
2.1 록 기반 규약
- 트랜잭션 스케줄을 제한하여 원하는 트랜잭션 스케줄을 생성
- 록 기반 동시성 제어 규약의 트랜잭션 운용 원리를 보임
exclusive (X) mode: 데이터를 쓸 때 주로 사용 (write lock) -> read 도 가능
shared (S) mode: 데이터를 읽을 때 주로 사용 (read lock) -> write 는 불가
transaction - 트랜잭션은 lock을 보유하여야 그에 따른 read()/write() 연산을 할 수 있다. (read 연산이면 read lock)
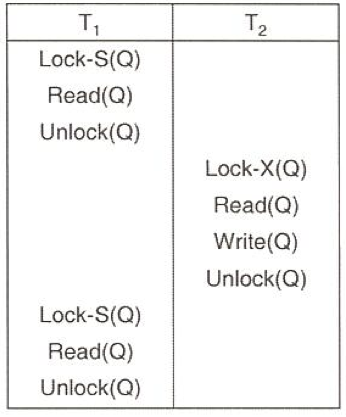
- write lock은 반드시 한 개의 트랜잭션에 부여 가능 / read lock 은 동시에 다수의 트랜잭션에 부여 가능
- lock을 받지 못해 기다리는 트랜잭션은 다른 트랜잭션에 부여된 lock이 해제될 때까지 기다린 후, 받으면 수행 가능
lock-S(A)
read(A)
unlock(A)
lock-S(B)
read(B)
unlock(B)
display(A+B)
특정 연산에 대해 해당 연산의 앞 뒤를 locking, unlocking이 감싸야 함
-> 해당 규약 만으로는 serializability 하지 않음 (read(A)와 read(B)하는 사이에 A, B 값이 update 될 수 있으므로)
Two-Phase locking 규약
- Phase 1: growing phase (록이 증가하는 단계)
- Phase 2: shrinking phase (록이 감소하는 단계)
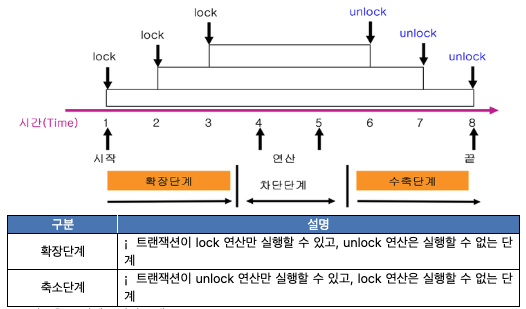
(growing과 shrinking은 범위와 강도에 대한 것임)
특징: 우선 lock을 풀기 시작하면 감소 단계로 들어간 것이므로 더이상 새로운 lock을 잡을 수 없음
해당 방식은 Isolation 관점에서만 conflict serializable schedule을 보장하고 / Atomic, Durability, Recovery 관점에서 추가적인 제한이 필요함
Cascading rollback을 방지하기 위해
- strict two-phase locking
exclusive lock(write lock)을 잡으면 이 lock을 transaction이 끝날 때 까지 (commit/abort) 놓지 않는 방식
Cascading rollback 문제를 방지
lock point 순서로 결정됨- Rigorous two-phase locking
모든 lock(read lock & write lock , ...)을 transaction이 끝날 때 까지 놓지 않는 방식
strict two-phase locking보다 병렬성이 떨어지지만, 구현이 용이
commit order로 결정
Issue: Lock Conversions (록 변환)
트랜잭션이 데이터에 대한 록을 요구할 때, 동일 데이터에 대한 록을 기존에 할당받아 보유하고 있다면 모드만 변환
(해당 방식은 serializability를 보장)
two-phase locking에서...
