LLM-Based Offline Learning for Embodied Agents via Consistency-Guided Reward Ensemble

Introduction
LLM을 agent의 뇌처럼 직접 사용하는 것은 복잡한 환경 특화 프롬프트 설계 & 막대한 계산 자원 요구 & 모델 추론 지연과 같은 비효율성이 동반됨. 이러한 단점은 Embodied agent가 빠르고 효율적으로 반응해야 하는 상황에서 LLM의 실용적인 적용에 한계를 줄 수 있음.
기존 offline RL 접근법은 효율적인 agent 구조를 구축하기 위해서 실시간으로 환경과 상호작용하기 보다 미리 수집한 에이전트의 행동 기록 + 보상 정보를 이용해서 학습을 하였음. 하지만 instruction-following tasks의 특성은, long-horizon goal-reaching 성격(청소 ➡️ 물건 정리 ➡️ 청소기 작동 ➡️ 쓰레기 버리기 등) 때문에, offline RL은 학습 데이터에 모든 단계에 대한 데이터가 있어야 하지만, Long-horizon은 중간 단계 보상 정보는 거의 없고 마지막에만 보상이 생기므로 요구하는 데이터 특성과 실제 데이터 특성이 서로 충돌하게 됨.
instruction-following tasks가 이진 결과(success or failure)를 기준으로 평가되므로 Embodied Agent는 일반적으로 sparse reward feedback을 포함하는 궤적을 생성함. 그러므로 Offline RL에서는 sparse reward 설정이 효과적인 에이전트 정책을 달성하는 데 중대한 도전 과제가 됨.
Sparse vs Dense?
종류 설명 특징 Sparse reward 성공했을 때만 보상 학습이 현실적
학습이 어려움(무엇이 잘한 행동인지 알 수 없음)
어떤 행동이 결과에 기여했는지 추적하기 어려움Dense reward 진행 단계마다 피드백 학습이 빠르고 안정적
부적절한 보상 설계 시 잘못된 행동 학습 가능
이 논문은 Offline RL을 위해 LLM을 탐구함. LLM을 reward estimator로 활용하여 agent actions에 즉각적인 피드백을 제공함으로써, agent의 궤젝 데이터셋을 dense-reward information으로 증강함. 이렇게 LLM-based reward estimator는 embodied agent를 위한 오프라인 RL의 효과를 크게 향상시킬 수 있음.
LLM-based reward estimator의 제한점은 없을까? 아니다 오프라인 환경에서 환경과의 상호작용이 제한되므로, LLM이 필수적인 환경 정보를 습득하는 데 어려움을 겪는다는 점이 존재한다. 오프라인 설정에서 생성된 보상이 특정 환경 도메인에 적절하게 적용된다는 것을 보장하기 어려움.
예시
타겟 환경에서 꽃병이 일반적으로 거실에 놓인다는 명시적인 지식이 없다면, LLM은 식물에 물을 주는 task에서 "거실로 이동" vs "발코니로 이동"과 같은 행동에 대한 보상을 정확하게 할당하는 데 어려움을 겪을 수 있음.
위 예시에서 두 행동 모두 상식적으로 타당해 보이지만, 최적의 행동은 LLM이 접근할 수 없는 타겟 환경의 구체적인 조건에 따라 달라짐.
물론 online 방식은 사람이나 환경과 반복 상호작용을 하면서 프롬프트를 fine-tuning하면서 이러한 제한점을 해결할 수 있겠지만, offline 방식은 이러한 상호작용이 불가능하므로 같은 방식으로는 문제를 해결할 수 없다.
| 구분 | 설명 |
|---|---|
| Online | 에이전트가 실시간으로 환경과 상호작용하면서 학습 데이터를 직접 수집하고 개선할 수 있는 방식 |
| Offline | 에이전트가 이미 수집된 고정된 데이터만 가지고 학습하며, 환경과의 추가 상호작용은 불가능한 방식 |
그래서 LLM-based reward estimator의 한계를 해결하기 위해 COREN(consistency-guided reward ensemble framework) 를 제안함.
