Key words
인터페이스, DB API, 클라우드 데이터 베이스/온프레미스(on-premise) 데이터 베이스, sqlite3, connect/cursor
1. 인터페이스란?
- 오늘 웜업영상으로 이걸 봤는데, 인터페이스에 대해 깔끔하고 재밌게 정리해줘서 좋았다. 아침에 깔깔 거리면서 봤네ㅎㅎ
- 인터페이스란 '약속'이다.
- 예를 들어, A라는 함수를 호출하면 B라는 결과가 리턴된다. 티비 리모컨, 노트북 전원 버튼을 누르면 전원이 켜진다 등.
- 영상에서는 주로 식당의 호출벨로 예를 들었는데 아주 직관적이고 좋았다.
- API는 덩치가 큰 인터페이스로 생각해도 된다고 한다.
- 인터페이스 함수를 만들 때 고려해야할 사항 4가지!
- 직관적인 입출력!
- Simple is the Best! 명확하고 알기 쉽게 설계하는 것이 중요하다는 것이다.
- 예를 들어, 식당 호출벨이 '따 따 따 따'로 눌러야만 호출된다고 설계하면 사람들이 그걸 어떻게 알고 쓸 수 있겠냔 말이야~ (주석이 면죄부가 될 수는 없다는 말이 이 예시를 보니까 확 와닿았다ㅋㅋㅋ)
- 성능 요구사항!
- 요청을 하면 일정한 시간 내에는 어떤 응답이던, 그게 에러건 뭐건, 와야한다는 것이다.
- 호출벨 눌렀는데 10초가 지나도 아무도 안와! 뭐야! 계속 눌러봐! 근데 안 와!
- 하위호환지원
- 개발을 하다보면 중요한 개념이라고 한다. 이건 나름 이전에 SaaS 회사에 있던 짬밥이 있어서 듣기 전에 뭐에 관한 건지 알 수 있었다.
- MS가 이걸 상당히 잘 해준다고 한다. 하지만 하위호환지원이 능사가 아니다. 개발이나 관리 리소스 때문에.
- 프론트엔드 개발자가 15년 전 핸드폰 쓰는 사람의 오류 때문에 괴로워하던 짤이 떠올랐다ㅋㅋㅋ 제발 핸드폰 좀 바꾸세요!!!!
- 쉬운 접근성과 대중성
- 인터페이스는 누구나 아는 것이어야 한다. 호출벨을 보고 '이거 뭐야!'하고 아무도 안 쓴다면? 아무도 안 쓰면 안 만든거나 마찬가지라는 명언을 날려주셨다.
- 직관적인 입출력!
2-1 Python DB API
- 파이썬을 활용해 데이터베이스와 연결하는 걸 배웠다.
- (중간에 conn, cur 등 개념 공부하다가 문득 '아니 db 그냥 어제랑 엊그제처럼 DBeaver 연결해서 하면 되는거 아냐? 굳이 왜 이렇게 해야해?라는 근복적인 의문이 들었었다. 그때 위 문장을 떠올렸다! 나는 파이썬을 활용해 DB에 연결하고 원하는 데이터를 입력/출력하는 등의 작업을 하고자 하는 것이다!!)
- PEP249
- 파이썬에서 명시하는 DBAPI v2.0에 대한 문서이다. 쉽게 데이터베이스와 연결하는 파이썬 모듈을 제작할 때의 가이드라인으로 생각하면 된다. 이런 것도 만들어놓고 개발자들 진짜 대단하다.
- PEP은
Python Enhancement Proposals의 약자다. - (참고로
PEP8이라는 것도 있는데, 이건 code format에 관한 것으로 어떻게 하면 코드를 깔끔하고 효율적으로 쓸 수 있을지에 대한 문서라고 한다. 나중에 함 봐바야지)- 여하간 이런 가이드라인이 있기 때문에 다양한 데이터베이스를 동일한 형식의 API를 이용해 다룰 수 있는 것라고 한다. 무한 감사.. (반대로 생각하면 DB 만들 때도 이런 가이드라인을 지켜야 한다는 것!!)
- SQLITE
- SQLite 데이터베이스는 파이썬과 함께 설치되는 가벼운 관계형 데이터베이스이다.
- 즉, SQLite: DB 이름. / SQLite3: sqlite에 쓸 수 있는 python package로 생각하면 된다. 헷갈리지 말자구~
- SQLITE는 파일형 DB라서 데이터 손실에 주의해야 하지만, 가볍고 빠르기 때문에 단순 실험, 교육용으로는 좋다고 한다.