upgrade(lock-S(read lock) -> lock-X(write lock)) : Phase 1
downgrade(lock-X(write lock) -> lock-S(read lock)) : Phase 2 2PL의 conflict serializability 보장에 대한 증명
two-phase locking은 serializability를 보장하지 않는다고 가정
2PL을 사용한 non-seializable한 스케줄 T0, T1, ..., Tn 의 선행그래프 "T0 -> T1 -> ... -> Tn -> T1" (사이클이 있음)
Ai = Ti의 lock point(lock을 마지막으로 얻은 시점)라 가정
모든 트랜잭션 Ti -> Tj에 대해 Ai < Aj 가 성립하며 "T0 -> T1 -> ... -> Tn -> T1" 가 "A0 < A1 < ... < An < A1"을 만족해야 함하지만 Tj가 실행되려면 Ti의 lock을 풀고, Tj가 lock을 얻어야 하기에 Ai < Aj 일 수 밖에 없음
An < A1 가 모순
자동 록 획득
lock에 대한 획득/철회는 사용자의 구체적인 요구에 의하여 운영되지 않고 시스템 내부에서 자동으로 운영
S-lock (read lock)
if Ti has a lock on D
then
read(D);
else begin
if necessary wait until no other transaction has a lock-X on D;
//다른 트랜잭션이 D에 대해 imcompatible한 lock을 가지고 있을 때 -> 대기
grant Ti a lock-S on D;
read(D)
end;X-lock (write lock)
if Ti has a lock-X on D
then
write(D);
else begin
if necessary wait until no other transaction has any lock on D;
//다른 트랜잭션이 D의 어떤 lock도 가지고 있지 않을 때까지 대기
if Ti has a lock-S on D
then
upgrade lock on D to lock-X;
else
grant Ti a lock-X on D;
write(D);
end;록 구현
- Lock-Manager라는 독립된 프로세스를 통해 구현
- 트랜잭션이 해당 프로세스에 lock을 요청 -> Lock-Manager의 응답을 대기
- Dead lock 발생 시 Rollback
- lock 획득 여부를 Lock Table(memory hash table)로 관리함
Deadlock (교착 상태)
 2개 이상의 트랜잭션이 서로 무한정 기다리는 상태
2개 이상의 트랜잭션이 서로 무한정 기다리는 상태- 교착상태에 있는 트랜잭션이 . 타데이터에 대한 록을 가지고 있는 경우 -> 데이터베이스 시스템 정지하는 상태 발생
Starvation (기아 현상)
특정 X-lock 이 계속 Rollback 되거나, lock을 아예 얻지 못하는 현상
ex) write lock하고 있는 상황에서 다른 뒤의 트랜잭션이 read lock을 계속해서 요청할때, 시스템 구현의 오류로 read lock을 허용하고 write lock은 무한정 대기할 수 있음
Deadlock은 어쩔 수 없는 현상이지만, Starvation은 구현의 문제임
Graph based protocol
lock-based protocol의 일환
D = {d1, d2, …, dn}, di가 dj 보다 반드시 먼저 실행되어야하는 부분 순서 조건을 만족하는 D에 대해서 di -> dj 간선을 그림
그러한 D는 directed acyclic graph 이며 이를 데이터베이스 그래프라고 부름
Tree-based protocol 에서 주로 사용됨
Tree-based locking 규약 (to Graph based protocol)
- X-lock 만 존재
- 어느 data item이든지 lock을 잡을 수 있음
- Ti가 Q에 대하여 lock을 잡으려면, 반드시 Q의 부모에 대한 lock을 우선 잡고 있어야 함.
