요약정리
▶︎ python이 타입을 관리하는 방식에 대해 설명 해주세요.
파이썬은 동적 프로그래밍 언어이며, 인터프리터가 코드를 실행하면서 타입을 추론하여 체크한다.
자료형을 컴파일 시 에 결정하는 것이 정적, 실행 시 자료형을 결정하는 것 동적
변수의 타입이 고정되어있지 않기 떄문에 개발자가 원하면 자유롭게 바꿀 수 있고, 타입처리를 명시적으로 표시할 필요가 없기 때문에 간단 명료하게 코드를 작성할 수 있다.
———————————
select_related 와 prefetch_related 의 차이점과 이점
select_related는 일대일 관계, 정참조의 경우 사용가능하며 쿼리를 한번 요청하고 profatch_related는 다대다, 다대일 관계까지 사용가능하며 쿼리를 순차적으로 불러와 두번요청한다.
이 함수들을 사용하면 참조관계에 있는 테이블을 캐싱하여 퀴리를 줄이는 목적으로 사용한다.
하나의 QuerySet을 가져올 때 related objects들 까지 불러오는 함수입니다. 이렇게 불러온 data들은 cache에 임시 저장되어 다시 쿼리문을 불러올 때 중복되는 쿼리를 요청하지 않아도 된다.
select_related는 one-to-one, foreinkey(1:n, n:1)일 때 밖에 사용이 불가하고 prefetch_related는 두 객체를 각각 퀴리문을 요청하고 python 자체에서 join해주므로 many-to-many관계에서도 사용할 수 있다.
———————————
select_related와 prefetch 가 SQL문으로 어떻게 되는지
selcet_related는 정참조의 테이블에 퀴리를 한번 요청하여 임시 저장하고
Prefetch 는 정참조,역참조 상관없이 순차적으로 쿼리(두번이상)를 요청하여 임시 저장한다.
———————————
* 데코레이터를 사용하는 이유?
함수가 실행되기 전 먼저 실행되는 함수로 데코레이터를 실행하면 중복을 줄이고 가독성이 높다.
예를 들어 프로젝트를 진행하면서 사용한 인증/인가 데코레이터는 매번 인증/인가, 유효성 처리를 해야 하는 것을 데코레이터로 만들어 반복되는 코드를 하나로 만들어 관리가능하다.
———————————
* 데이터베이스를 최적화 하는 방법에는 어떤게 있을까요?
데이터베이스를 최적화 하는 방법에는 인덱싱, 쿼리최적화, DB튜닝 등이 있으며. 예를 들어 데이터조회를 할때 전체 컬럼을 출력하는것보다는 필요한 컬럼만 가져오는 것도 데이터 최적화 중 하나라고 생각합니다.
———————————
* 모델 정규화가 무엇인지?
데이터를 효율적으로 사용하기 위해 테이블을 나눠 구조화 하고 데이터를 분해하는 과정, 제1정규화~ 제3 정규화까지 사용하여 데이터를 나누어 관리합니다.
제1 정규화 : 모든 컬럼에는 하나의 값만 출력,
하나의 컬럼에 두개의 값이 들어가면 테이블을 분리하여야한다.
———————————
* DBMS는 무엇인지?
DBMS는 사용자의 요구에 따라 정보를 조작하는 소프트웨어로 데이터 관리 시스템입니다.
———————————
* Django ORM이 성능에 더 좋을까요? Raw SQL(query)을 쓰는게 성능이 더 좋을까요?
ORM은 Raw SQL로 변환시켜주는 라이브러리이므로 Raw SQL로 한번더 변환시켜 실행시켜 처리하기 때문에 Raw SQL가 성능은 더 빠르다.
하지만, 데이터 변경(CUD)시 속도의 차이가 거의 없고 ORM이 가독성이 좋아 ORM을 많이 사용한다.
———————————
▶︎ AWS에서 로드 밸런서가 하는 일은 무엇이고 왜 사용할까?
