주의 메커니즘을 기반으로 특징 표현력을 강화하기 위한 새로운 주의 방법을 제안
Transformer를 도입하여 후보 프레임을 정제하고, 동적 합성곱을 사용하여 백본 네트워크를 수정
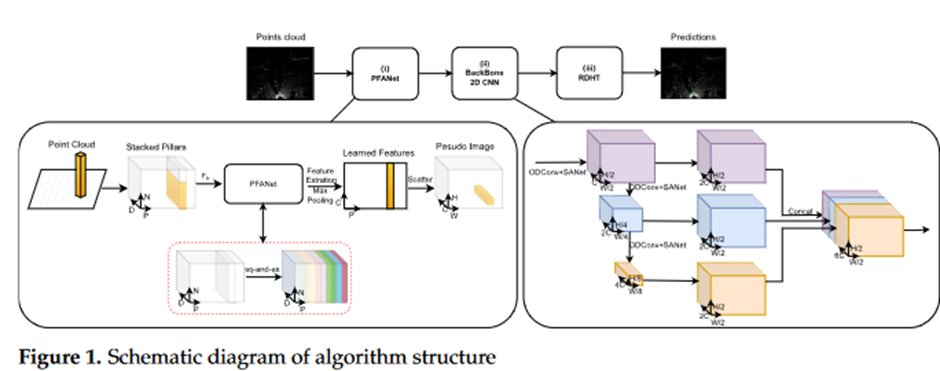
- Pillar Feature Attention Net (PFANet)
- Backbone (2D CNN)
- Redefined Detection Head based on Transform (RDHT)
1.논문에서 얘기하는 핵심이 무엇인지?
LiDAR는 레이저 광선을 사용하여 주변 환경을 스캔하고, 그 결과를 포인트 클라우드라는 형태로 데이터만드는데, 이 데이터는 복잡하고 정돈되지 않은 형태를 가지고 있어 처리하기 어려움
따라서 그리드 기반 방법을 이용하여 포인트 클라우드 데이터를 격자 모양의 상자(보셀)로 나누어 처리하여 2D 이미지 처리 기술을 사용할 수 있어 빠르고 효율적으로 데이터 처리를 함
- 논문의 장점이 무엇인지?
1) 그리드 기반 방법 중 하나인 PointPillars 모델을 사용, 포인트 클라우드데이터를 직접 처리하고, 특징을 추출하여 매우 빠르게 동작하지만 작은 물체를 잘 감지 못하는 단점이 있음
→ 이를 보완하기 위한 특징 추출 과정에서 주의 집중 메커니즘을 사용하여 작은 물체에 더 많은 관심을 기울이도록 함(2D 이미지 처리 기술을 최적화 하여 성능 높임), Transformer 기술을 사용하여 물체 감지 결과 정확도 향상됨
2) Point Featured Attention Net (PFANet)을 제안하며 여기에는 Squeeze-and-Excitation Networks를 도입하여 정보가 많은 특징을 선택적으로 강조하고 덜 유용한 특징을 억제할 수 있게 학습하여 각 D차원 특징을 처리하여 특징의 표현을 개선함
Squeeze 단계에서 합성곱 층의 출력 특징 맵을 글로벌 평균 풀링 작업을 통해 특징 벡터로 압축
Excitation 단계에서 완전 연결 층과 비선형 활성화 함수를 사용하여 채널의 가중치 벡터를 생성하는 방법을 학습(가중치 벡터는 원래 특징 맵의 각 채널에 적용되어 다른 채널의 특징을 가중치로 부여) → 채널 간의 종속성을 포착하게 됨
3) 백본에서 다운샘플링단계에서 작은 대상물에 대한 감지능력을 향상→ SA-Net (Spatial Attention Network)를 도입하여 작은 대상물 감지하기 위한 특징 추출 능력을 강화(심층 학습 네트워크)
ODConv (Potimized Dynamic Convolution) 합성곱의 신경망의 표현력을 향상시키기 위한 기술 → 매개변수를 동적으로 조정하여 다양한 특징과 맥락 정보에 적응, 특히 얕은 층에서 특징 표현을 크게 풍부하게 만들고 정제
이 두가지로 계산 효율성 또한 올라가고 작은 대상물과 복잡한 장면에 대한 감지 네트워크의 적응성을 향상시킴
- 논문 내용에서 의문사항
1) A-Net과 ODConv를 도입하여 이 문제를 해결했을때, 이러한 개선 기법들이 어떤 구체적인 한계나 단점을 가지고 있지는 않는지??
2) 각 포인트에 효과적인 제안-포인트 임베딩 접근 방식을 통해 인코딩을 하고 자기-주의 메커니즘을 사용하여 포인트 간의 원격 상호 작용을 포착한다는데, 인코딩과 디코딩 과정에서 해당 방법의 효과가 얼마나 큰지??
→ 실험결과에서 향상을 보여줌
3) Decoder 모듈에서 M개의 query 임베딩을 사용하지 않고 오직 하나의 예측만 요구하는 이유가 무엇인지? 표준 Transformer Decoder와의 차이점이 무엇인지?
3.Questions about the paper's content:
1) When introducing the A-Net and ODConv, what specific limitations or drawbacks do these improvement techniques have?
2) The paper uses an effective proposal-point embedding approach to encode and uses a self-attention mechanism to capture remote interactions between points, but how effective is this method in the encoding and decoding process?
→ The experimental results show improvements.
3) Why does the Decoder module use only one prediction and not M query embeddings, and what is the difference from the standard Transformer Decoder?
- 논문 내용에서의 한계점 또는 단점이라고 생각되는 것들
1) 전체적인 검출 정확도는 향상되었으나, 보행자와 자전거를 종종 잘못 분류하며, 환경 잡음이 자전거와 보행자로 오해하기 쉬움
2) 제안된 Redefined Detection Head 기법이 Transformer 기반으로 설계되어 있는데, Transformer 모델의 복잡성으로 인해 계산 비용이 증가할 수 있다는 점. 특히 3D 객체 탐지 작업에서는 점군 데이터 처리에 많은 계산 자원이 필요하므로, 이에 대한 고려가 필요해보임
3) Feed Forward 레이어에 대한 설명은 간단하지만, 실제로 이 레이어가 어떤 역할을 하는지, 그리고 다른 구성 요소들과 어떻게 상호작용하는지에 대한 설명이 더 필요하지 않을지?
