웹크롤링 절차
- HTML 소스코드 불러오기 (Request, Selenium..)
- HTML 소스코드 파싱하기 (BeautifulSoup)
- 반복문을 활용하여 원하는 정보 추출
파싱 : 구문을 분석하는 것
0. HTML
HTML이란 웹페이지 어떻게 나타낼지 명령하는 언어
< > 를 활용한 '태그'로 구성
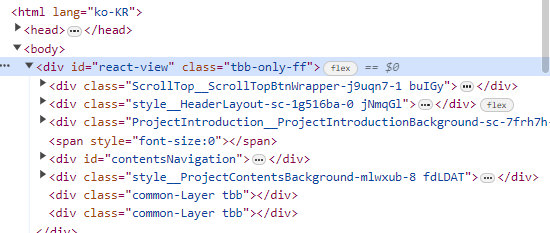
<태그들의 색깔>
보라색 : 태그 이름
노란색 : 속성
파란색 : 속성 정보
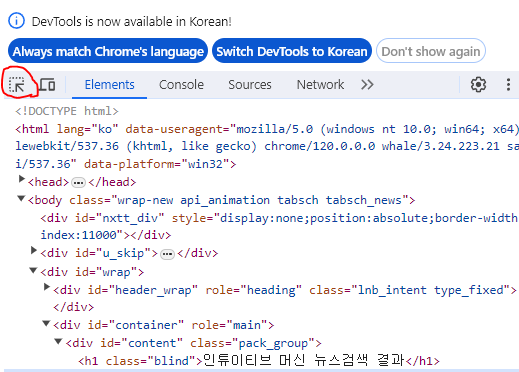
해당 버튼을 클릭해 각 부분의 html 코드를 볼 수 있다
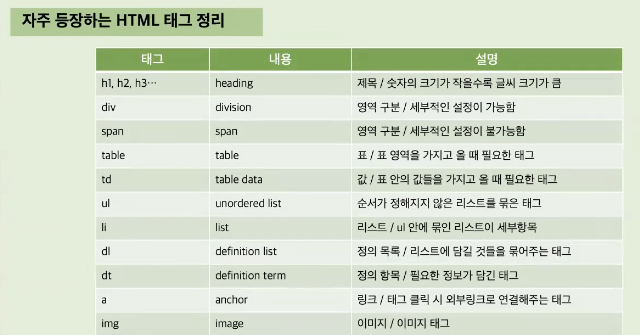
<자주 등장하는 태그 정리>
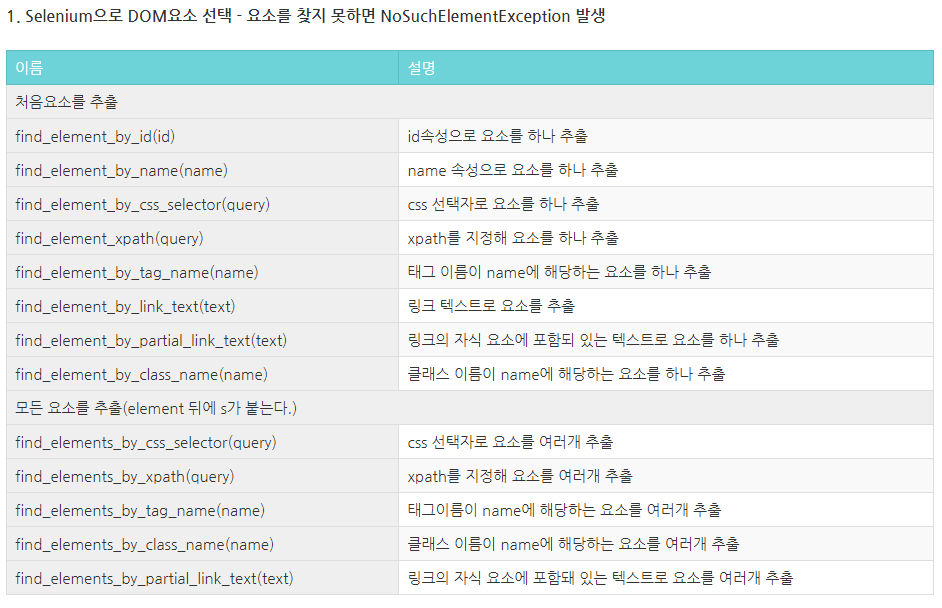
1. Request
# 웹 페이지 URL
url = 'https://tumblbug.com/deepdaiv/......'
# 웹 페이지의 HTML 가져오기
response = requests.get(url)
html = response.text
# BeautifulSoup 객체 생성
soup = BeautifulSoup(html, 'lxml') # 'html.parser'도 가능BeautifulSoup : 스크래핑을 하기위해 사용하는 패키지
lxml : 구문을 분석하기 위한 parser
BeautifulSoup은 response.text를 통해 가져온 HTML 문서를 탐색해서 원하는 부분을 뽑아내는 역할을 하는 라이브러리
또한, response.text로 가져온 HTML문서는 단순히 String에 지나지 않으니, lxml을 통하여 의미있는 HTML문서로 변환
결론적으로, response.text로 가져온 String은 lxml이라는 모듈의 해석에 의하여 의미있는 HTML 문서로 변환되고, 이렇게 변환된 HTML문서는 BeautifulSoup에 의해서 원하는 부분을 탐색할 수 있게 된다.
