Key words
GAN, DCGAN, CycleGAN
유투브에서 찾아본 Cycle GAN 논문 리뷰 영상인데, cycle gan 뿐 아니라 앞서 gan에 대한 구조 등 설명도 좋아서 링크 첨부해둔다.
1. GAN이란?
- GAN(Generative Adversarial Networks)은 실제와 유사한 데이터를 만들어내는 생성모델이다. 즉, GAN 모델의 목표는 실제와 유사한 이미지 등을 만들어내는 것이다. 대표적인 예시는 딥페이크(Deep Fake)가 있다.
- 그 외에도 colorized gan (흑백사진 컬러로 바꿀 수 있는거), 사진이나 영상을 웹툰화하는 필터 같은 것, 사진에 있는 사람을 움직이는 것처럼 보이게 하는 것, 옷 가상 착장 서비스 같은 것 등등..
- GAN을 번역하면 생성적 적대 신경망 정도가 되는데, 뭐가 생성적이고 뭐가 적대적이라는 걸까? GAN의 아이디어를 가장 많이 나타내는 예시로는 위조지폐범과 지폐감별사의 관계로 나타내는 것 같다.
- 위조 지폐범이 처음에는 보잘 것 없는 위조 기술로 감별사를 속일 수도 있었지만, 감별사도 위조 지폐를 많이 보다 보니 감별 기술이 올라감 > 위조범도 감별사를 속이기 위해 위조 기술이 향상됨 > 감별사의 감별 기술이 올라감 > 위조범의 위조 기술이 향상됨 > .... > ....
- 근데 나는 이 비유를 보고 생성자와 판별자는 생성자와 판별자 → 블랙해커와 화이트 해커?로도 볼 수 있지 않을까 했다. 해커가 꼭 진짜 같은 가짜를 만들어내는 건 아니지만, 여하간 뚫고 막고 또 뚫고 막고 하는 모순의 관계인 것 같아서.
- 이런 식으로 GAN 또한
생성자(generator)는 위조 지폐범처럼 실제와 동일한 데이터를 만들기 위해 노력하고,판별자(discriminator)는 지폐 감별사처럼 생성된 데이터가 진짜인지 아닌지 판단하게 된다. 처음에는 생성자와 판별자의 성능이 좋지 않지만 둘이 뚝딱뚝딱 하면서 생성자의 성능이 올라가게 된다.- 조금 유식하게 말하면 길항 작용을 하는 두 네트워크가 서로 경쟁하면서 발전한다.
- 자 마지막 문장에서 말한 것처럼 결국 GAN의 목적은 실제 있을법한 이미지를 만들어내는 것이기 때문에, 판별자는 생성자의 성능을 높이기 위한 카운터파트일 뿐 결국 중요한 건 생성자다. 이건 기억하고 넘어가자~!
- 아래 이미지는 고양이 그림을 그리는 GAN 모델에서 생성자, 판별자의 역할을 나타낸 것이다. 생성자는 거의 노이즈 수준의 이미지부터 생성을 시작하고, 판별자는 이 이미지를 Fake/Real이진 분류를 수행한다.
