ML
1.SVM에서 Kernel이란?
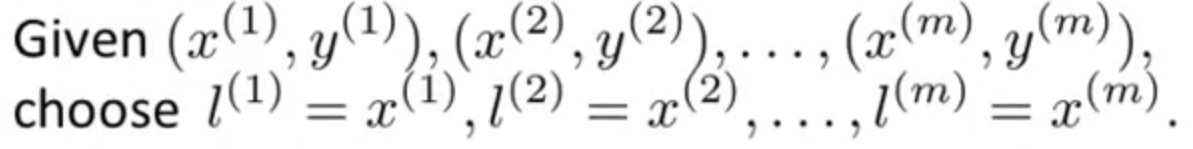
Kernel 복잡한 nonlinear classifier를 위한 핵심 기술, kernel에 대하여 공부해 봅시다! 비선형 결정 경계를 고르는 데에 $$f1$$, $$f2$$ 등의 feature를 선택해야 하는데, 그 방법으로서 더 나은 방법이 있을까? > inp
2.Using an SVM

liblinear, libsvm 등의 패키지를 이용하여 SVM 을 실제 코드에 적용시켜 볼 수 있습니다!특정해야 하는 부분은,1) parameter C를 고르고,2) kernel을 골라야 합니다.대표적인 예시로 gaussian kernel을 들어 설명해보겠습니다.아래는
3.[머신러닝]차원축소(PCA,t-SNE)
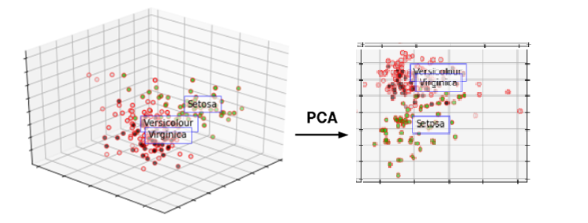
비지도학습의 일종으로, 많은 feature로 구성된 다차원 데이터 세트의 차원을 축소해 새로운 차원의 데이터 세트를 생성하는 것메모리 효율화 및 데이터 시각화에 매우 유용PCA, t-SNE 등이 있음출처:https://steemit.com/steempress/
4.[머신러닝]이상치 탐지(Anomaly Detection)
