Fact
오늘은 아래 내용을 배웠다.
KeyWords
Interpreting_ML_Models
- PDP (Patial Dependent Plot, 부분의존도)
- SHAP
- 참고로 이것들은 model-agnostic, 즉 어떤 모델이건 상관없이 사용할 수 있다.
이 개념을 어떤 맥락에서 배웠나?
- 모델링을 할 때 모델이 단순히 예측값만 잘 뱉는다고 그냥 그 모델을 무작정 신뢰하고 사용하기만 할 수는 없을 것이다. 데이터와 모델을 가지고 사람이 여러 분석과 새로운 판단을 해야할 때가 있지만(그게 모델 최적화건, 새로운 인사이트 추출이건, 의사결정권자를 설득하는 일이건), 모델이 복잡할 수록 사람인 우리가 이해하기는 점점 어려워진다. 즉, 보통은 아래와 같다.
- 단순한 모델 (ex. 선형회귀) > 이해하기가 쉽지만 성능이 부족함.
- 복잡한 모델 (ex. 랜덤포레스트, 부스팅과 같은 앙상블 모델) > 이해하기 어렵지만 성능이 좋음. (쉽게 말해 알아서 잘 계산해주긴 하는데, 도대체 어떤 과정을 거쳐 이 예측값을 내놓는지 쉽게 파악하기 어렵다. aka 블랙박스 모델.
- 랜덤 포레스트, 부스팅에서는
Feature Importance를 쉽게 구할 수 있었는데(model.feature_importance_), 이건 어떤 특성이 모델의 성능에 있어 중요하며 많이 쓰이는지를 알려주긴 하지만, 어떻게 영향을 주는지는 알려주지 않는다. (피쳐의 값에 따라 타겟값이 증가/감소하는지와 같은 관계를 말함) - 즉, 오늘 배운 PDP, SHAP은 복잡한 모델에 대해 각 피쳐가 타겟에 '어떻게' 영향을 주는지, 모델을 보다 잘 이해할 수 있도록 도와주는 기능으로 기억하면 된다.
PDP
While feature importance shows what variables most affect predictions, partial dependence plots show how a feature affects predictions.
=> 사실 이 말 하나면 PDP의 사용 목적은 다 설명이 되는 것 같다. (출처)
-
전체 관측치에 대하여 특성과 타겟 간의 관계를 설명할 수 있다.
- 선형회귀에서는 회귀계수(coefficients)를 통해 타겟과 변수 간의 관계를 해석할 수 있지만, 트리모델은 할 수 없다. 그럴 때 이 PDP를 사용하면 알 수 있다.
-
관심있는 한 가지 특성에 대해서만 볼 수도 있고, 2개 이상에 대해서도 볼 수 있다.
-
pdp_isolateICE(Individual Condition Expectation) Curves라는 개념이 나오는데, 이 곡선은 하나의 관측치에 대해 관심있는 그 특성을 변화시킴에 따른 타겟 예측값의 변화곡선을 말한다.- 쉽게 말하면, 10개의 샘플을 가져다가 ICE 곡선을 그린다고 했을 때, 각 샘플별로 특성의 값을 변화시키면서 나오는 예측값의 변화가 10개 찍히는 것이다. (양의 관계인지, 음의 관계인지도 파악할 수 있다)
- 이 ICE curves들의 평균이 바로 PDP이다.
- (그럼 선형회귀에서는 ICE curves를 그릴 수는 있지만, PDP랑 같을 때니 큰 의미는 없을 것이다. 아무리 특성값을 바꿔봐도 기울기가 같으니까 결국은 다 겹쳐 하나로 보일거니까!)
