BigData
1.[빅데이터]Spark tool의 실무 적용
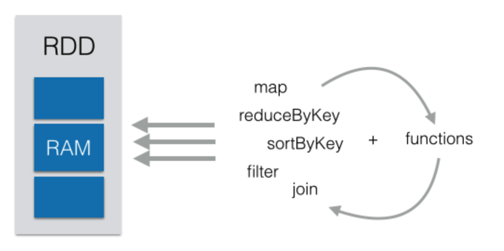
RDD와 Dataframe의 주 데이터 타입하둡과 달리 RAM에서 I/O가 발생하도록 설정 가능: 속도에서 비약적 차이 발생효율적인 처리/분석 가능Transform/Action으로 구분하여 Action일 경우에만 실제 실행이 발생 : 속도 향상Transfrom: fil
2.[빅데이터]Hadoop과 Spark
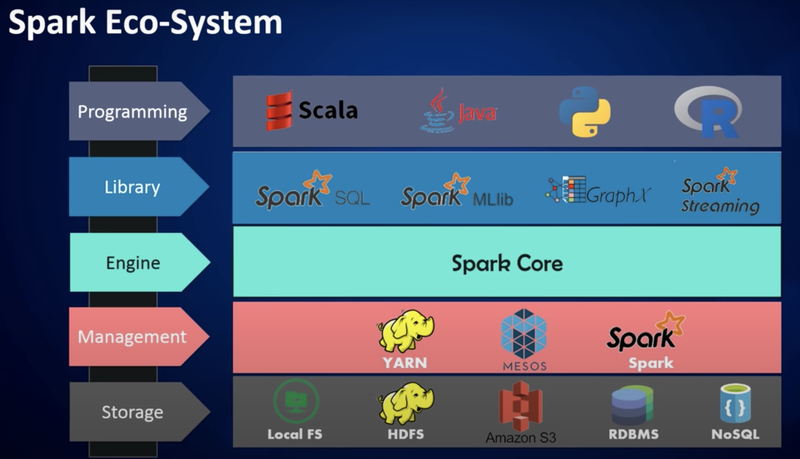
빅데이터 플랫폼 위에 스파크가 적용되는 것이 일반적In-memory 기반의 클러스터 컴퓨팅 데이터 처리 프로그램RDD(Resilient Distributed Dataset)을 구현하기 위한 프로그램in memory 기반의 데이터 처리방식이 real-time분석을 가능하