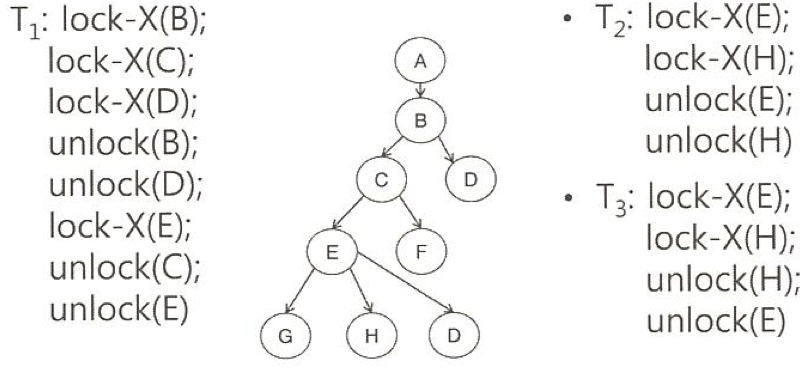
Conflict Serializability & Not Deadlock
pros
- 2PL에 비해 unlock이 자유 -> waiting time 감소, concurrency 증가
- Deadlock free -> Rollback에 대해 자유로움
cons
- recoverability, cascade free는 아님
- 부모 자식의 관계로 인해 필요없는 lock을 잡는 경우가 있음
DBMS에서는 2PL 규약을 보완하는 역할 정도
2.2 Multiple Granulatrity Locking (MGL)
locking이 적용되는 데이터의 크기는 다양함 (DB ~ record)
DB의 상위-하위 카테고리를 Tree로 구성하였을 때, 특정 노드에 locking 할 경우 그 하위 노드에 lock을 잡는 효과가 있음
Fine granularity : record 단위로 잘게 쪼개어 lock을 관리 : 동시성 향상, 오버헤드 증가
Coarse granularity : Table처럼 큰 단위로 lock을 관리 : 동시성 하락, 오버헤드 하락
Multiple granularity : Fine, Coarse 를 적절히 섞어 사용
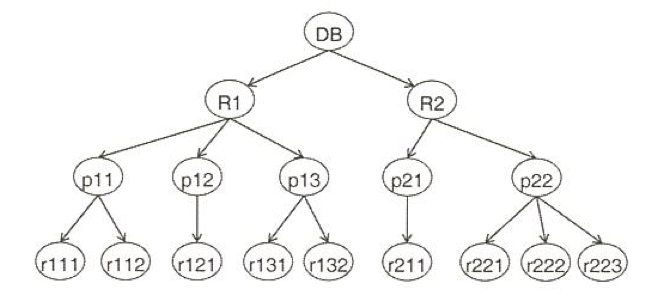
DB: database
R: relation
p: page
r: record (tuple)Intention lock
노드 N에 대해 Intention lock을 건다는 것은 후에 N의 하위 노드에도 lock을 얻는다는 명시
- S : Shared Lock (S-lock) (read lock)
- X : Exclusive Lock (X-lock) (write lock)
- IS : Intention Shared Lock
- IX : Intention Exclusive Lock
- SIX : Shared + Intention Exclusive Lock
(S-lock을 걸어 전체적으로 read()하고, 어느 하위 노드에서 IX-lock도 거는 것)
어떤 노드에 lock이 걸리면 해당 노드의 모든 부모 노드에 적절한 Intention lock 이 걸림
ex) r222에 S-lock 을 걸게되면 p22, R2, DB에 IS-lock이 걸리게되며, 후에 이들이 lock을 얻을 때 도움이 됨
DB가 나중에 S-lock을 얻고자 했다면 IS-lock이 있으므로 lock을 얻을 수 있음
하지만 X-lock 을 얻고자 한다면 IS락이 있으므로 락을 얻을 수 없음(내부 자식 중 S 락을 갖고 있는 자식이 있다는 뜻이며, X-lock 은 S-lock 과 incompatible 하기 때문)
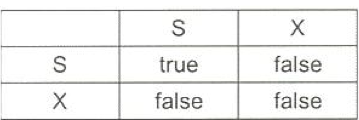
- Intention lock 의 호환성(Compatibility) 행렬
IS / IX 는 본인의 하위노드 어딘가에서 read() / write() 한다는 것
