Section4 딥러닝 개인 프로젝트
- 진행 기간: 7월 23일 ~ 7월 26일
- Deep Learning 프로젝트 목표
- 내가 설정한 포지션에서 적합한 데이터셋을 구한 뒤 그에 맞는 가설을 세우고 가설을 검증합니다.
- 가설 검증을 위한 딥러닝 파이프라인을 구축합니다. 구축한 파이프라인은 완벽하지 않아도 되며, 큰 가설의 일부(곁 가지)에 대한 검증을 목표로 해도 좋습니다.
- 모자란 부분에 대해서는 이후 프로젝트를 통해서 연계해 나가도 좋으며 이런 부분은 '한계점 및 추후 발전 방향' 등을 통해 제시해 주어도 됩니다.
- 프로젝트 전반의 과정에서 데이터선정, 모델 선택 등 완전한 자유가 주어졌다.
- 발표는 5-10분 사이로 녹화해야했고, 청자로 주어진 대상은 없었다.
진행 내용
진행 내용, 어려웠던 점, 해결한 방식 등을 최대한 상세히 노션에 기록하며 프로젝트를 진행했다. 그 중 핵심 내용만 여기에 옮겨오며 과정을 회고해 보고 느낀 점을 남겨둔다. (코드를 옮겨두진 않을 거다)
프로젝트 구조를 짜며 기본적인 파트 구분은 아래와 같이 했다.
데이터 선정/가설 수립>데이터 전처리>딥러닝 모델링 및 모델 검증/해석>발표자료 준비 및 제출
하지만 실제로는 모델링과 전처리 등을 왔다갔다 했다.
- 따라서 아래의 파트 구분은 프로젝트를 실제 진행하며 밟았던 과정을 기준으로 했음을 밝힌다.
1. 데이터 선정 / 가설 수립
가장 먼저 해야할 일은 어떤 주제로 딥러닝 프로젝트를 진행할지 정하는 것이었다.
- 분야에 대해서는 크게
자연어 처리와이미지 처리둘 중 하나를 골라야겠다는 생각을 했다. - 주제에 대해서는 그저 딥러닝을 사용해야하는 프로젝트니까 거기서부터 주제를 골라나가는 순서가 아니라, 내가 관심있어 설정한 문제에 딥러닝 기술이 어떤 진정한 의미가 있기 때문에 적용해보는 순서로 정해보려고 했다.
- 이렇게 해야 젓가락을 쪼개기만 하면 되는 문제를 거대한 톱을 가지고 와 해결하려 하는 것 같은 실수를 안 할 수 있겠구나 싶었다. 또 어떤 특별한 의미 없이 그저 딥러닝 사용만을 위한 딥러닝 사용을 하기는 싫었다.
일단 분야를 정하는 것에 있어서는 다음과 같은 과정을 거쳐 자연어 처리로 정하였다.
- 이전 회사에서 자연어 처리 프로젝트하는 걸 처음부터 지켜봤는데, 기업이 고객을 이해하는데 있어서 좋은 자연어 처리 기술이 가지는 가능성을 볼 수 있었다. 창업 아이템을 정한다고 이것저것 정보를 모으며 막연히 인사이트를 뽑겠다고 할 때도 마찬가지 생각을 했다. 그 이후로 자연어 처리 기술에 막연하지만 꾸준히 관심을 가지고 있었다.
- 내가 데이터 분석가가 되면 대부분의 시간을 보낼
데이터 전처리작업도 많이 해볼 수 있을테니 도움이 되겠다 싶기도 했다. 자연어 처리는 데이터 전처리가 전체의 거의 90% 가까히 차지한다는 얘기를 들었었다. 섹션3 데이터 엔지니어링을 거치며 데이터 다루는 감이 좀 떨어졌을 수도 있겠다는 걱정이 들던 참이었다. - 사실 코치님의 말에 의하면 그냥 이미지 처리를 선택하는게 좀 더 쉬운 선택일 수도 있었다. 단기간에 트랜스포머 등을 모두 이해하고 프로젝트에 적용하기에는 상대적으로 더 어렵기 때문에 이전 기수에서도 자연어 처리보다는 이미지 처리 쪽을 주제로 선택한 게 훨씬 더 많았다고 했다. 내 생각도 그랬다. 자연어 처리는 이미지 처리에 비해 난이도가 더 높아보였고, 짧은 프로젝트 기간 내에 데이터 전처리부터 모델에 대한 이해와 적용까지 모두 적용할 수 있을지 걱정도 들었다.
