
3.1 장애 및 복구
Failure(장애)
-
트랜잭션 장애: 트랜잭션 수행 오류
Logical errors, System errors (교착 상태에 있는 트랜잭션 중 철회되는 트랜잭션에게 발생하는 장애) -
시스탬 장애 (crash): 하드웨어의 결함으로 인한 오류
휘발성 기억 장치인 주기억 장치 메모리에 문제가 발생하여 메모리 내용이 사라지는 경우 -
디스크 장애: 디스크 장치 결함(하드웨어 및 소프트웨어 결함으로 인해)
장애는 아무 위치에서 아무 시간에 발생
트랜잭션의 ACID성질(특히 원자성, 일치성, 지속성)을 지원하기 위하여 복구 기법은 필요함
Recovery(복구) 알고리즘
정상 상태에서 시스템 복구를 대비하기 위하여 수행되는 연산
장애가 발생하였을 때 복구하기 위하여 수행하는 연산
Storage(저장장치)
-
휘발성(Volatile) 저장 장치
system crash에서 생존 불가 -
비휘발성(Nonvolatile) 저장 장치
system crash에서 생존 -
안전(Stable) 저장 매체
어떠한 장애에서도 저장 내용이 상실되지 않는 가상적인 저장매체
-> 다수 개의 하드디스크에 저장 내용을 체계적으로 중복 분산 복사 및 유지
-> 안전 저장 매체에 대한 가정으로 복귀 기법을 기술하기 위한 최소한의 안정성을 기대
Stable-storage Implementation (안정 저장 매체 구현)
디스크 읽기, 쓰기 연산에서 오류가 발생하면 안됨
- 동일 블록을 중복적으로 저장/관리하는 방식을 사용
- 중복 장소에 동일 블록 쓰기 연산이 성공적으로 종료하여야 쓰기 연산이 완료
- RAID 저장 시스템
RAID (Redundant Array of Independent Disks)
여러 개의 하드 드라이브를 하나의 배열로 묶어 데이터의 성능과 안정성을 향상
-> 성능 향상, 데이터 안정성, 가용성
각 level은 데이터의 분산, 중복, 오류 복구등을 다르게 조합함- RAID 0: 데이터 스트라이핑을 사용, 중복이 없음
한 드라이브가 손상되면 전체 데이터가 손실됩니다. - RAID 1: 미러링을 통해 데이터를 복제
디스크가 손상되어도 데이터 복구가 가능합니다. - RAID 5: 최소 3개의 디스크, 패리티 정보를 분산 저장하
성능과 안정성을 모두 보장하는 구조입니다. - RAID 6:패리티를 두 번 저장 (P+Q)
- RAID 10 (1+0): RAID 0의 성능과 RAID 1의 안정성을 결합한 구조
- RAID 0: 데이터 스트라이핑을 사용, 중복이 없음
Disk I/O는 원자성(atomic)을 가져야 함
복구(recovery) 관점에서 모든 디스크 I/O는 원자성을 가져야 함
읽기 연산은 데이터베이스에 큰 손상을 주지 않음
쓰기 연산이 일부분만 수행되면 후에 시스템 복구를 함에 있어 많은 문제점을 야기
RAID 저장시스템에서 하드웨어 지원으로 원자성 I/O을 지원
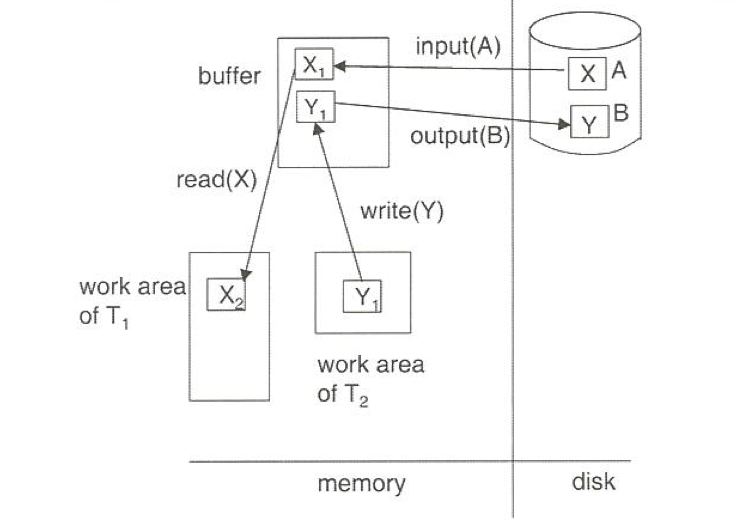
데이터 위치
<< 데이터가 위치할 수 있는 공간 >>
- 디스크 블록
- 메인 메모리 상의 데이터 버퍼 블록
- 트랜잭션 프로세스 메모리 영역
디스크 블록과 메인 메모리 버퍼 블록 간 이동
- 입력(B): 디스크의 물리적 블록 B를 메모리로 전송
- 출력(B): 메모리의 버퍼 블록 B를 디스크로 전송하여 영구 저장 (필요 시 수행)
트랜잭션 작업 영역과 시스템 버퍼 블록 간 이동
- 트랜잭션은 개인 작업 영역에서 로컬 사본을 조작함
- 읽기(X): 데이터 항목 X의 값을 로컬 변수에 저장