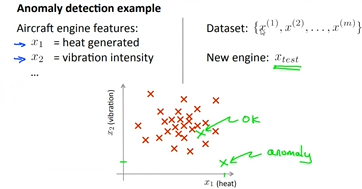
멀리 떨어진 애가 이상치.likelihoodGaussian Distribution을 가정하고,Threshold 기준으로, 멀리 떨어진 애개 여기서 나왔을 가능도가 낮다.우리는 sample로부터 parameter를 추출하고 싶습니다.likelihood 측정을 통해 이상치
5.[ML]Collaborative Filtering(추천시스템)
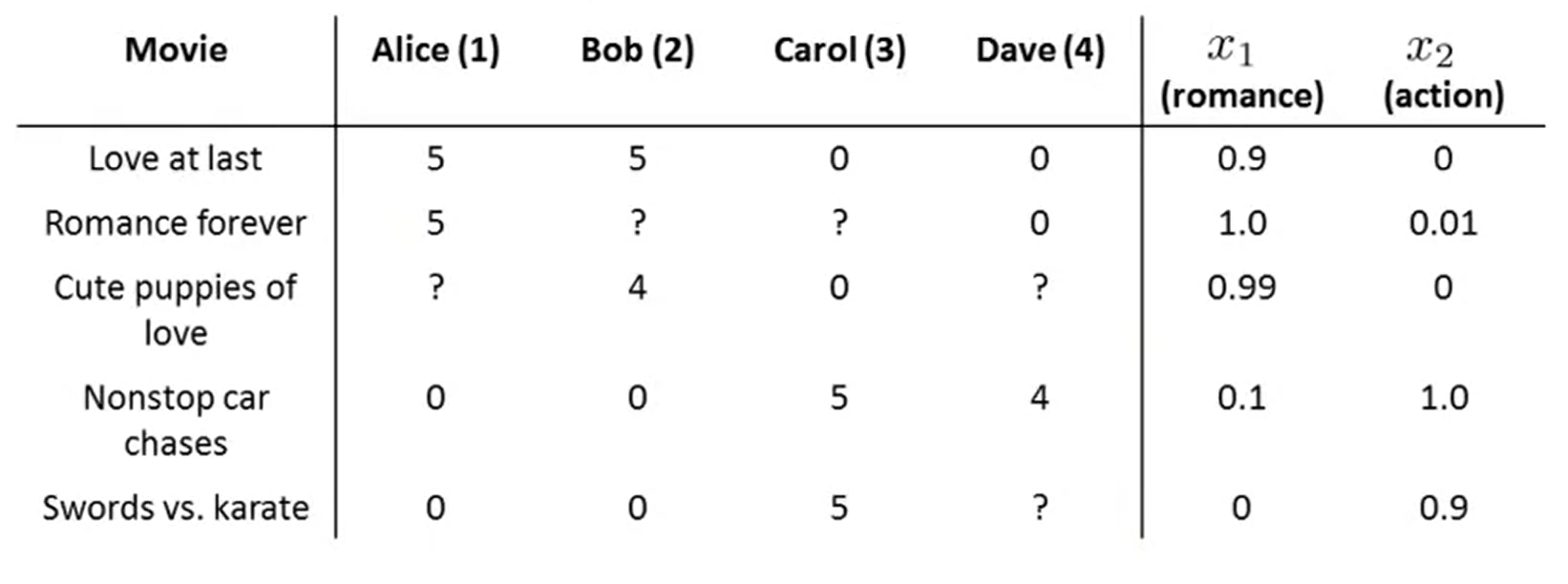
content based filtering과 달리, 많은 사용자들로부터 얻은 기호정보에 따라 사용자들의 관심사들을 자동적으로 예측하게 해주는 방법본 강의에서는 Collaborative filtering의 특성인 feature를 자동으로 학습하는 알고리즘에 대해 설명합니
6.[ML]Gaussian Mixture Model
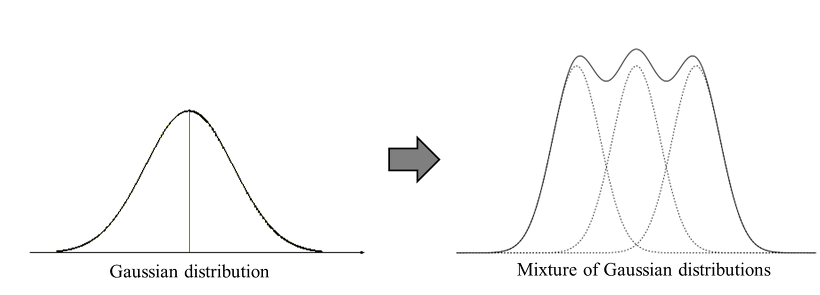
https://untitledtblog.tistory.com/133Gaussian 분포가 여러 개 혼합된 clustering algorithm정규분포를 가정하고, data로부터 여러 정규분포를 혼합한 확률 모형을 찾는 과정그림 1과 같이 K개의 Gaussian
