재귀(Recursion)는 자기 자신을 호출하는 함수로 다른 말로는 재귀함수(Recursion Function)이라고 한다.
1. 재귀함수란 무엇인가?
재귀함수는 상술했듯 자기 자신을 호출하는 함수를 재귀함수라고 한다. 이 재귀적 방법은 자신의 복사본을 호출하여 더 작은 문제를 풀게 하여 문제를 해결한다. 이를 재귀적 단계(Recursion Step)라고 한다.
또한 재귀 단계는 더 많은 수의 재귀 단계를 생성할 수 있다.
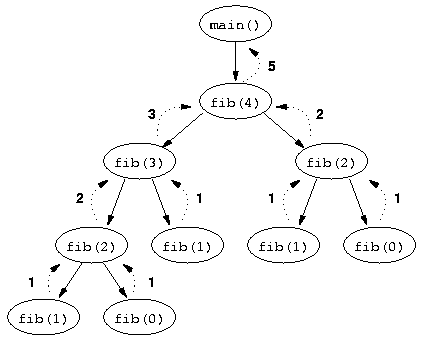
출처 : 구글 검색(피보나치 수열 재귀함수)위의 그림과 같이 피보나치를 구하는 재귀함수의 경우 4단계의 함수가 3단계, 2단계를 만들고 3단계의 함수가 2, 1단계를 만든다.
작은 문제의 서열(호출된 함수)은 기본 경우(Base Case)로 수렴해야 한다. 이 말이 무슨 말인가 하면, 피보나치 수열의 점화식을 예로 들면
f(n) = f(n-1)+f(n-2)로 볼 수 있는데 이 때 만약 n < 3일 때에 1을 return 한다면 본인을 부르지 않고 기본 단계(Base Case)로 수렴할 수 있다는 것이다.
1. 재귀를 왜 사용해야 하는가?
우리는 사실 컴퓨터과학을 공부하기 이전에도 재귀를 수학에서 다른 형태로 맞이한 적이 있었다. 수학적 귀납법(Mathematical Induction)을 통해 접한 적이 있는데, 간략히 설명을 하자면
수학적 귀납법(Mathematical Induction)에 의해 증명을 할 때에
예를 들어 n = 27이라고 가정한다면 n = 1이라는 것을 증명하고,
n = 1+1이라는 것을 증명하고,
n = 1+1+1이라는 것을 증명하고, 증명하고, 증명해서 n = 27이라는 것까지 증명하는 것을 수학적 귀납법이라고 한다.
이를 쉽게 표현하자면,
n = 1 (증명)
n = i (가정)
n = i+1 (증명)을 반복하는 과정을 수학적 귀납법이라고 한다.
재귀를 사용한 코드는 일반적인 loop를 사용한 코드보다 짧고, 작성하기 편리하며, 코드를 이해하기에 용이하다.
Factorial을 함수로 만들어 보면서 차근히 코드를 해석해보면 수학적 귀납법과 매우 유사하다는 것을 알 수 있다.
//n의 입력은 0 ≤ n이라고 가정한다.
long long int Factorial(int n) {
if (n <= 1) {
return 1;
} else {
return n * Factorial(n-1);
}
}(설명에서는 편의를 위해 Factorial 함수를 f로 표현한다.)
위의 코드를 뜯어보면 n ≤ 1일 때에 1을 return한다. 당연한 얘기이다. 0! = 1, 1! = 1이기 때문이다. 그렇다면, 3이 입력으로 들어올 경우는 어떨까
n이 3일 경우 n이 1을 초과하므로 else로 넘어간다. 그렇다면 3*f(2)을 호출한다. f(2)는 2*f(1)을 호출하고 f(1)은 1을 return한다. 이게 우리가 아까 설명한 작은 단계를 증명해둔 것이다. 그렇다면 상위 단계로 올라가보자. f(1) = 1, f(2) = 2*1 = 2, f(3) = 3*2*1 = 6.
