📌Hyperparameter란?
- 엔지니어가 직접 설정해 주어야 하는 변수값
- 값을 어떻게 설정하느냐에 따라 모델의 성능을 개선시킬 수도, 저하시킬 수도 있음
Hyperparameter Tuning 세 가지 요소🥰
- Objective Function : 최대화(점수)하거나 최소화(Loss, Cost)해야 하는 값
- Search Boundary : 탐색 범위 설정
- Step : 탐색 시 간격
- Objective Function을 optimize 하는 방향으로 범위 및 간격을 설정
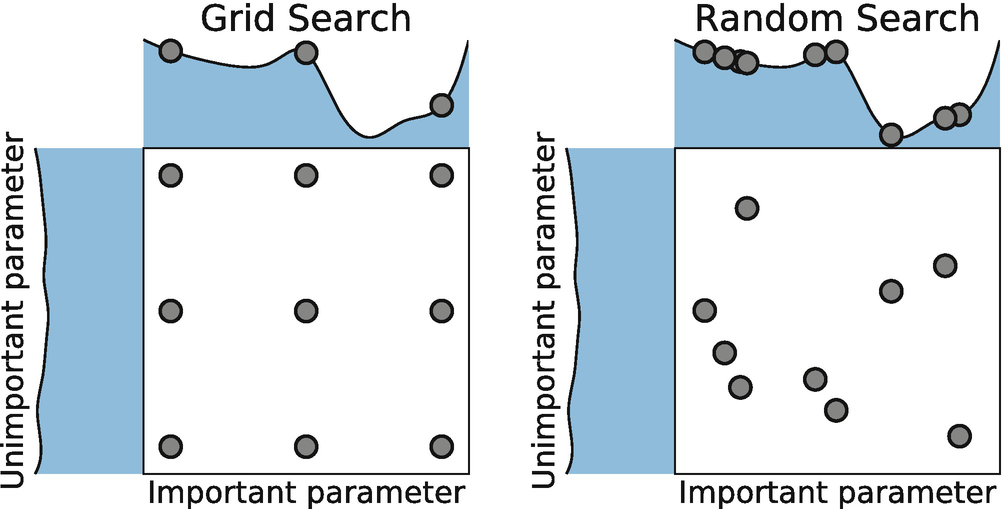
[Image Source: Bergstra, J., Bengio, Y.: Random search for hyper-parameter optimization. Journal of Machine Learning Research 13, 281–305 (2012)]
📌GridSearch
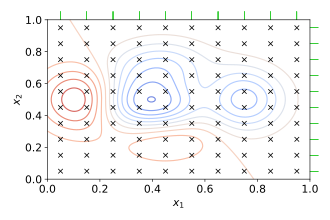
- 간단하고 광범위하게 사용되는 hyperparameter 탐색 알고리즘
- 해당 범위 및 Step의 모든 경우의 수를 탐색
- 범위를 넓게 가져갈수록, Step을 작게 설정할 수록 최적해를 찾을 가능성이 높이지지만 시간이 오래 걸림
- 일반적으로 넓은 범위와 큰 Step으로 설정한 후 범위를 좁혀 나가는 방식을 사용하여 시간을 단축
when coding...
- python에서
scikit-learn의GridSerachCV모듈를 통해 구현 가능
parameters
- estimator : 측정에 이용되는 model
- param_grid : gridsearch에 사용되는 search space
- scoring : 성능 측정 metric. 'accuracy', 'roc_auc', 'r2', 'neg_mean_squared_error' 등
(이외의 scoring parameter는 여기 서 확인 - n_jobs : gridsearch 시, multicore processor일 경우 병렬처리할 횟수
- cv : cross-validation 시 fold 수
✒gs = GridSearchCV(~)인스턴스 선언 시
-
gs.best_params_ : 가장 좋은 parameter
-
gs.best_score_ : 그 점수
-
gs.best_estimator_ : 가장 좋은 모델
📌Randomsearch
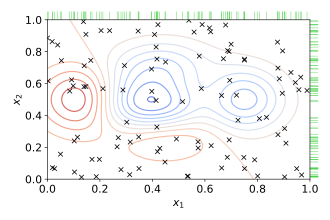
- 정해진 범위 내에서 Random하게 선택
- 기본적으로는 더 빠르고 효율적이기 때문에 GridSearch보다 권장되는 방법
- Grid Serach보다 속도가 빠르지만 optimzed solution이 아닐 수 있음
- Sample의 수가 많다면 Random Sampling을 통해 최적해를 찾을 가능성이 높아짐
when coding...
- python에서
scikit-learn의RandomSearchCV모듈를 통해 구현 가능
parameters(gridsearch와 겹치는 paramter 생략)
- n_iter : random하게 골라지는 hyperpareter 조합의 수를 특정합니다. 값이 10인 경우, size가 10인 hyperparameter 조합을 고려합니다.
- random_state : random 변수 생성 시 seed 값
🤡GridSearch 와 RandomSearch 를 구현한 결과는 여기를 클릭하시면 확인할 수 있습니다.
📌Bayesian Optimization
- GridSearch와 RandomSearch는 각 Search가 종속되어 있지 않음(서로 간 정보를 사용하지 않음)
- 따라서 찾아낸 값이 최적의 값이라고 생각할 수 없음
Bayesian Optimization은...
- "Gausain Process"라는 통계학을 기반으로 만들어진 모델로,
- 여러개의 하이퍼 파라미터들에 대해서,
- "Aqusition Fucntion"을 적용했을 때,
- "가장 큰 값"이 나올 확률이 높은 지점을 찾아냅니다.
목적함수의 '형태'를 학습
- Prior Distribution에 기반하여 하나의 탐색 함수 가정
- Exploartion : 매번 새로운 Sampling을 사용해 목적함수를 Test할 시, 해당 정보를 사용하여 새로운 목적함수의 Prior Distribution을 update
- Exploitation : Posterior distribution에 의해 얻은 global minimum이 나타날 가능성이 높은 위치에서 알고리즘을 테스트합니다.
주의할 점🤡
- 최적해일 가능성이 높은 지점에서 sampling이 계속 일어날 수 있음(exploitation) -> 이 지점이 local minimum이면 거기서 계속 머무르게 되는 것
- 이 때문에 exploration 및 exploitation 사이에 balance point를 찾게 됨
Reference

romantic ai developer