7.[ML]Gradient Descent 의 세 종류(Batch, Stochastic, Mini-Batch)
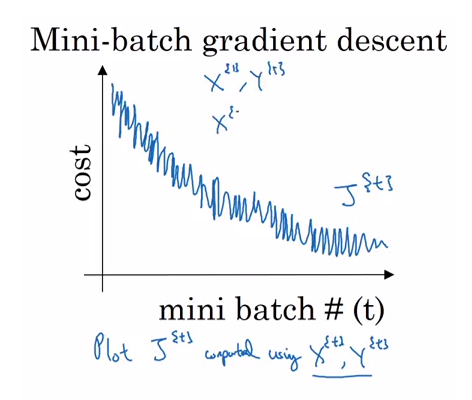
https://light-tree.tistory.com/133전체 학습 데이터의 gradient를 평균내어 GD의 매번의 step마다 적용데이터셋이 매우 큰경우, 매번 전체 학습 데이터를 연산하는 것은 메모리 사용량이 늘어나는 일임하나의 데이터를 골라 인공신경
8.[ML]Overfitting and Regularization
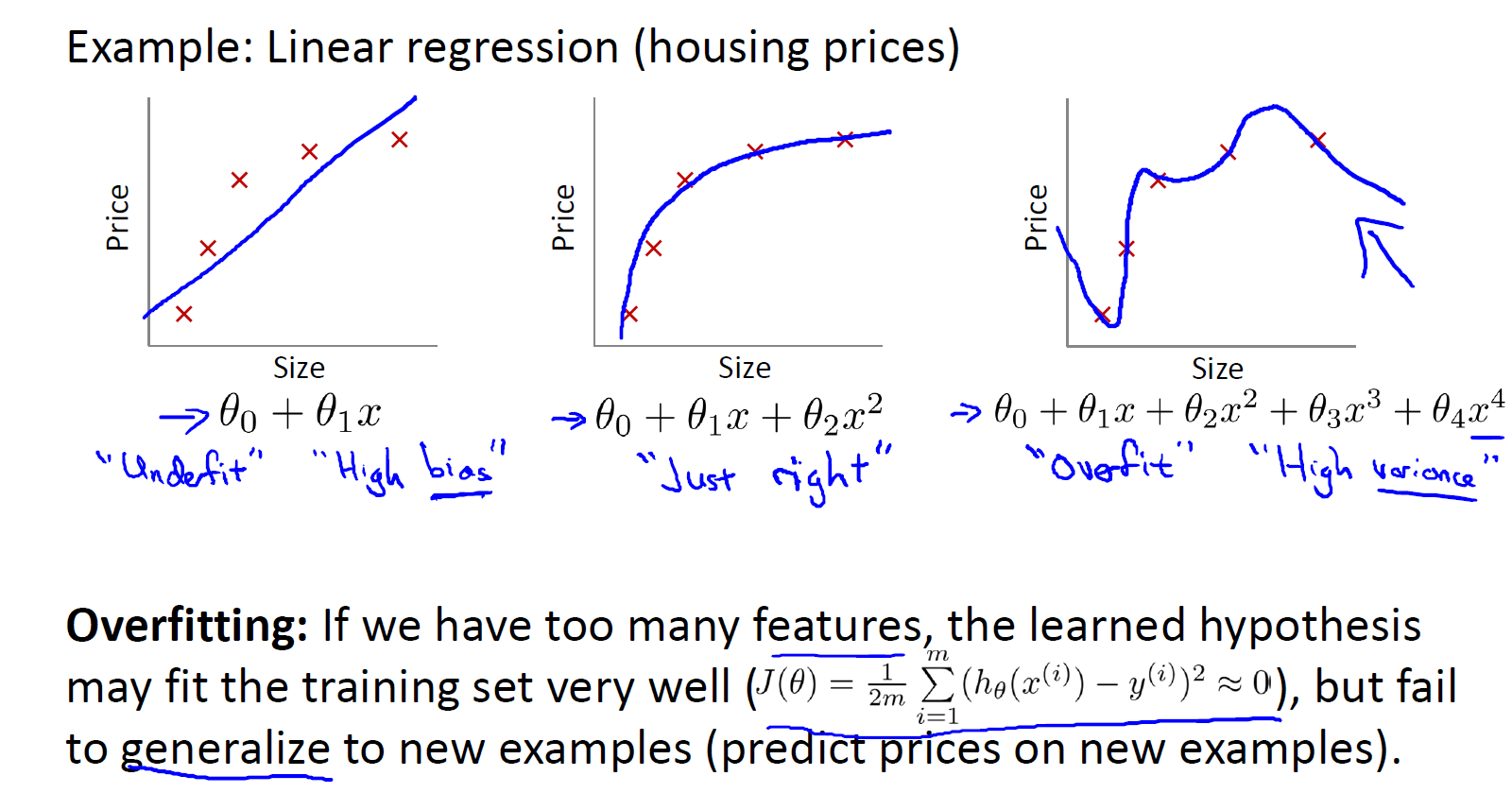
과적합. 모델이 training set을 과하게 학습하여 융통성이 없는 상태. testset에 대한 일반화가 안됨!feature가 과도하게 많을 때 일어나는게 일반적특정 알고리즘 적용직접 사라질 feature 선택feature 수를 줄이지 않고, 각 feautre($$
9.[ML]Batch Normalization
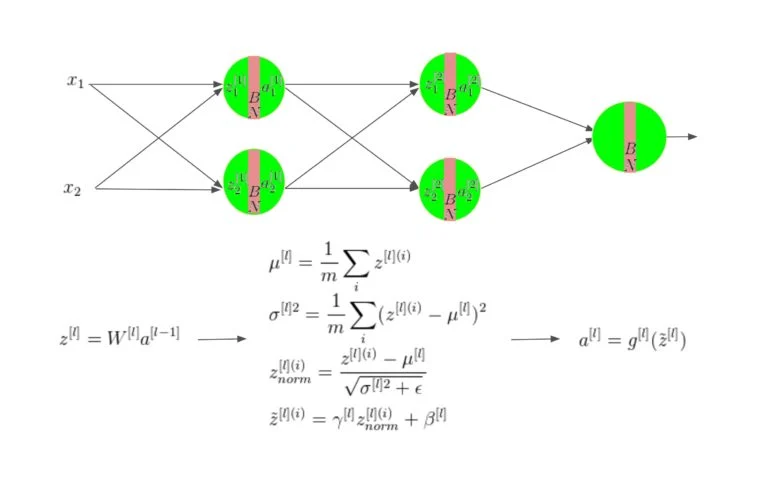