하나의 서비스에 트래픽이 많아지면, 속도 저하 등에 문제가 발생합니다. 이때 여러 대의 서버(scale out)에서 분산처리가 필요할 수 있습니다. 이 때 어떤 서버에 트래픽을 분산시킬지 결정하는 것이 로드밸런서 입니다.
sticky session : 특정 사용자가 접속을 했을 때 처음 접속된 서버로 계속 접속 되도록 트래픽을 처리하는 방식
———————————
▶︎RESTful API에 대해서 간략히 설명해주세요.
클라이언트와 서버 사이의 통신방식으로, 자원의 이름으로 구분하여 해당 자원의 상태를 주고 받는 것으로
URI에는 자원을 표시, 자원에 대한 행위는 HTTP Method로 표현합니다.
———————————
▶︎Docker는 무엇인가요?
컨테이너 기반으로 하는 가상화 플랫폼,
컨테이너는 다양한 프로그램, 실행환경을 컨테이너로 추상화하고 동일한 인
터페이스를 제공하여 프로그램의 배포 및 관리를 단순하게 해주는 것
이미지는 컨테이너 실행에 필요한 파일과 설정 값을 포함하고 있는 것
어떤 컴퓨터든 이미지만 가지고 있으면 똑같은 가상환경에서 실행할 수 있는 프로그램으
———————————
▶︎비밀번호 암호화로 어떤걸 사용해봤고, 어떤 방식으로 동작하는지 설명해주세요.
Bcrypt 라이브러리를 사용하였고, 알고리즘으로는 SHA-256을 사용하였습니다.
Bcrypt는 해시 알고리즘을 이용하여 단방향 암호화를 하는 라이브러리 입니다. 솔팅과 키 스트레칭 기법을 이용하여 복잡한 암호화를 할 수 있습니다.
Bcrypt를 사용한 이유는 다른 암호화 라이브러리 보다 비밀번호가 어떻게 만들어지는지 볼 수 있어 선택하였다.
———————————
* hash의 용도는 무엇일까요?
hash는 단방향 암호화 기법으로 평문을 암호화된 문장 으로 만들어 준다.
암호 저장 시 그대로 저장하지 않고 해시함수로 암호화하여 저장한다.
———————————
* 방화벽을 사용해야 하는 이유? (현석)
방화벽은 인터넷을 통해 컴퓨터로 들어오고 나가는 데이터 패킷을 검사하기 위한 소프트웨어 및 하드웨어
방화벽 필터가 의심스러운 패킷을 발견하면 시스템 및 네크워크에 대한 액세스를 차단, 위험한 트래픽이 네크위크을 통과하는 것을 차단한다.
또, 방화벽 뒤에 실제 서버의 IP를 숨겨 보안상 매우 유리하다.
———————————
▶︎TDD에 대해 설명 해주세요
TDD란 개발시 테스트 코드를 작성한 뒤에 실제 코드를 작성하는 소프트웨어 개발론 중 하나입니다.
테스트 코드를 먼저 작성하기 때문에 개발자가 지금 무엇을 해야하는지 분명히 정의하고 개발을 시작하게 됩니다. 또한 기능을 추가할 때 가장 우려되는 점은 해당 기능이 기존 코드에 어떤 영향을 미칠지 알지 못한다는 것이다. 하지만 TDD의 경우 자동화된 유닛 테스팅을 전제하므로 테스트 기간을 단축시킬 수 있다는 장점이 있습니다.
———————————
* 캐싱을 해야하는 이유를 설명해주세요.
캐싱은 동일한 요청이 여러 번 들어왔을 때 매 요청마다 계산을 하여 보여주는 것이 아닌 기존에 계산했었던 내용을 저장하여 내용을 보여주는 것
웹서버의 부하를 줄일 수 있는 기술
데이터에 액세스해야하는 필요를 줄임으로 데이터검색 성능향상
애플리케이션 성능개선, 데이터베이스 비용절감, 백엔드 로드감소
* JWT란?
사용자에 대한 속성을 저장하는 웹토큰, 주로 회원 인증이나 정보전달에 사용된다.
https://mangkyu.tistory.com/56
* JWT는 어떤 원리로 작동하는지?