- 하지만 그렇다고 더 쉽다는 이유로 선택하고 싶지는 않았다. 더 쉬운 선택이라고 내가 자꾸 표현하는 이유는 나에겐 이미지 처리는 거의 블랙박스에 가까웠기 때문이다. 무슨 말이냐면 이미지 데이터 넣어주고 모델만 코드 참고해서 짜주면 모델이 알아서 어떤 결과를 내주는데 내가 그 과정을 정말 조금이라도 이해하고 있냐고 하면 그건 아닌 것 같았다. 앞에서 내가 하기 싫다고 했던 기술의 사용만을 위한 기술의 사용을 하게 될 것 같아 싫었다.
- 이런 이유들 때문에 못 먹어도 고! 자연어처리 쪽을 일단 해보자고 결정했다.
주제에 대해서도 고민이 많았는데, 고객 상담을 보조하는 챗봇 기능을 구현해보자고 정했다.
- 일단 내 백그라운드도 그렇고 관심사도 이커머스 쪽에 주로 쏠려있었는데, 많은 쇼핑몰 운영자와 소통을 하며 느낀 건 그들에게 고객 상담은 굉장히 리소스가 많이 드는 피곤한 일이라는 것이었다. (이건 쇼핑몰 운영자를 CS 해주던 내 입장에서도 마찬가지였다.) 굉장히 간단하고 반복적인 소통처럼 보여도 그들은 처리를 위해 생각보다 많은 일을 해야 한다. 그래서 막연하게나마 챗봇으로 이런 문제를 도와줄 수 있는 건 없을까? 생각하게 되었다.
- (뒤에 말하겠지만 이 막연함이 후에 조그만 실패를 가져다 주기도 했다)
- 그럼 일반적으로 흔해빠진 FAQ 기반의 챗봇을 만들고 싶었던 거냐? 그건 아니었다. 왜냐면 나 스스로가 고객으로서 이런 FAQ 기반의 챗봇 때문에 화났던 경험이 한 두번이 아니었기 때문이다. 뭘 이렇게 고르라는게 많은지, 그렇게 골라서 들어가면 내가 원하는 답이 없어 결국은 상담원 연결해서 처음부터 다시 설명해야 하는 상황위 반복으로 이에 대한 안 좋은 경험이 있었다.
- (챗봇이 운영자의 리소스 감소만을 위해서 존재하는 건 아니지 않은가? 고객이 편해야 하는 건 기본인데 많은 회사가 챗봇을 도입할 때 그 의미를 운영자 편의적으로만 보는 경우가 많다고 생각한다.)
- 그리고 결정적으론 그냥 저냥한 챗봇 만들겠다고 하면 차별성도 없고 재미도 없을 것 같기도 했고.
- 그렇다면 결국은 템플릿을 정해놓고 고객이 눌러서 정보를 얻는게 아니라, 상담원과 직접 대화하는 것과 비슷한 경험이 가능한 챗봇을 만들고 싶다는 것이었다.
물론 생각이 여기까지 미쳤다고 해서 주제에 대한 확신을 가졌던 건 아니다.
- 이쯤에서 기술적으로 짧은 시간 내에 구현이 가능할지도 알아봐야 했다. 가장 많이 참고한 건 혜성처럼 등장했지만 불꽃처럼 산화해버린
이루다서비스였다. 이 블로그 자료와 이루다 개발사 대표님이 초기 개발 히스토리를 설명한 이 발표에서 많은 정보를 얻을 수 있었다. 기술 구현 자체뿐 아니라 이루다로 불거졌던 이슈에 대해 내가 만들 챗봇이 가질 수 있는 문제에 대한 생각도 많이 해볼 수 있었다. - 처음에는 '아 위 이루다 발표 영상에 나온 루다 프레임워크처럼 고객이 질문을 넣으면 DB에 있는 과거 상담 데이터를 기반으로 코사인 유사도를 통해 비슷한 질문을 찾고, 그 답을 리턴해주면 되겠다'고 생각했다. 코사인 유사도는 노트 때도 해본 적 있으니까 그리 어렵지는 않을 것 같다는 생각도 들었다.