batch 단위로 학습을 진행하니, 각 batch 별 분포 차이가 큼.(Covariance값)1) dataset을 minibatch(묶음)으로 나눔2) minibatch 평균 $$\\mu_b$$, 분산 $$\\sigma_b^2$$값을 구하고3) 평균 0, 분산 1 인
10.[tensorflow]tf.data.Dataset 클래스 파헤치기

Reference https://youtu.be/NUMzrqxQ4zk tf.data.Dataset 클래스 batch 구성 전처리 함수 매핑 shuffle window 데이터셋 구성 prefetch 옵션 등 데이터 파이프라인 구축에 매우 유용한 클래스! tf.dat
11.[Tensorflow] 오디오 데이터 전처리하기1(librosa, fft, log- melspectrogram)
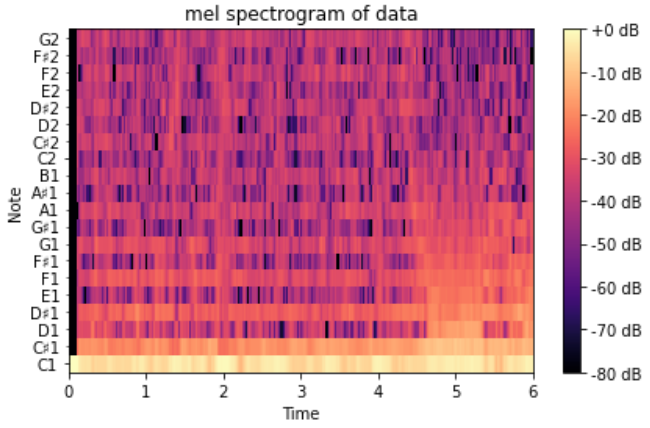
Reference https://ichi.pro/ko/tensorflowleul-sayonghayeo-gpueseo-odioleul-swibge-cheolihaneun-bangbeob-50154769354502 https://towardsdatascience.com
12.[ML]머신러닝 평가지표 뜯어보기(confusion matrix,P-R curve, ROC-AUC..)
