📌vanishing gradient란?
- 딥러닝에서 parameter를 update하는 데에 핵심적인 역할을 하는 gradient값이 소실되어 학습이 제대로 이루어지지 않는 현상
- 반대로 exploding gradient가 있음
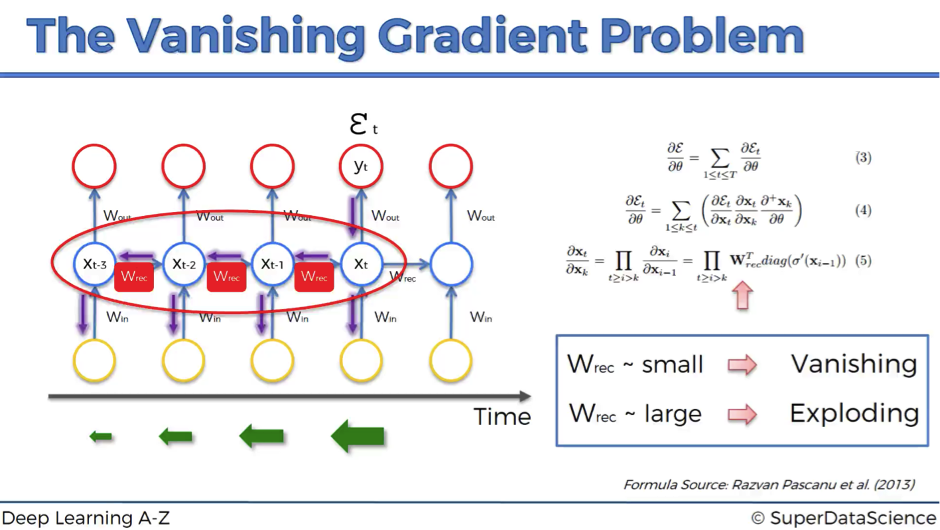
1. vanishing gradient 원인
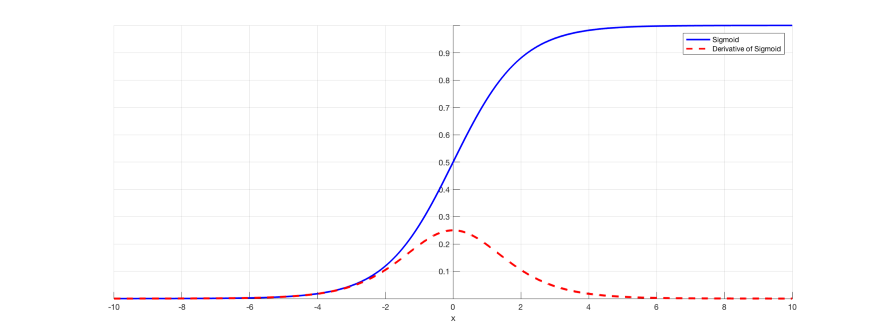
- activation function : 예를 들어, sigmoid의 derivative 값이 0인 부분을 거치면 'saturate'
- 주로 layer가 깊어지기 때문에 나타나는 현상
2. gradient 소실이 어떻게 문제가 되는가?
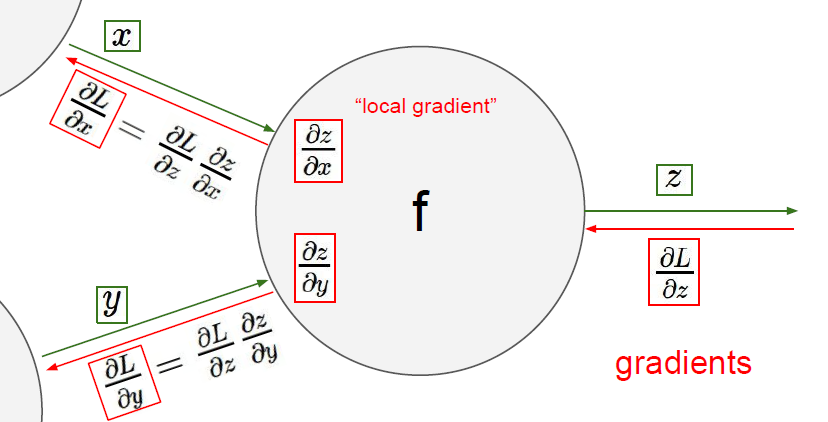
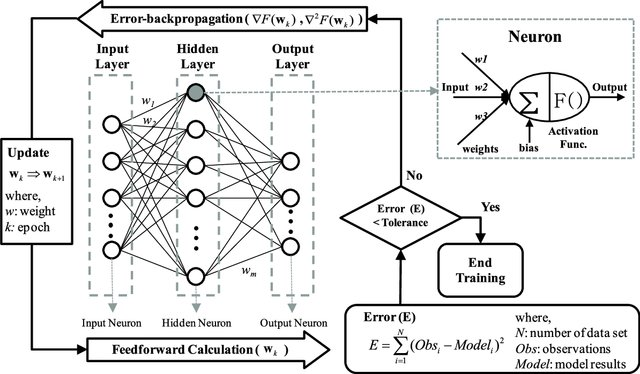
- backprop 과정에서 마지막 layer로부터 초기 layer까지 진행하면서, chain rule에 의해 gradient가 계산되어 감
- 한군데에서 0이 되어버리면 곱해지니 전체 gradient가 0으로 수렴하여 버림
- 결과적으로 뒤쪽 parameter는 잘 바뀌는데, inital layer의 parameter가 제대로 update되지 않음(그대로 있음)!