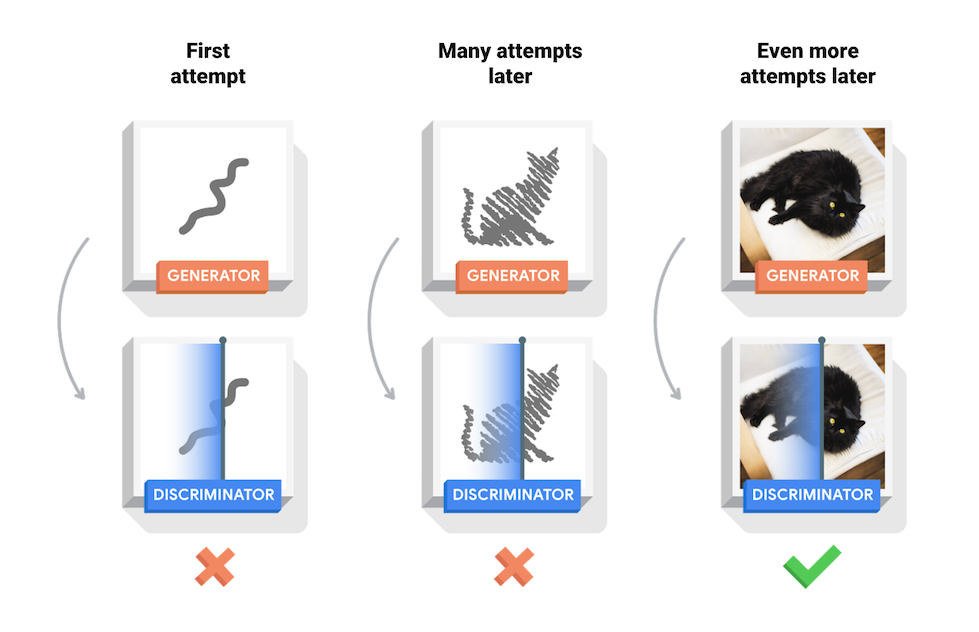
- 학습을 잘 마친 GAN 모델의 경우 생성자가 생성한 이미지를 판별자가 제대로 fake, real 구분을 하지 못하게 된다. (accuracy가 0.5에 수렴한다는 의미)
- 아래 이미지는 GAN의 구조를 표현한 것인데, 위 이미지보다 아래가 구조를 이해하는데 더 도움이 됐던 것 같다. (출처는 맨 위 첨부해둔 영상)
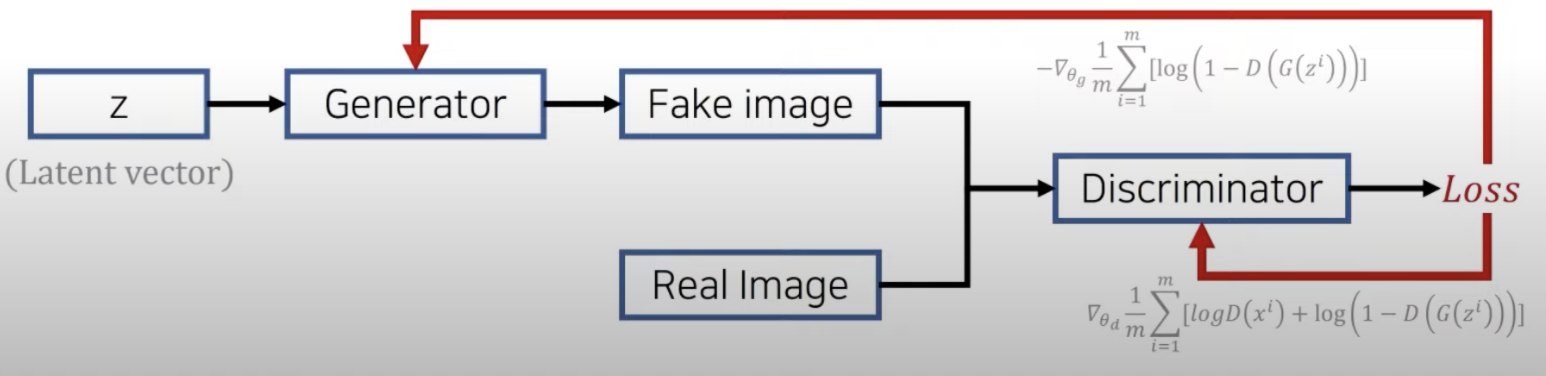
- 여기서 Latent vector가 어제 배운 그건가 해서 물어봤는데, 그건 아니고 말 그대로 그냥 정해지지 않은 잠재적인 벡터라는 뜻으로 생각하면 된다고 했다.