- 예를 들면
질문(input)이 들어온다 > 질문 텍스트 전처리 및 이해 (via BERT) > 코사인 유사도를 통해 비슷한 질문을 찾아준다 > 비슷한 질문의 답변을 확인한다 > 답변 후보들 중 가장 적절한 1개를 뽑는다 > 출력한다.의 구조이다.
- 예를 들면
일단 여기까지 오는데 상당한 시간이 이미 흘러버린 시점이었기 때문에, 더 확신을 가지려고 고민하기보단 관련 데이터 찾아서 기술적으로 MVP 수준으로라도 구현을 먼저 해보자, 그런 다음에 디테일은 늘려나가자는 전략을 택했다.
- 위의 주제로 진행한다고 했을 때 내가 필요한 건 고객 상담 데이터였다.
- 최종적으론 AI Hub의 소상공인 고객 주문 질의-응답 텍스트를 선택했다. 16개 업종의 질문-답변 데이터가 총 500만 건 정도 있어서 전처리만 잘 하면 내가 원하는 형태로 쓸 수 있겠다 싶었다.
- 16개 업종 중 난 패션 카테고리를 골랐다.
- 내 도메인에서 이커머스 고객사 중 가장 많은 것이 패션 카테고리였기 때문이다. 잘 만들면 그만큼 더 많은 임팩트를 낼 수 있는 것이다.
- 확장성을 생각해 처음부터 여러 카테고리를 써볼까도 고민해는데 상담 내용의 방향 자체가 달라 어려울 수 있으니 우선 하나만 해보고 여유가 되면 여러 카테고리로 확장해 적용해보기로 했다.
내가 세우고 넘어간 가설은 아래와 같다.
- 데이터 출처에서 말하는 것처럼 고객 문의에 자연스럽게 응대할 수 있는 챗봇이 있다면 대기업 뿐 아니라 많은 소상공인에게도 큰 도움이 될 것. (기업 입장)
- 지금의 FAQ 형식의 답변은 고객이 하나하나 선택해야 한다는 점에서 너무 불편함. (고객 입장)
결론적으론 좋은 목적지향형 챗봇 서비스는 양측 모두에게 만족을 줄 수 있을 것.
물론 모델링까지 다 해본 후에 카페 카테고리로 싹 바꾸긴 했는데, 그 과정은 후술하도록 하겠다. 이렇게 데이터를 확보했고 전처리 단계로 넘어갔다.
2. [시도1] 패션 카테고리 데이터 전처리 / 모델링
우선 기본 데이터셋은 아래와 같은 형태였다.
 기본적인 데이터 특이사항 확인을 했고 이 중에서 null이 많았던
기본적인 데이터 특이사항 확인을 했고 이 중에서 null이 많았던 가격~상품명칼럼은 드랍을 했다.
처음에는 무작정 데이터 전처리를 해보려고 했었다.
- 근데 생각해보니 만들고 싶은 모델의 구조 자체는 '질문을 던지면 그에 맞는 답변을 뱉는 것'으로 픽스되어 있지만, 내가 어떤 모델을 선택하느냐에 따라 전처리의 방향이 완전 달라질 수도 있겠구나 싶었다.
- 그래서 어떤 모델을 사용하면 좋을지부터 리서치해보기로 했다.
일단 한국어를 대상으로 한 사전학습 모델들에 대한 리서치를 진행했다.
- 사전 학습 모델을 사용하면 좋겠다는 생각을 했던 건, 1) 빠른 시간 내에 어느 정도의 성능을 내야하는 상황이었고, 2) 내가 처음부터 복잡한 자연어 처리 모델을 직접 다 짤 수 있는 능력이 될까? 라는 생각 때문이었다. (수업 때 다룬 모델의 구조를 이해하는게 굉장히 어려웠다.)
- SKT에서 개발한
Kobert부터KcBERT,KcELECTRA,KOELECTRA등 다양한 모델에 대해서 찾아보고 공부해보았다.- 각 모델은 목적에 따라 학습한 데이터가 다르기 때문에 그 부분을 중점으로 차이점을 찾아보려고 했다.