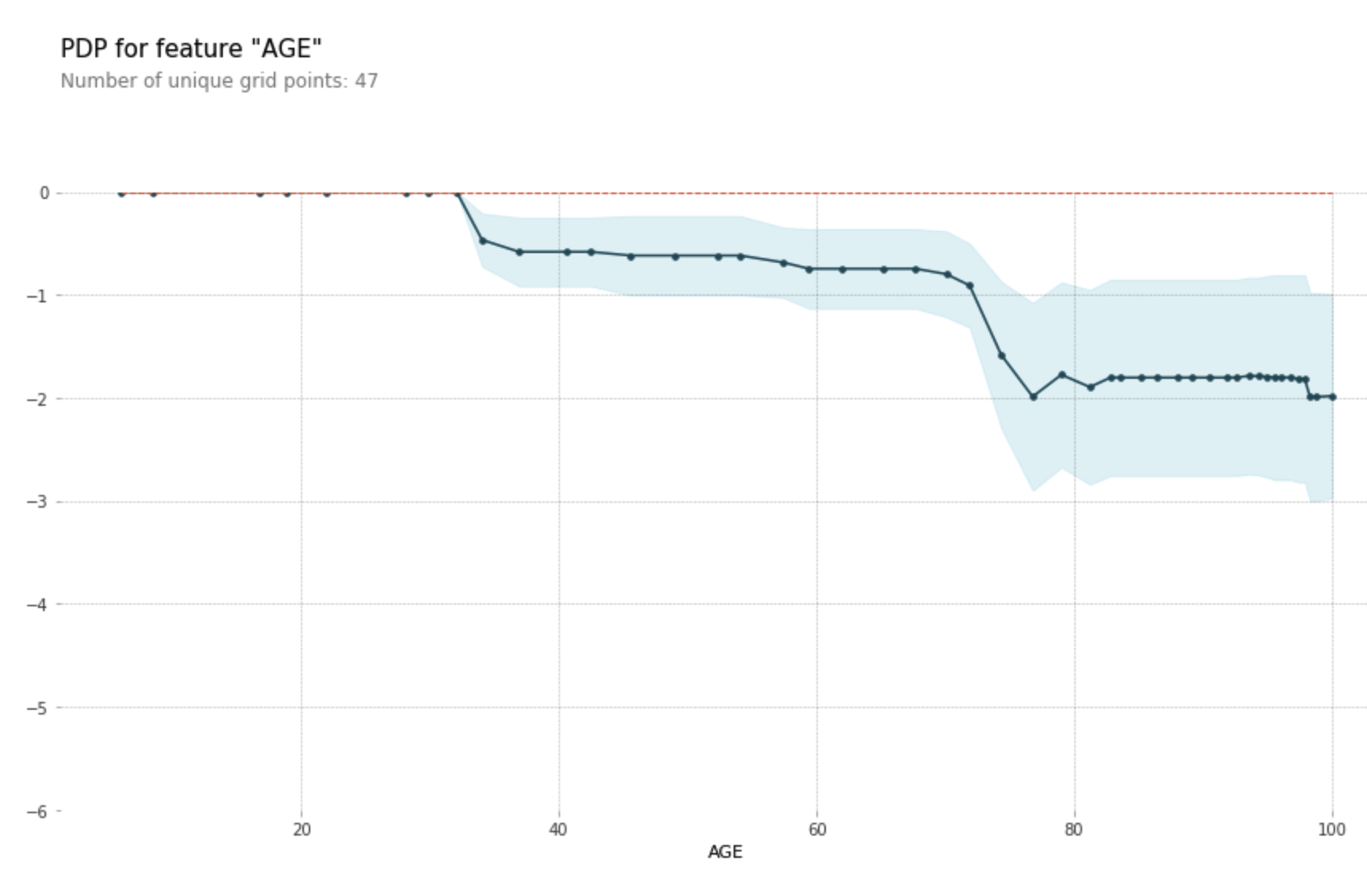
- 참고로 이렇게 하단에 샘플의 분포도 표시할 수 있다. 오른쪽으로 갈수록 점차 타겟 예측값의 변화가 둔해지는 것을 확인할 수 있는데, 그래서 이 뒤는 더이상 영향이 없다고 결론을 내릴 때, 샘플 수가 충분히 반영된 건지(=신뢰할 수 있는지) 아닌지를 보여주기 위해서 그려보는 것으로 이해했다.

- 반대로는 이렇게 샘플의 분포를 고려하지 않는게 PDP의 문제점이라고 할 수 있다.
-
pdp_interact- 고른 여러 특성 간 상호작용을 확인할 수 있다. (난 오늘 2개 특성만 해보았다)
- 참고로 모델링할 때 인코딩을 많이 하는데, 인코딩 후 PDP를 그리면 인코딩된 값이 나오게 되어 카테고리 특성을 확인하기 어려운 경우가 있으니 이럴 땐 적절한 처리를 해야 한다고 한다. (이건 나중에 케이스를 만나면 알아서 처리의 필요성을 느끼고 직접 작업해보게 되겠지?)
-
SHAP Value plot
You've seen (and used) techniques to extract general insights from a machine learning model. But what if you want to break down how the model works for an individual prediction? + 만약 은행에서 모델을 통해 특정 고객을 대출 거부로 결정하였는데, 해당 고객에게 왜 대출 거부로 분류되었는지 설명해야 한다면 어떻게 할 것인가? (출처)
- SHAP(SHapley Additive exPlantions)은 개별 관측치(샘플)에 대하여 특성과 타겟과의 관계를 설명할 수 있다.
