데이터 엔지니어
1.Airflow
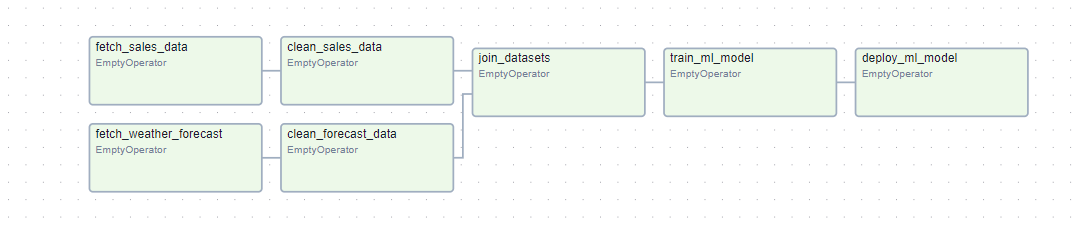
다음 주 날씨를 알려주는 쇼핑몰의 날씨 대시보드를 구축파이프라인은 비교적 간단하지만 서로 다른 태스크로 구성태스크(task)간의 의존성을 명확하게 확인하는 방법 중 하나는 Dag를 이용 Dag는 방향성을 가지지만 비순환 날씨 예보 가져오기 -> 예보 데이터 정제하기 -
2024년 7월 10일
2.Spark
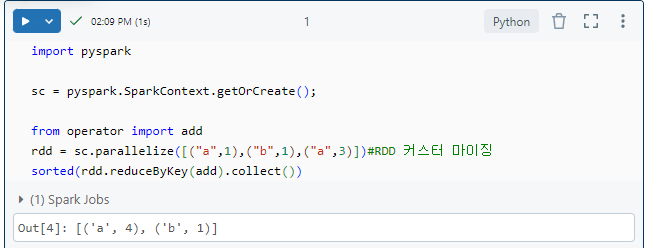
먼저 클러스터를 만들어야 한다.이후 Spark rdd를 통해서 커스터 마이징을 해봤습니다.reducedBykey: key별로 value를 merger하는 것
2024년 7월 15일
3.DBFS
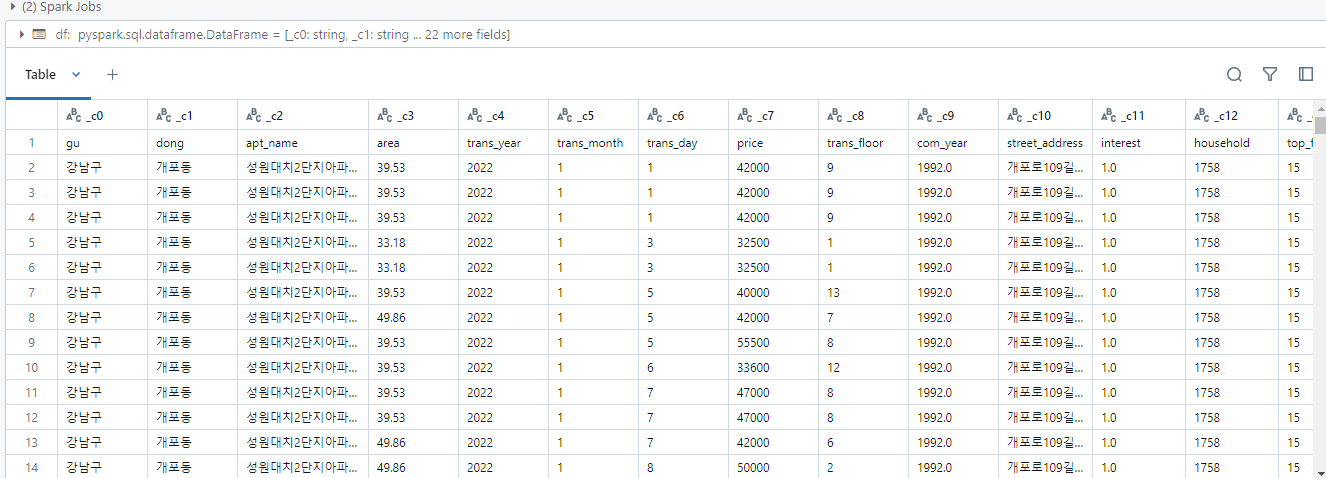
먼저 클러스터를 만들어야 한다이후 원하는 데이터를 삽입한다세미 프로젝트에서 진행했던 데이터 전처리와 파생변수 생성을 databricks spark로 진행SQL도 가능하다파생변수 및 이상치 제거, 전처리
