
import os
import shutil
import kagglehub
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
# Define the function to download the Kaggle dataset
def download_kaggle_data():
# 기본 다운로드 위치에서 데이터를 가져옴
path = kagglehub.dataset_download("shivamb/netflix-shows")
print("Path to downloaded dataset files:", path)
# 다운로드한 파일을 원하는 위치로 이동
target_path = "/opt/bitnami/spark/data" # 원하는 경로로 변경
os.makedirs(target_path, exist_ok=True) # 타겟 디렉토리가 없으면 생성
for file_name in os.listdir(path):
source_file = os.path.join(path, file_name)
target_file = os.path.join(target_path, file_name)
# 파일이 이미 존재하면 삭제
if os.path.exists(target_file):
os.remove(target_file)
# 파일 이동
shutil.move(source_file, target_file)
print("Data moved to:", target_path)
return target_path
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime(2024, 6, 26),
"retries": 1,
"retry_delay": timedelta(minutes=2),
}
dag = DAG("kaggle-pipeline",
default_args=default_args,
max_active_runs=1,
schedule_interval="30 0 * * *",
catchup=False,
tags=['data'])
# Define the task for downloading data from Kaggle using kagglehub
download_kaggle_data_task = PythonOperator(
task_id='download-kaggle-data',
python_callable=download_kaggle_data,
dag=dag
)
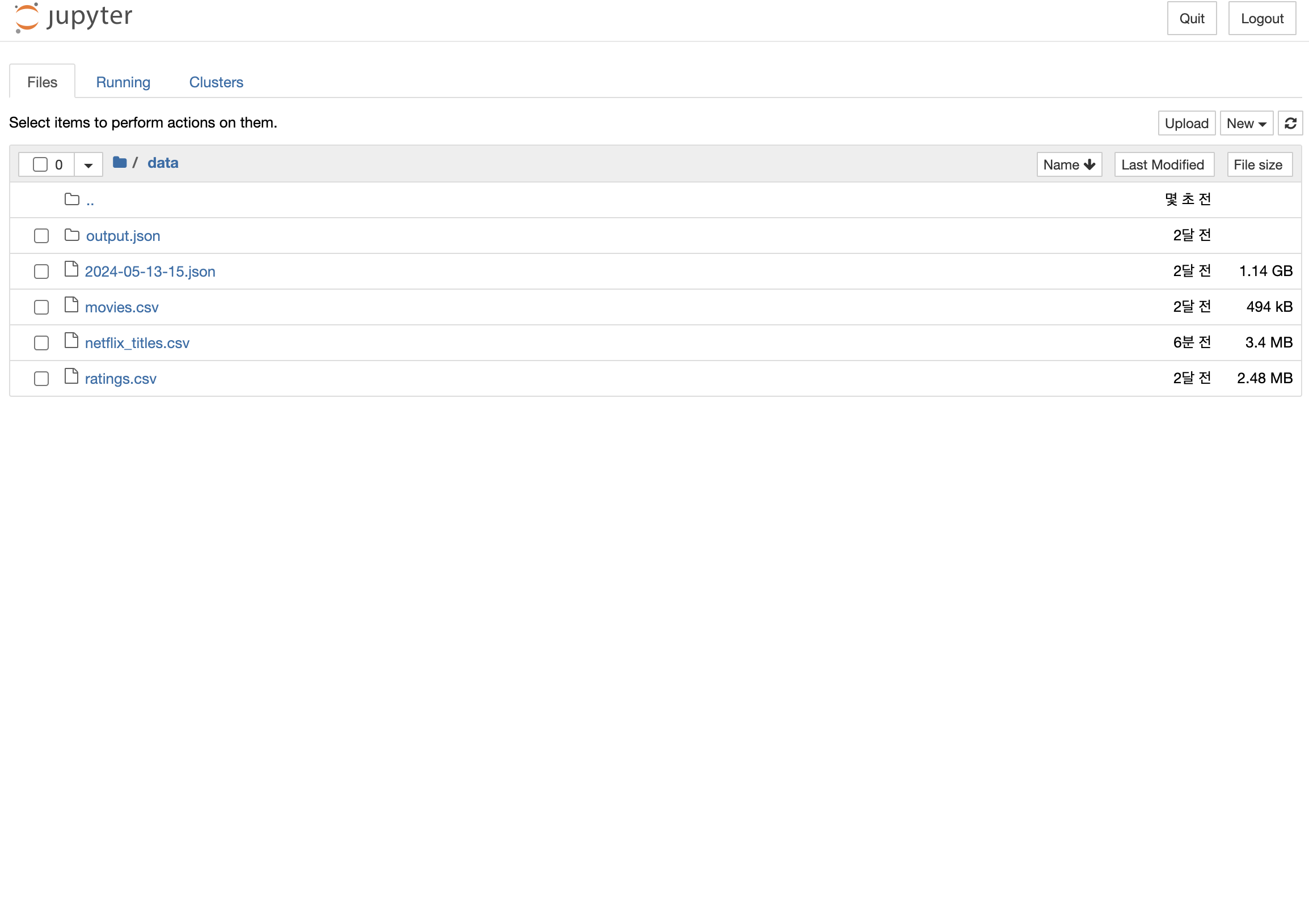
download_kaggle_data_task- 캐글 넷플릭스 데이터를 다운로드 후 data 경로에 저장을 했다.