📌어떻게 해결하는가?
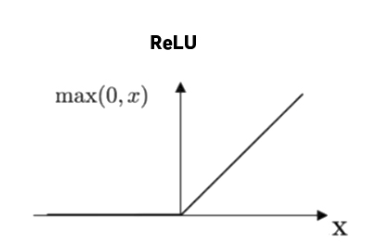
1. ReLU & LeakyReLU
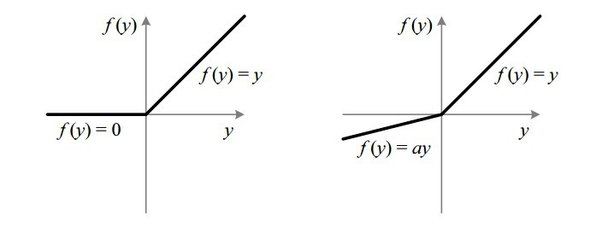
- relu 로 값이 커져도 gradient가 0으로 수렴하지 않지만, 음수값이 input으로 들어올 경우 dying relu 현상 발생
- leakyrelu 로 해결. (parametric relu도 있음)
2. Residual Network
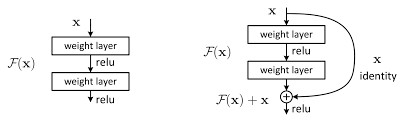
- CNN의 발전 과정 중, layer수가 늘어날수록 오히려 학습이 제대로 진행되지 않는 현상이 발생하여 고안된 모델
- derivative를 0으로 만드는 것은 대부분 activation function
- input으로 들어오던 x를 layer를 거친 F(x)와 더해주어 소실을 완화하고, 결과적으로 gradient값을 더 크게 만들어줌
3. Batch Normalization
minibatch 별 input을 normalize 해주는 기법
covariate shift(학습 parameter)
- Weight initialization, activation function 개선 등에도 예측할 수 없는 gradient 소실 문제가 발생할 수 있음
- 딥러닝에서 training parameter가 변화하면서 layer의 input의 분포(distribution) 도 달라지게 됨
- 이는 training을 training을 천천히 만들고, learning rate도 크게 설정 못하게 하고 initialization도 더 섬세하게 진행해줘야 함
-> nolinearity 가 포화되어 학습이 매우 어려워짐
5. (Proper) Weight initialization
- 학습이 잘 진행되려면
- 각 layer output의 분산(variance)값이 input의 variance 분산값과 유사해야 함.
- backprop 시 각 layer의 upstream gradient와 downstream gradient값이 같아야 함.
- Xavier Initialization
- Normal distribution with mean 0 and variance σ2 = 1/ fanavg
- Glorot initialization
- Or a uniform distribution between -r and +r , with r = sqrt( 3 / fanavg )
6. RNN -> LSTM!
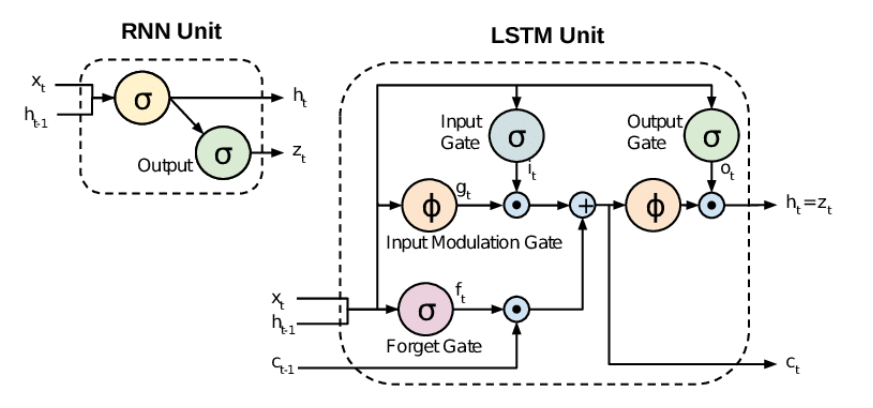
- 기존 vanishing Gradient issue를 해결하기 위해 LSTM 모델이 개발됨
- 장기적 의존관계를 반영하는 'memory cell'
- vanishing & exploding gradient 문제를 여러 gate를 통해 해결
Exploding Gradient 를 해결하기 위해서는?
- Gradient Clipping
Reference

romantic ai developer