BeautifulSoup에서 많이 쓰는 함수들
.find 태그명과 속성 정보로 매치되는 것 한개만 찾을 때
.find_all : 태그명과 속성 정보로 매치되는 것 모두를 찾을 때 -> list형태로 반환
.text 태그의 텍스트를 출력할 때
.get 태그의 속성 정보를 가지고 올 때
soupd.find('태그명', {'속성' : '속성 정보'})
soup.find('span', attrs = {'class' : '...'})
soup.find('div', class_='...') soup.find('meta', attrs={'property':'og:title'})
속성정보를 입력하는 경우 attrs에 딕셔너리 형태로 입력
soup.find()로 찾은 태그가
자식 태그까지 포함하는 경우 자식 태그까지 모두 가져온다
soup.find('ul', attrs={'class':'type01'}
여기서 class는 속성, type01은 속성정보, dictionary형태로 attrs = {'속성':'속성정보'}로 가져옴
soup.find('ul', attrs={'class':'type01'}.find('a')
find로 찾은데서 다시 find로 다시 그 안에 있는 태그를 가져올 수 있다
soup.find('ul', attrs={'class':'type01'}.find('a').get('title')
contents = soup.find('div', attrs = {'class' : 'news my news section _prs _nws})
-> contents.find()를 활용하여 원하는 정보 검색
2. Selenium
웹 어플리케이션을 테스트하기 위해 고안된 프레임워크로
크롤링을 위해 웹을 동작시키는 데 매우 유용
requests 모델에 비해 selenium은 속도가 좀 느리다
selenium 웹을 동작시키고
beautifulsoup로 소스코드를 파싱
selenium을 쓰는 경우
1. 로그인을 해야하는 경우
2. 웹을 동작시켜야만 원하는 정보가 나오는 경우
ex) 마우스를 갖다대야만 가격이 나오는 경우
ex) 스크롤 다운을 해야 정보가 나오는 경우 (페이스북 등)
<셀레니움 패키지 호출>
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 경우에 따라 추가# Chrome 열기
driver = webdriver.Chrome()
# 웹 페이지 열기
url = 'https://tumblbug.com/discover?category=zines&ongoing=confirm&tab=category'
driver.get(url)
time.sleep(2) # 오픈 될 때까지 코드를 지연시킬 수 있다
# 오픈한 웹 페이지의 source를 저장, soup로 연결
html = driver.page_source
soup = BeautifulSoup(html,'lxml')
# 드라이버 닫기
driver.close() 이제 크롬 드라이버를 따로 깔지 않아도 webdriver.Chrome()을 하면 크롬이 열린다
열고 싶은 url을 지정 후 driver.get(url)


# xpath 로 접근
driver.find_element(By.XPATH, '//*[@id="query...."]')
<Send_keys로 검색>
query = driver.find_element(By.XPATH, '//*[@id="query"]')
query.send_keys('코로나') # send_keys로 검색도 가능<click()으로 선택한 곳 클릭>
btn = driver.find_element(By.XPATH, '//*[@id="search_btn"]')
btn.click() # 클릭 칸의 XPATH를 찾고 저장, .click하면 그 버튼이 클릭된다<로그인이 필요한 경우 send_keys를 이용하여 ID, PW입력 후 click()으로 로그인 가능>
# ID와 비밀번호 입력
ID = input('ID: ')
PW = input('PW: ')
# ID
driver.find_element('xpath', '//*[@id="loginForm"]/div/div[1]/div/label/input').send_keys(ID)
# 비밀번호
driver.find_element('xpath', '//*[@id="loginForm"]/div/div[2]/div/label/input').send_keys(PW)
# 로그인 확인 버튼 클릭
driver.find_element('xpath', '//*[@id="loginForm"]/div/div[3]/button').click()<이미지 URL 찾고 저장>
# 이미지 URL 찾기
img_url = soup.find('img', attrs = {'class' : "x5yr21d xu96u03 x10l6tqk x13vifvy x87ps6o xh8yej3"}).get('src')
print(img_url)
# 폴더에 사진 저장하기
urlretrieve(img_url, filename='C:/Users/coul6/Desktop/성윤/Instagram/' + keyword + '.jpg')<인스타그램 스크롤 내리면서 이미지 URL 저장 후 이미지 수집>
# 스크롤 다운 방법
body = driver.find_element('css selector', 'body')
body.send_keys(Keys.END)
# 스크롤 5번 내리기
for rep in range(5):
body.send_keys(Keys.END)
time.sleep(1)
# 이미지 URL 찾기
img_list = soup.find_all('img', attrs = {'class' : "x5yr21d xu96u03 x10l6tqk x13vifvy x87ps6o xh8yej3"})
print(img_list)
# 이미지 URL 리스트에서 이미지 URL만 가지고 오기
img_url_list = []
for img in img_list:
img_url = img.get('src')
img_url_list.append(img_url)
print(len(img_url_list), '개의 사진을 수집하였습니다.')
# 폴더에 사진 저장하기
n=1
for img_url in img_url_list:
urlretrieve(img_url, filename='C:/Users/coul6/Desktop/성윤/Instagram/' + keyword + str(n) +'.jpg')
time.sleep(1)
n += 1