X가 메모리에 없으면: 입력(Bx) 명령어로 블록 Bx를 메모리로 불러옴 - 쓰기(X): 로컬 변수 값을 버퍼 블록의 데이터 항목 X에 저장
X가 메모리에 없으면: 입력(Bx) 명령어 발행 가능
출력 작업 타이밍
- 출력(Bx)는 쓰기(X) 직후 바로 수행할 필요 없음, 시스템이 적합한 시점에 수행
데이터 버퍼와 프로세스 메모리 영역은 메인메모리 내에 존재
-> 메인 메모리가 고장이 나는 경우에 디스크에 존재하는 데이터는 손상이 없음
프로세스 고유 영역에서 버퍼 블록으로 데이터를 이동하는 것은 사용자의 요청으로 진행
데이터 버퍼에서 디스크로 데이터를 이동하는 것은 운영체제의 결정으로 진행
데이터 쓰기를 완료하는 것은 데이터 버퍼에 쓰기임을 인지하여야 함
-> 쓰기 완료 후에 시스템 장애가 발생하면 디스크에는 갱신이 반영 안되었을 수 있음
-
데이터는 디스크에 존재, 필요시 DBMS에 의해 시스템 버퍼에 블록 단위로 복사 (input 연산)
(시스템 버퍼에 있는 데이터를 사용자 트랜잭션이 직접 사용하지 않음 -> 복사(read 연산)로 접근) -
사용자가 write 연산을 사용하여 사용자 영역 데이터를 시스템 버퍼에 복사
(DBMS의 output 연산) -
가장 정확한(= Recently) 데이터 값은 사용자 영역에 존재하는 데이터 값임
3.2 로그
복구 기법
log-based recovery
shadow-paging
복구 및 원자성을 위해 DB상 변화가 일어나기 전에 변화에 대한 정보를 안전저장장치에 미리 기록하는 행위
-> 특히, 로그 방식에서는 변화가 발생하기 전에 먼저 안전장치에 기록함
Shadowing (그림자 기법)
- 원자성과 내구성을 지원하는 매우 간단한 트랜잭션 기법
- 에디터와 같은 간단한 응용에서 사용 (데이터베이스 환경에서는 사용하지 않음)
- 데이터 클러스터를 원천적으로 제공하지 못함
- 동시 트랜잭션이 많은 경우 그림자가 많이 생성되는 문제 발생
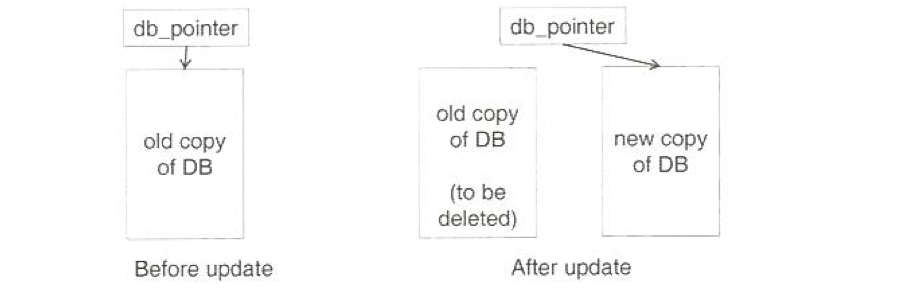
- 모든 업데이트는 데이터베이스의 shadow 사본에서 진행
DB_pointer는 트랜잭션이 부분 커밋에 도달하고 모든 업데이트 된 페이지가 디스크로 flush된 후 업데이트 된 사본을 가리킴 - DB_pointer는 항상 데이터베이스의 일관된 사본을 가리킴
트랜잭션 실패 시, do_pointer가 가리키는 오래된 사본을 사용하고 그림자 사본을 삭제할 수 있음
- 모든 업데이트는 데이터베이스의 shadow 사본에서 진행
Simple Logging (간단 로깅)
간단 로깅: 정상처리 (Normal Processing)
데이터 항목에 대하여 연산 전의 값과 연산 후의 값을 기록하는 방식
WAL: Write-Ahead-Logging
로그에 기록을 먼저 남겨 데이터 무결성과 복구를 보장
- 트랜잭션 시작 시
<T, start> 로그 기록: 트랜잭션 T가 시작됨을 기록
- 쓰기 작업 수행 전
쓰기 전 로그 기록: <Ti, X, V1, V2>
Ti가 데이터 항목 X에 대해 쓰기 작업을 수행했음을 기록
V1: 쓰기 이전 X의 값
V2: 쓰기 이후 X의 값
이 로그는 트랜잭션이 데이터 항목 X를 업데이트하면서 이전 값(V1)과 새 값(V2)를 기록하여, 나중에 복구 시 해당 정보를 사용 가능
- 트랜잭션 종료 시
<.Ti commit> 로그 기록: Ti의 마지막 문장이 실행되었음을 기록, 즉 트랜잭션이 성공적으로 완료됨
log는 안전장치(Stable storage)에 기록