- 근데 일단 큰 문제가.. 이 모델들에 대한 이해를 내가 온전히 하기가 어려웠다..! 또 나는 classification이 목적이 아닌데 이 모델들은 분류를 결과로 내는 것이어서 뒷딴을 내가 커스텀해야하기도 했다. 사전학습 모델의 의미를 생각하면 커스텀은 당연한 걸수도 있긴 한데 너무 어렵게 느껴졌다..ㅠㅠ
- 그러면 오픈된 코드를 내가 잘 활용할 수라도 있어야 할텐데 pytorch 기반이라 tensorflow로 잘 바꿔쓸 수 있을까? 걱정이 되기도 했고.. 또 한국어 기반 자연어 처리 모델이라 그런지 구글링을 해도 이해할 수 있는 좋은 자료를 찾기가 어려운 점도 있었다.
- 계속 리서치를 하며 내가 풀고자하는 것에 어떻게 적용할 수 있을지 찾아보았지만, 결론은 위와 같은 사전학습 모델을 쓰는 건 짧은 시간 내에 프로젝트를 다 완성하기 어려울 것 같다는 것이었다. 사전학습모델 적용은 좀 미뤄보고 기본 형태로 구현부터 한번 해보기로 했다.
그러다가 sentence transformer에 대해서 알게 되었다!
- 관련 자료 1 (공식 문서), 관련자료 2, 결정적으론 이 자료에 코드 구현이 되어있는 것도 있어서 내 문제에 잘 적용만 하면 될 것 같았다.
- 위 자료들을 보았을 때
sentence transformer를 쓰면 가장 간단한 형태로 내가 원하는질문 > 답변구조를 만들 수 있을 것 같았기 때문에 도저히 안 쓸 이유가 없어보였다. - 위 레퍼런스에서 봤을 때 만들어야할 데이터셋의 구성은 아래와 같았기 때문에 우선 이 방향으로 데이터 전처리를 진행하기로 했다.
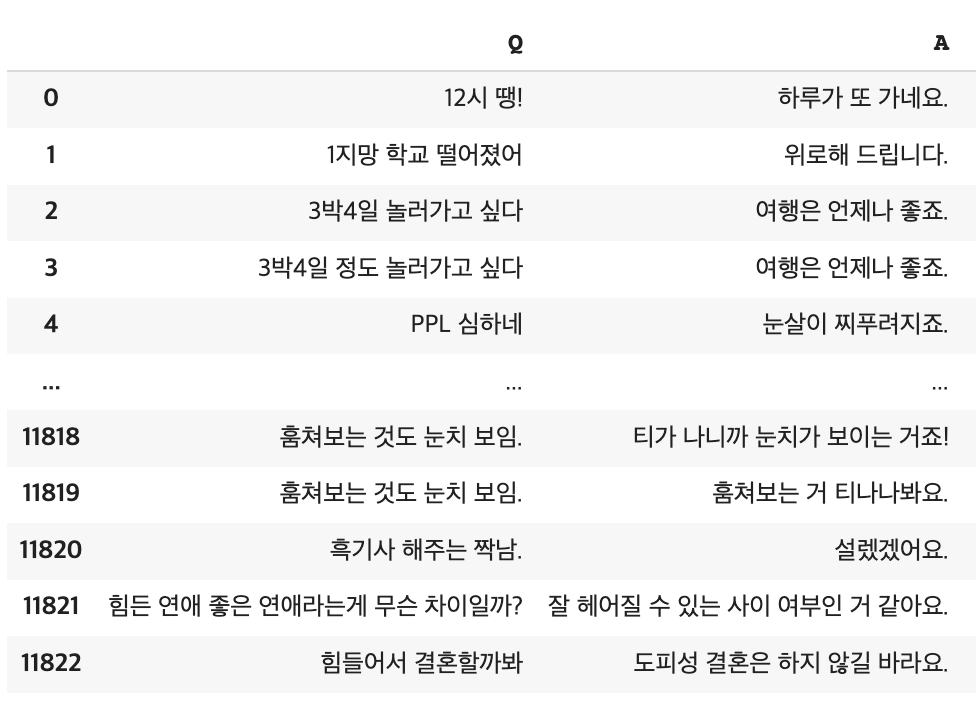
데이터 전처리 과정은 어려운 점이 많았다. 다시 원래 내가 활용할 데이터셋 형태를 보자. 