read() / write()는 서로 Compatable하지 않지만, 해당 행렬은 본인 노드에서의 IS / IX 을 이야기 하는 것 (IS / IX는 호환이 됨)
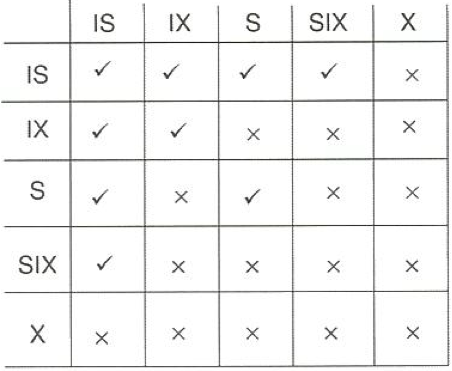
MGL Scheme (동작 방식)
- 트리의 Root 노드가 가장 먼저 lock 에 걸려야 함 (any lock)
- 노드 Q에 S-lock 또는 IS-lock을 걸려면 그 부모 노드의 IX 또는 IS 락을 가진 상태여야 함
- 노드 Q에 X-lock, SIX-lock, IX-lock을 걸려면 그 부모 노드에 IX-lock 또는 SIX-lock을 가진 상태여야 함
- Two-phase 를 따르기 때문에 어떤 lock이든 해제한 적이 있다면 그 뒤로는 lock을 얻는 행위는 하지 못함
- 노드 Q의 lock을 해제하고 싶다면 하위 노드 중 lock이 걸린 노드가 없어야함
lock을 걸 때는 root-to-leaf / 풀 때는 leaf-to-root
2.3 Deadlock
Deadlock 처리
- Timeout-based Schemes
일정 시간이 지나도 응답이 없으면 해당 트랜잭션 Rollback
Starvation 발생 가능성
적절한 시간 설정의 어려움 - Deadlock Prevention Protocols
Graph-based protocol
Predeclaration
Wait-die / Wound-wait Scheme (Older-Younger)
Timestamp를 통해 트랜잭션이 시작된 시간을 관리하고, 이를 기준으로 처리
Wait-die
- Non-preemtive approach (비선점형 방식)
- lock 충돌 발생 시, 기존에 lock을 가진 트랜잭션과 비교하여 새롭게 lock을 요구하는 트랜잭션이 old하면 wait, young하면 die(Rollback)
- 충돌이 발생하는 lock을 이미 가지고 있는 트랜잭션은 상태변화 없음
Wound-wait Scheme
- preemtive approach (선점형 방식)
- lock 충돌 발생 시, 기존에 lock을 가진 트랜잭션과 비교하여 새롭게 lock을 요구하는 트랜잭션이 old하면 wound(lock을 가진 트랜잭션을 Rollback), young하면 wait
restart 하는 transaction는 항상 원래 timestamp를 가지고 실행하여야 한다.
(livelock을 방지하지 위하여)
Deadlock detection (해결)
wait-for graph : Ti 가 Tj 의 종료를 기다리는 그래프
(wait-for 그래프에 사이클이 발생하면 데드락 발생)
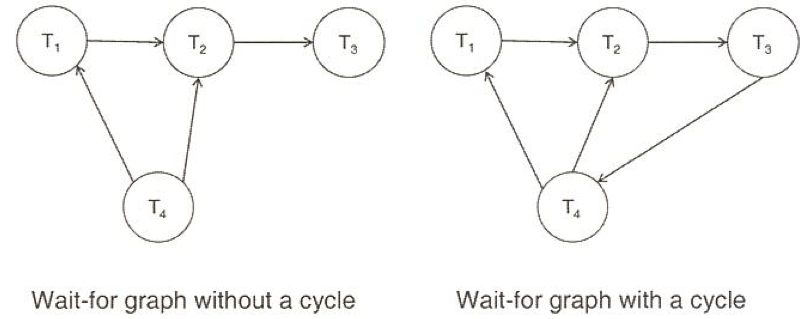
detection (해결책)
- cycle 내에 트랜잭션(victim)을 골라 Rollback
-> Rollback시 가장 cost가 적은 트랜잭션을 Rollback (total(전체)/partial(부분) Rollback) - starvation: 같은 트랜잭션만 Rollback당할 수 있음 (횟수를 계산하여...)