어플을 실행하여 로컬스토리지에 값이 존재하는지 확인 한 후 있다면 서버에서 정상적으로 발급된 토큰을 확인하고 로그인을 하고 값이 없다면 서버에서 JWT을 발행하여 응답 헤더에 담아서 보내서 로컬스토리지와 스타틱에 저장한 후 로그인 합니다.
* JWT를 활용하여 이상적인 Scalable한 인증서버를 만들려고 하고자 할때 어떻게 구성을 할 것인가?
토큰을 사용하여 인증서버를 구현한다.
토큰은 무상태이며 확장성이 있다. 토큰은 클라이언트 사이드에 저장하기 때문에 완전히 stateless하며 서버를 확장하기에 매우 적합한 환경이다. 토큰을 사용한다면 어떤 서버로 요청이 들어가도 가능하다.
* JWT 사용했다고 했는데 JWT의 구성요소 세가지가 있다 뭐냐
헤더, 페이로드,시그니처 이며 헤더는 토큰의타입과 해싱 알고리즘을 지정하고, 페이로드는 토큰에 담을 정보가 있으며,(키:벨류 형태) 시그니처는 해더의 인코딩값과 정보의 인코딩값을 합친 후 주어진 시크릿 키로 해쉬를 하여 토큰 생성
* JWT의 페이로드에 들어가서는 안될 내용이 있나? 그이유는 무엇인가?
중요데이터(개인정보)를 넣지 않아야한다. 중간에 페이로드를 탈취하면 디코딩하면 데이터를 볼수 있다.
* JWT의 유효기간을 어떻게 설정했었으며 그 이유는 무엇인가?
토큰을 받아 인코딩 할 때 현재시간에서 사용가능 한 hours, days, weeks 를 넣어서 시간을 기입한다. 토큰이 유효한지는 토큰을 디코드하는 과정에서 자동으로 되서 따로 설정은 안해도된다.
JWT 변조 공격 어떻게 대처 하겠는지?
AccessToken, RefreshToken을 활용한다.
액세스 토큰이 만료 될 경우 따로 저장했던 리프레쉬토큰을 이용하여 액새스토큰 재발급을 요청합니다
https://velog.io/@ikswary/JWT%EC%9D%98-%EB%B3%B4%EC%95%88%EC%A0%81-%EA%B3%A0%EB%A0%A4%EC%82%AC%ED%95%AD
https://code-machina.github.io/2019/09/01/Security-On-JSON-Web-Token.html
https://velog.io/@geuni1013/JWT-%EC%A0%95%EB%A6%AC-%EA%B0%9C%EC%9D%B8%EC%A0%95%EB%A6%AC
https://covenant.tistory.com/201
———————————
▶︎ 효율성을 높이는 방법
먼저 코드들의 중복을 없애고 쿼리를 요청하는 것을 최소화 하여 진행합니다. 만약 더 좋은 방법이 있다면 새롭더라도 그 방법으로 진행하여 효율성이 좋은 코드, 가독성이 좋은 코드로 바꾸려 노력합니다.
———————————
▶︎ 컴파일러
컴파일러는 작성된 프로그램 전체를 목적 프로그램으로 번역, 컴퓨터에서 실행 가능한 실행 프로그램을 생성, 번역 과정을 거쳐야 하기 때문에 번역 과정이 번거롭고 오래걸리지만 한번 번역한 후에는 다시 번역하지 않으므로 실행 속도가 빠르다. C언어 java 등이 있다,
———————————
▶︎인터프리터
작성된 프로그램 한줄 단위로 받아들여 번역, 번역과 동시에 프로그램을 한줄 단위로 즉시 실행, 번역 속도는 빠르지만 프로그램 실행 시 매번 번역해야되므로 속도가 느리다.
Python 등이 있다.
———————————
▶︎유닛테스트는 어떻게 진행하였는가?
파이썬에서 지원하는 유닛테스트를 사용하여 테스트 케이스에 성공케이스와 실패케이스, 예외처리 등을 만들고 그에 맞게 출력이 나오는지 확인하여 유닛테스트를 진행하였습니다.
