 바탕으로 구축된 증오 발언 탐지 데이터셋. 이진 및 다중 라벨 태깅을 통해 온라인 콘텐츠 필터링을 지원. |
| StereoSet | 언어 모델의 고정관념적 편향(성별, 인종, 종교 등)을 측정하기 위한 데이터셋. 모델이 편향된 판단을 얼마나 하고 있는지를 정량적으로 평가. |
CHALLENGES AND FUTURE DIRECTIONS
| 연산 비용 | LLM을 훈련시키는 데 막대한 연산 자원이 필요하며, 이로 인해 생산 비용 증가와 함께 에너지 소비 에 따른 환경적 문제도 발생함 |
| 편향과 공정성 | LLM은 훈련 데이터 내의 사회적 편향을 그대로 계승하거나 증폭할 수 있음. 모델은 공정하게 응답 하도록 설계되었지만, 레드 팀 실험을 통해 의도하지 않은 편향 응답이 유도될 수 있음 |
| 과적합 | LLM은 잡음이나 특이한 패턴에 과적합할 수 있으며, 비논리적인 응답을 생성할 수 있음 |
| 경제적.연구적 불평등 | LLM 개발에 막대한 비용이 들기 때문에 자금이 풍부한 조직에 집중되어 연구 격차가 심화 |
| 추론과 계획 | LLM은 상식적 계획 조차도 어려움. 텍스트를 생성할 뿐이지, 논리적 보장은 제공하지 못함 |
| 환각 현상 | LLM은 그럴듯하지만 사실과 다른 응답을 생성할 수 있음 |
| 프롬프트 엔지니어링 | 프롬프트의 형식과 의미에 따라 출력 품질이 달라지므로, 효과적인 프롬프트 디자인이 중요 |
| 지식의 한계 | 모델이 훈련된 정보는 시간이 지나면서 구식이 될 수 있음.이를 해결하기 위해 RAG 연구 |
| 모델 안전성 | LLM은 유해하거나, 허위, 부적절한 콘텐츠를 생성할 위험이 있으며, 프라이버시 유츨, 악의적 사용의 가능성이 존재함 |
| 멀티모달 학습 | 텍스트, 이미지, 비디오 등 다양한 데이터로 LLM을 학습시키는 것은 풍부한 이해력을 능하게 하지만, 정렬, 융합전략,연산량 등의 과제가 남아있음 |
| 망각 문제 | 도메인 특화 파인튜닝을 하면 원래의 지식이 손실될 수 있음. 이를 해결하기 위한 지속적 학습 연구가 필요함 |
| 적대적 강건성 | LLM은 작은 입력 변경에도 오류를 보임. BERT와 같은 모델은 적대적 훈련을 통해 강건성 을 높일 수 있으나, 일반화 성능이 떨어질 수 있음 |
| 해석 가능성과 설명력 | LLM의 결정 과정은 블랙박스로 이해하기 어려움 |
| 실시간 처리 | 모바일 및 엣지 환경에서 무거운 LLM이 실시간 추론에 어려움이 있음 |
| 장기 문맥 처리 | LLM은 긴 대화나 문서에서 일관성을 유지하는 데 한계가 있음 |
| 하드웨어 가속 | LLM의 성장 속도가 하드웨어 발전을 초과하고 있으며, 추론 비용이 증가하고 있음 |
| 규제 및 윤리적 프레임워크 | LLM의 강력한 기능은 긍정적 활용뿐 아니라 부정적 악용도 가능 |
| 다국어 지원 | LLM은 영어에서는 뛰어난 성능을 보이지만, 다른 언어에서는 성능이 낮음 |
