목표🥰
웹 링크로부터 html 문서를 추출하는 request 라이브러리의 한계를 극복하는 또 하나의 crawling library, Selenium에 대하여 알아봅시다.
request 라이브러리 한계
- 로그인이 필요한 사이트의 경우, 크롤링이 어려움
- 동적으로(dynamic) HTML이 설계되어 있는 경우
ex)- url은 그대로인데 + 버튼이나 스크롤을 통해서 또 다른 UI 부분이 생성되는 경우
- 특정 부분만 바뀌도록 설계되어 있는 경우
동적 HTML 예시
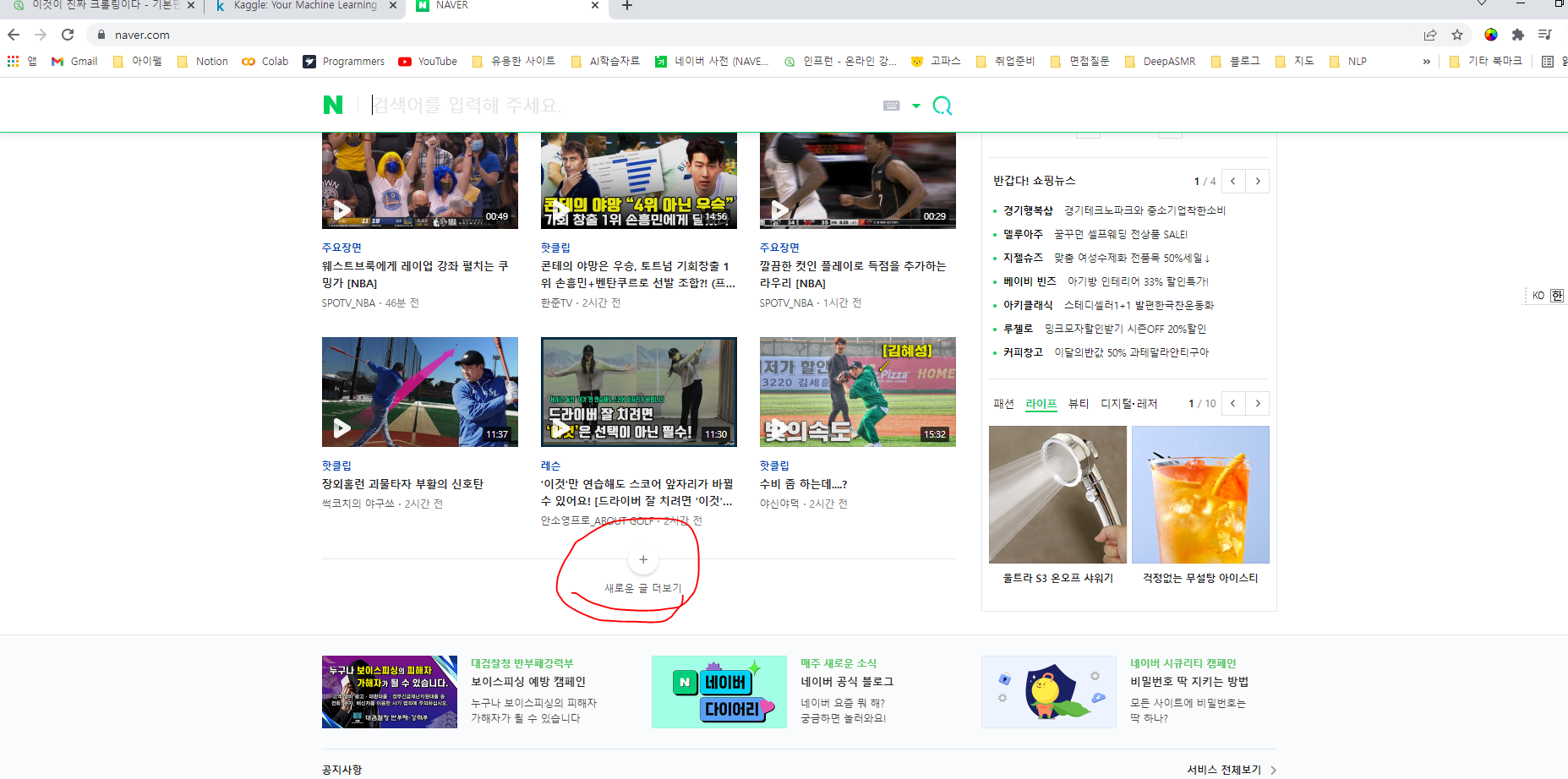
[새로운 글 더보기 부분을 request 라이브러리로는 크롤링하기 쉽지 않다(클릭해도 url은 같기 때문)]
Selenium
- 웹 어플리케이션 테스트를 위한 도구
- 브라우저를 실제로 띄워서 사람처럼 동작하도록 만들 수 있음
기초 사용법
- 크롬 드라이버 다운로드
- 라이브러리 설치
pip install selenium
무한 스크롤 처리 방법
while True:
# 맨 아래로 스크롤 내림 (html의 body마다 멈춤)
# css 선택자로 body 선택하고 키보드의 end 키 클릭
browser.find_element_by_css_selector("body").send_keys(Keys.END)
# 스크롤 사이 페이지 로딩 시간
time.sleep(1)
# 스크롤 후 높이
after_h = browser.execute_script("return window.scrollY")
if after_h == before_h:
break
before_h = after_hcsv 파일로 저장하는 법
with open(r"C:\Users\crosstar\OneDrive - 고려대학교\Desktop\practice_crosstar\practice-crawling\selenium_shopping_crawling\data.csv", 'w', encoding='CP949', newline='') as f:
csvWriter = csv.writer(f)
items = browser.find_elements_by_css_selector("div.basicList_info_area__17Xyo")
for item in items:
# class = basicList_link__1MaTN
name = item.find_element_by_css_selector(".basicList_link__1MaTN").text
#class = price_num__2WUXn
try:
price = item.find_element_by_css_selector(".price_num__2WUXn").text
except:
"판매 중단"
# price = item.find_element_by_css_selector(".basicList_price_area__1UXXR")
# 태그에 해당하는 정보가 어떤 식으로 나와있는지에 유의!
link = item.find_element_by_css_selector(".basicList_link__1MaTN").get_attribute("href")
print(name, price, link)
csvWriter.writerow([name, price, link])
romantic ai developer