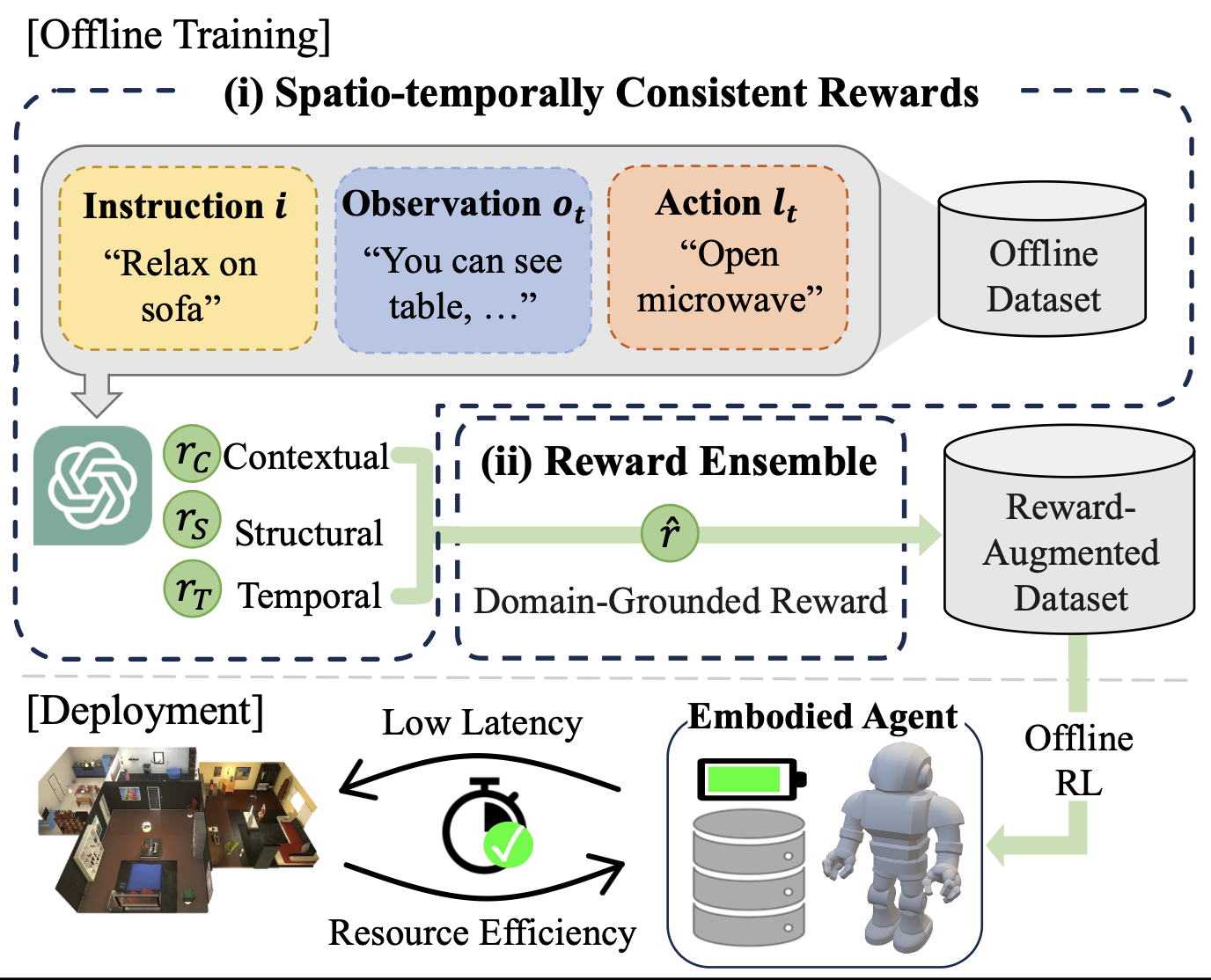
COREN은 이미지와 같이 두 단계의 보상 추정 과정을 채택함.
단계 설명 Spatio-temporally Consistenct Rewards 1. Instruction, Observation, Action이 포함된 offline dataset이 있음
2. 이 데이터를 GPT(LLM)에 넣음
3. GPT가 Contextual, Structural, Temporal reward 계산Reward Ensemble 4. 이 rewards를 ensemble해서 domain-grounded reward를 계산
5.이 보상으로 reward-augmented dataset을 만듦
이렇게 통합된 dense rewards로 offline RL을 통해 훈련된 agent는 배포 시 instruction-following tasks를 높은 효율성과 최소한의 지연으로 수행할 수 있으며 이는 LLM-based reward estimation으로 강화된 offline RL이 LLM을 온라인으로 활용하는 기존 방식의 에이전트들이 직면했던 한계를 극복함.