———————————
▶︎ select_related 와 prefetch_related 쿼리가 어떻게 날라가는지?
select_related는 실행하여 하나의 query로 related objects 를 불러오고
prefetch_related는 main query가 실행된 후 별도의 query가 실행되어 1번이상 query가 실행된다.
Inner join : A ,B에 대해 수행하는 것은 A,B 의 교집합
Outer join : A, B 대해 수행하는 것은 A,B의 합집합
Left outer join : A,B A의 모든열 더하기 B에 있는 공통부분을 출력
Right outer join B의 모든열 더하기 A에 있는 공통부분을 출력
Full outer join A,B 의 합집합, 값이 없는 부분은 null값으로 출력
스키마란 > 데이터베이터내에 어떤 구조로 데이터가 저장되는가를 나타내는 데이터베이스 구조
———————————
▶︎ EC2 서버(정적담당)는 어떤것인지? 웹어플리케이션 서버는 어떤것?
웹 서버 : 클라이언트로부터 HTTP요청을 받아들이고, 웹페이지의 정적으로 처리
웹어플리케이션 서버 : 애플리케이션을 수행하는 미들웨어, 동적 서버 콘텐츠를 수행한다.
Gunicorn : Python WSGI(Web Server Gateway Interface)로 WEB Server(Nginx)로부터 서버사이드 요청을 받으면 WSGI(Gunicorn)을 통해 서버 어플리케이션 (Django)으로 전달하는 역할을 함.
EC2 서버를 사용하여 웹서버는 지-유니콘을 사용하여 배포하였습니다.
———————————
추가 조사 질문
try... except... else 구문에서 else는 언제 실행되나요?
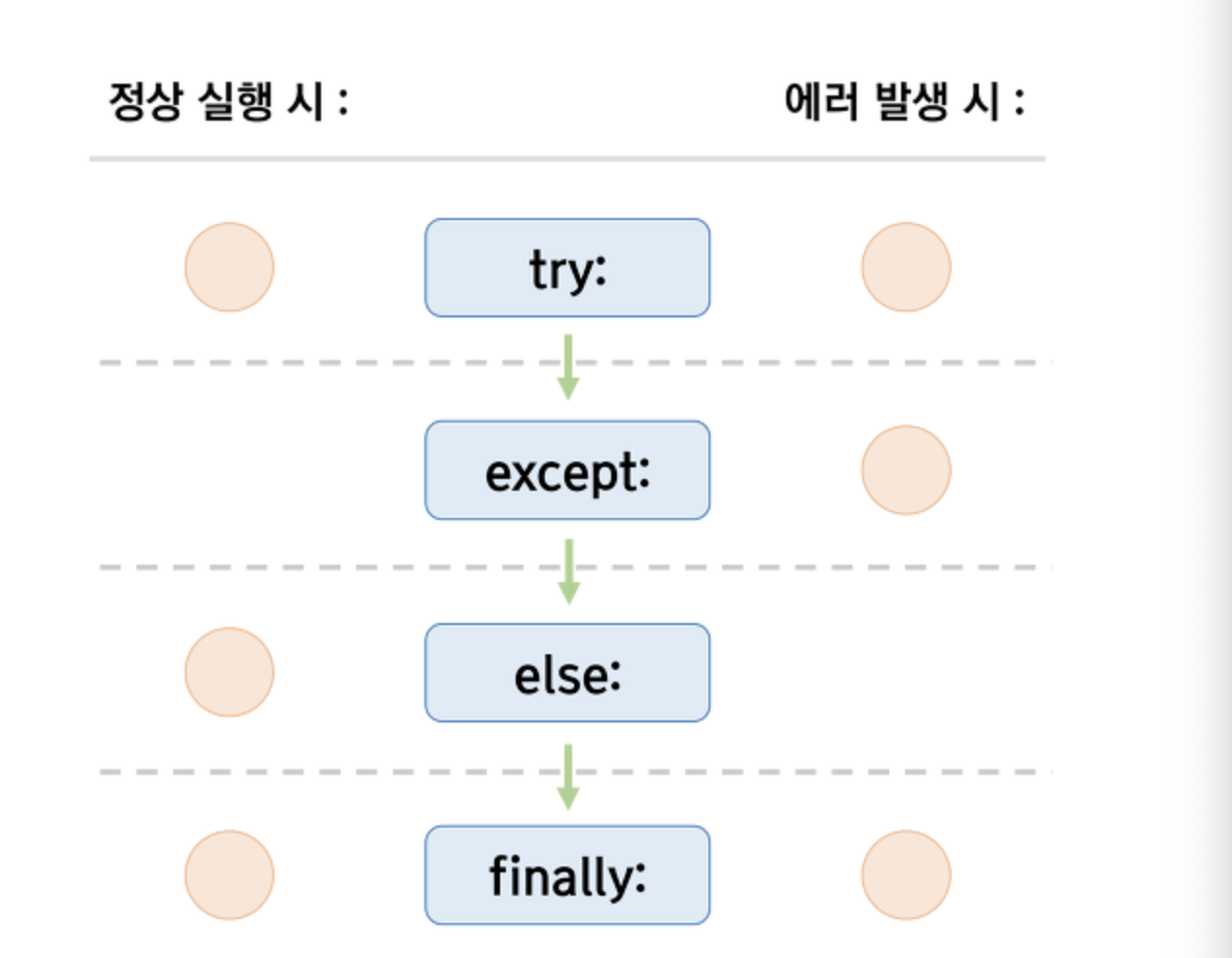
https://gomguard.tistory.com/122
list append 와 list extend 의 차이점을 설명하세요.
list.append(x)는 리스트 끝에 x 1개를 넣습니다.
list.extend(iterable)는 리스트 끝에 iterable의 모든 항목을 넣습니다.