2.4 Insert and Delete Operations
입력, 삽입 연산은 X-lock(write lock)을 가져야 함
X-lock은 다른 lock모드와 배타적이므로 다른 트랜잭션은 새로운 tuple 또는 삭제되는 tuple을 인식하지 못함
Phantom Phenomenon (팬텀 현상)
팬텀 현상(Phantom Phenomenon) : 데이터베이스의 동시성 제어 문제 중 하나로, 트랜잭션이 실행되는 동안 다른 트랜잭션에 의해 데이터베이스의 데이터가 추가되거나 삭제되어 원래 트랜잭션의 결과가 예상과 달라지는 현상
예제
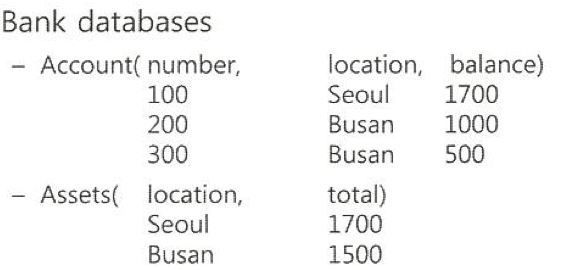
T1 트랜잭션은 Account 테이블 전체를 읽은 후에 Assets 테이블에 있는 total 값과 맞는지 비교하는 연산 수행
T2 트랜잭션은 새로운 Busan계좌<400, Busan, 700> 터플을 입력함
팬텀현상 : T1이 Account 테이블에서 모든 Busan 계좌를 읽기 하는 중간에 T2에 의하여 새로운 Busan 계좌가 입력될 가능성
- 2PL에서의 흐름
T1 : Read(Account[100], Account[200], Account[300]) // returns 1500
T2: insert(Account[400, Busan, 700])
T2 : read(Assets[Busan]) // returns 1500
T2 : write(Assets[Busan]) // writes 2200
T1 : read(Assets[Busan]) // returns 2200
- 여기서 T1 은 1500과 2200을 비교하여 둘이 다르다고 결과를 내놓음
- 위 결과는 <T1, T2> 혹은 <T2, T1> 그 어떤 것과도 결과가 다르므로 serializable 하지 않음
- table locking 을 사용하게 된다면 팬텀현상은 발생하지 않지만 concurrency 가 떨어짐

팬텀 현상 처리 (해결방안)
- insert, delete 가 있는 tuple이 없도록 (이론상 ...)
- Table lock 방식을 사용 (테이블 자체에 lock을 잡고 시작)
- Index lock 방식을 사용 (팬텀 현상 해결책으로 널리 사용되고 있음)
2PL을 Index에 적용
- Index는 B-Tree 구조와 같이 이루어지며 lock을 걸 때 대상을 타고 내려오는 부모/조상 노드(index)에도 걸도록 (S-lock, X-lock 적절히 사용)
- Two-phase locking protocol 도 적용 가능 (한번 lock을 걸면 트랜잭션 끝날때까지 유지)
- 인덱스에 2-phase locking 을 걸면 Concurrency (동시성)이 떨어짐
Crabbing 기법 (Tree 기반)
- 루트 노드에 S-lock
- 필요한 모든 자식 노드들에게 S-lock 을 걸고, 자신의 lock 은 품 (lock을 미리 풀 수 있음)
- leaf 노드에 다다르면 X-lock 으로 업그레이드
- B-Tree 특성인 Splitting(분할), Coalescing(병합)이 일어난다면 이 때는 부모 노드에 대해서도 X-lock 이 필요함
- 데드락 발생 가능성
실제 사용 시스템에서는 Index구조에 대해서는 non-serializable한 접근을 허용함
-> 트랜잭션은 latch를 활용하여 index 구조 변경 시에 배타적인 접근을 보장받음
2.5 SQL Transaction isolation
SQL 트랜잭션은 DML 문장이 나오면 암시적으로 시작 (commit work / rollback work 로 끝남)
트랜잭션에 관한 SQL 언어
set transaction
commit
rollback
savepoint (Abort 시 해당 시점으로 돌아감)
rollback to savepoint
몇 Application의 경우에는 다른 트랜잭션과 Serializable한 스케줄이 아니어도 작동 가능함
-> Read-only 트랜잭션: 대략적인 추정 결과를 내놓는 대신 성능을 향상시키는 방법 (Consistency level이 낮음)
Degree-two Consistency
- Two-phase locking protocol 은 phase 2가 되어야 unlock 이 가능
- Degree-two consistency 는 S-lock 에 한하여 중간에도 unlock 이 가능
- X-lock은 트랜잭션의 끝까지 가야함
- 트랜잭션의 serializable schedule이 보장되지 않는다.