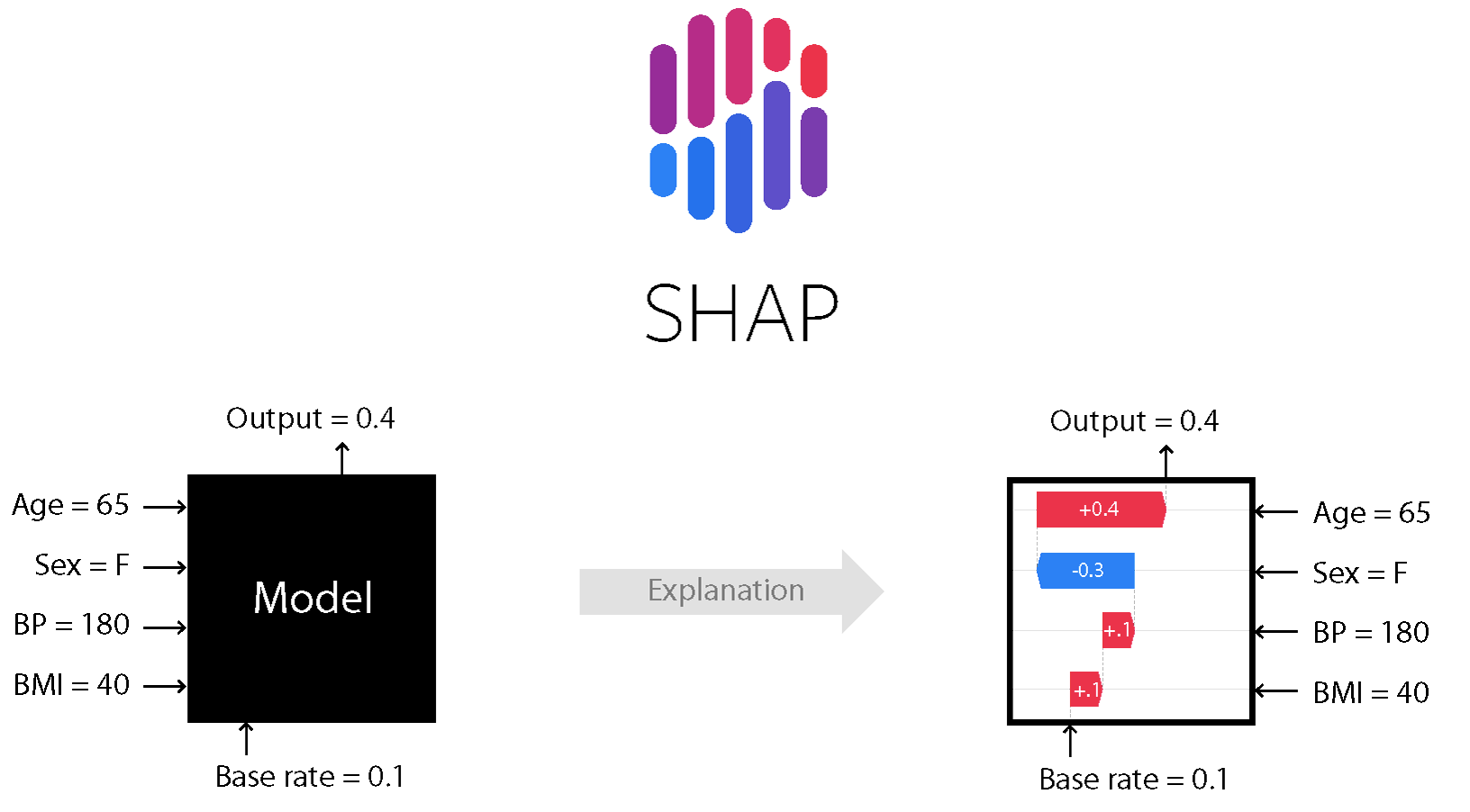
- 각 특성의 기여도 산정은
Shapley Value(혹은 줄여서shap value)를 계산하여 이루어지는데, 특성 수가 많을 수록 계산량이 기하급수적으로 늘어나므로, 적절한 샘플링을 통해 근사적으로 값을 구해야 한다! - SHAP Force plot - 하나의 샘플
- 하나의 샘플에 대해 Force plot을 그리면 아래와 같이 나온다.