- 이 데이터셋에서 내가 해결해야할 건 질문과 답변이 각 row로 섞여있는 것을 규칙을 찾아서
질문-답변으로 묶어내는 것이었다. - 근데 문제는 그 명확한 규칙이 없다는 것이었다. 데이터셋을 딱 보면
상담번호,QA여부,상담내순번등으로 잘 라벨링이 되어있어 이것만 이용하면 될 것 같지만 실제로는 뒤죽박죽이고 틀린 라벨링이 많았다.- 게다가 당연하지만 고객이 질문만 하지 않고, 상담원도 답변만 하지 않았다. 이것까진 괜찮았지만, 질문을 한 문장에 끝내는 것도 아니고 답변을 한 문장에 주고 대화가 꼭 끝나는 것도 아니었다. 그리고 꼭 하나의 주제로 대화가 이루어진 것도 아니고 중간에 주제가 갑자기 바뀌기도 했다. 즉 노이즈가 너무 많았다.
- 그럼
상담번호,QA여부,상담내순번이런 것들이 잘 정리라도 되어있어야 할텐데 예외로 보이는 경우도 데이터 탐색을 해보니 많이 보였다. 애초에 데이터셋을 Q, A 순으로 잘 정렬한 후 For loop을 돌려서 Q와 A를 하나씩 뽑아서 각각의 새로운 리스트에 담는 식으로 분리해야겠다 생각했는데, 이대로면 내가 생각한 대로 할 수가 없었다.(규칙에 따라 제대로 정렬할 수 없다면 Q, A가 매칭되지 않고 어긋난다. 이건 모델의 성능에 치명적이다.) - 아까 내가 생각했던 코사인 유사도에 더해
인텐트까지도 고려해서 더 정확한 답변을 뽑아줘야지~ 생각했었는데 이대로면 기본 기능도 구현하기 어려울 것 같았다.
결론적으로는 아래와 같이 전처리했다.
- 라벨 인코딩으로 발화문 외엔 다 숫자로 바꿔줌
- (원래는 모델에 담화문 외에 다른 조건들도 더 활용하고 싶다는 생각을 했었기 때문. 결과적으론 쓸모 없었음..)
상담번호,상담내순번으로 sorting
- 일단
상담번호 1번만 대상으로 테스트
- 위 이미지 1~4열에 있는 상담내순번을 보면 같은 시점의 질문과 답변이 나뉘어서 이어지는데 그렇게 연속되는 경우는 하나의 Q, A로 넣기 위해 열을 합치기.
-상담번호+상담내순서를 문자열로 변형한 뒤 합쳐서 단순히 숫자로 더했을 때 다른 대화와 섞이지 않게 하였다. (숫자로 하면 혹시 5+5도 10이고 6+4도 10이기 때문에 같은 대화로 엮일 수도 있었다). 그렇게new칼럼을 생성해 합친 텍스트를 넣어주고 중복열을 제거해줬다.
