Wavenet이란
- Audio waveform을 generate 하는 모델
- waveform을 결합확률분포로 표현하고, 이를 convolution layer를 쌓아서 모델링
- 다시 말해, 1D convolution 으로 time-series data를 causal하게 메핑하여 음원을 생성하는 알고리즘
- Receptive Field 가 너무 좁음 -> dilated convolution으로 넓힘
- Residual block 및 skip connection 활용
- TTS, 음악, voice conversion
특징
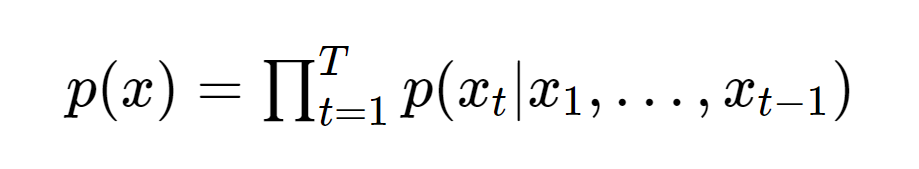
- t 시점의 오디오 샘플을 t-1 시점까지의 샘플들을 조건부 분포로 모델링(causal modelling)
- pooling layer는 네트워크에 없고, input output 차원이 동일
- 최적화는 MLE를 활용(다시말해, Softmax function으로부터 cross-entropy를 최적화)
[https://youtu.be/GyQnex_DK2k]