- 빨간색은 타겟 값에 양의 영향을 주는 것이고, 파란색은 반대로 음의 영향을 주는 것이다. 각 바의 길이를 해당 샘플의 f(x)(=예측값)을 결정한 영향력의 정도로 생각하면 된다. 위 그림에서는 잘 안 보이지만,
Base Value라고 하여 전체 샘플에 대한 예측값의 평균도 보여준다. - 참고로 바가 특정 수치 구간 아래 걸쳐져 있는 듯 보여서 걸쳐진 구간의 정도가 의미가 있나 싶어 물어봤었는데, 그건 아무 의미가 없다고 한다. 그냥 바의 상대적 길이를 통해 영향력의 정도를 파악할 수 있다 정도로 우선 기억해두자. (의미가 있을 것 같기도 한데..)
- 하나의 샘플에 대해 Force plot을 그리면 아래와 같이 나온다.
- SHAP Force plot - 2개 이상의 샘플
- 똑같이 그려보면 아래와 같이 차트가 나오게 되는데, 왼쪽과 상단의 선택바를 통해 여러 특성, 옵션을 선택하다보면 많은 정보를 얻을 수 있다.
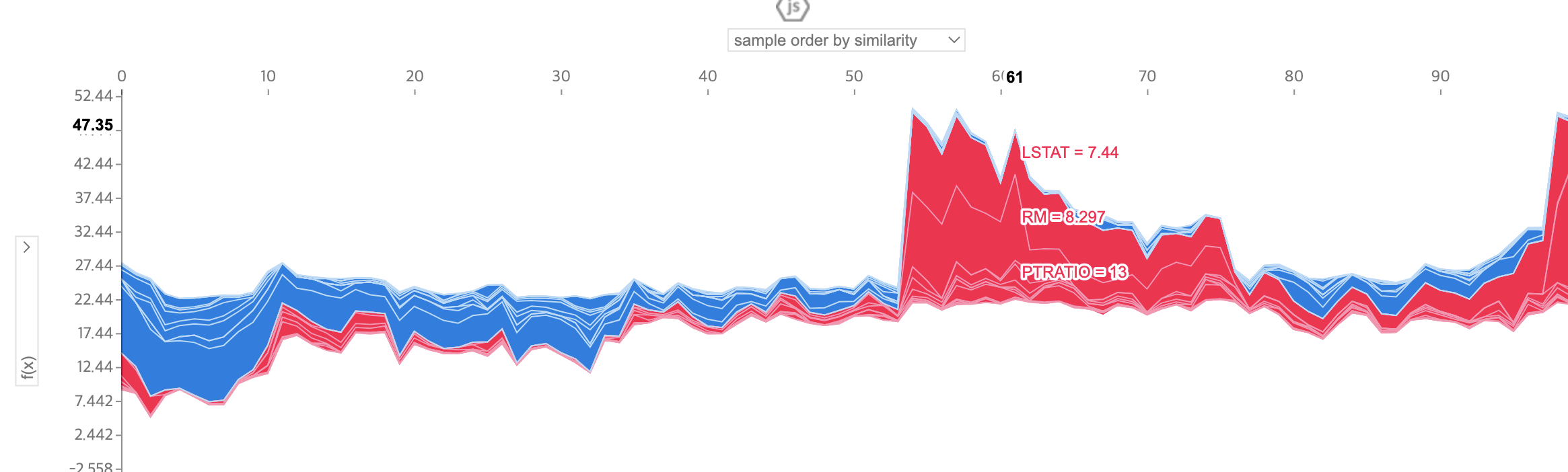
- 다만, force plot에서는 특정 특성이 전체 관측치에 대한 타겟값의 변화에 얼만큼의 영향력을 발휘하는지는 알 수 없다. 이건
summary plot을 통해 알 수 있다.
- 똑같이 그려보면 아래와 같이 차트가 나오게 되는데, 왼쪽과 상단의 선택바를 통해 여러 특성, 옵션을 선택하다보면 많은 정보를 얻을 수 있다.
- SHAP Summary Plot
- SHAP 중에서 가장 유용하게 쓰일 기능 같으니 잘 기억해두자.
- 아래와 같이 선택한 샘플들에 대한 피쳐와 타겟의 관계를 한 누에 파악할 수 있다.