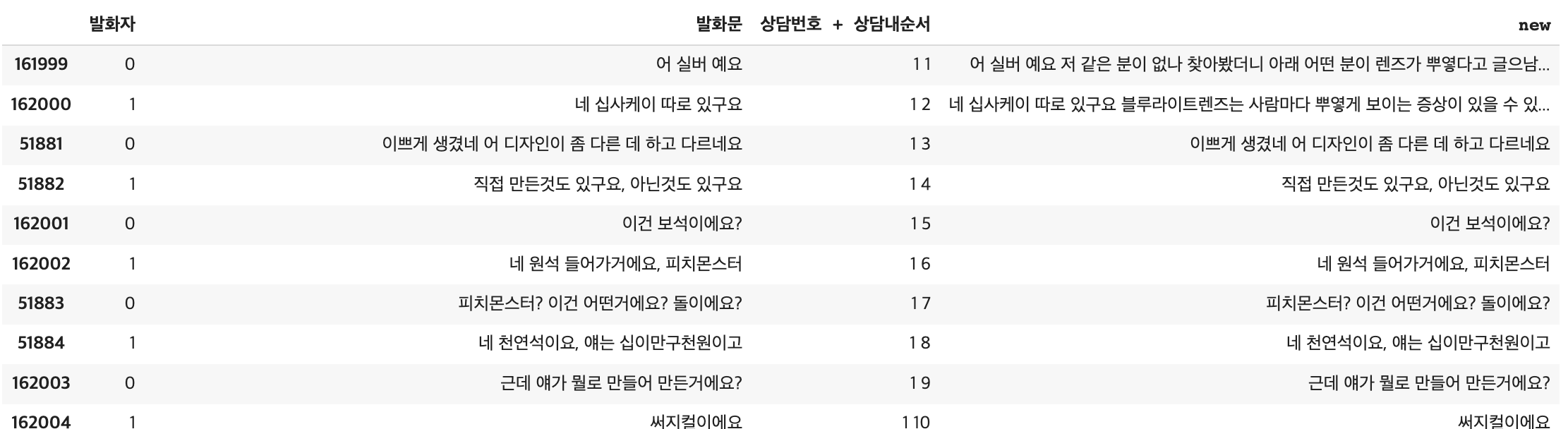
- for loop 돌려서 Q, A에 할당하기
- 행 하나씩 차례대로 Q, A에 할당한 것이다.

근데 여기서 문제는 중간에 질문과 답변이 어긋난 부분이 보였다.
- 이런 것들이 테스트로 진행했던
상담번호 1번외에도 다수 보였다. 조치가 필요했다. - 나는 이렇게 하면 행이 Q, A 순서대로 이루어질 것이고 나는 순서대로 뽑기만 하면 되겠거니 생각했던 것인데, 한 상담번호의 총 대화가 홀수개인 경우 마지막 질문 or 답변이 다음 상담번호의 질문 or 답변으로 할당되며 그 이후가 다 하나씩 밀리는 것이다.
- 그래서 어찌할까 이리저리 해보다가 아래 두 개의 선택지 중에 첫 번째껄로 해보기로 했다.
- 가공한 Df2에서 상담번호별 총 대화가 홀수 개인거 문제있는 걸로 보고 날린다. 전체 데이터수 유지만 어느정도 된다면 괜찮을 듯.
- 아예 처음부터 발화자 기준으로 Q 쭉 뽑고, A 쭉 뽑아서 비교해볼까?
- 결과적으로는 아래와 같은 형태로 94000여개의 샘플을 확보했다. 무작위로 처음, 중간, 마지막의 샘플들을 뽑아봤는데 답변이 어긋나는 부분은 눈으론 안 보였다. 일단 모델링 해서 결과 보고 이상한게 있으면 다시 돌아오자고 생각했다.

(모든 전처리 과정을 다 여기 옮길 수는 없어 요약해서 말했지만, 왜 전처리가 자연어 처리에서 가장 어려운 부분이라고 하는지 충분히 느낄 수 있었다.. 그래도 재밌었다.)
[sentence transformer] 적용!!
구현 자체는 어렵지 않았다. 위 참고 자료 중 코드 구현 부분 코랩 파일을 보면 되기 때문이다. 이미 데이터는 Q, A 형태로 준비되어 있고, 내가 모델을 직접 구축할 것도 없이 그냥 install만 해서 쓸 수 있었기 때문이다.
# 모델
model = SentenceTransformer('jhgan/ko-sroberta-multitask')- sentence transformer를 Q에 적용하면 아래와 같이 임베딩 벡터를 얻을 수가 있다.

- 그러면 이후에는 코사인 유사도에 기반해서 새롭게 넣은 input과 df의 Q와 유사한 것을 내적을 통해 찾아내고, 그 중 TopN의 A를 출력하게 된다.