3.[빅데이터]Spark 모듈과 머신러닝

스파크는 Spark Streaming, SparkSQL, MLlib, GraphX와 같은 모듈을 제공하여 실시간 수집부터 데이터 추출/전처리, 머신러닝 및 그래프 분석까지 하나의 흐름에 가능하도록 개발Spark SQL: Spark Wrapper 함수에 SQL 쿼리를 넣
4.[빅데이터]로그 데이터란?
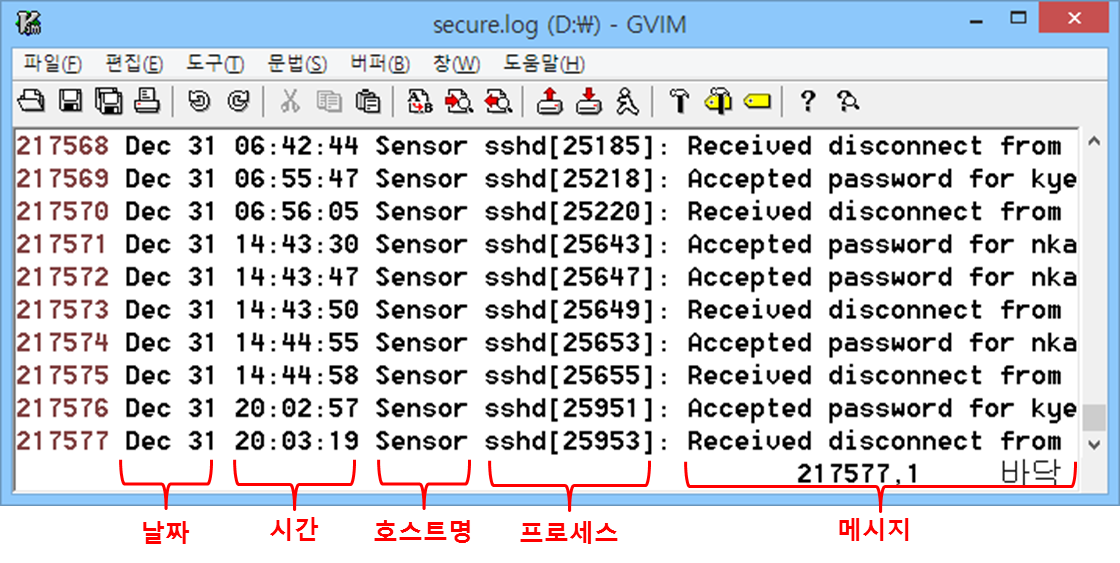
최근 사용자의 사용성 및 행동 패턴을 확인하거나 유저 클러스터링, 모델링 등 다양한 목적으로 사용되는 행동 기반 데이터설문과 같은 사용자 응답 및 기억에 의존하는 데이터 수집 방법 대비, 행동을 정확하게 파악/예측할 수 있음특정 결과에 이르는 과정과 흐름을 상세히 파악
5.[빅데이터]Hive란
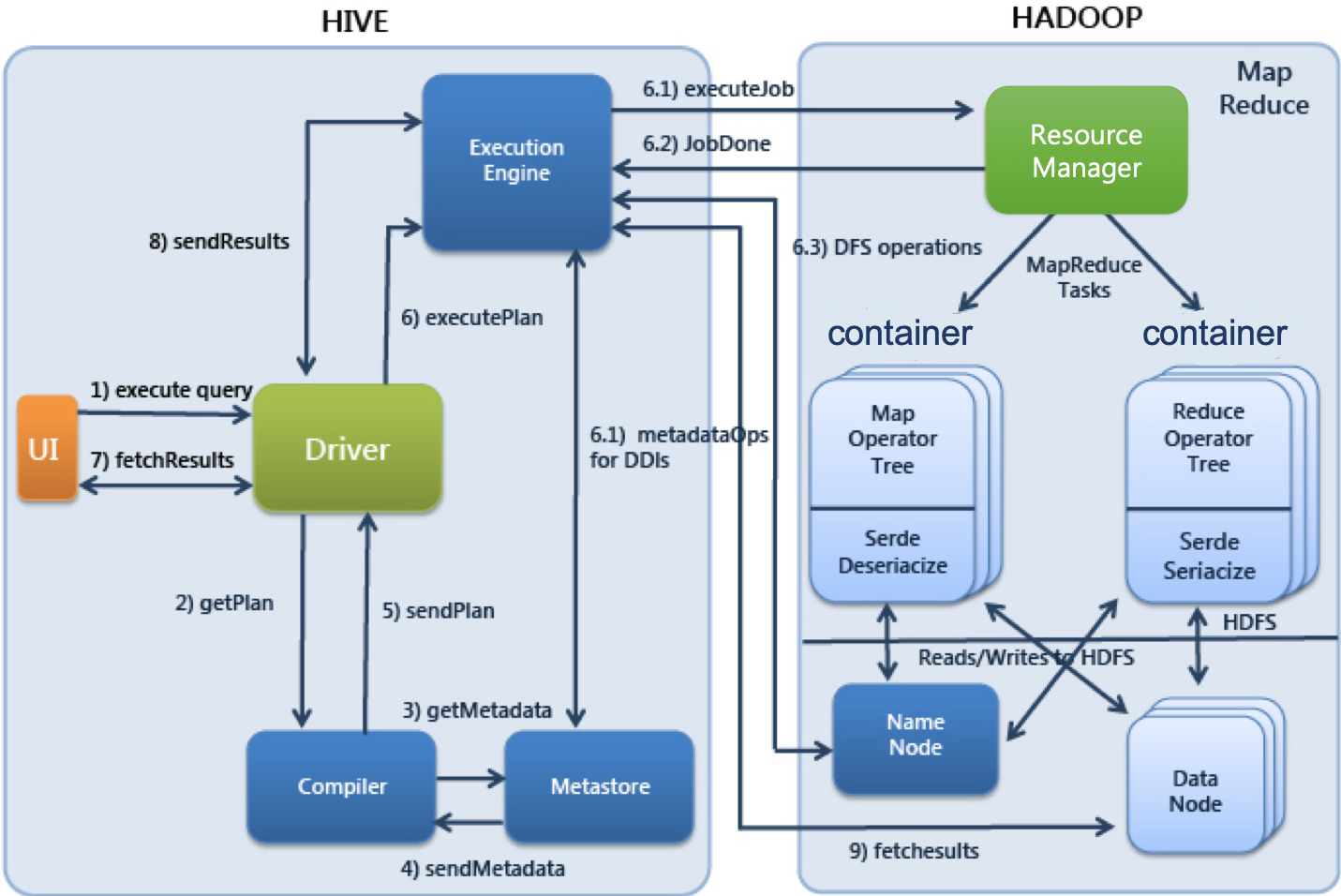
ㅎ