Preliminaries
Goal-POMDPs
user-specified instructions을 따르는 emboided agent를 위해, 환경을 목표 조건이 있는 goal-conditioned partially observable Markov decision process(Goal-POMDP)로 모델링함. (환경 상태, 행동, 목표, 관측, 보상 등을 포함한 일반적인 강화학습 포맷이지만, 목표 조건이 명시적으로 들어가는 것이 핵심 차이점)
Goal-POMDP는 튜플 ()로 표현됨
| 요소 | 기호 | |
|---|---|---|
| 상태 | 환경의 실제 상태. agent는 이를 완전히 알 수 없음 | |
| 행동 | agent가 취할 수 있는 행동 | |
| 할인 계수 | 미래 보상의 가치를 현재로 환산하기 위한 계수 (0에 가까울수록 단기, 1에 가까울수록 장기 목표 중시) | |
| 관측 | agent가 실제 상태 로부터 받아볼 수 있는 관측 정보(상태를 직접 알지 못하고 간접적으로 봄) | |
| 목표 조건 | agent가 달성해야 하는 목표들의 집합 | |
| 전이 함수 | 현재 상태 s와 행동 a를 취했을 때, 다음 상태 s'로의 확률 분포. 는 상태 공간 위의 확률 분포 | |
| 보상 함수 | 특정 목표 조건 하에서, 상태 와 행동 에 대해 받는 보상 | |
| 관측 전이 함수 | 상태와 행동으로부터 관측을 생성하는 함수 |
기존의 POMDP에서는 보상은 단순히 나 등으로 표현됨. 하지만 Goal-POMDP에서 보상은 로 보상 함수는 목표 조건()에 conditioned 되어 있다는 점이 핵심임. 따라서 같은 상태-행동 쌍이라도, 어떤 목표를 수행 중이냐에 따라 보상이 달라질 수 있음
instruction 는 일련의 목표 조건 로 구성됨. 즉, 사용자의 자연어 instruction 는 하나의 행동이 아니라, 하위 목표들로 구성된 일련의 목표 시퀀스로 모델링됨.
Agent는 무엇을 하는가?
에이전트는 instruction 를 받아, 그것이 표현하는 일련의 목표 조건 을 순차적으로 달성해야 하며, 각 단계마다 Goal-POMDP 구조에 따라 부분적으로 관측 가능한 상태 만 보고, 어떤 행동 를 선택할지 결정하게 됨.
예시
instruction : "책상 정리하고 물건은 서랍에 넣어"
이를 목표 시퀀스로 바꾸면
1. : "책상 위의 물건 식별하기"
2. : "물건 집기"
3. : "서랍 위치로 이동"
4, : "물건 넣기"이때, agent는 관측값 만 보고 매 시점에 어떤 행동 를 선택해야 할지 결정하고, 목표 를 성공하면 다음 단계로 넘어감.그리고 각 행동에 대해 가 주어짐
Offlien RL
Goal-POMDP에 대해, optimal policy는 다음과 같이 fromulated됨.
이 수식은 목표 조건 가 주어졌을 때, agent가 정책 를 따라 행동하여 얻을 수 있는 기대 보상을 최대화하는 정책 을 구하는 것이 목적임.
| 기호 | 의미 |
|---|---|
| agent의 정책 | |
| 정책 를 따라 생성된 상태 와 행동 | |
| 목표 조건은 전체 목표 집합 에서 샘플링 |
Offline RL은 policy가 Bellman error objective를 최적화함으로써 도출됨. 이 방법은 환경과의 상호작용 없이, 오직 오프라인 데이터셋 에만 의존함.
이 방법은 물리적 객체와의 환경 내 active exploration과 관련된 위험과 비용을 줄여주므로 embodied agent에게 유익함. 데이터셋은 다음과 같음
- : instruction 에 헤당하는 tragectory
기존 Offline RL과 달리, 이 데이터셋 는 sparse rewards를 포함함. 이러한 sparsity는 궤적의 부분 집합에 나타나며(전체 궤적들 중 일부 궤적에만 보상이 존재하고, 나머지 궤적에는 보상이 전혀 없다는 뜻), 해당 궤적 가 isntruction 에 대한 모든 필수 목표 조건을 만족했는지를 타나태는 success flag 로 표시됨.