-> 손실되는 경우를 없게 하기 위함
여러 트랜잭션이 동시에 실행됨
모든 트랜잭션이 하나의 디스크 버퍼와 하나의 로그를 공유
(버퍼 블록: 여러 트랜잭션이 업데이트한 데이터 항목을 포함)
동시성 제어 (strict 2PL 사용)
: 트랜잭션 종료시에 쓰기 록을 해제하는 방식
- 미완료 트랜잭션의 업데이트는 다른 트랜잭션에서 보이지 않도록 함
- 다른 트랜잭션이 변경 사항을 보지 못하게 하여 데이터 일관성 유지 및 롤백(undo) 문제 해결
ex) T1이 X를 업데이트한 후 T2가 X를 업데이트하고 커밋하면, T1이 취소될 때 T2의 커밋 내용과 충돌할 수 있음 (undo 시 문제 발생 방지)
-> 쓰기 록을 트랜잭션 중간에 해제하면, 다른 트랜잭션이 동일 데이터를 일고 쓰기한 후 commit하고 원래 트랜잭션이 abort하면 회복 불가능한 상태가 됨
로그 기록: 서로 다른 트랜잭션의 로그 기록이 혼재되어 나타날 수 있음
간단 로깅: 검사점 (Checkpoint)
복구 절차의 문제점
- 전체 로그를 검색하는 작업이 시간이 오래 걸림
- 이미 데이터베이스에 기록된 트랜잭션을 불필요하게 재실행할 수 있음
검사점(Checkpointing)을 통한 복구 절차 간소화
(주기적으로 검사점을 수행하여 복구 절차를 간소화함)
- 메인 메모리에 있는 모든 로그 기록을 안정 저장소에 출력
- 수정된 데이터 버퍼 블록을 디스크에 출력
- 검사점 시점의 활성 트랜잭션 목록 L을 포함한 ‹ checkpoint L > 로그 기록을 안정 저장소에 기록
검사점의 효과
- 복구 시 검사점 이후의 로그만 검색하여 복구 시간을 단축
- 불필요한 redo 작업을 줄이고, 필요한 부분만 복구하도록 지원
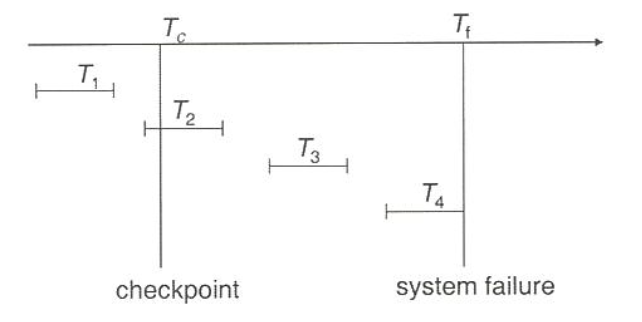
T1: 연산이 이미 디스크에 반영되어 있음 (검사점 연산으로 인해)
-> 더이상의 복구 연산이 필요 없음
T2, T3: 필요에 따라서는 재연산 수행 (Redo)
-> write 반영되지 않음
T4: 중간에 failure 발생으로 완료하지 못함 수행한 연산을 되돌려야 함 (Undo)
-> 본인이 abort
간단 로깅: 복구 (Recovery)
복구 초기화
- undo-list와 redo-list를 빈 상태로 초기화
- 로그 역방향 스캔을 시작하여 마지막 <.checkpoint L> 기록을 찾음
- 로그 스캔 중 트랜잭션 분류
<T, commit> 기록 → redo-list에 추가
<T, start> 기록 → redo-list에 없다면 undo-list에 추가
checkpoint 시점의 트랜잭션 L 중 redo-list에 없는 트랜잭션은 undo-list에 추가
복구 절차의 목적
- 장애 발생 시, 손실된 메모리 데이터를 로그와 디스크에 남은 기록으로 복구
- undo-list: 완료되지 않은 트랜잭션을 포함 → UNDO(원상 복구) 필요
- redo-list: 완료된 트랜잭션을 포함 → REDO(다시 수행) 필요
복구 실행 단계
(1단계: Undo 수행)
- 최근 기록부터 역방향 스캔을 진행하여 undo-list의 모든 트랜잭션의 <T, start> 기록을 찾을 때까지 스캔
- 스캔 중 undo-list에 포함된 트랜잭션의 로그 기록 발견 시 undo 작업을 수행하여 데이터를 원상 복구
(2단계: Redo 수행)
- <.checkpoint L>부터 순방향 스캔을 시작하여 로그 끝까지 스캔
- 스캔 중 redo-list에 포함된 트랜잭션의 로그 기록 발견 시 redo 작업을 수행하여 완료된 트랜잭션을 재실행