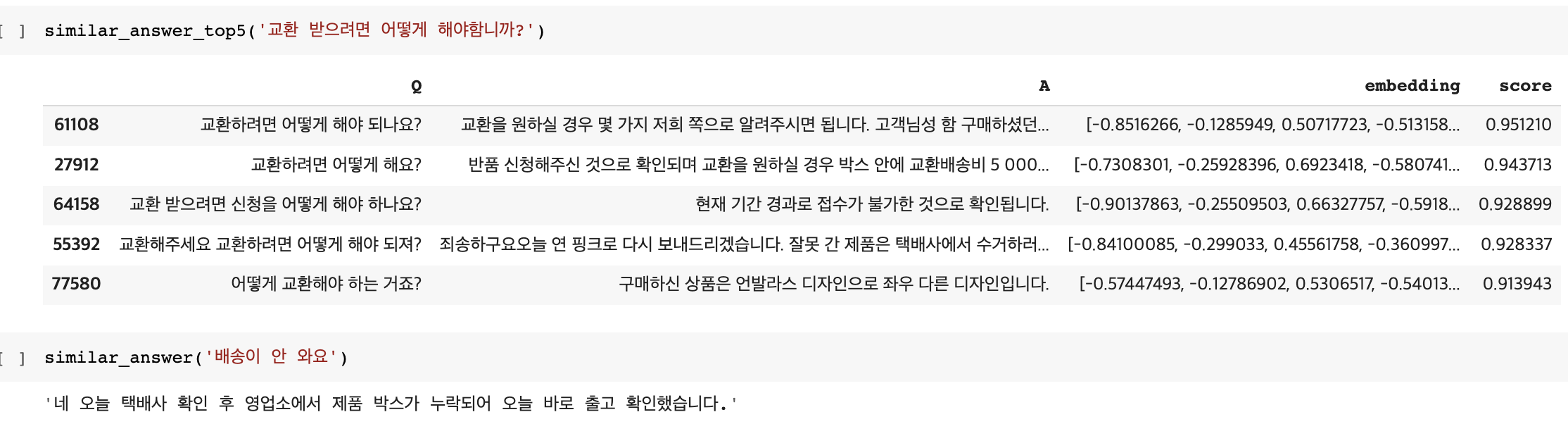
근데 결과를 보니 '이게 맞나..' 굉장한 회의가 밀려왔다.
- 일단 패션 카테고리의 대화 특성 상 같은 질문이어도 고객마다 다른 답변이 나가는 경우가 굉장히 많았다. 또 대화의 양상도 너무나 천차만별이었다. 상품도 너무 다양하고 고객의 상황도 다 다르기 때문에, 이렇게 유사도 기반으로 뽑아서 답변을 준다고 해도 정확하지 않을텐데 그게 과연 무슨 의미가 있을까 싶었다. 이걸 왜 애초에 더 깊게 고민하지 않았을까 하는 아쉬움도 이때 들었다. 결국 나도 시간에 쫒겨 딥러닝 기술을 '쓰는 것'만 생각하고, 이 기술이 내가 만들고 싶은 기능에서 어떤 역할을 해야할지 제대로 고민하지 않은 것이다.
- 또 하나의 문제는 프로젝트 채점 기준 중에
딥러닝 모델의 성능은 상관없지만 학습은 제대로 이루어져야 한다.는게 있었는데, sentence transformer를 쓴 과정을 보면 내가 실제 학습시킨 건 없고 그저 사전학습된 모델을 설치해서 임베딩 벡터를 뽑아낸 것 밖에 없었다.- 이건 이슈쉐어링을 통해 이대로 해도 채점 기준에 맞는지, 안 맞는다면 내가 그냥 트랜스포머를 직접 구축해서 하려고 한다고 코치님께 질문을 남겼는데, 직접 학습시키지 않으면 미달이라는 답변을 받았다.
결론적으론 서비스적인 의미로써의 모델 아웃풋도 좋지 않았고, 프로젝트 채점 기준으로써도 미달이었기 때문에 원점에서 프로젝트의 방향성을 다시 정해야했다.
3. [최종] 카페 카테고리 데이터 전처리 / 모델링
앞선 시도가 실패한 탓에 어떻게 해야하나 좌절했다..
- 이때가 25일 오후였으니까 마감까지는 2일도 안 남은 상태였다. 어떻게 해야할지 고민을 많이 했다. 주제를 아예 엎어야 하나, 데이터셋을 새로 찾아봐야 하나 등.
- 시간 관계상 새로운 데이터셋을 찾아서 처음부터 다 구성하는 건 무리라고 생각해, 원래 데이터 뭉치에서
패션카테고리 대신 다른 업종들의 데이터셋을 들여다보기로 했다.
그 중 카페 카테고리 데이터를 보다가 불연듯 아이디어가 떠올랐다!
