Model Selection
Key words
model selection, 교차검증(cross validation), hold-out method, k-fold cross validation, 하이퍼 파라미터 최적화, RandomizedSearchCV, GridSearchCV, target encoder
Details
교차 검증
- 이전에는 train, val, test 데이터 셋으로 나누어 학습을 진행하는 hold-out method만 사용했었다.
- 이 방법은 만약 가지고 있는 훈련, 검증 데이터의 크기가 충분히 크지 않다면, 모델의 예측 성능을 제대로 평가할 수 없는 문제가 있다.
- 또한 어떤 파라미터를 가진 모델을 사용할 것인지를 평가할 때도 좋지 않을 수 있다!
- 즉, 데이터의 크기가 충분하지 않은 문제 + 여러 모델을 비교해서 가장 나은 걸 채택하려는 model selection의 문제를 해결하기 위한 방법 중 하나로 교차 검증을 사용한다. (개인적으로는 가지고 있는 데이터가 크지 않은 상황이 더 와닿는다)
- 참고로 교차검증은 시계열 데이터에는 적합하지 않다. 시계열 데이터의 경우 일반적으로 시간에 따른 어떤 흐름을 보기 위한 건데, 무작위로 섞어가며 교차검증을 하면 안되기 때문!
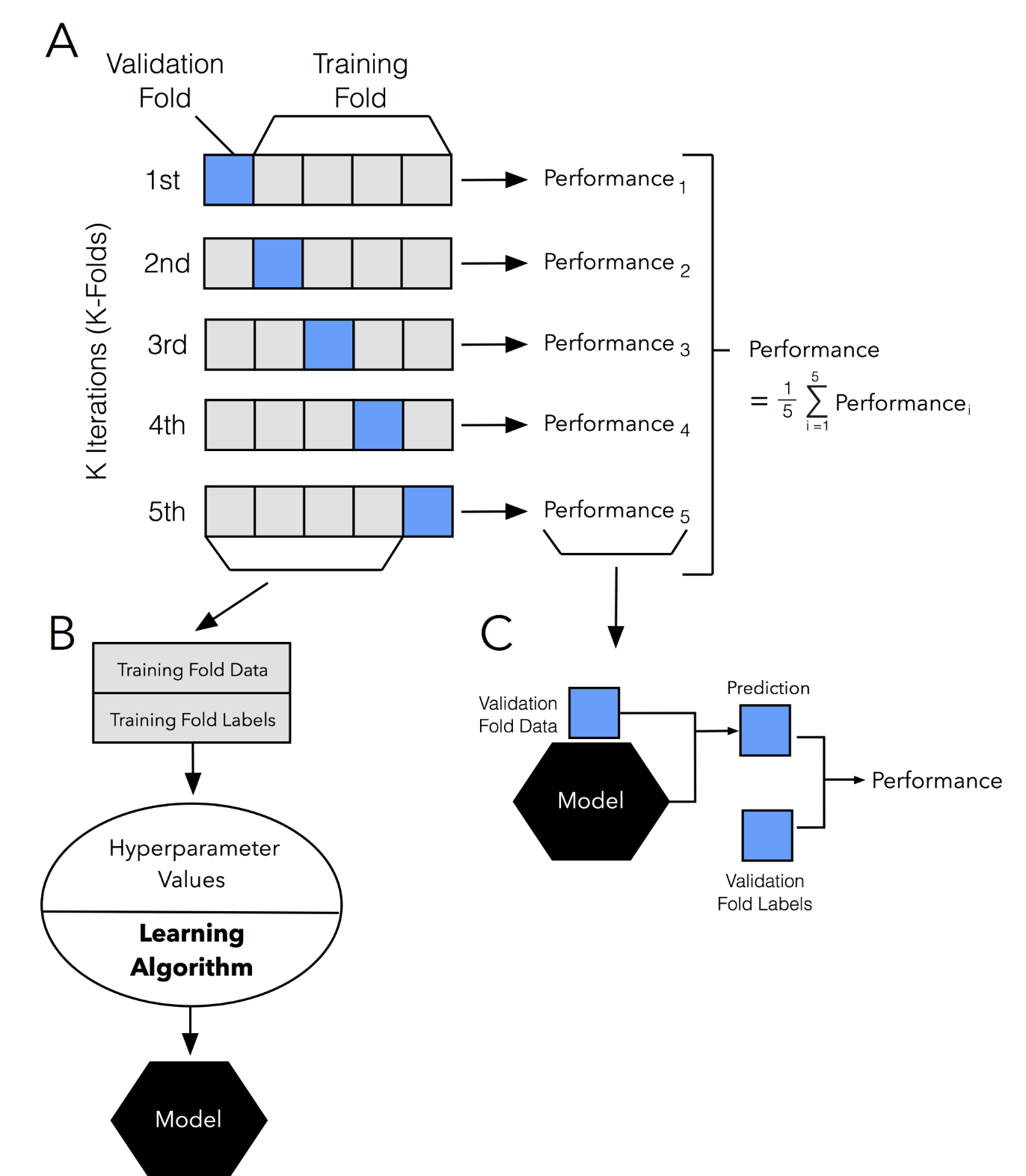
- 교차 검증을 하기 위해 데이터를 K개로 등분하는데, 이를 K-fold CV라고 부른다. 만약 데이터를 10등분 했다면, 10-fold CV라고 하면 된다. 이 때 9개의 fold는 훈련 셋으로, 1개의 fold는 검증 셋으로 사용하게 되는데, 10-fold면 이 과정을 10번하게 된다.
- (참고로, 데이터 샘플 수가 K로 딱 나눠떨어지지 않을 때는 어떻게 하나 궁금해서 찾아봤는데, 각 fold별로 최대한 유사하게 알아서 배분해준다고 한다.)
