-
BERT, T3, GPT-3 등의 학습에는 분산처리가 필요함
-
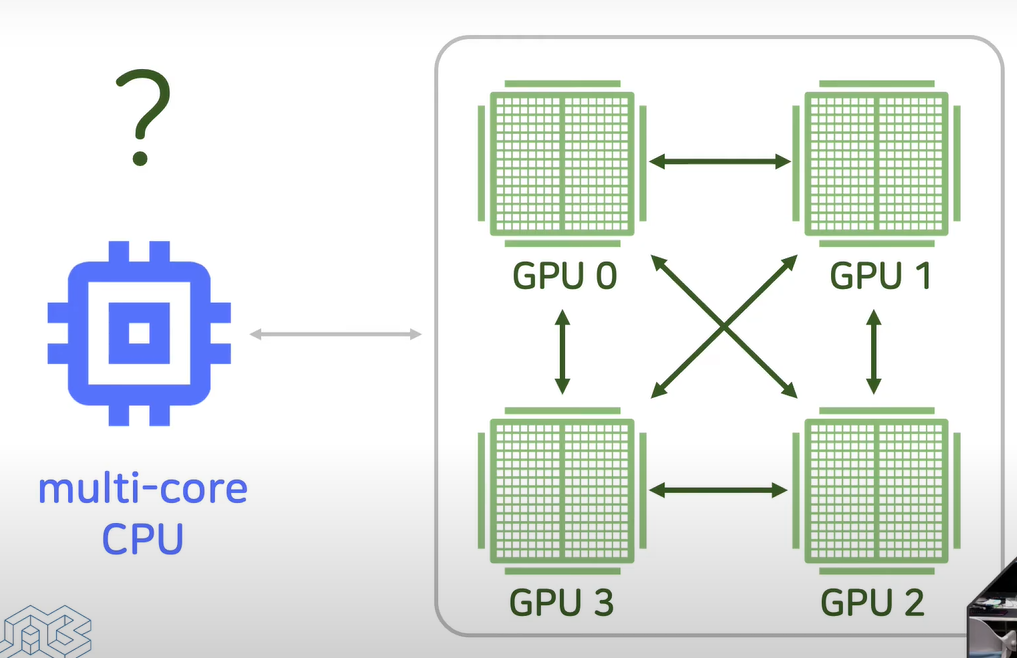
multicore CPU 하나에 GPU 4 개(여러 개)
-
GPU끼리 통신하는 방법
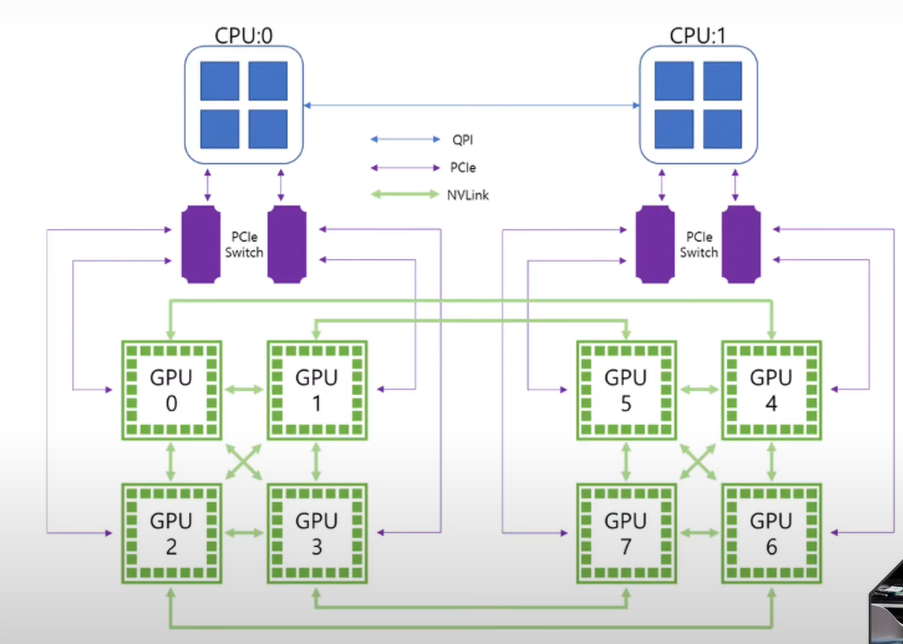
-
PCI express Switch
-
QPI로 CPU 연결
분산형 딥러닝
- 딥러닝의 중요한 과제 중 하나나는 시간이 많이 걸리는 프로세스
- 딥러닝 모델을 설계하려면 많은 하이퍼 파라미터의 설계 공간 탐색과 빅 데이터 처리가 필요
- 학습 과정을 가속화하는 것은 연구개발에 매우 중요함
- 연구개발 프로세스 가속화를 위하여 개인용 슈퍼 컴퓨터 "MN-1" 배포
문제
- GPU 간의 통신은 대규모 환경에서 분산 딥 러닝 모델을 학습시킬 때 많은 문제 중 하나
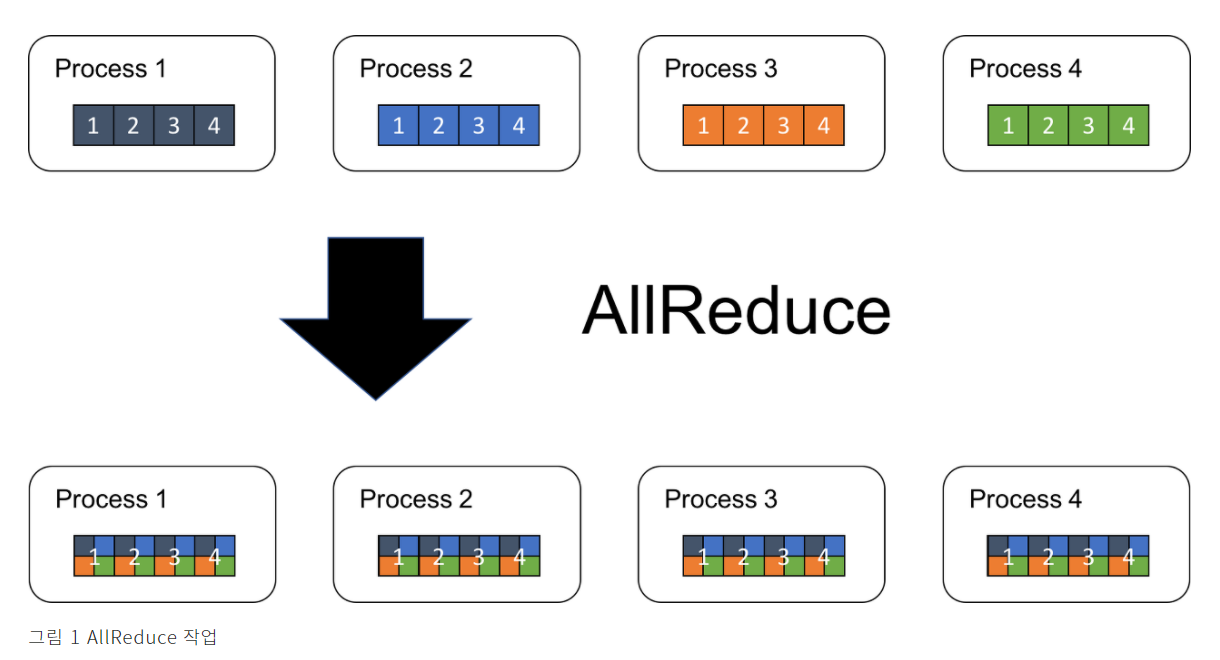
AllReduce
- 동기화 된 데이터 병렬 분산 딥 러닝에서 주요 계산 단계는 다음과 같다.
- 각 GPU에서 Mini-Batch를 사용하여 손실 함수의 Gradient를 계산- GPU간 통신을 통해 그래디언트의 평균을 계산 (Mini-Batch Gradient Descent 참조)
- 모델 업데이트
AllReduce 알고리즘
- 모든 프로세스의 대상 배열을 단일 배열로 줄이고 결과 배열을 모든 프로세스로 반환하는 작업
C3DL(Common central cluster deep learning)
- GPU를 동적으로 할당해서 원하는 딥러닝 시스템과 사용자 프로그램을 실행할 수 있는 플랫폼
- C3는 네이버 검색 데이터 처리에 사용되는 멀티테넌트 클러스터
Reference
https://d2.naver.com/helloworld/1914772
https://brunch.co.kr/@chris-song/96

romantic ai developer