2024년 7월 15일
4.[데이터엔지니어] Docker-Compose
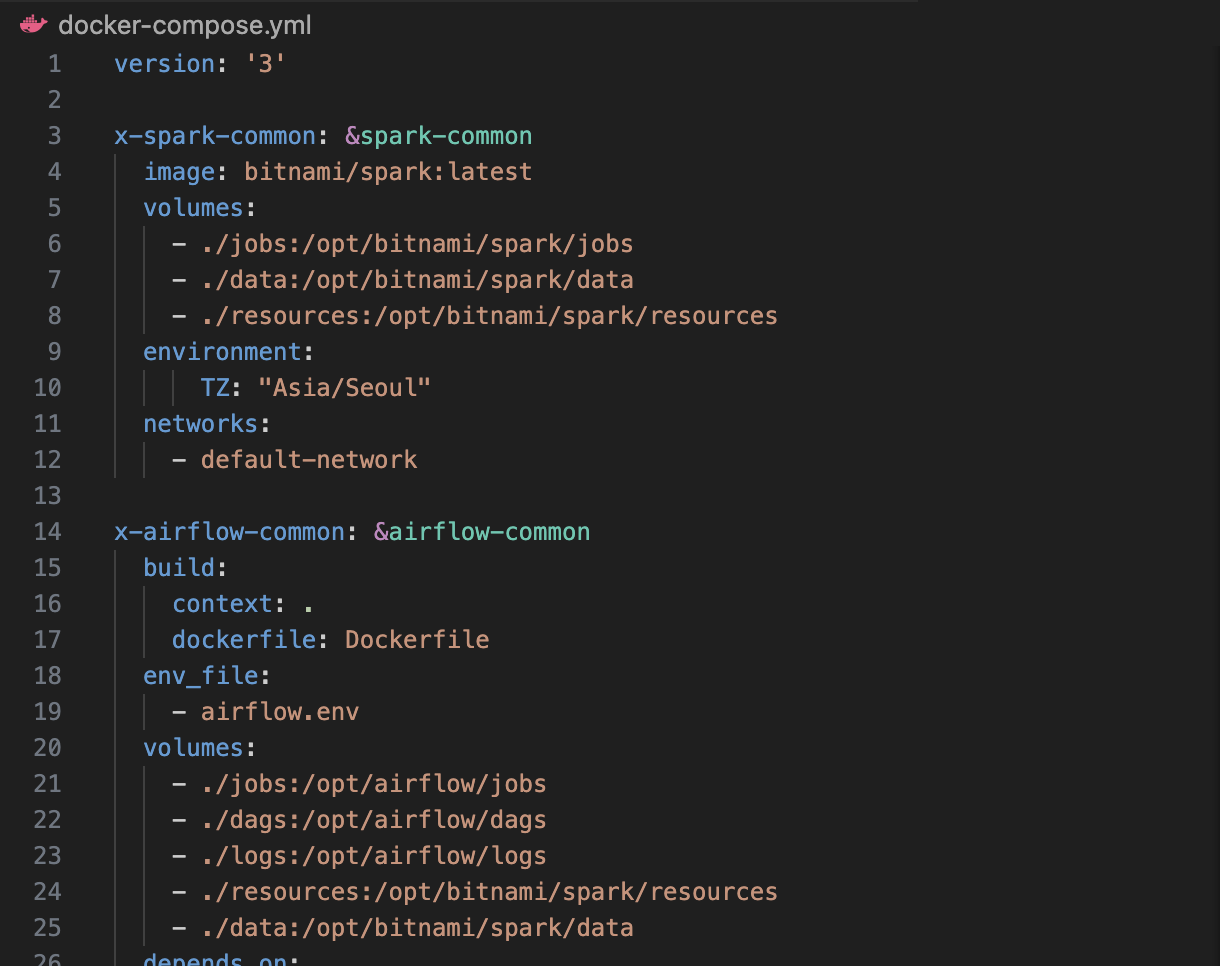
후 vm을 사용해봤지만 끔직했다...여러 개의 도커 컨테이너 설정을 한 번에 관리하기 위한 기술이다. 여러 개의 컨테이너가 하나의 어플리케이션으로 동작할때 도커 컴포즈를 사용하지 않는다면 이를 하나하나 실행해야한다!프로젝트를 진행하면서 airflow, spark, el
2024년 9월 18일
5.Spark
먼저 docker-compose-up -d 실행시킨다spark 실행방법1docker exec -it de-2024-spark-master-1 spark-submit --master spark://spark-master:7077 jobs/word-count.py방법 2
2024년 8월 26일
6.kaggle data download

캐글 넷플릭스 데이터를 다운로드 후 data 경로에 저장을 했다.저장이 잘 됐는지 확인해보겠다
2024년 11월 8일