causal convolution
- time series에서 과거의 데이터만 활용
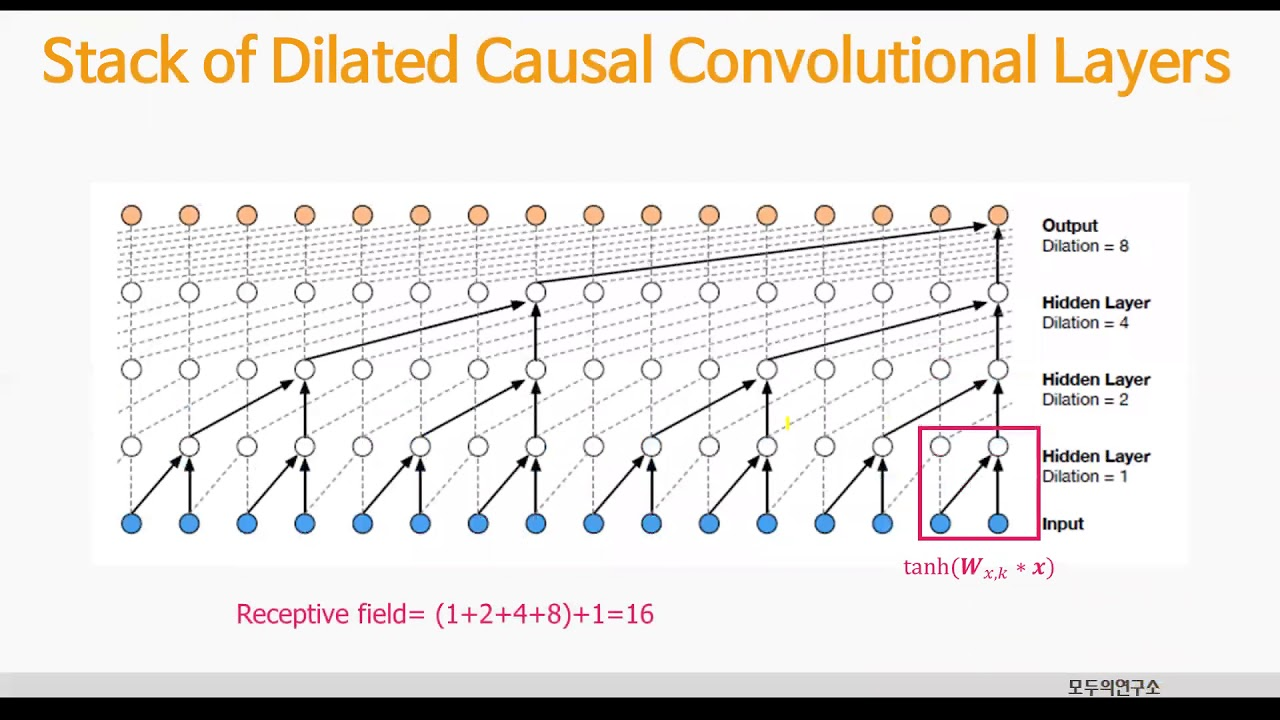
Dilated Convolution
- 범위를 넓히고, stride를 키워 컨볼루션
- 위 그림에서 dilation이 1, 2, 4, 8 로 receptive field를 키운 후 convolution 진행
- 계산량이 커지지 않으면서 다양한 특징을 학습하는 효과
Model architecture
미시적 구조
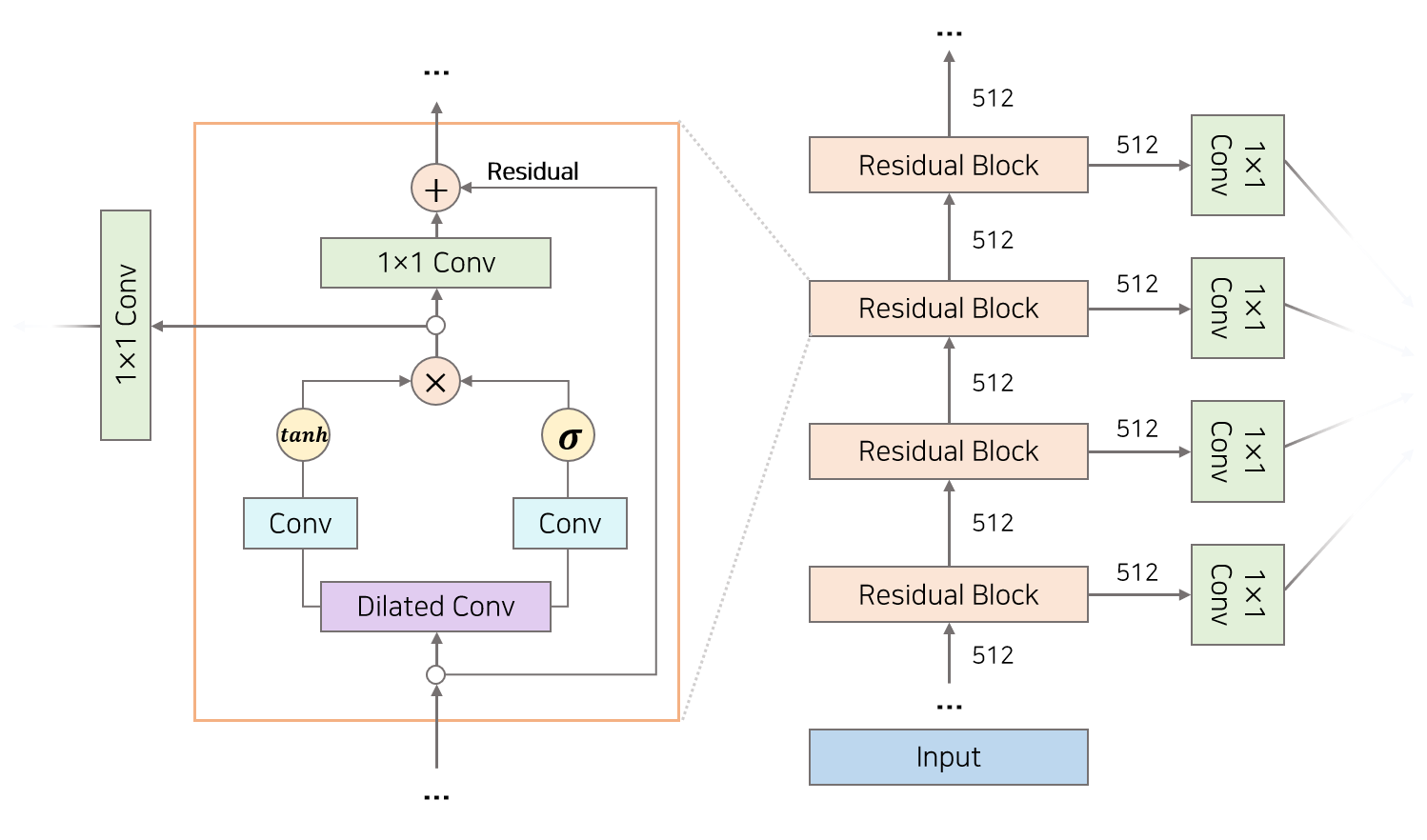
-
input signal이 들어가서 dilated conv -> Gated activation -> 1 * 1 conv** + residual 을 거쳐
1) 하나는 다음 layer
2) 하나는 skip connection으로 빼냄 -
1x1 Conv filter를 256개를 줘서 아웃풋을 256(8bit)로 맞춰줌
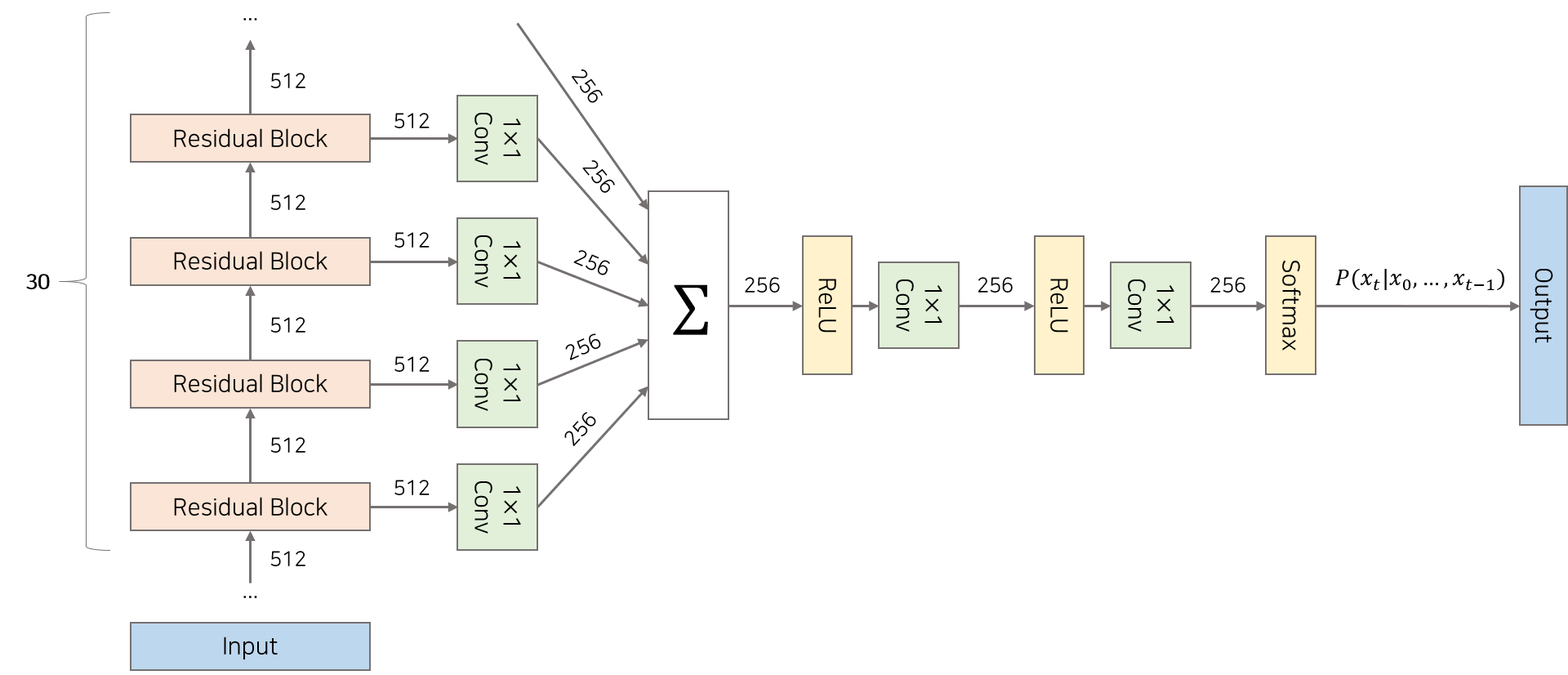
거시적 구조
[https://joungheekim.github.io/2020/09/17/paper-review/]
- 30개의 layer
- 30개의 Residual block
- 30개의 skip connection으로 빠져나온 벡터
- 이를 전부 더해서 마지막에 softmax를 취해 256개의 값 중 어디로 assign 될 확률이 가장 높은지 구함
-> 이것이 t 시점의 output이 됨.
Gated activation
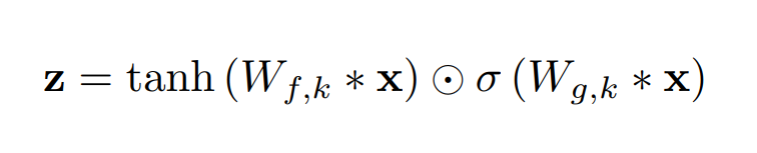
- dilated conv 뒤에 gated network 사용해서 다음 layer로 전달할 비율 조절
- 선택적으로 활성화 (LSTM Layer)
1* 1 convolution

[https://gaussian37.github.io/dl-dlai-network_in_network/]
- 채널 수를 줄이고 싶거나
- 단순히 가중치 적용 및 비선형성 추가하고 싶을때 적용
Reference

romantic ai developer