내가 원하는 태그를 선택할 수 있게 해주는 beautifulsoup 라이브러리에 대해 알아봅시다. 우선 아래 명령어로 설치부터 해볼까요?
pip install beautifulsoup4
번역된 객체! = Beautifulsoup(html코드, html 번역선생님)

html 코드 + 번역선생님 = 아름다운 수프 탄생!
import requests
from bs4 import BeautifulSoup
# 요청을 통해 response 받음
response = requests.get("https://www.naver.com/")
# naver에서 html 줌
html = response.text
# 수프 완성!
soup = BeautifulSoup(html, 'html.parser') # html, parser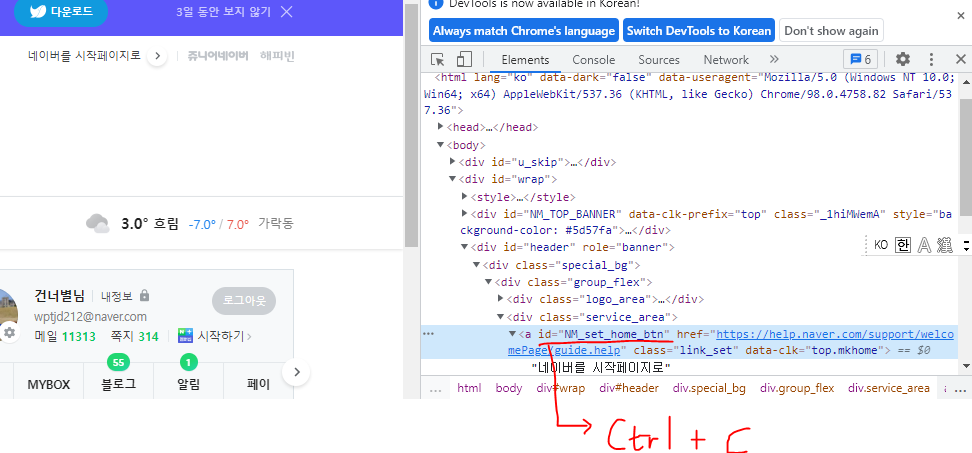
# 수프로부터 하나 골라서
word = soup.select_one('#NM_set_home_btn') # '네이버를 시작페이지로' 내용의 id를 입력하였음 +(#은 CSS 입력자)
# 텍스트로 출력
print(word.text)
>>> 네이버를 시작페이지로!Beautifulsoup 인스턴스의 메소드☺
- soup.select(선택자) : 여러개 가져옴
- soup.select_one(선택자) : 하나만 가져옴
** 파싱 : 어떤 페이지(문서, html 등)에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것
** span : SPAN 태그는 "Inline Text Container (문장 단위로 텍스트 영역을 지정하는 것)"인데, 그 자체로는 아무 역할도 하지 않고, 문장의 특정 구역에 CSS스타일을 지정할 때 사용함

romantic ai developer