Key words
트랜잭션(Transaction), ACID, 서브 퀴리, SQL 다양한 구문 연습
1. 트랜잭션 (transaction)
- 트랜잭션이란 단어를 처음 들었을 땐 어려울 것 같아서 쫄았는데, 개념 자체는 전혀 어렵지 않았다. 간단하게는 '데이터베이스의 상태를 변화시키는 작업의 모음'이라고 생각하면 된다.
- 세션에는 은행에서 송금할 때의 예시를 들어주었는데, 매우 직관적이어서 이해가 쉬웠다.
- 내가 철수에게 100만원을 송금하는 작업을 한다고 할 때, 세부적으로 보면 아래와 같은 단계로 나뉜다.
- 내 통장이 active한가? 확인.
- 내 통장에 100만원이 있는가? 확인.
- 내 통장에서 100만원 인출.
- 철수의 통장이 active한가? 확인.
- 철수의 통장에 100만원 입금!
- 내가 철수에게 100만원을 송금하기 위해 밟은 저 5개의 작업을 하나의 트랜잭션으로 볼 수 있다. 쉽죠?
- 만약 저 5개 중 하나라도 실패한다면, 그 전후의 어떤 작업도 실행되어선 안된다! (뒤에 ACID 얘기할 때 더 얘기할 거임)
- 내가 철수에게 100만원을 송금하는 작업을 한다고 할 때, 세부적으로 보면 아래와 같은 단계로 나뉜다.
- 여기서
Commit,Rollback의 개념을 다시 한 번 배우고 갔다. DBeaver로 SQLite 쓰면서는,Auto Commit설정이 디폴트로 활성화 되어있어서 몰랐는데, 굉장히 중요한 개념이었다!!- 트랜잭션은 확정 신호를 주어야 DB에 반영된다. 위 예시에서는 앞선 작업이 모두 성공한다면 최종적으로 '철수의 통장에 100만원을 입금해!'라는 '확정 신호'를 주어야 데이터 베이스에 반영되는데, 이 확정 신호를 commit이라고 한다.
- (참고로 트랜잭션은 DB의 상태를 변화시키는!!! 작업의 모음이므로, select 같은 단순 조회는 해당하지 않는다구~
INSERT, UPDATE, DELETE같은 걸 생각해야 한다) ROLLBACK은 commit의 정반대 개념이다.- 만약 아래와 같은 트랜잭션이 있다면 결과는? 어떨까? 앞의 작업은 rollback을 해주었으니 반영되지 않고, 뒤의 작업은 commit을 해주었으니, 결국
id4만 DB에 입력되게 된다.- 오늘 여러 경우로 이런 코드를 봤는데, 실제로 작업하다보면 중간에 실수하기 딱 좋아보였다!
BEGIN, END문으로 보완할 수 있을 것 같은데, 그건 뒤에서 다뤄보겠다.
- 오늘 여러 경우로 이런 코드를 봤는데, 실제로 작업하다보면 중간에 실수하기 딱 좋아보였다!
INSERT INTO user VALUES ('id3', 'user3');
ROLLBACK;
INSERT INTO user VALUES ('id4', 'user4');
COMMIT;2. ACID
ACID 는 Atomicity, Consistency, Isolation, Durability 를 가리킵니다. 각 단어는 데이터베이스 내에서 일어나는 하나의 트랜잭션(transaction)이 보장하는 성질입니다.
- ACID는 우리가 다뤄야할 무언가가 아니라 하나의 상태로 보면 될 것 같다.
- Atomicity (원자성)
All or Nothing을 기억하면 된다. 한 트랜잭션을 구성하는 작업은 모두 실패하거나, 모두 성공해야 한다는 거다.- 위 송금 예시에서 보면, 만약 내 통장에서 100만원 빼는 것까지만 성공해서 실행해버리고 뒤에는 실패한다면? 내 돈 어디갔어!!!! 내놔!!
- (그나저나 네이밍 센스는 진짜.. 왜 이래.. 원자성이 뭐야 원자성이..)
- Consistency (일관성)
- '하나의 트랜잭션 이전과 이후 데이터베이스 상태는 이전과 같이 유효해야 한다는 뜻이다'라고 하는데, 이 말이 더 어렵다.
- 그냥 '데이터 베이스에 정해진 규칙/제약을 지켜야 한다'로 기억하자.
- Isolation (고립성)
- 트랜잭션끼리는 독립되어 있어야 한다는 것이다.