생성자: 진짜같은 가짜 이미지를 만들어냄.- random noise를 사용해서 판별자를 속일 수 있는 가짜 이미지를 만들어내는 것이 목표.
판별자: 진짜 이미지를 가지고 생성자가 만든 이미지의 가짜/진짜 판별- 판별자로부터 나온 Loss에 대해 판별자와 생성자 모두 역전파를 통해 재학습하며 가중치 갱신
- 즉, GAN의 손실함수(BinaryCrossentropy)는 생성자의 손실과 판별자의 손실 모두를 고려한다.
- 관련해서 했던 질문
판별자의 손실함수는 real_loss와 fake_loss를 더한 값입니다.라는 말의 의미를 판별자는 진짜와 가짜 모두를 잘 구분해내야하기 때문에 그 loss를 줄이는 방향으로 학습한다는 것으로 이해했는데 맞나요? 반대로 생성자는 판별자에 의해 fake라고 판별된 결과에 대해 loss를 줄여야 하니까 Fake로 판별된 것의 loss를 줄이는 쪽으로 학습되는 것을 의미하는 거구요. > 맞다고 함.
- 참고로 GAN이 나오게 된 아이디어는 모든 데이터는 통계적인 평균치를 가지고 있다. 즉, 분포가 존재한다는 거였음.
중요한 것!!!
- GAN도 비지도 학습이다!!!!!! 정답이 없는 문제에 대해서 새롭게 이미지를 생성하는 거니까.
- 비지도학습이라고 하면 학습을 할 때 레이블이 들어가지 않는 것을 말한다. GAN 모델을 보면 훈련 데이터만 넣어준다.
오늘 GAN 코드 예제에서는 Convolution Layer로 이루어진 DCGAN(Deep Convolution GAN)을 통해 MNIST 손글씨를 생성하는 것을 다루는 것을 보았다.
- 참고로 일반 GAN은 Fully connected Layer로 되어있어 블랙박스라는 단점이 있는데, 합성곱 신경망을 적용하면 모델이 학습하는 중간중간 결과물을 출력해서 볼 수 있는 장점이 있다고 한다.
- 참고로 신경망을 사용하기 때문에 이전에 한국-서울+도쿄 = 일본 과 같이 했던 것이 이미지에도 적용할 수 있다고 한다!! 안경쓴 남자 사진에서 남자를 빼고 여자를 넣으면 안경 쓴 여자가 나오는 식으로. 신기신기.
- 이 코드는 코딩 과제에서 참고해 사용해보았으므로 옮겨두진 않겠다.
2. Cycle GAN
- CycleGAN에 대해 알아보기 전에 GAN 기술의 발전 과정 참고!

- 으레 그러하듯 앞 단계 모델의 한계를 타파하기 위해 나온게 다음 모델이라고 할 수 있다.
- CycleGAN의 장점은 바로바로~ 훈련 데이터가 Unpaired 해도 된다는 거다! 서로 변환하고 싶은 두 스타일의 이미지를 따로 구해도 된다. 꼭 매칭되지 않아도 된다는 뜻.
- 앞선 모델인 Pix2Pix에서는 훈련 데이터셋을 구성할 때 레이블에 해당하는 데이터를 무조건 매칭해서 넣어줘야 했다. 예를 들면 흑백 사진을 컬러로 변경하는 모델을 만들기 위해 흑백 사진 만 장을 구해왔다면, 똑같이 해당 흑백사진 별로 매칭되는 컬러사진도 만 장이 필요한 것이다. 현실적으로 쉬운 일이 아니다.
- Cycle GAN이란 DCGAN의 구조를 변경하여 만든 새로운 구조라고 한다. Cycle GAN의 목표는 특정 이미지의 도메인을 다른 이미지에 적용하는 것이다.
- 무슨 말인지 이해하기 위해 Cycle GAN을 적용한 아래 예시 이미지를 보도록 하자.

- 위 이미지와 같이 과일 색 바꾸기, 오렌지를 사과로 바꾸기, 겨울 산을 여름 산으로 만들기 등이 가능하다.