- 교차검증할 때도 테스트 데이터는 아예 떼어두는거 잊지말자!! 기존에 훈련 데이터와 테스트 데이터를 나누고, 다시 훈련 데이터를 훈련과 검증 데이터로 나누던 것에서 뒤만 안 해도 되는 거다.
- 사이킷런에 있는
cross_val_score을 사용하면 교차검증을 쉽게 적용할 수 있다고 하는데, 일단 참고만 하자. 실습을 하면서 실제로 써본 적은 없다. 뒤에 배울 Random search cv를 주로 썼다.- 뒤에서도 마찬가진데, socring 잘 설정해주는 거 매우 중요하다!! 회귀문제인데 분류문제 score가져다 쓰거나 하면 안된다! 종류에 대해선 공식문서 참고할 것!!
하이퍼 파라미터 최적화
- 아마 최근 배운 것 중 가장 중요한 것이 아닐까 싶다. 결국 모델의 성능을 올리려면 하이퍼 파라미터를 어떻게 조정하느냐가 매우 중요한 거니까!
- 참고로 우리의 목표는 과소적합과 과적합 사이의 어느 지점 사이에 있는 이상적인 모델을 찾는 것이다. 이를 알기 위해 다양한 파라미터 값에 대해
검증곡선(validation curve)을 그리며 확인할 수도 있다. (검증곡선에 대해선 필요시 더 찾아보자) - 오늘은 여러 하이퍼 파라미터의 최적값을 찾기 위해
RandomizedSearchCV를 주로 사용했다. 이걸 설명할 때는GridSearchCV를 함께 설명하는게 좋겠다.- 둘은 연구자가 탐색하고 싶은 하이퍼 파라미터와 범위를 지정해주는 것까지는 똑같다. 차이는, Grid Search는 지정된 범위 내 조합을 모두 검증하는 것이고, Random Search는 지정된 범위 내에서 무작위로 값을 지정해 그 조합을 모두 검증한다는 것이다.
- 공통점으로는 이 탐색의 과정에서 CV를 사용한다는 것이다. (처음에 말한 모델 간 비교하여 최적의 모델을 뽑아낸다는 의미가 여기에 있다. 여러 하이퍼 파라미터의 조합 중 가장 최적의 모델을 뽑아내는 것이다.)
- Grid Search는 모든 조합을 다 탐색하는 것이기 때문에 비용이나 시간의 문제가 발생하게 되지만, 연구자가 꼭 보고 싶은 파라미터 값이 있다면 이 방법을 사용하면 된다. Random search는 반대로 생각하면 될 것 같다.
- 아무튼 보통은
RandomizedSearchCV를 더 자주 사용한다고는 한다.
- 사용하는 코드는 아래를 참고하자
from scipy.stats import randint, uniform
pipe = make_pipeline(
TargetEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=2)
)
dists = {
'targetencoder__smoothing': [2.,20.,50.,60.,100.,500.,1000.], # int로 넣으면 error(bug)
'targetencoder__min_samples_leaf': randint(1, 10),
'simpleimputer__strategy': ['mean', 'median'],
'randomforestregressor__n_estimators': randint(50, 500),
'randomforestregressor__max_depth': [5, 10, 15, 20, None],
'randomforestregressor__max_features': uniform(0, 1) # max_features
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);dists부분에는 내가 탐색하고자 하는 하이퍼 파라미터와 그 범위를 지정해주면 된다.RandomizedSearchCV중에 scoring 잘 넣는거 유의해야 한다. cv를 쭉 하면서 이 지정된 score가 가장 높은 걸 찾아 뱉어주기 때문이다. 또한n_iter와cv도 유의해서 사용해야 하는데, 이 탐색을 랜덤하게 50번 * 교차검증을 3번(fold 수 = 3이므로) 한다면, 총 150번의 탐색을 하는 것이기 때문에 잘 못 설정하면 시간이 아주 올래 걸리기 때문이다.- 아래 코드를 사용하면 탐색을 한 결과 최적의 파라미터와 (설정한 scoring의) best_score를 확인할 수 있다.
clf.best_params_ #탐색결과 찾아낸 최적의 파라미터 값을 확인할 수 있음.
-clf.best_score_ # -를 붙인 것은 그 값이 작아질 수록 성능이 좋아지는 걸 뜻하는 score 종류에 붙는다.
clf.cv_results_ #이걸 잘 sort하면 파라미터 조합으로 만들어진 모델들을 순위별로 나열할 수도 있다.
pipe = clf.best_estimator_
# 만들어진 모델 중 가장 성능이 좋은 모델을 이렇게 불러올 수 있다. 중요!!!! - “bestestimator 는 CV가 끝난 후 찾은 best parameter를 사용해 모든 학습데이터(all the training data)를 가지고 다시 학습(refit)한 상태입니다. 만약 여러분이 hold-out 교차검증(훈련/검증/테스트 세트로 한 번만 나누어 실험)을 수행한 경우에는, (훈련 + 검증) 데이터셋에서 최적화된 하이퍼파라미터로 최종 모델을 재학습(refit) 해야 합니다.” 이 말 잘 기억하자!!!
- 참고 - 튜닝 추천 하이퍼 파라미터

- 좀 다른 얘기지만, 다른 사람들 얘기 들어보니
class_weight주는 거랑Simpleimputer,target_encoding잘 설정하는 것도 모델 성능에 큰 영향을 준다고 한다. - 하이퍼 파라미터 튜닝을 어떤 건 하고 어떤 건 안했다면 왜 그런 선택을 했는지 면접에서 물어볼 수도 있다.

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.