- Cursor Stability
읽을 때만 S-lock 을 걸어버리고, 데이터의 전달이 마무리되면 S-lock 을 품
-> (Data가 read에 놓여져 있을 때 (Cursor가 stable 함))
- Cursor Stability
SQL Isolation level
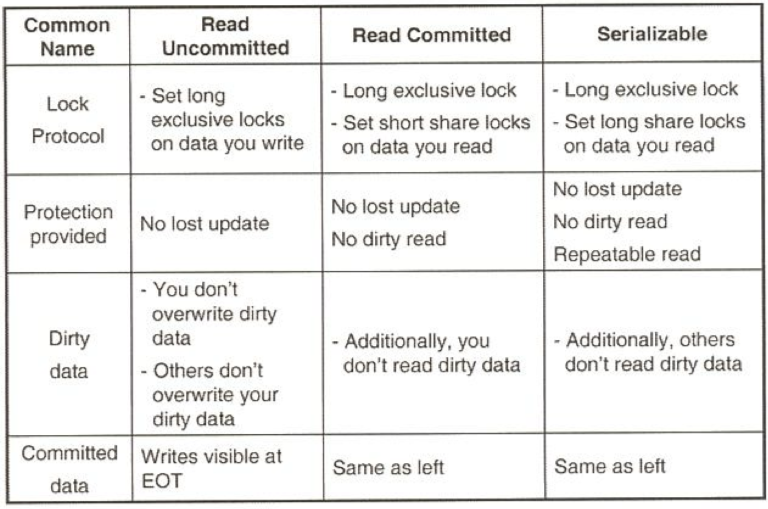
Dirty read, Non repeatable read, Phantom read와 같은 현상이 발생하지 않게 하면 DB에 제약사항이 많아지게 됨
이는 DB의 전체 처리량(throughput)의 하락을 일으킬 수 있음.
따라서 일부 이상한 현상은 허용하는 level을 만들어두고 사용자(개발자)가 이를 선택하여 사용할 수 있도록 함.