- 참고로 python 일정 버전 이상에서는 sqlite3가 기본적으로 설치되어 있어 import만 해주면 바로 쓸 수 있다.
2-2. SQlite3 기본 메소드
이건 중요하니까 별도로 빼서 기록해둔다.
- 데이터베이스 연결 및 커서 객체 생성
import sqlite3
conn = sqlite3.connect('DBname')
cur = conn.cursor()- Connect는 말 그대로 DB와 연결만 해주는 것이고, 데이터베이스와 소통하기 위해서는 cursor 객체가 필요하다.
- DBeaver를 예를 들면, connect는 '새 데이터베이스 연결' 버튼이고, cursor는 코드 실행할 때 쓰는 재생버튼으로 생각하면 된다. 난 이 예시 덕분에 팍 이해할 수 있었다. 굿굿.
- 참고로 conncect는 db가 아닌 (':memory:')에 연결해 실행할 수 있다고 하는데, 어디에 써먹게 될지는 잘 모르겠다. 휘발성이라 가볍고 빠르다? 글쎄..
- 커서 메소드 - 코드 예시는 실습 부분에 있기 때문에 키워드만 가져다 둔다.
cursor.execute
=> 가장 기본적인 DB 소통 방식.
conn.commit()
=> 어제까지와 마찬가지로 commit을 해줘야 DB에 최종 반영이 된다!!!!!!!!!
cursor.fetchone, cursor.fetchall
=> 데이터 조회할 때 쓸 수 있는 거다. 오늘 한 번도 안 써보긴 했다.
=> cur.execute("SELECT * FROM test_table;") 이렇게 조회하려고 하면 안된다.
=> one은 하나만, all은 전부 넘겨준다.
==> one 연속해서 3번 적으면 첫 값 하나만 3번 보여주는게 아니라 차례대로 3개의 값을 조회할 수 있는 건 참고!! 헷갈릴 수 있겠어.3. 클라우드와 데이터베이스
- 클라우드 데이터베이스가 뭔지, 온프레미스(on-premise) 방식에 비해 장단점은 무엇인지 배웠다.
- 로컬로 쓰면 관리비용 올라가고, 클라우드 쓰면 관리비용은 내려가지만 이용 비용이 올라가고, 로컬이 보안 좋고 등 상식 선에서 장단점은 생각해낼 수 있었다.
- URI
- URL은 들어봤는데, URI라고요?? 알고보니 URL은 URI의 하위 개념이라고 한다.
- 이 그림 하나면 딱 정리될 듯.
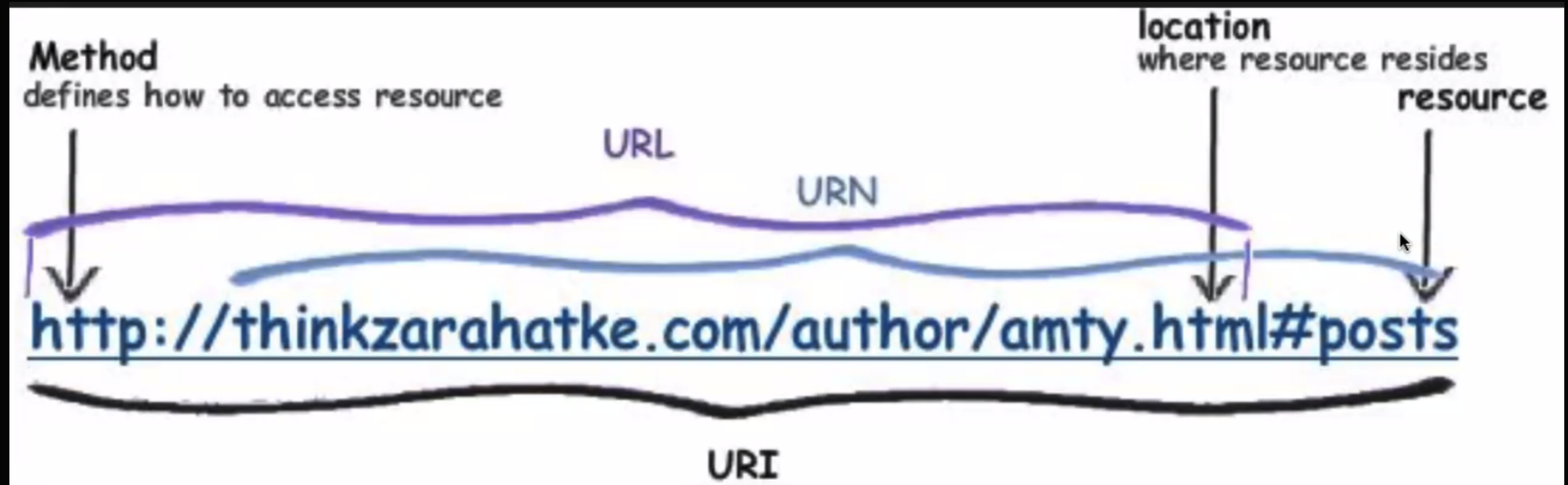
서비스://유저_이름:유저_비밀번호@호스트:포트번호/경로기억!