- 이따 구조 부분에서 얘기하겠지만, 원본 데이터의 상실을 막기 위해 Cycle을 돌리는 구조 때문에 아예 둥근 오렌지를 네모난 사과로 바꾸는 것처럼 원본에 있는 형태 자체를 바꾼다거나 할 수는 없다. 이걸 단점이라고 얘기하는 사람도 있지만 GAN이 나오게 된 이유를 생각해보면 그걸 단점으로 볼 수는 없다는 의견도 있다.
- Cycle GAN의 구조는 아래와 같다.

- 특징적인 것은 생성자와 판별자가 모두 각각 2개 씩이라는 것이다.
- 그림의 화살표를 잘 보면 알겠지만, 각각의 생성자는 말 > 얼룩말, 얼룩말 > 말로 바꿔주는 역할을 한다.
- 판별자 또한 각각에 대해 Real/Fake 판별을 진행한다.
- 즉, 정리하면 아래와 같다.
- A 이미지를 입력하여 A→B 생성자를 통해 B 이미지를 생성한 후 B 판별자를 통해 판별한다.
- 생성된 B 이미지를 B→A 생성자를 통해 다시 A 인풋과 같은 형태로 생성할 수 있도록 한다.
- 이렇게 변환 후 다시 원본 이미지로 변환하는 과정을 한 번 더 밟기 때문에 Cycle Gan이라고 불린다. 여기서 한 번 더 돌려주는 이유는 GAN의 데이터셋이 Unpaired한 특성을 갖기 때문이다. 예를 들어 오른쪽을 보고 있는 말을 얼룩말로 만들기 위해 왼쪽을 보고 있는 얼룩말을 넣고 거기서 끝내면, 원래 오른쪽을 보고 있던 말은 결국 왼쪽을 보게 된다고 한다. 원본 데이터의 특징을 상실하는 것이다. 그걸 방지하기 위한 것.
오늘 Cycle GAN을 구현한 예제 코드까지 보지는 않았다.
4. 실습한 것
아래는 Lecture Note에 있는 생성자 생성 함수입니다. (...)
- Upsampling 층을 통과한 후의 이미지 shape에 대해 적어주세요.
def make_generator_model():
generator_input = tf.keras.layers.Input(shape=(100,), name='generator_input')
x = generator_input
x = tf.keras.layers.Dense(7*7*256, use_bias=False)(x)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Reshape((7,7,256))(x)
x = tf.keras.layers.UpSampling2D()(x) # => 이전 레이어의 (7,7,256)를 받아 (14, 14, 256)로 업샘플링.
x = tf.keras.layers.Conv2D(128, 5, strides=1, padding='same', use_bias=False)(x) # => (5,5) 필터 사이즈를 128개 생성. stride = 1, padding = 'same' 옵션이 있으므로 통과 후 쉐입은 (14, 14, 128)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.UpSampling2D()(x) # => (28, 28, 128)
x = tf.keras.layers.Conv2D(64, 5, strides=1, padding='same', use_bias=False)(x) # => (28, 28, 64)
x = tf.keras.layers.BatchNormalization()(x)
x = tf.keras.layers.LeakyReLU()(x)
x = tf.keras.layers.Conv2DTranspose(64, 5, strides=1, padding='same', use_bias=False)(x) # => (28, 28, 64)
x = tf.keras.layers.Conv2DTranspose(1, 5, strides=1, padding='same', use_bias=False, activation='tanh')(x) # => (28, 28, 1)
generator_output = x
return tf.keras.models.Model(generator_input, generator_output)
model = make_generator_model()
'''
# 참고
- Conv2DTranspose에서 padding = "same"을 걸면 input size * stride = output size가 되도록 padding을 해준다. 출처 https://velog.io/@hayaseleu/tf.keras.layers.Conv2DTransposeoutput-shape-%EC%A0%95%EB%A6%AC
- Con2D에서는 padding = "same", stride = (2,2)일 때 절반으로 사이즈를 줄여준다. pmhttps://stackoverflow.com/questions/69709010/keras-conv2d-strange-i-use-padding-same-but-the-size-is-still-reduced
헷갈리니 잘 기억해두자.