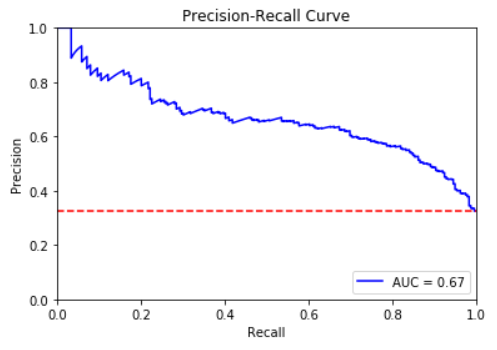
P-R 곡선 ROC curve(Receiver Opreating Characteristic Curve) 직역하면 수신자 조작 곡선 군사 영역에서 유래된 개념 나중에는 의학 영역에서 발전 > - Classification Model에서 분석 Metric! 가로축은
13.[ML]cosine similarity VS euclidean distance (+ KL divergence)
머신러닝의 데이터의 특성은 대부분이 벡터의 형태로 표현됩니다. 이러한 벡터 간의 거리를 측정하는 방법론에 대해 고찰하여 봅시다. 가까우면 유사도가 높다, 멀면 유사도가 낮다고 판단할 수 있겠다는 점은 직관적으로 판단 가능하겠죠?$$cos(A,B) = \\frac {A\
14.[머신러닝]모델 평가 방법(Holdout, k-fold validation, bootstrap)
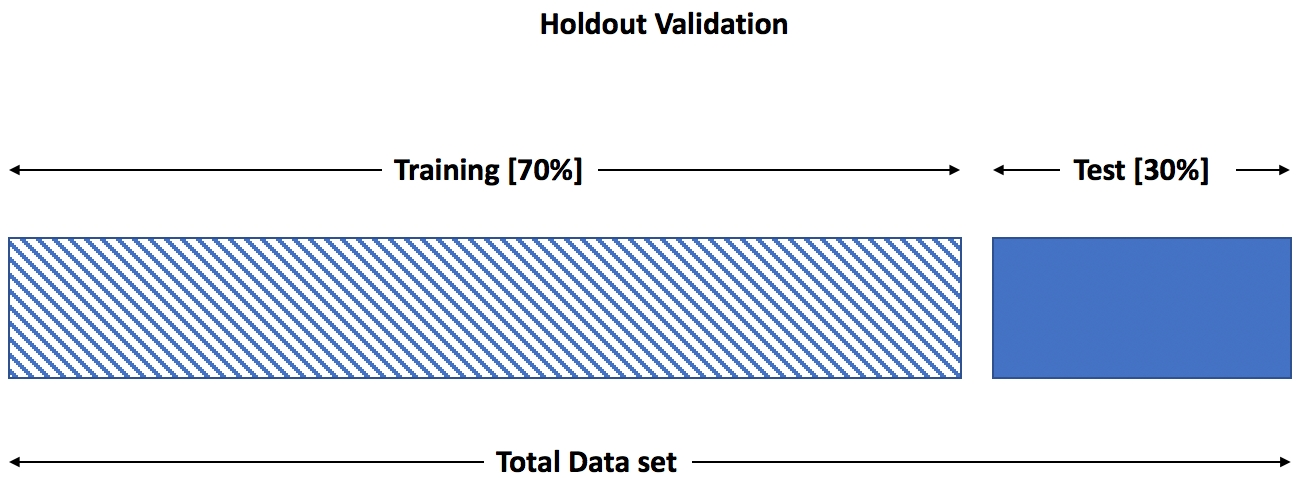
trainset / testset 은 각각 model training과 evaluation에 활용됩니다.https://subscription.packtpub.com/book/data/9781838556334/7/ch07lvl1sec85/holdout-appro
15.[ML]Scikit-learn VS Tensorflow