LSTAT특성이 가장 영향이 큰 것을 알 수 있다. 가운데 빨간색과 파란색 점이 몰려있는 걸 보면, 정확한 양음의 상관관계가 없겠구나 알 수 있다.plot_type이란 파라미터를 통해서 violin, bar등 여러가지 형태로 그려볼 수 있다.
- 참고로 SHAP에 대해서 공부하다보니 아래 궁금증이 들어서 질문을 했었다.
SHAP_summary_plot 응용에 대해 질문드립니다. 선택한 샘플들에 대한 피쳐와 타겟과의 관계를 볼 수 있다는 점은 이해했습니다. 그러면 만약 개별 고객에 대한 쇼핑 정보를 담고 있는 데이터에 이걸 사용해본다고 했을 때요. 단순히 100명의 고객을 샘플링하여 summaryplot을 보는 것보다는, 오늘 과제의 보스턴 데이터에서 하나의 샘플이 하나의 구획에 대한 평균 정보를 담고 있는 것처럼, 각 고객들을 '회원 등급'으로 임의로 클러스터링?하면(=한 행에는 한 회원등급의 평균 쇼핑정보가 담김), 각 회원등급별로 피쳐와 타겟의 영향력이 어떻게 다른지 보는데 활용할 수 있겠다는 생각이 들었습니다. 제가 잘 이해한게 맞을까요? 이런 생각을 하게된 이유가, 만약 오늘 보스턴 데이터의 각 샘플 하나가 '구획 하나'가 아니었다면, 단순히 100개 샘플링하여 summary plot을 그리는게 과연 어떤 의미가 있을지 싶어서였습니다.
내가 잘 못 이해한 부분은 없는 것 같았고, 내가 뭘 보고 싶은지에 따라서 활용 방향이 천차만별이겠구나~ 라는 결론을 내렸다.
오늘 실습한 코드만 그대로 옮겨둔다
어차피 open된 데이터셋을 사용했기 때문에 괜찮을 것 같다.
데이터셋은 Shap.datasets.boston()이다.
- PDP를 만들고 모델 설명하기
import sklearn
import xgboost
import shap
from sklearn.model_selection import train_test_split
shap.initjs();
df, target = shap.datasets.boston()
X_train,X_test,y_train,y_test = train_test_split(df, target, test_size=0.2, random_state=2)
model = xgboost.XGBRegressor().fit(X_train, y_train)
### Draw PDP plots ### - 직접 작성한 부분 시작
from pdpbox.pdp import pdp_isolate, pdp_plot, pdp_interact, pdp_interact_plot
# 한가지 특성 - 'AGE' & target
feature = 'AGE'
isolated = pdp_isolate( #공식문서 https://pdpbox.readthedocs.io/en/latest/pdp_isolate.html
model = model,
dataset = X_train,
model_features = X_train.columns,
feature = feature,
grid_type='percentile',
num_grid_points=50
)
