Kernel
복잡한 nonlinear classifier를 위한 핵심 기술, kernel에 대하여 공부해 봅시다!
kernel이란?
Kernel은 결국 두 벡터의 내적(inner product)이며, 기하학적으로 cosine 유사도를 의미하기 때문에 Similarity function 이라고도 불린다

비선형 결정 경계를 고르는 데에 , 등의 feature를 선택해야 하는데, 그 방법으로서 더 나은 방법이 있을까?
input 가 주어졌을 때, landmark ,, 와의 근접성에 따라 새로운 feature를 계산해 보자.
(Gaussian) Kernel Function
=
similarity function 을 kernel function이라고 하고,특히 exp있는 뒤쪽의 함수는 gaussian kernel function임.
x 가 landmark와 가깝다 :
x 가 landmark와 멀다 :
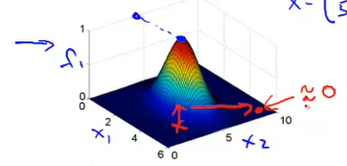 가운데 있으면 1, 멀리 있으면 0
가운데 있으면 1, 멀리 있으면 0
sigma가 커지면 -> 더 옆으로 퍼진 형태
sigma 작아지면 -> 더 좁아진 형태
가 1로 주어져 있을때, binary nonlinear classifier의 예시를 아래와 같이 확인해 봅시다.

결과적으로 decision boundary는 인접한 근처에서 그림과 같이 형성되게 됩니다.
SVM with Kernels
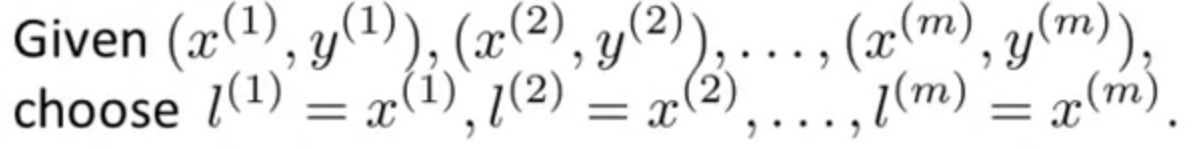
training example과 같은 위치에 landmark를 설정하여 보겠습니다.
그렇다면 우리가 이전에 배운 SVM에 따라 아래와 같이 표현을 할 수 있습니다.
참고할 점은 가 로 대체되었고,
regularization이 m개의 feature에 관하여 시그마 연산이 진행됩니다.

SVM overfitting 조정하기!
bias VS variance tradeoff관계를, hyperparameter C 와 sigma로 조정할 수 있습니다!
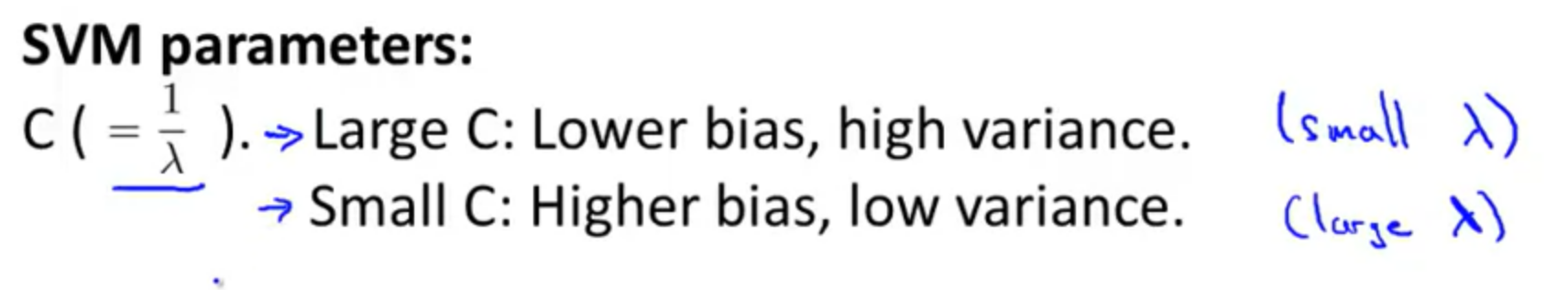
Larger C : to overfitting
Smaller C : to underfitting

larger : to underfitting
smaller : to overfitting