'''
Upsampling + Conv2D가Conv2DTranspose를 대체할 수도 있다는 점도 기억해두자.
구글 QuickDraw 데이터셋을 다시 활용해 고양이를 그려내는 GAN 만들어보기
데이터를 불러오는 단계를 제외하고 GAN 구현 코드가 일부도 주어지지 않아서 살짝 당황하기도 했지만~ 거의 렉쳐 노트에 있는 코드를 이해하고 옮겨오면서 구현해보았다. 난이도가 상당하게 느껴졌다. 나중에 GAN 모델을 만들게 된다면 아마 다시 레퍼런스를 찾아보며 하게될 것 같다.
- GAN의 생성자와 판별자를 각각 만드는 것, 그 과정을 눈여겨봐야 한다.
- 아참 참고로 GAN은 이렇게 하나도 제대로 만들기 어려운 모델을 2개나 만들어야하기 때문에 학습이 잘 안되는 모델로 유명하다고 한다. 붕괴되기도 한다고.
[훈련 데이터 불러오기]
import tensorflow as tf
import json, glob, imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import time
from IPython import display
from tensorflow.keras import layers
from tensorflow.keras.utils import get_file
BASE_PATH = 'https://storage.googleapis.com/quickdraw_dataset/full/binary/'
path = get_file('cat', BASE_PATH + 'cat.bin')
import PIL
from PIL import ImageDraw
from struct import unpack
from sklearn.model_selection import train_test_split
def load_drows(path, train_size=0.85):
x = []
# 파일을 풀고 낙서를 하나하나 모은다. 낙서는 15바이트 헤더로 시작한다.
with open(path, 'rb') as f:
while True:
img = PIL.Image.new('L', (32, 32), 'white') # 8-bit pixels, black and white #https://pillow.readthedocs.io/en/stable/handbook/concepts.html#concept-modes
draw = ImageDraw.Draw(img)
header = f.read(15)
if len(header) != 15:
break
# 낙서는 x,y 좌표로 구성된 획(stroke) 목록으로 되어 있고, 각 좌표는 분리되어 저장되어 있다.
# 방금 위에서 생성한 ImageDraw 객체의 좌표 목록을 이용하기 위해 zip()함수를 사용하여 합쳐준다.
strokes, = unpack('H', f.read(2))
for i in range(strokes):
n_points, = unpack('H', f.read(2))
fmt = str(n_points) + 'B'
read_scaled = lambda: (p // 8 for
p in unpack(fmt, f.read(n_points)))
points = [*zip(read_scaled(), read_scaled())] # zip 함수
draw.line(points, fill=0, width=2)
img = tf.keras.utils.img_to_array(img)
x.append(img)
x = np.asarray(x) / 255
return train_test_split(x, train_size=train_size)
# 입력받은 10만개의 고양이 낙서 데이터를 활용할 수 있다.
x_train, x_test = load_drows(path)
print(x_train.shape, x_test.shape) # ((104721, 32, 32, 1), (18481, 32, 32, 1))- 참고로 렉쳐노트 예제에서는 데이터 정규화시
127.5로 나누어서 데이터의 범위를-1~1사이로 두었는데, 이는 경험적으로 이렇게 정규화하니 가장 성능이 잘 나오더라~ 하는 것이라고 한다.
오늘 학습한 기본적인 GAN을 활용하여 고양이 그림을 그려내는 여러분만의 GAN을 만들어보세요!
다음과 같은 내용을 숙지하며 과제를 진행해달라고 했는데 이것도 참고하여 코드를 볼만 하다.