list.extend(iterable)는 리스트 끝에 가장 바깥쪽 iterable의 모든 항목을 넣습니다.
(자료형이 list 일때 list 자체를 넣는다.)
(자료형이 list 일때 list에 항목을 넣는다.)

https://m.blog.naver.com/PostView.nhn?blogId=wideeyed&logNo=221541104629&categoryNo=50&proxyReferer=
Python은 open()을 통해 파일을 열 때, 파일 처리 모드를 설정합니다. 어떤 모드가 있나요?
- 'r' : 읽기 용으로 열림 (기본값)
- 'w' : 쓰기 위해 열기, 파일을 먼저 자른다.
- 'x' : 베타적 생성을 위해 열리고, 이미 존재하는 경우 실패
- 'a' : 쓰기를 위해 열려 있고, 파일의 끝에 추가하는 경우 추가합니다.
- 'b' : 2진 모드(바이너리 모드)
- 't' : 텍스트 모드 (기본값)
- '+' : 업데이트 (읽기 및 쓰기)를 위한 디스크 파일 열기
f = open('test.txt', mode='wt', encoding='utf-8')
파일 쓰기 모드 mode='wt'
파일 읽기 모드 mode='rt'
파일 추가 모드 mode='at' (파일 내에 내용 추가)
https://thrillfighter.tistory.com/310
Python 에서 map() 함수는 어떤 역할을 하나요?
map(변환 함수, 순회 가능한 데이터)
map() 함수는 두번째 인자로 넘어온 데이터가 담고 있는 모든 데이터에 변환 함수를 적용하여 다른 형태의 데이터를 반환합니다.
https://www.daleseo.com/python-map/
git rebase 에 대해서 설명, git squash
merge 명령과 같이 다른 브랜치에서 변경 된 사항을 병합하는 용도로 사용하지만
rebase 명령은 작업을 하고 기록한 commit을 병합하여 1개의 commit으로 관리할 수 있다.
Git rebase 명령을 실행하게 되면 작업한 commit 들이 나와 있고 이 중 한개를 pick하여 commit 관리를 한다. 나머지는 squash 로 하여 이력이 소실된다.