이러한 sparse reward setup은 Goal-POMDP 내에서 각 instruction이 일련의 목표 조건으로 취급되므로, embodied instruction-following tasks에 내재적임.
⭐️ Our Approach
| 접근법 | 설명 |
|---|---|
| LLM-based reward estimation | Offline RL은 agent가 환경과 직접 상호작용 하지 않고 학습할 수 있지만 , sparse rewards에만 의존하여 장기 instruction-following tasks를 학습하는 것은 종종 비효율적임 이를 개선하기 위해 LLM-based reward estimation을 통해 stepwise intrinsic rewards를 agent 궤적에 추가함 |
| Not-grounded reward estimation | LLM이 중간 단계에서 추정한 instrinsic reward는 각 instruction-following task의 결과에서 제공되는 sparse rewards와 일관되게 정렬되지 않을 수 있음 (중간 추론 보상과 실제 결과 보상이 정렬되지 않음) 이렇게 LLM이 생성한 보상이 환경과 "정렬되지 않았기 때문에 not-grounded라고 부름" 이 문제는 특히 partially observable 환경 설정에서 약화된다. 그 이유는 POMDP 방식에서 agent는 전체 상태 를 모르고 일부 관측 만 보면서 판단해야 하기 때문에 관측값이 제한적이므로 판단 근거가 불완전함 결국 LLM은 보상을 상상할 수밖에 없어 오류 가능성이 높아지게 됨. |
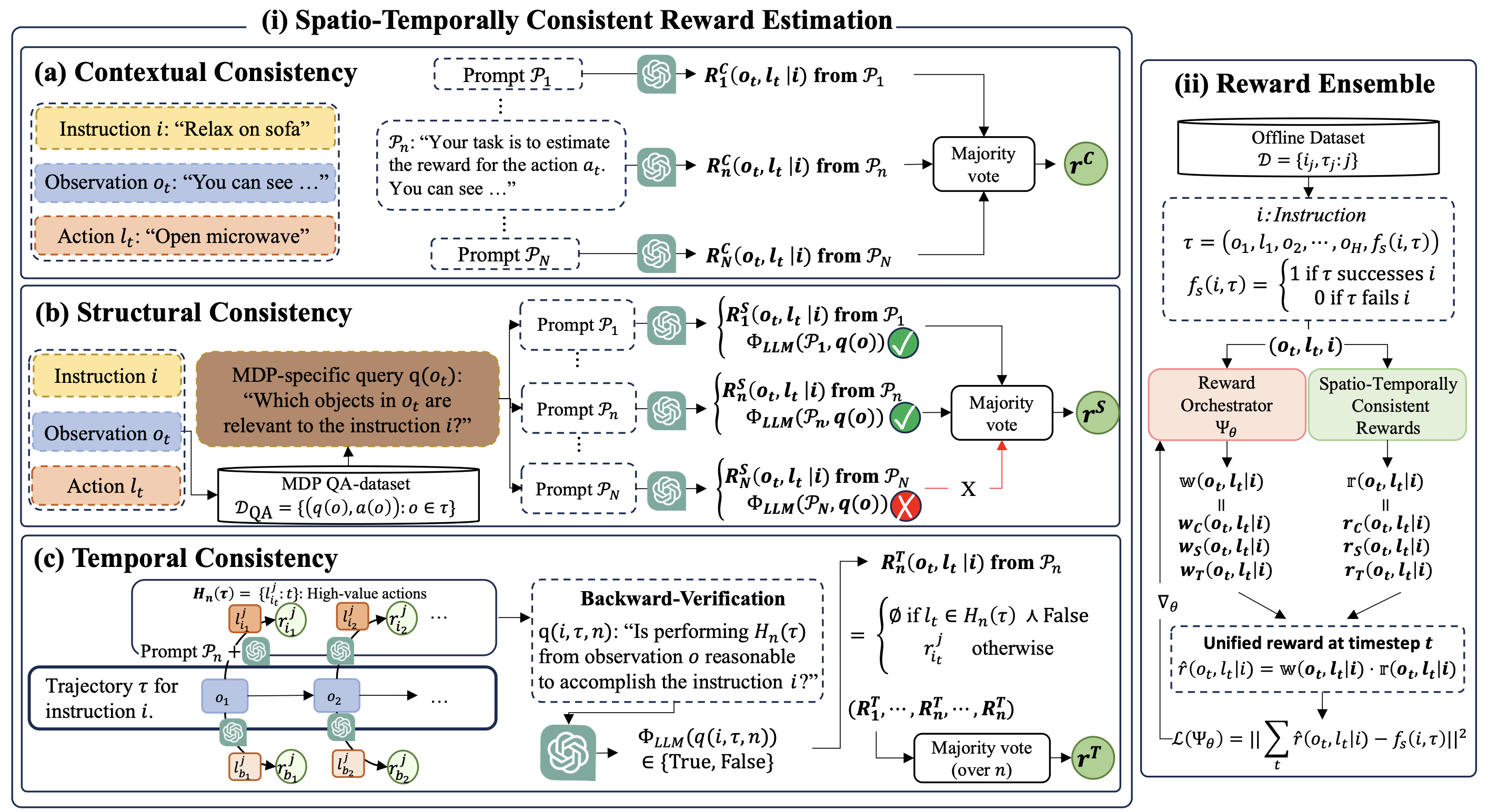
1️⃣ Spatio-Temporally Consistent Rewards
reward estimation을 위해 LLM() & 서로 다른 개의 프롬프트 을 사용함. 각 프롬프트는 unique explanations, in-context demonstrations, chain-of-thought(CoT) 사용 여부에 따라 구분됨.