- 입력 이미지 shape이 변했을 때, 어느 부분을 수정해야 하는가
- MNIST를 학습하는데 사용했던 EPOCH 수가 해당 데이터셋에서 생성자가 고양이 그림을 생성해내는데 충분한가
BUFFER_SIZE = 104721 # => 전체 데이터셋 갯수로 지정함.
BATCH_SIZE = 256
# 데이터 배치를 만들고 섞기.
train_dataset = tf.data.Dataset.from_tensor_slices(x_train).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
'''
[기록]
레퍼런스
https://kyuns96.tistory.com/3
https://helloyjam.github.io/tensorflow/buffer-size-in-shuffle/
https://velog.io/@crosstar1228/tensorflowtf.data.Dataset-%ED%81%B4%EB%9E%98%EC%8A%A4-%ED%8C%8C%ED%97%A4%EC%B9%98%EA%B8%B0
- shuffle을 하는 이유는 원래는 mnist 손글씨 예제에서는 1-9 숫자로 이루어졌기 때문에 한 번 섞어서 배치에 1만 들어가 있거나 하는 걸 막기 위해서다.
- 이번 데이터는 그렇지는 않아서 빼도 되긴 하지만, 연산에 무리가 있는 수준은 아니므로 코드를 빼진 않았다.
- 배치를 나누는 이유는 한번에 대량의 데이터를 넣으면 메모리가 터질 수도 있으니까 나눠서 학습해주는 것임.
'''### Deep Convolution GAN으로 모델링 ###
# generator 생성
'''
# 노트에서는 input shape이 (28,28, 1)이었지만, 위 훈련 데이터는 (32,32,1)이므로 이에 맞추어 층을 쌓아 out shape을 만들어야 한다.
맨 마지막 층에서 output shape부터 적어두고 차근차근 위로 올라오며 필요한 부분 수정해보았다.
'''
def make_generator_model():
"""
모델을 구축하는 함수입니다.
"""
model = tf.keras.Sequential()
model.add(layers.Dense(4*4*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((4, 4, 256)))
assert model.output_shape == (None, 4, 4, 256)
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 8, 8, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 16, 16, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 32, 32, 1) # => 훈련 데이터와 같은 사이즈로 출력.
return model
- ReakyReLU는 ReLU랑 거의 비슷하게 생김.
# 생성자로 이미지 한 번 생성해보기 (노트 따라하기)
generator = make_generator_model()
noise = tf.random.normal([1, 100]) # => 생성자는 처음엔 아무 의미가 없는 노이즈(=임의의 데이터)로부터 시작한다는 것
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray') # => 일단 생성은 잘 되는구나..! 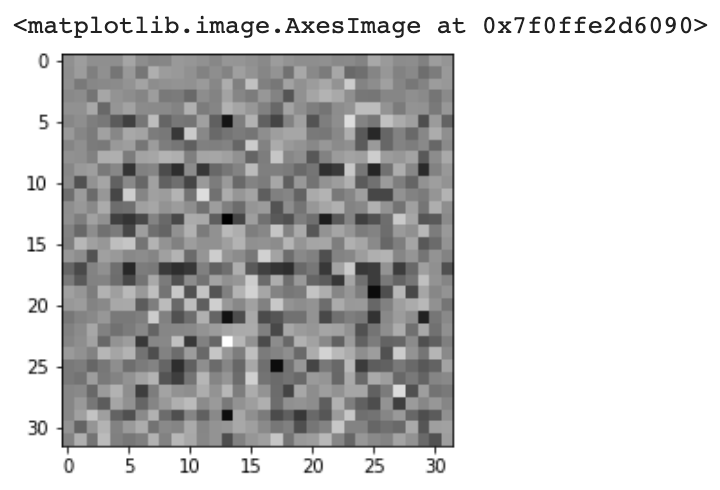
# Discriminator 생성
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[32, 32, 1])) # input shape (32, 32, 1) !!
