
개요
코사인 유사도는 특히 결과값이 [0,1]의 범위로 떨어지는 양수 공간에서 사용된다.(from 위키피디아)

특징
계산된 유사도는 −1 ~ 1 사이의 값을 가진다.
- −1은 서로 완전히 반대되는 경우
- 0은 서로 독립적인 경우
- 1은 서로 완전히 같은 경우를 의미한다.
성능이 좋지 못할 때
상호 상관관계를 가지는 feature
(키, 몸무게 등)를 갖는 원소들간의 유사도를 계산할때에 좋지 못하다.
더 자세한 설명은 Euclidean vs. Cosine Distance 에서 확인할 수 있다.
성능을 발휘할 때
코사인 유사도는 다양한 차원에도 적용이 가능하여,
다차원의 양수 공간에서의 유사도 측정에 자주 이용된다고 한다.
다른 많은 유사도 알고리즘에서도 측정 가능하지만, 특별히코사인유사도가 강점을 가지는 부분을 이해해보자
코사인 유사도는 벡터의 규모(크기)가 중요하지 않을때 사용된다.라고 한다.
이 말을 풀어보면
✔︎ 각 차원의 벡터값이 존재할때, 그 값의 크고 작음은 중요하지 않다.(~=결과에 크게 영향을 미치지 않는다)
✔︎ 차원의 값이 존재하는것 자체가 유사도 계산에 중요한 영향을 미친다.(로도 생각해볼 수 있다)
✔︎ 다양한 차원이 존재할때 유사도를 구분이 뚜렷할 수 있다.실험1 : 특징 이해하기
코사인 유사도의 성능을 발휘할 때의 특징을 단어의 갯수를 feature로 사용하는 문서 유사도 측정 실험을 통해 이해해보자.
이해를 돕기위해 2차원에서 삼각함수의 cos함수 정의 방식으로 계산하도록 한다.
sin, cos 공식은 기억나시죠? wikipedia:삼각함수 정의
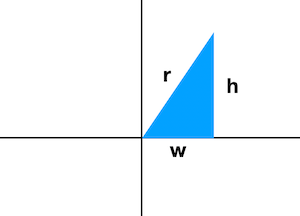
✔︎ 전제조건 : 2개의 단어만을 가지고 유사도 계산을 진행한다.
w = '아이유' 단어 갯수
h = '콘서트' 단어 갯수
r = O 에서 (w,h)까지의 거리✔︎ r 은 피타고라스 정리를 통해 계산이 가능하다
r² = w²+h²
r = √(w²+h²)
✔︎ 응용하여 cos 값을 계산해본다.
cos(Θ) = w/r = w / √(w²+h²)실험1 값 변화량

콘서트 단어의 수가 많아질수록 끼치는 영향이 크지 않음을 알 수 있다
'아이유' 단어의 갯수가 동일하다는 가정과 함께 '콘서트' 단어가 코사인 값에 영향을 끼치는 결과는 그림처럼 클수록 영향력이 작아지게 된다.결론
코사인 유사도는 다음의 특징을 가진다는것을 다시한번 확인할 수 있다.
✔︎ 차원의 벡터값이 영향을 끼치는 정도는 작은편
✔︎ 벡터값이 조금이라도 존재하는지가 결과값에 크게 영향을 끼친다실험2 : 3차원 이상의 코사인 유사도 계산
실험을 통해 코사인 유사도의 특징을 파악했으니, 실제 예제 문서간의 유사도 파악을 실험해보자
# Python3
doc_a = "청하가 아이유 손편지"
doc_b = "가수 청하가 선배 가수 아이유"
doc_a.split(" ")
# ['청하가', '아이유', '손편지']
# {'청하가': 1, '아이유': 1, '손편지': 1}
doc_b.split(" ")
# ['가수', '청하가', '선배', '가수', '아이유']
# term & count
# {'가수': 2, '청하가': 1, '선배': 1, '아이유': 1}doc_a와 doc_b가 가지는 단어들을 확인할 수 있다.
이제 두 문서간의 cos 유사도를 계산해보자.
공식
분자 계산(A*B)
| A(doc_a) | B(doc_b) | A*B | |
|---|---|---|---|
| 청하가 | 1 | 1 | 1*1 |
| 아이유 | 1 | 1 | 1*1 |
| 손편지 | 1 | 0 | 1*0 |
| 가수 | 0 | 2 | 0*2 |
| 선배 | 0 | 1 | 0*1 |
A*B = (1*1)+(1*1)+(1*0)+(0*2)+(0*1)
= 2분모 계산 (||A||*||B||)
(√ΣA^2) * (√ΣB^2) = √(1+1+1+0+0) * √(1+1+0+4+1)
= √3 * √7 = √21최종 A와 B의 유사도
2 / √21 = 0.436435780471985더 나아가서
지금까지 살펴본 코사인 유사도의 완성도를 크게 떨어뜨리는 단점중 하나는 단어와 단어 사이의 유사도는 알 수 없다는 점이다.
ex)
✔︎ 가수 & 싱어
✔︎ 왕 & 왕자
✔︎ 개울 & 호수
✔︎ play & game이를 해결하기 위한 코사인 측정방법인 Soft Cosine Measure가 있다.
보다 좋고 최신의 해결책도 많지만 코사인 유사도 내에서 해결하는 방식이라는 점에서 소개한다.
참조
