
혼공학습단 11기로 활동하게 되었습니다.
머신러닝과 딥러닝에 대해서 6주동안 간단하게 집고 넘어가고자 신청하게 되었네요.
제가 책을 보며 작업한 소스코드는 깃허브로 공유하겠습니다.
1장 깃허브
2장 깃허브
Chpater 01. 나의 첫 머신러닝
01-1 인공지능과 머신러닝, 딥러닝
- 인공지능이란
- 사람처럼 학습하고 추론할 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술- 인공일반지능(강인공지능) :사람과 구분하기 어려운 지능으로 현재의 기술로는 어려운 상황
- 약인공지능 : 특정 분야에서 사람의 일을 도와주는 보조 역할 가능(현재의 수준)
- 머신러닝이란
- 규칙을 일일이 프로그래밍하지 않아도 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야- 파이썬 API 제공 : 주로 사이킷런(scikit-learn)을 통해 활용
- 딥러닝이란
- 머신러닝 알고리즘 중에 인공 신경망(artificial neural network)을 기반으로 한 방법들을 통칭- 파이썬 API 제공 : 구글의 텐서플로(Tensorflow)와 페이스북의 파이토치(PyTorch) 등의 딥러닝 라이브러리를 활용
01-2 코랩과 주피터 노트북
1주차 기본미션은 코랩 실습화면 캡쳐하기입니다.
하지만, 저는 일단 특별한 상황이 없는 이상 주피터 랩(Jupyter lab)으로 진행하고자 합니다.
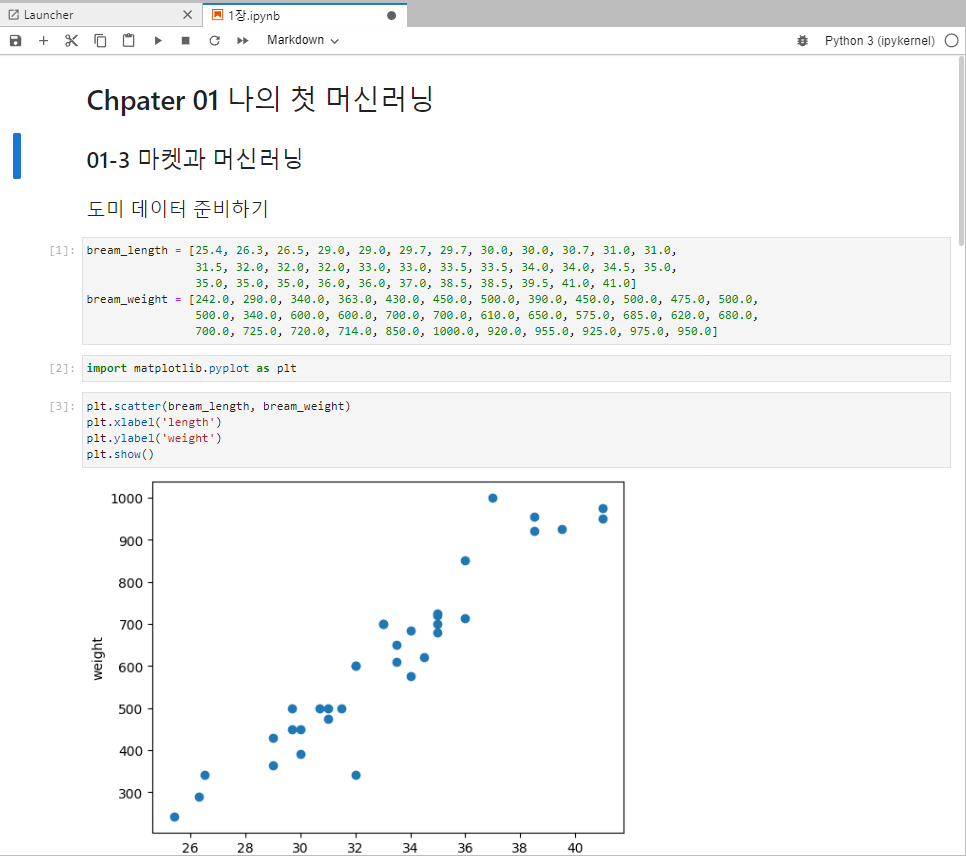
01-3 마켓과 머신러닝
소스코드에 대한 내용은 1장 깃허브를 참고바랍니다.
k-최근접 이웃(k-Nearest Neighbors)
- 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
Chpater 02. 데이터 다루기
02-1 훈련 세트와 테스트 세트
- 지도 학습과 비지도 학습
- 지도 학습 : 입력과 타겟으로 이뤄진 훈련 데이터 필요
- 비지도 학습 : 입력 데이터만 있을 때 비지도학습 알고리즘 활용
- 훈련 세트와 테스트 세트
- 훈련 세트 : 훈련에 사용되는 데이터
- 테스트 세트 : 평가에 사용하는 데이터
- 샘플링 편향 : 일반적으로 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향이라고 한다
[1주차 선택 미션에 대해 풀고 가겠습니다.]
- 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
=> 답 : (1) 지도 학습
비지도 학습은 타깃을 모를 때 활용할 수 있는 방법이다.
- 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
=> 답 : (4) 샘플링 편향이 있으면 모델이 편향될 수 있다.
- 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
=> (2) 행 : 샘플, 열 : 특성
행 단위로 샘플이 있고, 열단위로 특성이 있어야 한다.
02-2 데이터 전처리
소스코드에 대한 내용은 2장 깃허브를 참고바랍니다.
- 스케일(scale) 문제
- 예를 들면 길이와 무게처럼 값이 놓이 범위가 다른 경우 스케일이 다르다고 할 수 있음
- 가장 널리 사용되는 전처리 방법 중 하나는 표준점수(z점수)를 활용하여 전처리 진행

Computer Science And Mathmatic