각 프롬프트()는 관측값(), 행동(),instruction()와 결합여 LLM 추론을 통해 보상 을 생성함
Contextual consistency
LLM 기반 보상 추정 시 사용되는 특정 프롬프트 맥락에서 비롯되는 bias를 완화하는 것을 목표로 함. 서로 다른 contextual frame을 가진 개의 프롬프트를 사용해서, 다양한 조건에서도 일관된 보상을 생성함.
Structural consistency
reward estimation이 환경의 물리적 구조(객체, 객체 간의 관계, 지시와의 관련성)에 대한 포괄적인 이해를 통합하는게 중점임.
LLM에게 관측값 에 대해 다음과 같은 MDP-specific queries 를 질의함. "에 나타나는 어떤 객체들이 instruciton 와 관련이 있을까?". 이 query에 대한 응답은 를 활용하여, 프롬프트 에 대한 보상 를 다음과 같이 통합함.
query violation 경우를 위해 (1)을 다음과 같이 재작성함
| 정리 |
|---|
| 1. 먼저 각 프롬프트 에 대해 행동 보상 을 생성 2. 이 프롬프트가 환경 구조를 제대로 이해했는지를 검증하기 위해, 같은 질문을 프롬프트에 붙여 LLM에 질의(sentence similarity 점수 사용) 3. 0.5이상 값을 가지면 신뢰할 수 있는 프롬프트로 간주하고 통과된 프롬프트들의 보상만 가지고 majority voting 수행 |
MDP-specific queries and answer
질의에 대한 응답의 정확성을 평가함으로써, 보상 추정이 환경의 내부 구조를 적절히 고려하며 수행되었는지를 판단함.에 대한 정답을 생성하기 위해, GPT-4를 사용
instruction에 따라 목표를 달성하는 데 중요한 역할을 하는 객체들을 식별하는 데 초점을 둔 질의들을 생성함.총 139개의 QA쌍을 생성하며, 밑에 이미지는 QA-pair의 예시를 보여줌
관측값 가 주어졌을 때, 은 프롬프트 과 함께 을 입력으로 받아 응답 을 생성함. 여기서 은 관측값 와 간의 sentence embedding similarity에 기반해 선택됨.
