Python을 이용한 오디오 신호 분석 - 오디오 신호 pitch 추출하기
실제 오디오 데이터를 이용하여 pitch를 추출하는 과정을 정리하겠습니다.
일단 신호처리적으로 pitch를 추출하는 2가지 방법이 떠오릅니다.
1. 오토코릴레이션을 이용하여 peak(혹은 최댓값)를 찾는다
2. FFT를 이용하여 magnitude의 peak(혹은 최댓값)를 찾는다.
정확도를 높이기 위해선 피치 더블링이나 신호의 주기성을 고려한 방법을 추가해야 겠죠.
- 주파수 범위를 한정한다던가,
- 신호가 얼마 이상의 크기이여야 피치로 결정한다던가
간단한 것 같지만, 이것 저것 생각하다보면 구현이 복잡해 집니다.
그런데, 파이썬은 이런 구현 조차도 라이브러리로 제공합니다.
실제 사용되는 함수는 librosa.core.piptrack 입니다.
다음은 위 함수를 이용해 오디오 파일의 pitch를 추출하는 코드 입니다.
import librosa
import scipy.signal as signal
import numpy as np
audio_sample, sampling_rate = librosa.load("sine.wav", sr = None)
S = np.abs(librosa.stft(audio_sample, n_fft=1024, hop_length=512, win_length = 1024, window=signal.hann))
pitches, magnitudes = librosa.piptrack(S=S, sr=sampling_rate)
shape = np.shape(pitches)
nb_samples = shape[0]
nb_windows = shape[1]
for i in range(0, nb_windows):
index = magnitudes[:,i].argmax()
pitch = pitches[index,i]
print(pitch)
# FFT 결과를 plot
import matplotlib.pyplot as plt
import librosa.display
#normalize_function
min_level_db = -100
def _normalize(S):
return np.clip((S-min_level_db)/(-min_level_db), 0, 1)
mag_db = librosa.amplitude_to_db(S)
mag_n = _normalize(mag_db)
plt.subplot(311)
librosa.display.specshow(mag_n, y_axis='linear', x_axis='time', sr=sampling_rate)
plt.title('spectrogram')
t = np.linspace(0, 24000, mag_db.shape[0])
plt.subplot(313)
plt.plot(t, mag_db[:, 100].T)
plt.title('magnitude (dB)')
plt.show()결과는 아래와 같습니다.
263Hz -> 291Hz -> 329Hz -> 347Hz
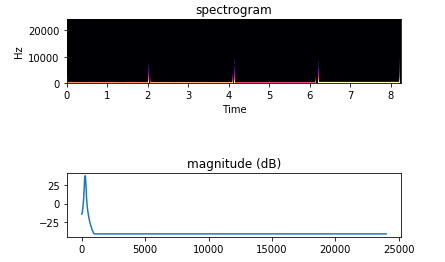
matplot을 이용해서 스펙트럼을 그리는 것 까지 넣었습니다.
실제 pitches 배열에는 pitch 후보들이 있는데,
이 중 가장 큰 값을 갖는 주파수를 출력하는 코드를 작성했습니다.
librosa.core.piptrack` 에 인자로 min, max를 넣어 pitch의 범위를 한정하는 것도 가능합니다.
이제 음성/오디오 신호의 주요 파라미터인 pitch를 추출 할 수 있게 되었습니다.

ꜱɪɴᴄᴇ 2021.09.01