6.[Hadoop&Spark]RDD(Resilient Distributed Dataset) 이해하기
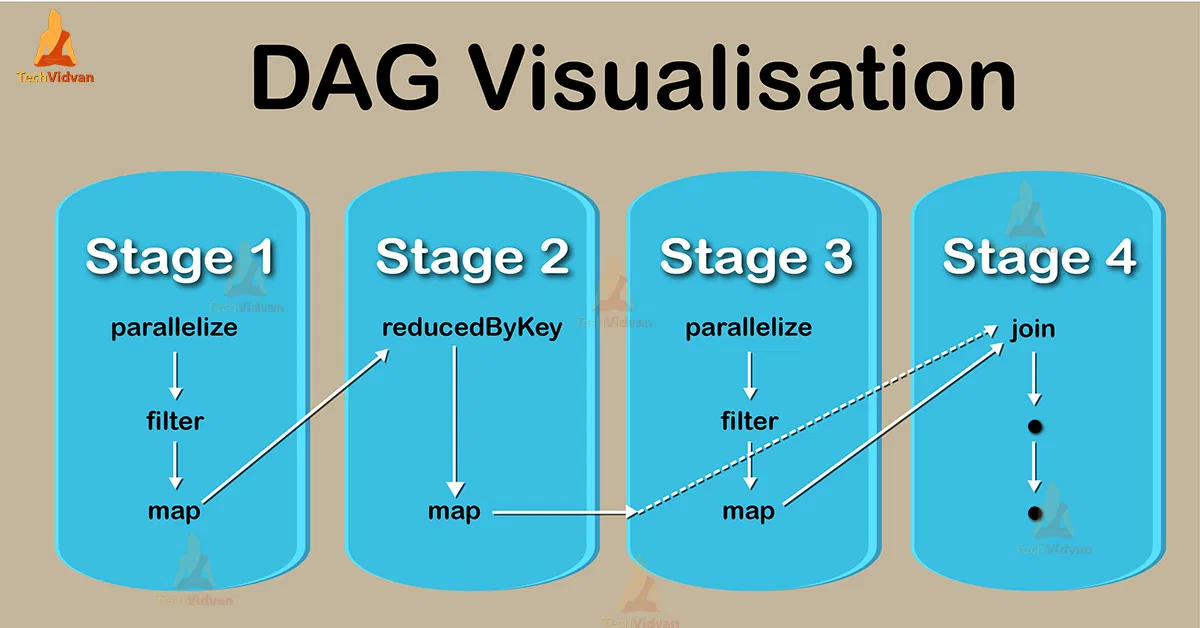
데이터를 HDFS(Hadoop File System)에 넣었다 뺐다 하니까 느리다. 다시말해 처음부터 읽어오지 말고 RAM에 올려놓고 쿼리쿼리쿼리~\-> 하지만 RAM에 올려놓으면 또 에러나거나 컴퓨터가 꺼지면 소실되잖아..RAM에 READ-ONLY로 입력해 놓자!어떻
7.[통계학] T-distribution, T-test
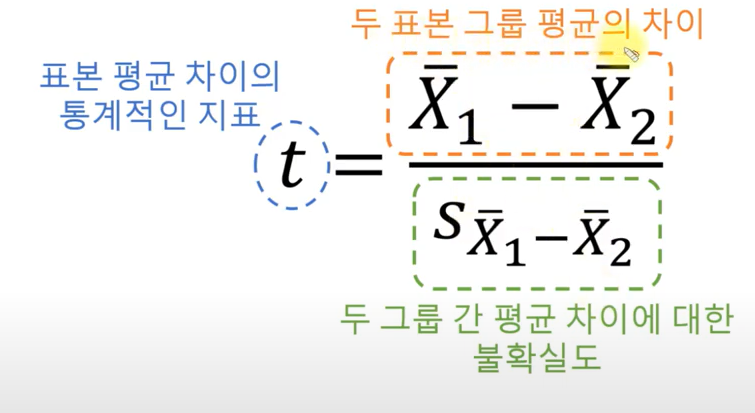
통계적 추론의 두 가지 목적 평가(Estimation) 실제 effect size에 알맞는 그럴듯한 범위 설정 가설검정(p-value) 가설이 효력이 있다고 볼 수 있는지 여부 판단 T-distribution 가운데가 더 좁은 모양(양 끝이 더 높이 떠있는, fat