머신러닝 학습 알고리즘 및 모델이 탄탄하게 구현되어 있음예제와 사용 설명서가 잘 되어있음Regression, Clustering, Model Selection, preprocessing에 특화되어 있음딥러닝이나 강화학습을 다루지 않음그래픽 모델이나 시퀀스 예측 기능을
16.[ML]Logistic Regression(로지스틱 회귀), Softmax function, Cross entropy 정리

logit(log odds) 의 개념으로부터 나옴Linear regression의 hypothesis function에 sigmoid function을 적용한 것으로, 이진분류 문제에 이용됨결과는 확률값으로 매핑됨multivariate linear regression(
17.[ML]PCA(Principal Component Analysis)
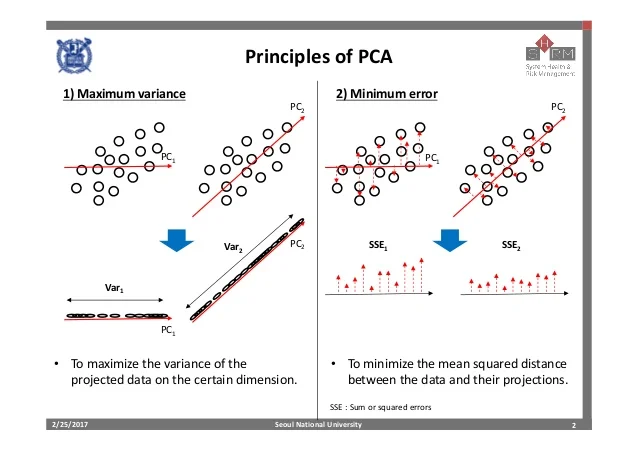
모델이 사용되는 문제(도메인)Clustering, Dimensionality Reduction, Visualization, Noise Reductionlabel이 없는 상태에서 데이터의 경향성을 분석하거나 데이터 간 Colinearity를 제거하는 데에 이용됩니다. 모
18.[딥러닝]python으로 CNN 컨볼루션 구현하기
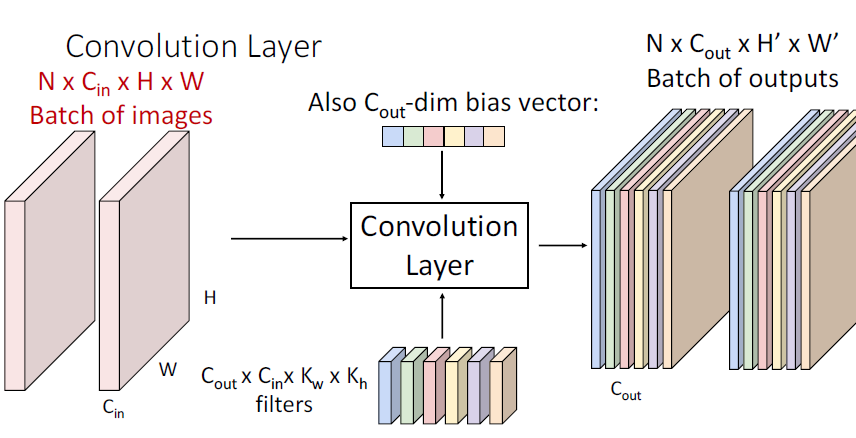
CS231 2020 Lecture note 7CNN에서 N개의 batch에 대하여input image x.shape : $$C\_{in}$$\*$$H$$ \* $$W$$ filter.shape : $$C{out}$$\*$$C{in}$$\*$$K_w$$\*$$K_h