- 만약 1억만 있는 계좌에 동시에 2개의 1억 인출 요청(트랜잭션)이 들어온다면? 먼저 들어온 트랜잭션만 실행하고 뒤에꺼는 잔액이 없으니 실패시킨다.
- 진짜 완전 동시에 요청을 넣어서 1억원의 부당 이득을 취하려는 범죄조직 시나리오를 떠올려봤지만, 완전 동시에 들어와도 순차적으로 하나의 트랜잭션씩 실행시키는 로직을 다 가지고 있다고 한다. ㅋㅋㅋ
- Durabilty (지속성)
- 트랜잭션 커밋 후 디스크에 저장된 DB의 상태는 유지되어야 한다. 즉, 트랜잭션의 성공/실패/오류 등의 기록이 영구적으로 로그 등으로 남아있어야 한다는 뜻이다.
SQL 이것 저것 추가 공부
- group by, having, 서브 쿼리, select 문 실행순서, 등등..
- 오늘 본걸 다 나열하기 보다는, 걍 실습한 부분에서 직접 써먹었던 것 중 어려웠던 것, 기억하고 싶은 것 적는 걸로 바로 고고!
5. 실습한 것
실습한 내용 중에 기억하고 싶은 것만 옮겨둔다. (참고로 오늘 실습도 DBeaver 통해 SQLite를 사용했다)
- upper, lower 함수는 sqlite에도 있다! 그리고 두 문자를 붙이는
||의 경우 sqlite에서는 저 기호를 쓰지만, Mysql에서는concat으로 쓴다.
SELECT c.CustomerId,
(UPPER(c.City) || ' ' || UPPER(c.Country)) AS '새로운 칼'
FROM customers c;SUBSTRING!! 특정 문자열만 순서를 지정해서 뽑아올 수 있다. 가령 1번째부터 4개의 문자열을 뽑아주세요~ 같이. 특이했던 건 여기서 시작은 0이 아니라 1이더라고?! (참고했던 글)
"SELECT (LOWER(SUBSTRING(c.FirstName, 1, 4)) || LOWER(SUBSTRING(c.LastName, 1, 2)) ) AS '새로운 컬'
FROM customers c;- 아하~ 이 친구도 재밌었지~ 일자 간 차이 구할 때 이렇게 하더라. 참고로 난 DAY Difference를 구한 거고, 시간 등 다른 건 이 글 참고하기.
SELECT e.EmployeeId
FROM employees e
WHERE (CAST((JULIANDAY('2020-01-01') - JULIANDAY(e.HireDate)) AS INTEGER)) >= 2555
ORDER BY e.LastName;- 서브쿼리 적은 건 걍 아무거나 하나 남겨둠.
SELECT (D.FirstName || D.LastName || D.InvoiceId) as 'new col'
FROM (SELECT i.InvoiceId , i.CustomerId, c.FirstName, c.LastName
FROM invoices i
JOIN customers c ON c.CustomerId = i.CustomerId
ORDER BY c.FirstName, c.LastName, i.InvoiceId) as D;- Primary key 여러 개일 때, 그냥 ()안에 연속에서 쓰면 되더라! 다른 언어는 Contraints로 묶어서 일종의 복합키로 표현하는 것 같던데. 암튼 참고!
CREATE TABLE Student(
teacher_id INTEGER NOT NULL,
student_id CHAR(4) NOT NULL,
age INTEGER NOT NULL,
PRIMARY KEY (teacher_id, student_id),
FOREIGN KEY (teacher_id) REFERENCES Teacher (id)
);- 다중 조건문!! 아~ 얘도 참 재밌었지.. SQL에는 IF문이 없다. 대신
CASE WHEN THEN ELSE END형태로 쓴다. 아래 코드 참고. (참고한 글)
SELECT name, subject, salary,
(CASE
WHEN salary < 3000 THEN 'Low'
WHEN salary < 4000 THEN 'Mid'
ELSE 'High'
END) AS '월급 그'
FROM Teacher;RANK(),Partition by얘가 오늘 제일 재밌었다. 파티션은 사무실에서 책상 파티션 나누듯이 랭크하는 기준을 쪼개는 거라고 생각하면 쉽다. (참고한 글)
SELECT teacher_id , student_id, (RANK() OVER (ORDER BY student_id)) as '전체 학생 순' FROM Student s ;
SELECT teacher_id , student_id, (RANK() OVER (PARTITION BY teacher_id ORDER BY student_id)) as '전체 학생 순' FROM Student s ;- 위 구문은 각각 아래 결과를 보여준다.