간단 로깅 방식은 장애 발생 시 복구 기법의 기본 개념을 쉽게 이해하도록 돕기 위함
실제 복구에서는 다양한 추가 기법이 사용될 수 있음
간단 로깅 예제

redo-list와 undo-list를 구성할 때에는 가장 최근 시점에서 로그를 역방향으로 스캔
Undo 연산은 가장 최근 로그부터 역방향으로 진행 (가장 최근 검사점을 지날 수 있음)
Redo 연산은 가장 최근 검사점부터 순방향으로 진행 (재연산을 수행함)
3.3 데이터 버퍼
Buffer Management
디스크 접근의 연산이 비싸 디스크 접근을 블록단위로 하기 위함
- 블록(Block): 고정 길이의 저장 단위로, 데이터베이스 파일을 구성하며 저장 공간 할당과 데이터 전송의 단위
- 디스크 전송 최적화: 데이터베이스 시스템은 디스크와 메모리 간의 블록 전송 횟수를 최소화하려고 함
- 버퍼(Buffer): 메인 메모리에서 디스크 블록 복사본을 저장할 수 있는 공간
- 버퍼 관리자(Buffer Manager): 메인 메모리 내 버퍼 공간 할당을 관리하는 하위 시스템
버퍼 관리 동작 절차
데이터가 버퍼에 존재할 경우
- 버퍼 관리자에서 버퍼 블록을 사용자에게 반환하여 디스크 접근을 피함
데이터가 버퍼에 없을 경우
- 디스크에서 해당 블록을 읽어와 버퍼에 저장하고, 사용자에게 반환
- 이때, 새로운 블록을 위한 공간이 필요하면 기존 블록을 교체(삭제)하여 공간을 확보
교체된 블록이 수정된 경우 디스크에 쓰기 연산을 수행하여 변경사항을 기록함
Buffer-Replacement Policies
버퍼에 더 이상 가용한 블록 공간이 없을 때 가용한 블록 공간을 만들기 위해서 메모리상에 이미 존재하는 블록을 선택하는 정책
선택된 버퍼는 더 이상 메모리 버퍼 공간을 차지하지 않고, 내용이 변경되었으면 디스크에 반영하여야 함
LRU (Least Recently Used) 전략
- 가장 오래된 참조 블록을 교체하는 방식
- 과거 블록 참조 패턴을 바탕으로 미래 참조를 예측하는 방법
- 운영체제에서 주로 사용되며, 데이터베이스 쿼리의 순차적 스캔과 같은 일정한 접근 패턴이 있는 경우 효과적임
LRU의 한계
특정 접근 패턴(예: 반복 스캔)에서는 LRU가 비효율적일 수 있음
ex) 블록 중첩 루프 조인
두 릴레이션(r과 s) 간의 중첩 루프 조인에서는 반복 스캔이 발생하여 LRU가 적합하지 않음
혼합 전략의 필요성
Query optimizer가 제시하는 교체 전략 힌트를 반영하여 혼합 전략을 사용하는 것이 효율적
반복 스캔이 필요한 경우 LRU 대신 다른 전략을 사용하여 성능 최적화
Toss-immediate 전략
- 블록의 마지막 tuple을 처리한 즉시 해당 블록을 버퍼에서 해제
- 효율적인 메모리 사용에 도움을 주며, 불필요한 블록이 버퍼에 오래 머물지 않도록 함
MRU (Most Recently Used) 전략
- 가장 최근에 사용된 블록을 교체하는 방식
- 반복 스캔이 필요한 경우, 예를 들어 같은 블록을 여러 번 읽는 경우에 효과적임
히스토릭 데이터 유지
- 참조 빈도가 높은 블록은 버퍼에 상주시켜 성능을 높임
ex) 데이터베이스에서 자주 사용되는 데이터 사전 블록은 버퍼에 상주시킴으로써 빠른 접근을 보장
강제 블록 출력 (Forced Output)
- DBMS가 원하는 시점에 특정 블록을 디스크에 즉시 쓰는 flushing 기능을 제공해야 함
- 복구 목적으로 필요한 경우 블록을 강제로 디스크에 기록
- 데이터 일관성과 안정성을 유지
Data Page Buffering