재귀가 어떤 식으로 큰 문제를 작은 문제로 나누어 해결하는지 이해가 되었을 것이다. 그렇다면 재귀(Recursion)과 반대되는 개념인 반복(Iteration)을 이용해 코드를 짜보면
long long int Factorial(int n) {
int res = 1;
for (i = n; i >= 1; i--) {
res = res * i;
}
return res;
}반복(Iteration)을 이용해 코드를 작성하면 재귀(Recursion) 코드 작성 시에 고민해야 할 거리가 많이 생긴다. 초항을 1로 잡는 것이 맞는지, i를 n부터 시작해서 1 이상일 경우 반복인지, 초과일 경우 반복인지 등등등 해서 말이다. 반복(Iteration)의 경우 여러 경우를 생각해야 하지만, 재귀(Recursion)의 경우 익숙해지기만 한다면, Factorial의 정의를 의사코드로 하여 코드를 작성할 수 있다는 것이다.
재귀는 메서드(함수, Function)가 복사된다(변수만 복사).메서드(함수, Function)은 return 될 때 삭제된다.
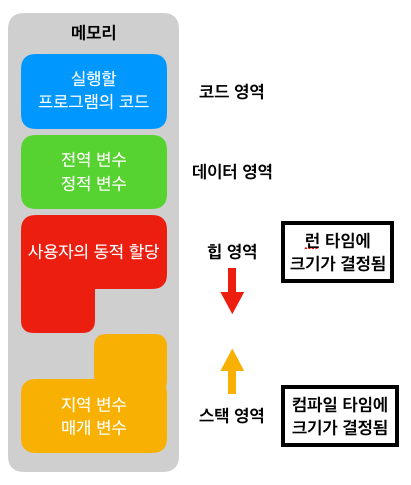
출처 : 구글 검색(메모리 구조)위의 이미지를 보더라도 메모리가 할당받는 구역이 위에서 생성되는 부분이 있고 아래서 생성되는 부분이 있는데 위에서부터 함수가 차곡차곡 쌓아가며 메모리를 할당한다(이 파트는 컴퓨터 구조와 운영 체제파트를 통해 다시 서술할 예정).
호출된 함수가 지워지려면 당연하게도 return이 되어야 한다. 함수의 경우 위에서 밑으로 쌓이는 Stack 구조를 취하는데 만약 Factorial 함수의 매개변수(Parameters)를 4로 호출한다면 4는 3을, 3은 2를, 2는 1을 호출하는 그림일 것이다. 하지만 피보나치는 한 함수가 두 개의 함수를 호출하기에 더 많은 양의 메모리를 차지하게 되는 것이다.
여담으로 좀 지능이 높은 컴파일러나 인터프리터라면 컴파일링, 인터프리팅할 때에 재귀(Recursion)이 반복(Iteration)으로 바뀐다(전부는 아님).
2. 재귀와 반복의 차이
재귀와 반복 둘 중에 뭐가 더 좋냐고 물어본다면 개발자가 무엇을 하고 싶은가?에 따라서 다르다.
일반적으로 재귀는 개발자가 풀고자 하는 문제에 따라 다르며 보통 수학적 접근을 하고자 할 때에 자주 사용된다.
이러한 이유 때문에 반복(Iteration)으로는 수학적 접근이 어려워 난항을 겪던 문제도 재귀(Recursion)을 이용해 쉽게 풀 수 있다.
재귀는 매번 호출을 할 때마다 스택의 공간(메모리)을 필요로 한다. 이게 무슨 말이냐면 위에 있는 이미지 자료를 보면 함수는 호출될 때마다 메모리를 한 칸씩 잡아먹는데 이게 과하게 많아지면 프로그램의 치명적인 오류를 발생시킬 수 있을 수 있으며, 호출떄 마다 새로운 메모리 공간을 할당해줘야 하기에 반복(Iteratoin)에 비해 약간 느리다고 할 수 있다.
재귀와 반복의 차이를 좀 더 자세히 풀자면
재귀(Recursion)
- 기본 경우(Base Case)에 도달할 경우 종료한다.
- 상술했듯 함수들은 호출시 스택 프레임(메모리)에 부가 공간을 필요로 한다.
- Infinity Recusion(무한 재귀)할 시에 스택 프레임(메모리)에 부가 공간을 필요로 하기에 스택 오버플로우(메모리 오버플로우)가 발생한다.
- 어떤 문제들(수학적 사고를 요하는 문제)에 대해선 재귀를 사용하면 쉽게 해답을 구할 수 있다.
반복(Iteration)
- 조건이 거짓일 경우 반복을 종료한다(바꿔 말하면 조건이 참이라면 반복한다는 것).
- 각 반복이 실행될 떄에 부가적인 공간을 필요로하지 않는다.