pdp_plot(isolated, feature_name=feature);output
# 두가지 특성 & 타겟 ('AGE', 'RM)
features = ['AGE', 'RM']
interaction = pdp_interact(
model = model,
dataset = X_train,
model_features = X_train.columns,
features = features
)
pdp_interact_plot(interaction, feature_names = features, plot_type = 'grid') # type of the interact plot, can be ‘contour’ or ‘grid’output 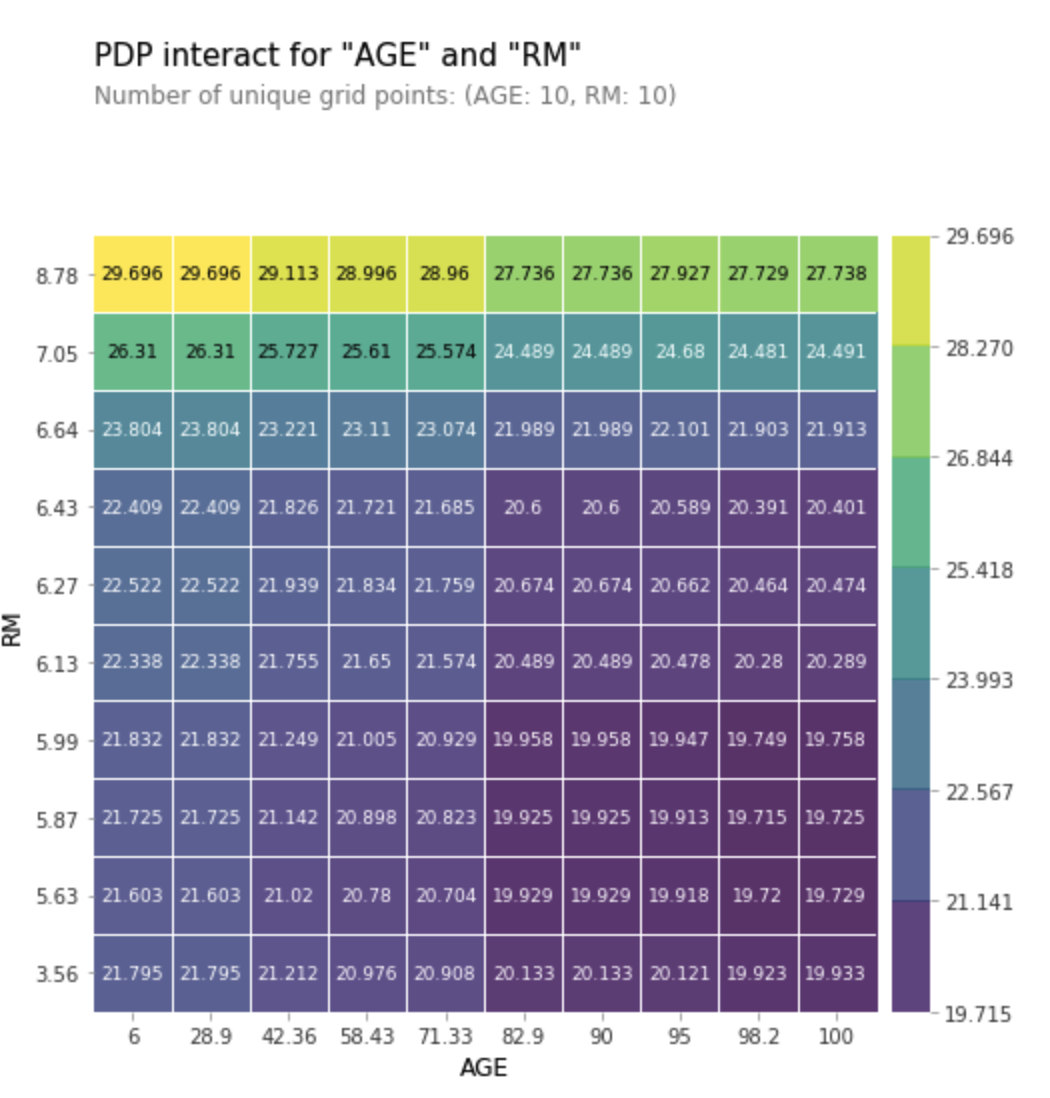
- SHAP 라이브러리를 사용해 최소 3개 이상 시각화를 하고 분석하기
### (Urclass Quiz) 이곳에서 과제를 진행해 주세요 ###
explainer = shap.TreeExplainer(model) #tree model의 shap values 확인 객체 생성
shap.initjs(); #이거 셀에 안 넣으면 JS 작동 안하는 듯.
### Draw SHAP plots ###
# 첫번째 샘플을 가지고 shap force_plot를 그려보자
row = X_train.iloc[[1]] #사용할 샘플
shap_values = explainer.shap_values(row) #shap values 계산
shap.force_plot(
base_value=explainer.expected_value,
shap_values=shap_values,
features=row
)# SHAP_2 - force plot 그려보자.
shap.initjs();
rows = X_train.iloc[:100] #샘플은 100개만
shap_values = explainer.shap_values(rows) #shap values 계산
shap.force_plot(explainer.expected_value, shap_values, rows)#Summary plot 그려보기
shap.summary_plot(shap_values, rows) #동일한 샘플에 대해 2번 아웃풋은 상단 개념 부분에 넣은 그림을 보면 됨.
정리
서로 관련이 있는 모든 특성들에 대한 전역적인(Global) 설명
- Feature Importances
- Drop-Column Importances
- Permutaton Importances
타겟과 관련이 있는 개별 특성들에 대한 전역적인 설명
- Partial Dependence plots
개별 관측치에 대한 지역적인(local) 설명
- Shapley Values
Feeling
- 오늘은 개념 간 차이를 구분하기가 처음엔 헷갈렸는데, 결과적으로는 잘 이해하고 넘어가는 것 같아 매우 기분이 좋다!
- 당장 내일모레부터 시작되는 개인 프로젝트 때나 혹은 나중에라도 복잡한 모델 다루면서 꼭 필요한 순간이 올 것이다. 세부적인 건 기억 못하더라도 종류, 사용 목적 키워드라도 꼭 기억해두자!!!