데이터베이스는 메모리 내 데이터 블록 버퍼를 유지하여 성능을 최적화
WAL (Write-Ahead Logging)
- 블록이 커밋되지 않은 상태로 디스크에 기록될 경우, 해당 업데이트의 Undo 정보를 로그에 먼저 기록
- 로그에 기록 후 디스크로 데이터를 출력하는 Write-Ahead Logging 기법을 사용하여 복구를 보장
Pinned Block
- 특정 트랜잭션이 블록을 독점적으로 접근할 때 발생
ex) 디스크에 블록을 flush하거나 블록을 읽거나 쓰기할 때 블록이 pinned 상태로 고정됨 - 블록이 pinned 상태일 때는 갱신 작업이 수행되지 않도록 보호가 필요함
- 데이터를 기록하기 전에 트랜잭션이 해당 블록에 대해 배타적 잠금(exclusive lock)을 획득하여 동시 수정 방지
-> 쓰기 작업 완료 후 잠금 해제
Latch와 Lock의 차이점
Latch: 운영체제에서 제공하는 기능으
짧은 시간 동안 배타적으로 블록을 보호하여 교착 상태를 방지하도록 설계됨Lock: 데이터베이스 시스템에서 동시성 제어를 위해 관리하는 기능
다양한 Lock 모드가 존재하며, Latch보다 유지 시간이 길고 교착 상태 가능성 존재
운영체제의 Latch를 사용하여 Lock을 구현
블록을 디스크에 기록할 때 Latch를 사용하여 다른 트랜잭션이 해당 블록을 수정하지 못하도록 Pin하여 보호
데이터베이스 시스템에서 교착 상태를 최소화하고 효율적 동시성 제어를 위해 Latch와 Lock을 적절히 조합하여 사용
데이터베이스 버퍼 구현 방식과 장단점
-
할당 받은 메인 메모리 영역에 데이터베이스 버퍼를 구현
Pros
데이터베이스 전용 메모리 공간을 확보하여 고정된 버퍼 공간 사용
Cons
메모리를 사전에 파티셔닝해야 하므로 유연성이 제한됨
데이터베이스와 애플리케이션 간의 메모리 요구 변화에 유연하게 대응할 수 없음 -
가상 메모리에서 데이터베이스 버퍼를 구현
Pros
운영체제가 메모리 분할을 동적으로 관리하므로 유연한 메모리 사용 가능
Cons
운영체제가 최적의 메모리 분할을 알고 있더라도 고정 파티션을 동적으로 변경할 수 없음
가상 메모리상에 데이터 페이지 버퍼 구현
데이터베이스 버퍼는 가상 메모리에 구현되며, 운영체제의 메모리 관리 기능을 사용
Dual Paging(이중 페이징) 문제
-
운영체제가 수정된 페이지를 스왑 공간으로 내보낼 때, 데이터베이스 버퍼 페이지가 스왑에 저장될 수 있음
-
추가 I/O 발생: 데이터베이스가 해당 페이지를 디스크에 쓰려고 할 때, 스왑에서 다시 읽어온 후 데이터베이스에 저장해야 하므로 불필요한 I/O가 발생함
-
이상적인 해결 방법: 운영체제가 페이지를 제거할 때 데이터베이스에 제어권을 넘겨 직접 데이터베이스 디스크로 출력하게 함
수정된 페이지라면 로그 레코드를 먼저 출력한 후 디스크로 데이터 전송
이후 운영체제가 해당 페이지를 버퍼에서 해제하여 메모리를 재활용 가능하게 함
일반적인 운영체제는 이중 페이징 문제를 피하는 기능을 제공하지 않음
Slotted Page Structure
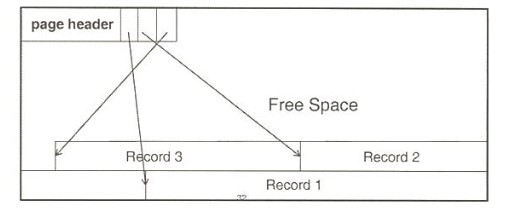
데이터 베이스 시스템에서 가장 널리 사용되는 페이지 구조 (가변길이 레코드 지원)
페이지 헤더가 나오고, 정해진 수의 slot이 나옴,
각 slot은 페이지에 저장되는 레코드의 주소를 가짐
페이지 헤더에 저장될 수 있는 정보
페이지 id
소유자
여부공간
페이지 마지막 수정 시간
본 페이지와 관련된 로그 페이지 id
...