- Infinity Iteration(무한 반복)은 부가적인 공간을 요하지 않아, 무한히 반복한다(재귀는 위에서 말한 스택 오버플로우가 발생).
- 반복적 해법은 재귀적 해법에 비해 문제 해결을 하지 못 할 때가 있다.
재귀와 반복의 차이를 번호 별로 새겼으니 1번은 1번을 보고 차이를 이해하고 2번은 2번을 보고 차이를 이해하면 된다.재귀의 특징이 몇 개가 있는데 한번 보면
- 재귀적 알고리즘에는 두 가지 경우가 있는데, 재귀적 경우(Recursion Step)과 반복적 경우(Base Case)가 있다.
- 모든 재귀(Recursion)는 기본 경우(Base Case)에 종료해야 한다.
- 일반적으로 반복 해법이 재귀 해법보다 효율적이다(재귀 호출시에 사용되는 부가적인 메모리 때문).
- 보통의 문제들은 재귀(Iteration)으로 풀 수 있다면 반복(Iteration)으로도 풀 수 있다(전부는 아니다). 즉, 대부분의 문제는 재귀(Recursion)으로 풀 수 있다면, 반복(Iteration)으로 풀 수도 있지만, 몇몇의 문제들은 폰 노이만이 부활해도 풀 수 없다는 것이다.
- 몇몇의 문제들은 눈에 띄는 반복적(Iteration) 해답이 없을지도 모른다.
재귀 알고리즘의 예시들
- Fibonacci Numbers, Factorial (Mathmatic)
- Quick Sort, Merge Sort (Sort Algorithm)
- Binary Search (Search Algorithm)
- InOrder, PreOrder, PostOrder (Tree Search)
- Depth First Search, Breadth First Search (Graph Search)
- Dynamic Programing
- Divde and Conquer Algorithm
- Tower of Hanoi
- Back Tracking
이 알고리즘들은 서로 개행의 알고리즘인 것이 아니라, Back Tracking 안에 DFS가 있고 그런 형식이다.
아무튼 이렇게 예시만 보여주면 알기 어려우니 Tower of Hanoi로 알고리즘을 연습해 보자면
일단 문제 해결 방식은 이러하다(하노이의 탑 규칙).
(1) n-1개의 원반을 보조 타워로 옮긴다.
(2) 남은 타워를 옮겨야 할 타워로 옮긴다.
(3) 만약 옮겨야 할 원반이 남았다면 다시 (1)로 돌아간다.
뭔가 말이 안된다고 생각할 것이다. 분명 2개 이상의 원반은 옮길 수 없다고 명시되어 있었는데, 멀쩡히 옮긴다고 생각할 것이다. 하지만, 이를 의사코드로 생각해보면
원반을 모두 옮겼는가? (옮겼다면 return)
원반을 모두 옮기지 못했다면 (n-1)개를 보조 타워로 옮긴다.n이 1이될 때까지 큰 문제를 작은 문제로 쪼개어 생각하게 되는 것이다.
이를 코드로 작성해보면,
void TowersOfHanoi(int n, char from, char to, char aux) {
/*만약 원반이 하나라면 옮기고 return*/
if (n == 1) {
printf("원반 1을 막대 %c로부터 막대 %c로 옮긴다.", from, to);
return;
}
/*원반을 Auxiliary Tower로 옮긴다(옮기고자 하는 Tower는 Auxiliary가 된다).*/
TowerOfHanoi(n - 1, from, aux, to);
/*Auxiliary Tower를 이용해 원래 옮기고자 헀던 Tower로 옮긴다.*/
printf("\n원반 %d를 막대 %c로부터 막대 %c로 옮긴다.", n, from, to);
TowerOfHanoi(n - 1, aux, to, from);
}그리고 만약 이 문제를 '반복(Iteration)으로 풀어라'라고 한다면, 몇몇의 사람들은 오랜 시간이 지나도 이 문제를 풀지 못할지도 모른다. 즉, Hanoi 문제가 재귀(Recursion)으로 풀면 쉬워지는 대표적인 예제라는 것이다.
책에는 Back Tracking에 대해서 다루고 있지만, 필자가 생각하기엔 Back Tracking은 자료구조보단 알고리즘에 가깝다고 생각이 들어 다루지 않겠다.
필자가 보고있는 강의인 남원홍 교수님의 자료구조 강의에서도 다루지 않아 그냥 넘기겠다.