- ElephantSQL
- 무료로 제공하는 클라우드 DB 서비스인데, 어떻게 연결해서 사용하는지 보기만 하고 실제 써보지는 못 했다. 내일 도전과제 하다보면 해보게 될 것 같다.
- PostgreSQL 베이스다.
- 위 클라우드 데이터 베이스 서비스를 통해 DB를 생성하고, DBeaver에서 PostreSQL로 연결해 psycopg2를 활용하여 위에서 했던 conn, cur등등을 하는 것도 보았다. 역시 직접 해보진 않았고, 도전과제 하다보면 해보게 될 것 같다.
import psycopg2
conn = psycopg2.connect(
host="서버 호스트 주소",
database="데이터베이스 이름",
user="유저 이름",
password="유저 비밀번호")- 이런 식으로 처음에 connect하는 것만 다르고 나머지는 sqlite3에서 했던거랑 똑같긴하다. 클라우드와 온프레미스.. 흥미로워!
4. 실습한 것
실습한 내용 중에 기억하고 싶은 것만 옮겨둔다. (오늘은 VSCode만 사용)
문제
DB_API이라는 이름의 sqlite 데이터베이스를 과제의 setup.cfg가 있는 위치에 생성한다.- 데이터베이스에는
Albums_Part1,Albums_Part2,Albums_Part3라는 테이블이 각각 생성되어야한다.- 각 테이블에 주어진 list_data, dictionary_data, json_data를 입력해야 한다.
Albums_Part1
# 입력해야 하는 데이터 형태는 이랬다.
list_data = [
["AlbumId","Title","ArtistId"],
[1,"For Those About To Rock We Salute You",1],
[2,"Balls to the Wall",2],
[3,"Restless and Wild",2],
[4,"Let There Be Rock",1],
[5,"Big Ones",3],
[6,"Jagged Little Pill",4],
[7,"Facelift",5],
[8,"Warner 25 Anos",6],
[9,"Plays Metallica By Four Cellos",7],
[10,"Audioslave",8]
]conn = sqlite3.connect('DB_API.db') #db가 없는 경우 새로 생성된다.
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS Albums_Part1;")
cur.execute("""CREATE TABLE Albums_Part1(
AlbumId INTEGER NOT NULL,
Title NVARCHAR(160),
ArtistId INTEGER,
PRIMARY KEY (AlbumId)
)
""")
for i in list_data[1:]:
cur.execute("INSERT INTO Albums_Part1(AlbumId, Title, ArtistId) VALUES (?, ?, ?)", i)
conn.commit();Albums_Part2
# 주어진 데이터는 다음과 같았다.
dictionary_data = {
"Columns":["AlbumId", "Title", "ArtistId"],
"1" : ["For Those About To Rock We Salute You",1],
"2" : ["Balls to the Wall",2],
"3" : ["Restless and Wild",2],
"4" : ["Let There Be Rock",1],
"5" : ["Big Ones",3],
"6" : ["Jagged Little Pill",4],
"7" : ["Facelift",5],
"8" : ["Warner 25 Anos",6],
"9" : ["Plays Metallica By Four Cellos",7],
"10" : ["Audioslave",8]
}conn = sqlite3.connect('DB_API.db')
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS Albums_Part2;")
cur.execute("""CREATE TABLE Albums_Part2(
AlbumId INTEGER NOT NULL,
Title NVARCHAR(160),
ArtistId INTEGER,
PRIMARY KEY (AlbumId)
)
""")
for i in list(dictionary_data.items())[1:]:
k = i[0]
v1 = i[1][0]
v2 = i[1][1]
cur.execute("INSERT INTO Albums_Part2(AlbumId, Title, ArtistId) VALUES (?, ?, ?)", (k,v1, v2))