페이지 내 레코드의 이동이 자유로움
레코드의 물리적 위치가 변경되면 slot번호는 동일하고 그 속의 페이지 주소만 변경
외부에서 페이지 고유 번호와 slot번호만을 가지고 접근
페이지 크기 보다 큰 레코드는 지원하지 않음
clob/blob필드는 별도로 저장/관리하고 포인터 값만 페이지에 저장
Steal/Force 방식
데이터 버퍼 관리는 복구 기법과 밀접하게 관련
Force 정책
- 트랜잭션이 커밋 시 수정된 블록을 디스크에 즉시 기록하는 방식
Pros: 커밋 후 디스크에 데이터가 반영되어 복구가 간단
Cons: 커밋 시 비용 증가로 인해 성능 저하 가능
Not-Force 정책
- 정책: 트랜잭션이 커밋될 때 수정된 블록을 디스크에 즉시 기록할 필요가 없음
Pros: 커밋 시 비용이 적어 효율적
Cons: 복구 시 커밋된 데이터를 디스크에 반영하는 추가 작업 필요
Steal 정책
- 커밋되지 않은 트랜잭션이 수정한 블록도 디스크에 기록 가능
Pros: 메모리 공간 절약 가능
Cons: 복구 시 커밋되지 않은 트랜잭션 데이터를 롤백해야 하는 추가 복구 작업 필요
Steal/Force의 4가지 방식

실질적으로는 Steal/Not Force 방식 사용
-
Not Steal 방식의 문제점
페이지 버퍼 용량이 초과하는 많은 수의 데이터 페이지를 변경하는 트랜잭션이 수행되면 기능상의 문제 발생 -
Force 방식의 문제점
트랜잭션이 완수될 때 마다 모든 로그가 안전 저장 장치에 저장되어야 함 -> 성능상의 문제를 야기
3.4 로그 기반 복구
Log Block Buffering
LRU은 데이터 블록 버퍼링에서만 적용되며, 로그 블록에는 적용되지 않는다
-
로그 기록의 블록 메모리 버퍼링
버퍼가 가득 차거나 log force(로그 강제)연산이 실행될 때 stable storage(안전 저장소)로 저장
(log force: 트랜잭션을 커밋하기 위해 해당 트랜잭션의 모든 로그 기록(커밋 기록 포함)을 안정 저장소로 강제 저장) -
Group Commit
로그 블록 쓰기 연산은 시간이 소요되는 연산이므로 효율성을 위해서 사용
다수개의 로그 레코드가 로그 블록에 거의 차지할 때까지 기다렸다가 한번에 commit
로그 기록 버퍼링 시 필수 규칙 요약
-
로그 기록 순서 유지
로그 기록은 생성된 순서대로 안정 저장소에 기록되어야 함 -
커밋 조건
트랜잭션 T는 <.T commit> 로그 record가 안정 저장소에 먼저 기록된 후에만 데이터 페이지가 디스크에 저장 -
데이터 블록 출력 조건 (WAL 규칙)
버퍼의 데이터 블록이 디스크로 출력되기 전에 해당 블록과 관련된 모든 로그 기록이 안정 저장소에 먼저 기록되어야 함
undo하는 information도 같이 내려옴 (redo도 보통 같이 옴)트랜잭션이 완수되기 전에 완수 로그 레코드가 미리 안전 저장 장치에 저장되어야 함
데이터 페이지가 디스크에 저장되기 전에 관련 로그 레코드가 안전 저장 장치에 저장되어야 함
-> 시스템 crash가 나도 회복하기 용이하기 위함(아니라면 Data page가 어떻게 변경된지 알 수 없음)
Recovery Algorithm
로그 기록 (정상 상태에서)
- <.Ti start>: 트랜잭션 시작 시 기록
- <Ti, Xj, V1, V2>: 트랜잭션 업데이트 시 기록
V1: 업데이트 전 값, V2: 업데이트 후 값 - <.Ti commit>: 트랜잭션 종료 시 커밋 기록
트랜잭션 롤백 (정상 상태에서)
- 롤백할 트랜잭션 Ti를 선택하여 로그를 역방향 스캔 (최근 -> 오래된)
- <Ti, Xj, V1, V2> 형태의 로그 기록을 찾으면 V1을 X에 기록하여 undo 작업 수행
- 이때 <Ti, Xj, V1> 형태의 보상 로그 기록(CLR; Compensation Log Record)을 작성하여 undo 작업을 기록
("Ti는 Xj를 V1로 다시 바꾸었습니다"라는 log record)
<.Ti start> 로그를 찾으면 스캔을 중단하고 <.Ti abort> log record를 작성하여 트랜잭션이 철회되었음을 표시
CLR(Compensation Log Record): Undo 작업 시 생성되는 로그 기록으로, 롤백 과정 중 수행된 변경 사항을 추적
복구 단계
1) Redo 단계: 모든 트랜잭션의 업데이트를 재실행 (커밋 여부와 관계없이 모든 트랜잭션 포함)
2) Undo 단계: 미완료된 트랜잭션의 작업을 취소하여 원상 복구
Redo Phase
- 가장 최근 <.checkpoint L> 기록을 찾아 undo-list를 L로 초기화