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model# 위에서 생성한 이미지 판별자에 돌려보기
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print(decision) # 실제(Real) 이미지에는 양수(Positive)를, 가짜(Fake) 이미지에는 음수(Negative)를 출력하도록 훈련된다.
#=> tf.Tensor([[-0.00103436]], shape=(1, 1), dtype=float32)# 손실함수 정의
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True) # => 참고 https://runebook.dev/ko/docs/tensorflow/keras/losses/binarycrossentropy
def discriminator_loss(real_output, fake_output):
"""
"""
real_loss = cross_entropy(tf.ones_like(real_output), real_output) # => ones_like 참고 https://runebook.dev/ko/docs/tensorflow/ones_like
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss # 둘 다 못 맞추는 걸 줄여 나가야 함.
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output) # 진짜여야 하는데 판별자한테 fake로 걸러진 이 loss를 줄여야 함.
# 옵티마이저 정의
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
- 판별자의 손실함수는
real_loss와fake_loss를 더한 값이다. 아래 말 기억!- "
real_loss의 경우 전체가 1인 행렬과real_output을 비교하여 구하며fake_loss의 경우 전체가 0인 행렬과fake_output을 비교하여 구합니다. 생성자의 손실 함수는 전체가 1인 행렬과fake_output을 비교하여 구합니다."
- "
## 모델 구축 ##
# 모델이 저장될 체크포인트 지정 (chekpoint 의미 참고 https://www.tensorflow.org/guide/checkpoint?hl=ko)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
# 훈련 루프 지정
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
seed = tf.random.normal([num_examples_to_generate, noise_dim])
# 생성자, 판별자의 학습 지정
def train_step(images):
"""
위에서 정의한 손실함수를 바탕으로
Iteration(=step) 마다 가중치를 갱신합니다.
Args:
images: 훈련 데이터셋에 있는 실제 이미지입니다.
"""
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))# 학습 중간에 진행 내용 확인용 함수
def generate_and_save_images(model, epoch, test_input):
"""
모델이 이미지를 생성한 후 저장하는 함수입니다.
Args:
model: 이미지를 생성할 모델입니다.
epoch: 진행 중인 Epoch 숫자입니다.
test_input: model에 입력되는 데이터입니다.
"""
# training=False 이면 모든 층이 추론(inference)모드로 진행됩니다.
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()def train(dataset, epochs):
"""
학습 중 실행할 동작을 함수로 정의합니다.
Args:
dataset: (훈련) 데이터셋입니다.
epochs: 최종 학습 Epoch 입니다.
"""
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# 이미지를 생성한 뒤 저장합니다.(추후에 만들 GIF를 위함입니다.)
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
# 15 에포크가 지날 때마다 모델을 Checkpoint에 저장합니다.
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
# Epoch 마다 소요 시간을 출력합니다.
print(f'Time for epoch {epoch + 1} is {time.time()-start} sec')
# 마지막 에포크가 끝난 후 이미지를 생성합니다.
display.clear_output(wait=True)
generate_and_save_images(generator, epochs, seed)%%time
train(train_dataset, EPOCHS) # EPOCHS = 50
형편없지만.. ㅎㅎ,,, 그래도..ㅎㅎ
참고로 특정 epoch의 이미지를 가져오려면 아래와 같은 함수를 활용할 수 있다.
def display_image(epoch_no):
"""
특정 Epoch에 생성된 이미지를 불러오는 함수입니다.
Args:
epoch_no: 특정 Epoch에 해당하는 숫자입니다.
"""
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))Feeling
- 오늘 배운 기술들은 꼭 세상에 올바른 방향으로 쓰였으면 좋겠다는 생각을 했다. "있을 법한 가짜 이미지"를 만든다는 말 자체가 주는 무게감만큼이나 악용되었을 때 파괴적일 것이기 때문이다.
Don't be evil - 코드 구조 이해하기 어려웠고 아직도 어려워~!!!!

B2B SaaS 회사에서 Data Analyst로 일하고 있습니다.