- 마지막으로, 아래 결과물을 뽑는 SQL문을 작성하는 문제가 있었다. 난 이걸 딱 중앙 열의 값을 뽑아오라는 걸로 해석했는데, 다르게 해석한 사람도 있던 것 같았다.

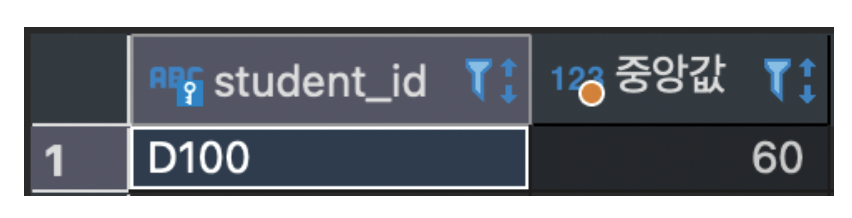
- 그리고
LIMIT을 이렇게도 쓸 수 있다는 거 처음 알았다. 신기했다. (근데 이건 첫 번째가 1이 아니라 0이더라고???!!) - 근데 칼럼이 홀수 개면 중앙을 어떻게 보고 뽑게 될까? 8개면 5번째 행이 뽑일텐데 그건 중앙이 아닌데.. 이건 뭘 뽑고 싶냐에 따라 다르겠지?

SELECT student_id, age as '중앙'
FROM Student
LIMIT ((SELECT COUNT(teacher_id) FROM Student) / 2), 1- INSERT할 때 만약 4개의 칼럼이 있는데, 3개의 값만 정확히 넣고 싶다면 어떻게 해야할까?
INSERT INTO table(col1, col2, clo4) VALUES(d1, d2, d4)와 같이 정확히 지정해주는 게 가장 안전하다고 한다!! 테이블 직접 생성할 일이 많이 있을까 싶기는 하지만 우선 기억하자!! (참고한 글)
그 외
- 데이터 베이스에 대한 기본 개념 소개하는 이 영상을 봤는데, 정말 좋았다. 나중에 다시 한 번 보도록 하자.
- DB 개념, metadata, query 날렸을 때 내부적으로 어떻게 동작하는지, Data Model 개념과 종류, DB schema, DB state(=snapshot), Three schema architecture 등등..
- 어제 SQL의 종류가 여러 개 있다고 했는데, 왜 그렇게 나뉘었는지도 영상을 보고 알 수 있었다.
Begin; End;에 대해 처음에 본 코드 예시에서Begin;만 쓰여있었는데, 도대체 그 역할이 뭔가 물어봐도 와닿지 않아 찾아봤다.- 정확한 정보는 반드시 공식문서를 통해 확인하는 버릇을 들이자. (그러면서도 위에 링크 건 게 다 공식문서가 아니네.. 머쓱..) 암튼 그래야 정보의 출처를 당당히 밝힐 수 있다.
- 동기 분이 아래와 같은 질문을 해주셔서
외래키 정책에 대해 찾아볼 수 있게 되었다. 여러 정책들이 있고, 이건 DB 디자이너가 설계 당시 어떤 정책을 채택하느냐에 따라 달라지는 것으로 이해하면 된다. - 집계함수 쓸 때, select문에 예를 들어,
id, 집계함수쓰고group by안 하면 Mysql은 에러 띄워주는 것 같은데, sqlite는 집계함수 대상 칼럼의 값이 있는(=null 빼고) 첫번 째 id값을 id로 보여주더라. 참고참고!
Feeling
- 오늘은 뭔가 체력적으로 후달리는 하루였다. 그래도 과제를 빨리 끝내서 배운 내용 정리할 시간이 충분해 다행이다.
- SQL 구문 짜는 건 너무 재밌어! 짜릿해! 적성에 맞는 것 같다ㅎㅎ 체력 안배 잘 하면서 열심히 해야지.
- 근데 어제 했던 생각을 오늘 또 했다. 이번에 SQL을 완전 처음 접한 분들은 정말 정말 헷갈리겠는데? 어려우신 분들 내가 아는 선에서라도 어떻게든 좀 도와드리고 싶은데,, 어떻게 말씀을 드려봐야할지.. 괜한 오지랖은 아닐지.. 동기들이랑 다 같이 끝까지 가고 싶다.

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.