- <.checkpoint L> 이후부터 로그를 순방향으로 스캔하며 다음을 수행
<Ti, Xj, V1, V2> 로그 발견 시: V2를 Xj에 기록하여 해당 작업을 무조건적으로 재실행(Redo)
<.Ti start> 로그 발견 시: T를 undo-list에 추가
<.Ti commit> 또는 <.Ti abort> 로그 발견 시: Ti를 undo-list에서 제거
-> Checkpoint 이후에 모든 연산을 다시 하는 것
Undo Phase
-
로그를 끝에서부터 역방향으로 스캔하며 미완료 트랜잭션의 작업을 취소
-
<Ti, Xj, V1, V2> 로그가 발견되고 T가 undo-list에 포함된 경우
(->V1을 X에 기록하여 Undo 작업 수행):
<Ti, Xj, V1> 형태의 보상 log record(CLR) 작성하여 Undo 작업을 기록 (Ti는 Xj를 V1값으로 환원 시켰음) -
<.Ti start> 로그가 발견되고 T가 undo-list에 포함된 경우:
<.Ti abort> log record하여 트랜잭션 철회 표시, T를 undo-list에서 제거
-> undo-list가 비워질 때까지 반복 (모든 미완료 트랜잭션의 <.Ti start> 로그를 찾을 때까지)
Repeating History
데이터 베이스의 모든 연산의 history를 repeating 하는 것으로 Redo를 먼저 실행하는 것
-> 좋은 아이디어
Recovery Algorithm 예제
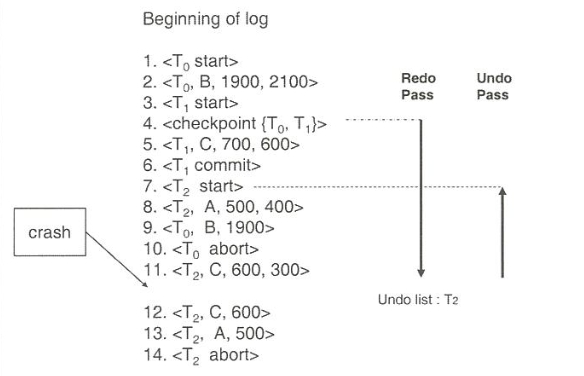
Fuzzy Checkpointing (퍼지 검사점)
checkpoint 중에도 업데이트를 허용하여 정상적인 트랜잭션 처리 중단을 최소화
(보통 checkpoint 중에는 normal processing 이 모두 stop 됨)
- 모든 트랜잭션의 update 일시적 중단
- modified 된 buffer block list인 M을 만들고 기록
- 트랜잭션은 update 다시 재개
- List M에 있는 모든 modified된 buffer block 출력 (출력 중에는 update 중단)
- 디스크의 고정된 위치에 마지막 <.checkpoint> 기록 위치 포인터 ("last_checkpoint") 저장
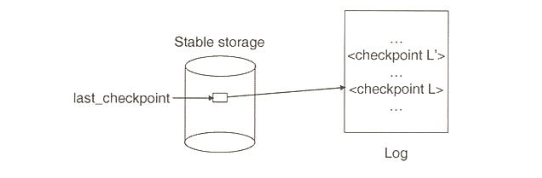
-> last checkpoint에 저장되어 있는 검사점 log record를 확인하고 이후부터 처리하면 됨
Failure of Nonvolatile Storage (비활성 저장장치 장애)
DB 전체 상태(log record 포함)를 주기적으로 안정 저장소에 Dump 시킴
덤프 절차
- 체크포인트와 유사한 과정을 통해 모든 데이터를 안정적으로 저장
- 메모리에 있는 모든 로그 기록을 안정 저장소에 출력
- 모든 버퍼 블록을 디스크에 기록
- 데이터베이스의 전체 내용을 안정 저장소에 복사
안정 저장소에 <.dump> 로그 기록을 남겨 덤프 완료를 표시
덤프 절차 동안 활성 트랜잭션이 없어야 함
복구절차
최근 덤프 파일을 이용하여 데이터베이스 복원
로그를 확인하여 덤프 이후 커밋된 트랜잭션을 모두 재실행 (Redo)하여 최신 상태로 복구
온라인 덤프 (Fuzzy Dump)
덤프 과정 중에도 트랜잭션이 활성 상태로 진행 가능
장애 발생 시에도 실시간 복구를 지원할 수 있음
3.5 ARIES 알고리즘
- 최신 복구 기법으로, IBM의 C. Mohan이 연구한 알고리즘
- Write-Ahead Logging (WAL) 적용
- Not-Force/Steal 정책 지원:
데이터가 커밋 시 즉시 디스크에 기록되지 않으며, 미완료 트랜잭션의 변경 사항도 디스크에 기록 가능- 복구 속도 및 처리 성능 최적화를 위한 다양한 최적화 기법 포함
- 대부분의 상용 시스템에 널리 구현되어 운영
ARIES 알고리즘의 특성
-
Log Sequence Number (LSN)
각 로그 기록을 식별하는 번호로, 페이지에 LSN을 저장하여 어떤 업데이트가 이미 적용되었는지 추적 -
Repeating History에 기반
복구 과정에서 정상 처리 중 발생한 작업을 정확히 동일하게 재실행 -
Physiological Redo
데이터 페이지 수준에서 Redo 작업 수행 -
Dirty Page Table
복구 시 불필요한 Redo 작업을 방지 -
Fuzzy Checkpointing
더티 페이지 정보만 기록하고, 체크포인트 시 더티 페이지를 디스크에 기록하지 않음
3.6 Remote Backup (원격 백업)
Disaster가 나는 경우에 어떻게 복구할 것인가?