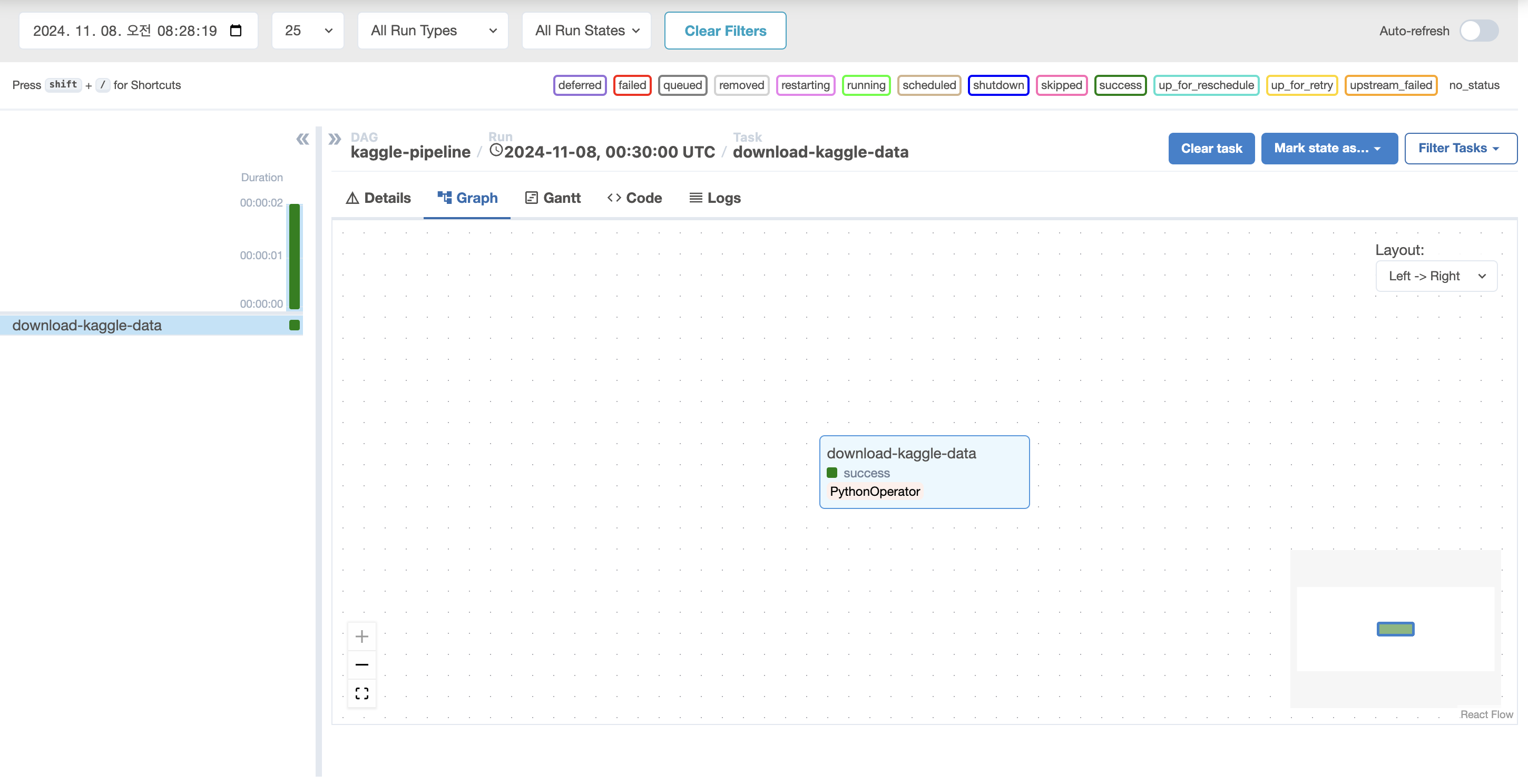
- 저장이 잘 됐는지 확인해보겠다

안녕하세요 반가워요