Dirty read : 오손 읽기
Non repeatable read : 같은 레코드를 반복해서 읽을 때 그 사이에 다른 트랜잭션에 의해 수정 또는 삭제되어 처음 읽었던 값과 달라지는 현상
Phantom read: 트랜잭션이 조건에 맞는 레코드를 여러 번 조회할 때, 그 사이에 다른 트랜잭션이 조건에 맞는 새로운 레코드를 삽입하거나 삭제하여 조회 결과의 레코드 수가 달라지는 현상
-
Serializable
default = 가장 강함 (직렬가능 실행)
Dirty read, Non repeatable read, Phantom read를 모두 허용하지 않고, 아예 이상한 현상 자체가 발생하지 않음 -
Repeatable read
commit 된 레코드만 읽을 수 있으므로 Consistency 를 보장
Dirty read, Non-repeatable read를 허용하지 않지만
[Phantom read]를 허용함 -
Read committed
degree two consistency 를 사용
commit된 것만 읽으나 S-lock 을 바로 풀어버려서 문제의 여지가 있음 -> 여러 번 읽으면 다른 결과를 리턴할 수 있음
Dirty read는 허용하지 않지만
[Non repeatable read, Phantom read]를 허용함
일반적인 상업 DB의 기본 -
Read uncommitted
commit안된것도 읽음(Read only인 경우에만 사용)
[Dirty read, Non repeatable read, Phantom read] 를 모두 허용하여 이상한 현상들에 가장 취약하지만 동시성이 높아져 처리량이 높아짐

Set transaction (read only | read write)
isolation level (Serializable | repeatable read | read committed | read uncommitted);
Transaction Isolation Effect
Transaction Isolation 예제
Read uncommitted
읽은 값 자체가 vaild 하지 않음(믿을 수 없음)
자리가 있다고 했는데 없을 수도, 없다고 했는데 있을 수 있음read committed
lock을 중간에 풀기 때문에 자리의 승인/변경 하는 순간에 타인이 자리를 차지할 수 있음repeatable read
한번 읽은 값을 트랜잭션 끝까지 유지되므로 사용자가 승인 후에 실제 값 변경
트랜잭션 중간에 생기는 새로운/제거되는 자리는 인지 못함

2.6 SnapShot Isolation
Multiversion Schemes (locking의 다중버전 기법)
- Multiversion timestamp ordering
- Multiversion two-phase locking
(timestamp : 시간의 흐름에 따라 값이 증가하는 성질을 가지고 있음)
multi-version timestamp ordering
- w-timestamp : 쓰기 버전 타임스탬프
해당 버전을 생성한 트랜잭션 / 해당 버전에 새로운 값을 쓴 트랜잭션의 timestamp 값- r-timestamp : 읽기 버전 타임스탬프
해당 버전의 값을 읽은 가장 최근(가장 마지막에) 트랜잭션 timestamp 값
Q1 : T5가 마지막으로 생성/쓰기 를 하고, T7이 마지막으로 읽음
Q2/Q3 : 각각의 트랜잭션이 생성/쓰기를 하며, 읽음TS(Ti) = N (Ti의 timestamp N)
write에서 N보다 작은 것 중에 가장 큰 content를 읽고 싶은 것
-> 시스템에 들어온 순서대로 일을 하게 하고 싶은 것예제
- T12가 들어와서 Q2값을 read/write?
Q2는 write=10, read=10 (둘다 12보다 작음(오래된 트랜잭션))이므로 이상없음
- T6이 들어와서 Q1값을 read/write?