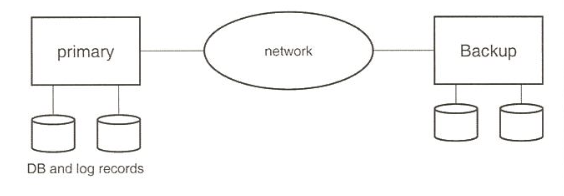
시스템 장애 시간을 최소화하게 하는 가용성(availability)이 높은 시스템을 요구
원격 백업 시스템은 주(primary) 사이트에 재난이 발생하여도 백업 사이트가 계속 수행하여 시스템 가용성을 증가시킴
1. 장애 감지
- 백업 사이트는 주 사이트의 장애를 감지해야 함
- 여러 통신 링크를 통해 주 사이트와 백업 사이트 간의 연결을 유지하며 Heart-beat 메시지로 상태 확인
2. 제어 권한 전환
- 백업 사이트가 제어를 인계받기 위해 자신의 데이터베이스 복사본과 주 사이트에서 수신한 모든 로그 기록을 사용하여 복구 수행
- 백업 사이트가 주 사이트로 처리를 인계받으면 새로운 주 사이트 역할을 수행
- 기존 주 사이트가 복구 후 다시 주 사이트 역할을 수행하려면, 백업에서 발생한 Redo 로그를 수신하고 모든 업데이트를 로컬에 적용해야 함
3. 복구 시간 단축
- Recovery 시간을 줄이기 위해 백업 사이트는 주기적으로 Redo 로그를 처리하고, 체크포인트를 수행하여 이전 로그 삭제
4. 핫스페어(Hot-Spare) 구성
- 빠른 전환이 가능하도록 설정
- 백업 사이트는 Redo 로그 기록을 실시간으로 처리하여 로컬에 업데이트를 적용
- 주 사이트 장애 감지 시, 백업은 미완료된 트랜잭션을 롤백하고 새로운 트랜잭션을 즉시 처리할 준비 완료
5. 분산 DB
- 여러 사이트에 복제된 데이터를 가진 분산 데이터베이스를 원격 백업의 대안으로 사용 가능
- 원격 백업은 더 빠르고 저렴하지만 장애 내성은 분산 데이터베이스보다 낮음
Time to Commit
백업 사이트에 Update log가 기록될 때 까지 commit을 지연하여 트랜잭션의 durability 확보
백업 사이트에 log record가 도달하기 전에는 commit을 완료하지 않음
durability 수준을 다르게 하여 커밋 지연 을 줄일 수 있음
durability level
-
One-safe: 트랜잭션의 커밋 로그가 주 사이트에 기록되면 즉시 커밋
문제점: 주 사이트가 장애가 나기 전 백업에 업데이트가 도달하지 않았을 가능성이 있어 데이터 손실 위험 존재 -
Two-very-safe: 주 사이트와 백업 모두에 커밋 로그가 기록된 후 커밋
내구성 보장도가 매우 높지만, 시간이 조금 걸림
주 사이트와 백업 중 하나가 죽으면 무한정 기다리게 됨 -
Two-safe: 주 사이트와 백업이 모두 활성 상태일 때는 Two-very-safe처럼 동작
주 사이트만 활성 상태일 경우 주 사이트에 커밋 로그가 기록되면 커밋을 완료
Two-very-safe보다 가용성이 높고, One-safe의 트랜잭션 손실 문제를 방지