conn.commit();Albums_Part3
# 주어진 데이터는 다음과 같았다.
json_data = {
"DATA": [
{
"AlbumId" : 1,
"Title" : "For Those About To Rock We Salute You",
"ArtistId" : 1
},
{
"AlbumId" : 2,
"Title" : "Balls to the Wall",
"ArtistId" : 2
},
{
"AlbumId" : 3,
"Title" : "Restless and Wild",
"ArtistId" : 2
},
{
"AlbumId" : 4,
"Title" : "Let There Be Rock",
"ArtistId" : 1
},
{
"AlbumId" : 5,
"Title" : "Big Ones",
"ArtistId" : 3
},
{
"AlbumId" : 6,
"Title" : "Jagged Little Pill",
"ArtistId" : 4
},
{
"AlbumId" : 7,
"Title" : "Facelift",
"ArtistId" : 5
},
{
"AlbumId" : 8,
"Title" : "Warner 25 Anos",
"ArtistId" : 6
},
{
"AlbumId" : 9,
"Title" : "Plays Metallica By Four Cellos",
"ArtistId" : 7
},
{
"AlbumId" : 10,
"Title" : "Audioslave",
"ArtistId" : 8
}
]}conn = sqlite3.connect('DB_API.db')
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS Albums_Part3;")
cur.execute("""CREATE TABLE Albums_Part3(
AlbumId INTEGER NOT NULL,
Title NVARCHAR(160),
ArtistId INTEGER,
PRIMARY KEY (AlbumId)
)
""")
for i in range(0,10) :
data = json_data["DATA"]
t = list(data[i].items())
v1 = t[0][1]
v2 = t[1][1]
v3 = t[2][1]
cur.execute("INSERT INTO Albums_Part3(AlbumId, Title, ArtistId) VALUES (?, ?, ?)", (v1,v2, v3))
conn.commit();- 3번은 처음엔 json을 딕셔너리로 바꿔서 해보려고
import jason, loads()를 써봤는데 계속 오류가 났다. 여하간 다른 방법으로 풀긴했지만, range 범위가 지정되어있다보니 일반화해서 쓰긴 힘들겠구나, 어떻게 하면 좋을까 싶어 과제 제출이랑 깃헙 PR까지 마치고, 다른 분의 코드도 살펴보았다. 아래와 같이도 가능하더만?!! 기억하자.
for data in json_data['DATA']:
cur.execute("""INSERT INTO ALbums_Part3 (AlbumId, Title, ArtistId) VALUES (?, ?, ?);""",
(data["AlbumId"], data["Title"], data["ArtistId"]))오늘 실습은
- 어떤 플로우로 진행되는지만 잘 기억하면 될 것 같다.
- IDLE 켜놓고 각 데이터 형태별로 어떻게 원하는 자료만 뽑아낼 수 있을지 거의 실험적으로 해봤던 것 같다.
- 어려웠지만, 재밌었고! 다음에 동일한 작업을 할 때는 더 나아질 수 있을 것이란 확신이 들었다.
- 도전과제는 내일 해야겠다. 몸이 아프려고 해서 체력 안배가 필요할 것 같다.
Feeling
- 오늘은 오전부터 오후까지 너무 너무 피곤하고 계속 졸리고, 말 그대로 체력 딸리는 게 느껴져서 좋지 않았다. 이대로 무리하다간 아플 것 같은 느낌이 들었다. 2주 전에 대상포진에 걸렸었는데, 다시 도질까봐 후달렸다.
- 그렇다고 공부를 대충하거나 그러지는 않긴 했는데, 체력 안배 차원에서 도전과제는 내일로 미루기로 했다. 오늘 금요일이라 다행이지 만약 화요일쯤 되었다면 결국 어딘가 아팠을 것 같다.
- 여하간 오늘도 배운 건 정말 재밌었다! 스킬이 하나씩 늘어가는 것 같아 좋다. 물론 스킬 숙지의 방향성은 늘 고민하고 있다.
- 벌써 이렇게 한 스프린드(일주일)가 끝났다.. 시간 너무 빨라.. 정신 바짝 차리자.
고생 많았어~~ 셀프 칭찬해!

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.