read 는 상관없음, write는 T6이 rollback
(T7이 이미 읽은 것에 T6이 그 이전의 Q1 값을 읽고 바꾸는 것임으로 허용되지 않음)
쓰기 연산이 너무 늦은 경우에 해당되는데, 트랜잭션 Ti가 다른 젊은(young)트랜잭션이 이미 읽은 버전값을 다른 값으로 갱신하려고 하는 경우, 갱신을 허용하지 않고 대신 Ti가 rollback한다TS(Ti) < R-timestamp(Qk)
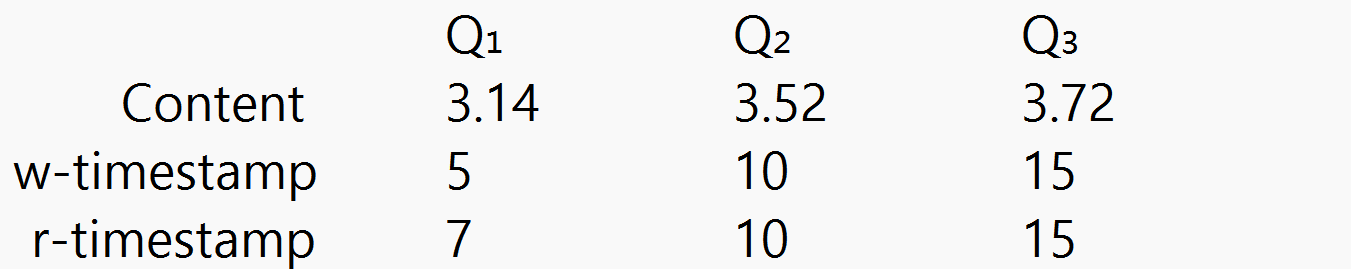
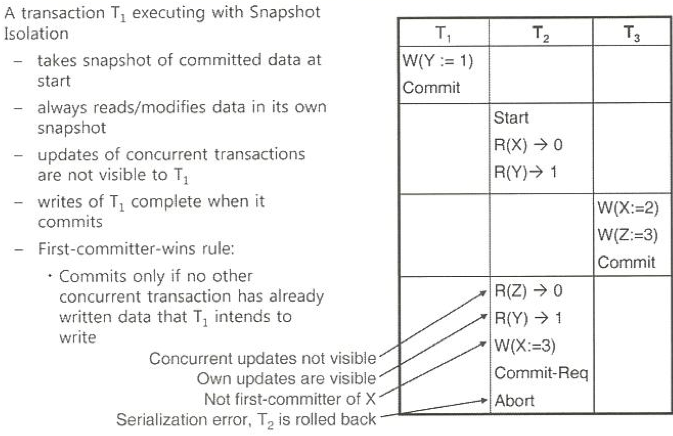
SnapShot Isolation
트랜잭션이 시작되는 시점의 DB 'Snapshot'을 해당 트랜잭션에게 제공
트랜잭션은 해당 Snapshot에 대해서만 read/write 작ㅇㅂ을 수행
트랜잭션이 데이터를 갱신/완료 하면?
타 트랜잭션과의 충돌 여부를 판단하는 검증과정 수행
예제
스냅샷 읽기 예제
7번연산에서 T2가 X를 50으로 갱신했음에도 100으로 read 함
번 연산에서 T1이 Y를 50으로 갱신했음에도 T1은 50으로 read 반면, T2는 0으로 read 함
(Snapshot시점에서 본인 트랜잭션만 고려하여, 갱신 값을 보지 못함으로)
Start = Snapshot
X -> 0 / Y -> 1 로 T2가 Read
X := 2 / Z := 3 으로 T3가 write 후 commit 하여 나감 (locking-based였다면 이 시점에 update 되었을 것)
Z -> 0 로 T2가 Read (T3의 갱신을 보지 못함)
Y -> 1 로 T2가 Read (본인의 갱신임으로 볼 수 있음)
X := 3 으로 T2가 write (T3가 write 후 commit 하여 나갔으므로 'first-committer-wins'규칙에 의해 T2가 rollback)
Commit-Req (Commit 후 검증 -> 누구를 commit하고, 누구를 rollback할 것인가)

First-commiter-wins / First-updater-wins
- First-commiter-wins
우선 commit한 트랜잭션이 살아남고, 타 트랜잭션이 rollback - First-updater-wins
해당 값을 첫 update한 트랜잭션이 살아남고, 타 트랜잭션이 rollback
SnapShot Isolation의 비직렬가능 수행
같은 element를 write하지 않아서 검증에서 기각당하지 않음 (잘못된 경우) -> write skew
write skew : 서로다른 데이터에 write했음에도 결국 inconsistency(일관성 없음)
(일반적으로 발생하지 않고, 이론상 가능한 문제임)
DB 시스템은 select하는 데이터를 마치 update하는 데이터로 취급함
-> 스냅샷 고립 문제점의 해결책 (일단 가져가는데 후에 갱신 하겠다 ...)
-> select .. for update

