Embedding?
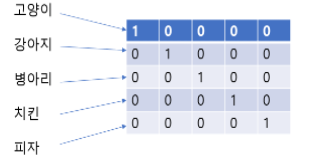
- vectorization의 치명적인 단점: 단어나 문장들 사이의 관계에 대해서 설명하지 못함.
- 단어사이의 유사도 구분을 위해서 Embedding 기법을 쓴다. (ex) word2vec

- 의미가 유사한 토큰들은 가깝게, 그렇지 않은 토큰들은 멀게 뿌림 -> 임베딩
- 임베딩 또한 훈련이 필요. 보통 pre_trained embedding model 사용
Keras Embedding Layer
- 무작위로 특정 차원으로 입력 벡터들을 뿌리고, 학습을 통해 가중치를 조절. (단어 사이의 관계 반영 X)
- keras 코드로 구현 가능
model = Sequential()
model.add(Embedding(vocab_size, 128, input_length = max_len))word2vec
- 주변 단어와의 관계를 통해 해당 단어의 의미적 특성을 파악
- 구글의 사전 훈련된 word2vec bin 파일을 다운
- gensim 모듈과 bin 파일을 활용해 word2vec 모델을 로드
- vocabulary에 있는 토큰들의 벡터를 가져와 embedding matrix에 저장
- keras embedding layer에 embedding_matrix를 가중치를 주어 사용한다.
glove
- word2vec은 사용자가 지정한 주변 단어의 개수에 대해서만 학습이 이루어짐-> 데이터 전체의 정보를 담기 어려움
- glove는 word2vec의 단점을 보완 -> 각 토큰들 간 유사성은 그대로 가져가고, 데이터 전체에 대한 빈도를 반영.
- 사전 훈련된 벡터를 갖고 있는 txt 파일을 다운
- txt 파일에 있는 단어, 벡터들을 glove dictionary에 저장
- vocabulary에 있는 토큰들의 벡터를 가져옴. embedding matrix에 저장
- keras embedding layer에 embedding_matrix를 가중치로 주어 이용
출처
https://dacon.io/competitions/official/235670/codeshare/1892?page=1&dtype=recent

공부방