항목 내용 현재 보상 추정 하고 싶은 시점의 관측, "컵을 들고 있고, 앞에는 식탁과 냉장고가 보인다" 와 문장 임베딩 유사도가 높은 기존 QA 데이터셋의 관측값, "컵을 들고 있고, 앞에는 식탁과 소파가 보인다" 을 기반으로 만든 간단한 구조적 질문, "instruction이 컵을 식탁 위에 올려놔일때, 이 관측에서 중요한 객체는?" 에 대한 정답, "컵, 식탁" LLM이 에 정확히 답하면, 해당 프롬프트를 기반으로 한 보상 추정도 신뢰 가능


Temporal consistency
모든 decision-making process에서 행동에 할당된 보상 값이 일관되게 유지되도록 설계되었음.
forward reasoning으로 특정 행동을 높은 가치로 평가한 경우, backward verification이 이러한 high-value 행동들이 실제로 instruction을 달성할 수 있는지를 확인해야 함.
이러한 backward verification을 위해 를 통해 LLM에 질의함. "관측 에서 고가치 행동 을 수행하는 것이 isntruction 를 달성하는 데 합리적인가?
이 쿼리에 대한 응답 에 따라 보상이 결정되며, 쿼리 위반 경우에 대한 식은 다음과 같음
- : 행동 이 고가치 행동 집합 에 속하면서 LLM이 에 대해 False로 판단했을 때로 "좋은 행동처럼 보이지만, LLM은 이 행동이 instruction을 완수하는 데 적절하지 않다고 판단한 경우"
모든 궤적 내 관측 에 대해, 고가치 행동은 다음과 같이 정의 됨
N개의 프롬프트가 주어졌을 때, 각 프롬프트로부터 생성된 보상들을 다수결 투표 방식으로 통합하여, 시간적으로 일관된 보상을 설정함
| 정리 |
|---|
| 1. LLM은 각 프롬프트 에서 관측 와 instruction 에 대해 가능한 행동들 중에서 가장 높은 보상을 가진 행동을 선택 2. 이 고가치 행동이 정말 instruction을 달성할 수 있는지 확인하기 위해 LLM에게 역방향 질의 3.LLM이 False라고 판단하면 이 행동의 보상은 제외 4. 이렇게 역검증을 통과한 고가치 행동들에 대해 보상을 majority voting으로 통합하여 시간적으로 일관된 보상 생성 |
Domain-Grounded Reward Ensemble
앞에서 계산된 시공간 일관성 보상들 로부터 주어진 offline trajectories들과의 정렬에 기반하여, domain-grounded 보상을 앙상블을 통해 도출함
unified reward()은 다음과 같이 모델링됨
는 학습 가능한 가중치로, 이 는 reward orchestrator 에 의해 생성됨.
는 관측 , 행동 , 지시 를 입력 받아, 에 대한 softmax distribution을 출력함.
는 trajectory predicted return과 labeled return을 align하기 위해 사용됨.
위 식에서 보이듯이 는 의 누적 합이 sparse reward 와 잘 맞도록 가중치를 학습함
정리
- 기존 offline RL의 한계점
제공되는 보상이 성공 / 실패 정도의 sparse reward ➡️ 긴 행동 시퀀스 학습에는 비효율적 - COREN의 첫 번째 해결책
LLM 보상 추정기를 활용해 각 step별 dense reward 생성
이렇게 하면 중간 행동에 대한 피드백을 줄 수 있어 학습 효율 향상 - LLM based estimator의 문제
LLM이 "그럴듯하지만 실제 환경에서는 불가능"한 행동에도 높은 보상을 줄 수 있음 - COREN의 두 번째 해결책
3가지 일관성 검증을 통해 LLM 보상에 현실성 부여
한계점
- LLM 성능 의존성
COREN이 생성하는 dense reward 품질은 LLM이 환경 도메인을 얼마나 잘 이해하는지에 크게 좌우 됨. 만약 LLM이 사전 학습에서 경험하지 못한 환경 구조나 규칙을 만나면, 보상 추정이 부정확해질 수 있음 - domain shift에 취약
COREN은 오프라인에서 학습된 정책과 보상을 사용 ➡️ 학습 후 환경이 변하면 성능이 하락
특히 non-stationary Goal_POMDP 환경에서는, 학습 시 생성된 보상이 새로운 환경 상황과 불일치할 수 있음 - 보상 재학습이 어려움
오프라인 설정이라 학습 후 환경 변화에 따라 LLM 보상을 실시간으로 업데이트 하거나 재학습하는 것이 어려움. 동적으로 변하는 환경에서는 장기적으로 유지 성능 이 떨어짐