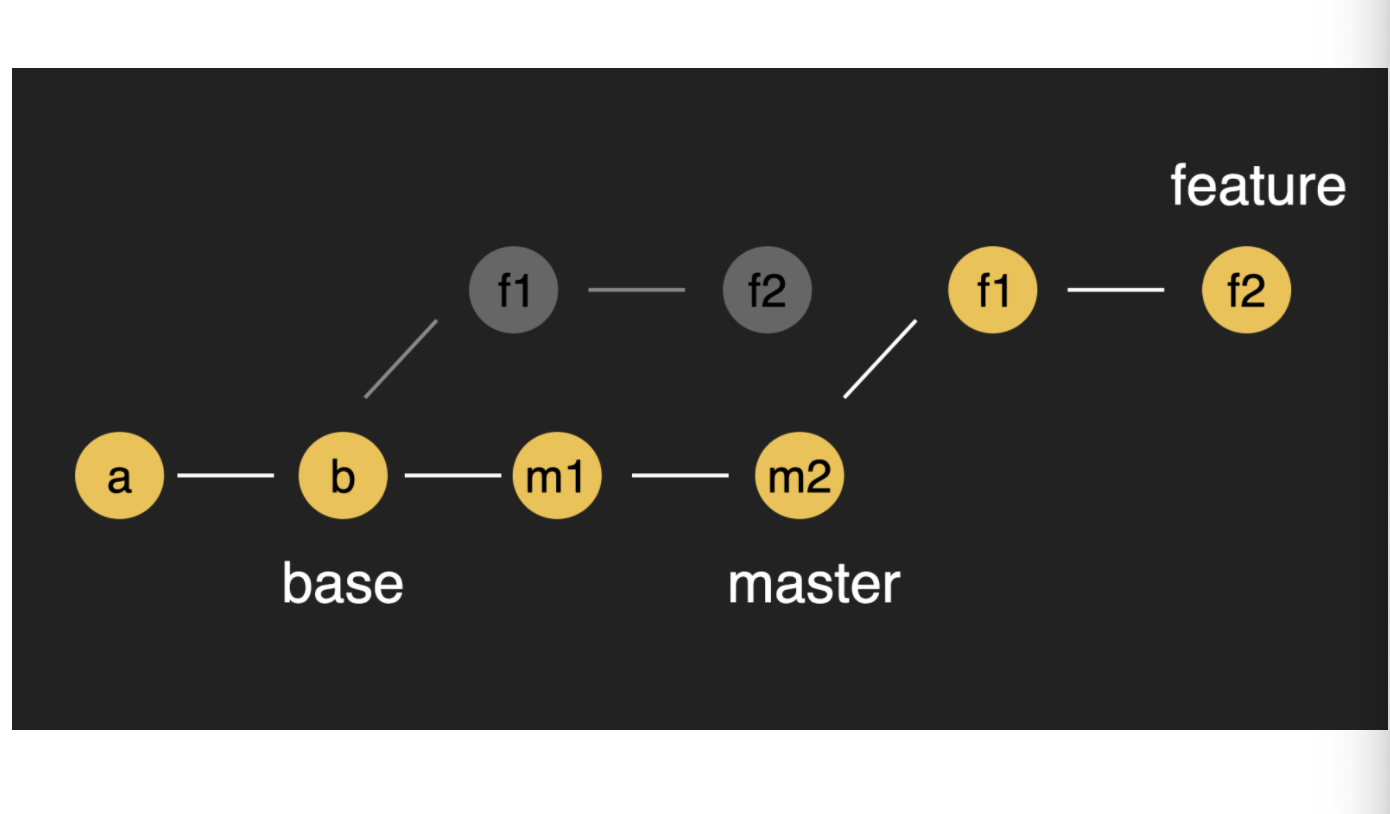
feature를 master에 rebase한다
= feature의 master 에 대한 공통 상위인 base를 master로 변경한다
https://velog.io/@godori/Git-Rebase
git stash 에 대해서 설명
아직 마무리하지 않은 작업을 스택에 임시 저장할 수 있는 명령어.
아직 완료하지 않은 일을 commit하지 않고 나중에 다시 꺼내와 마무리할 수 있다.
