Hadoop Ecosystem
- 빅데이터 플랫폼 위에 스파크가 적용되는 것이 일반적
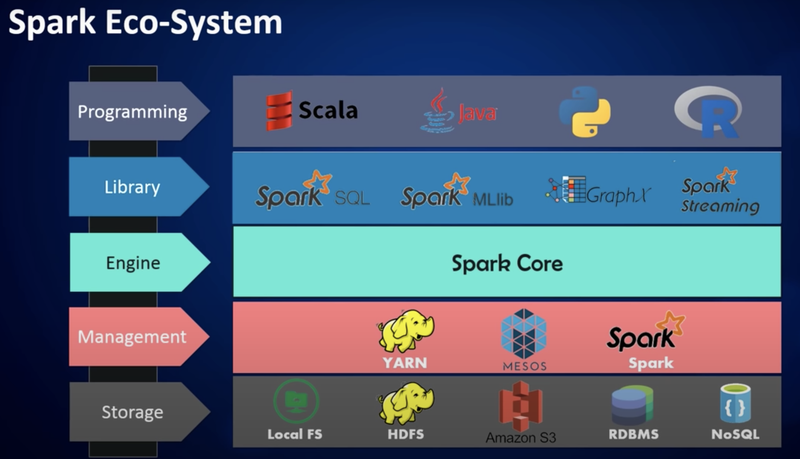
Spark
- In-memory 기반의 클러스터 컴퓨팅 데이터 처리 프로그램
- RDD(Resilient Distributed Dataset)을 구현하기 위한 프로그램
- in memory 기반의 데이터 처리방식이 real-time분석을 가능하게 해 줌으로서 하드디스크가 아닌 메모리에서 관리하고 실시간으로 분석할 수 있게 함
- Spark SQL, Spark Streaming, MLlib 와 같은 라이브러리가 있음
- Spark SQL: SQL 관련 작업
- Streaming: Streaming 데이터 처리
- MLlib: Machine Learning 관련 라이브러리
- GraphX: Graph Processing
[출처: https://youtu.be/VSbU7bKfNkA]
데이터 저장 : AWS의 S3인스턴스를 이용하기도 함
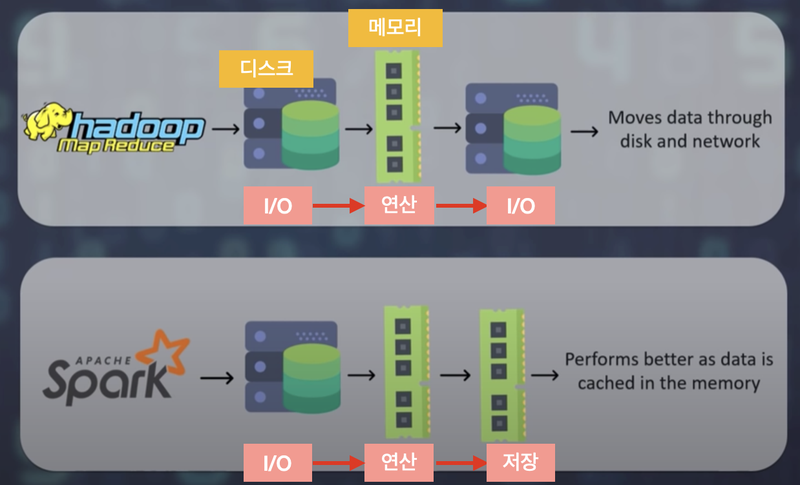
Hadoop과 Spark의 차이
[출처: https://youtu.be/ivgQtdB-BS4의 이미지 변경]
- 하둡은 파일을 디스크에 저장한 뒤 그걸 불러와 연산하고 닷 ㅣ디스크에 저장하면서 파일 처리를 수행
-> I/O 바운드가 주요 병목현상
이에 스파크는 연산단계에서는 데이터를 메모리에 저장하자는 아이디어를 생각해 냄
-> 메모리는 태생이 휘발성이 강하기 떄문에,
RDD(Resilient Distributed Dataset), "탄력적 분산 데이터 셋" 이 고안됨
클러스터의 머신(노드)의 여러 메모리에 분산하여 저장할 수 있는 데이터의 집합
RDD의 특징
- 메모리의 데이터를 읽기 전용(Read-Only, 변경 불가)로 만듦
- 그리고 데이터를 만드는 방법을 기록하고 있다가 데이터가 유실되면 다시 만드는 방법을 사용
RDD 생성
- 내부 데이터 집합 병렬화 :
parallelize()함수 사용 - 외부 파일 로드 :
textFile()함수 사용
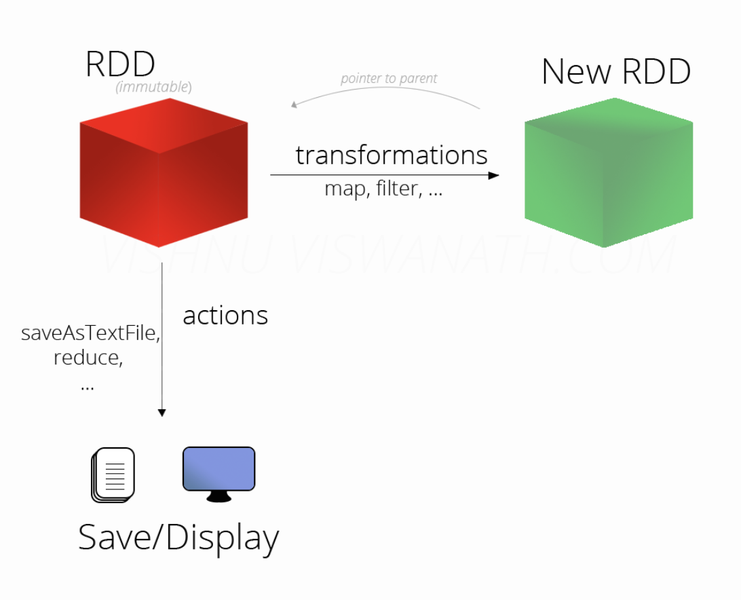
RDD 동작
- transformations
- Actions
구체적은 함수는 아래와 같습니다.

[출처: https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf (마태 자하리아의 RDD 논문)]
- 실제 RDD를 만들고 Transformation하는 과정은 Lineage(계보)를 만드는 과정이고 RDD가 생성되지 않음.
- Action을 해야 RDD가 생성됨
[출처: http://vishnuviswanath.com/spark_rdd.html]

romantic ai developer