19.[ML]최적화 알고리즘 2가지(optimization algorithm)
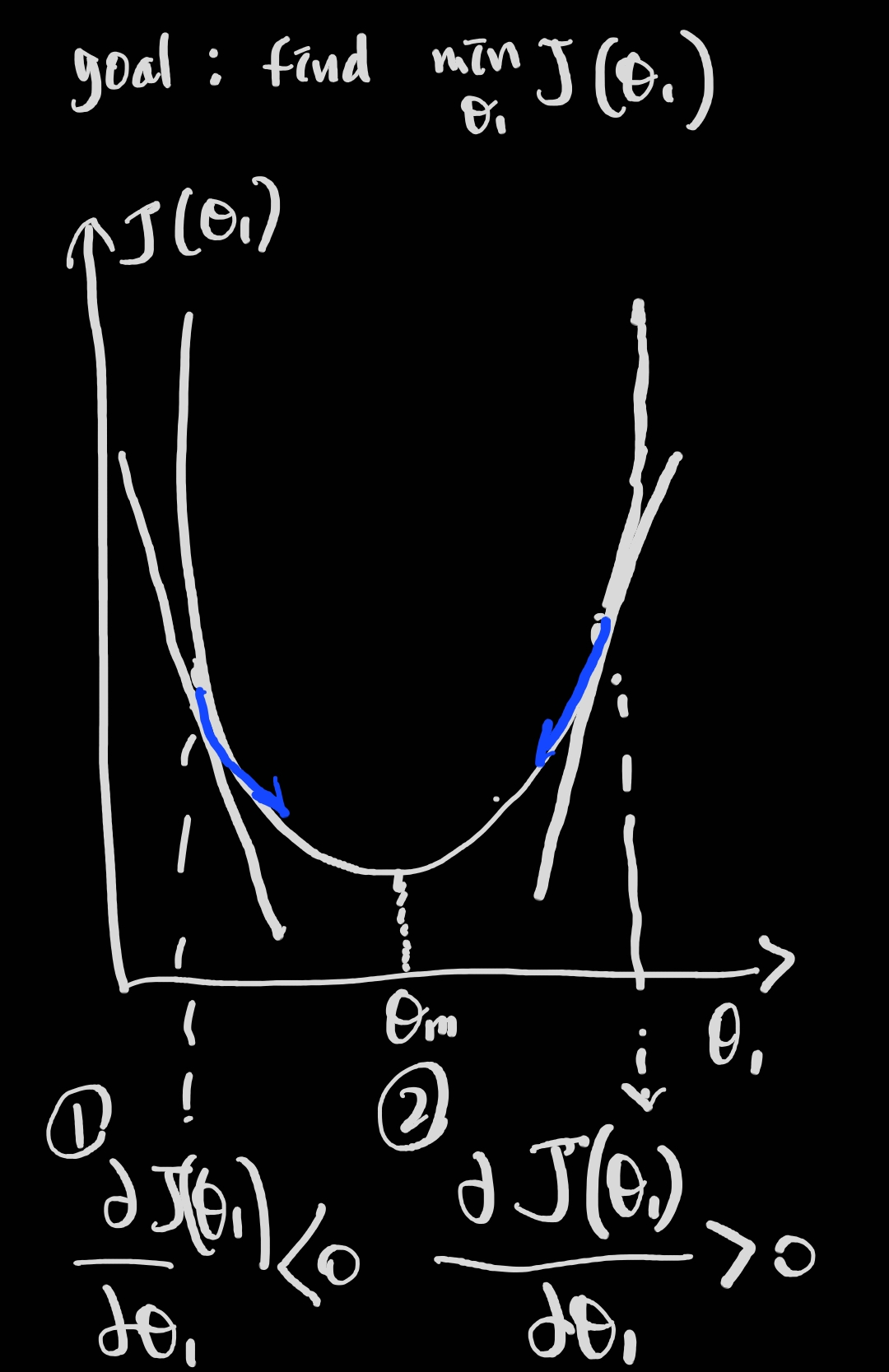
parameter를 측정하는 데에는 크게 두 가지 방법이 있습니다. 1) gradient descent로 iteration을 통해 최적화하는 방법과, 2) Normal equation을 통해 최적해를 결정적으로 구하는 방법입니다. 모델을 가설 함수에 기반하여 Loss
20.[ML]내가 생각하는 머신러닝의 정의
데이터 기반 의사결정에 도움을 주는 하나의 방법론. 모델을 설계하고 패턴을 학습(train)시키며 평가(evaluate)함. 이때 특정 평가지표(metric)를 기반으로 정량적으로 최적화(optimize)하여 보다 올바른 예측(predict)이 가능하게 함.
21.[딥러닝]Vanshing Gradient Problem과 해결하는 여러가지 방법(BN, init, ReLU, Residual Network)
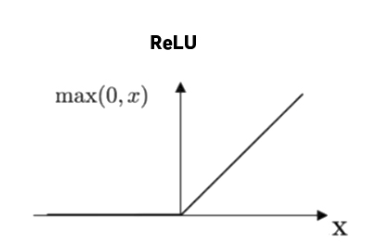
딥러닝에서 parameter를 update하는 데에 핵심적인 역할을 하는 gradient값이 소실되어 학습이 제대로 이루어지지 않는 현상반대로 exploding gradient가 있음vanishing gradient in RNNactivation function : 예