- 작년에 창업 아이템 아이데이션할 때 요식업 자영업자들을 타겟으로 이런저런 생각을 했었던 적이 있었다. 그때 내가 생각한 가장 큰 문제는 배달앱 시스템에 종속될 수 밖에 없는 상황이었다. 그런 상황에서 자영업자들이 겪는 수수료 등의 크리티컬한 문제를 해결할 수 있는 대안도 마땅히 없었다. (대안이 없는 건 지금도 마찬가지라고 생각한다)
- 그때 현재의 배달앱 시장을 대체할 수 있는 새로운 플랫폼에 대한 고민을 했었는데 그땐 마땅한 해결책을 생각해낼 수가 없어 유야무야되었었다.
- 근데 만약 채팅 기반의 새로운 플랫폼을 통해 고객과 요식업 자영업자가 직접 소통할 수 있다면? 그리고 그 소통의 보조도구로써 자연어 처리 기술이 도움을 줄 수 있다면 어떨까? 라는 생각을 하게 되었다.
- 아래는 이와 관련된 나의 가설과 아이디어를 정리해 발표자료에 넣은 것이다.

- 이게 애초에 생각했던 이커머스 쇼핑몰 담당자의 리소스 감소와 고객 편의라는 기능의 목적과 완전히 다른걸까?를 생각해보았을 때 꼭 그렇지도 않았다. 도메인은 다르지만 결국
고객과 소통의 보조도구로써 활용하는 자연어 처리 기술이라는 본질은 같다고 생각했기 때문이다. 만약 내가 이 주제로 좋은 경험을 해본다면 추후 다른 도메인에도 접목해볼 수 있을 거라고 생각했다.
다행히 카페 카테고리의 데이터도 쓰기에 좋아보였다. 왜 하필 카페 카테고리였냐? 아래 두 가지 이유를 보았을 때도 내 아이디어를 처음 구현해본다는 의미로는 충분해보였다.
- 업종 특성 상 응대 직원이 상시적으로 음료 제조에 투입됨.
- (NLP 자동완성 기술에 대한 니즈가 높을 것으로 예상)
- 판매 상품의 종류 및 고객 요청사항이 비교적 정형화되어 있고 대화가 짧아 NLP 모델의 일반화에 좀 더 유리하다고 판단됨.
- (Ex. 패션 카테고리의 경우 고객 개개인의 특성이 답변 선택에 있어 특수하게 적용되는 경우가 많음.)
데이터 전처리 과정은 압축하여 핵심만 옮겨두겠다. 참고로 가공해야할 데이터 형태는 패션 카테고리를 할 때와 똑같았다.
- label encoder는 생략
- 이번 프로젝트에서 모델 학습에
발화문칼럼 외 활용은 안할 것이므로. 추후에 추가 프로젝트 진행 시 필요하면 진행한다.
- 이번 프로젝트에서 모델 학습에
- 이번에도 다양한 칼럼들을 기준으로 소팅해보며 최대한 규칙을 찾으려고 해봤지만, 패션 카테고리와 똑같이 진행해도 노이즈가 너무 많았다. 그래서 그냥 모든 데이터 사용은 포기하고 과감하게 상담번호를 기준으로 질문과 답변이 딱 한번씩만 오고간 데이터만 남기고 모두 드랍하기로 했다.
- 질문과 그에 맞는 답변을 정확히 매칭해서 데이터프레임을 만드는게 가장 중요한 목표였기 때문에 모든 데이터를 쓰려다가 노이즈가 껴서 엉망진창이 되는 것보다는 그게 더 나을 것이라 판단했다.
- 다행히 그렇게 한다고 해도 질문-답변 샘플이 56000건 정도로 충분했다.
- 이번에는 패션카테고리처럼 q, a 기준까지 맞춰 정렬해 단순 행 순서대로 하나씩 넣지는 않았고, 그냥 상담번호 기준으로만 소팅하고, 상담번호 내의 q, a를 순서대로 하나씩
Q,A빈 리스트에 각각 할당하는 방식으로 했다. 어차피 대화가 한번씩만 오간 상담번호만 가져왔기 때문에 다른 상담번호 질문답변과 뒤섞일 문제는 없었다. 결과는 아래와 같이!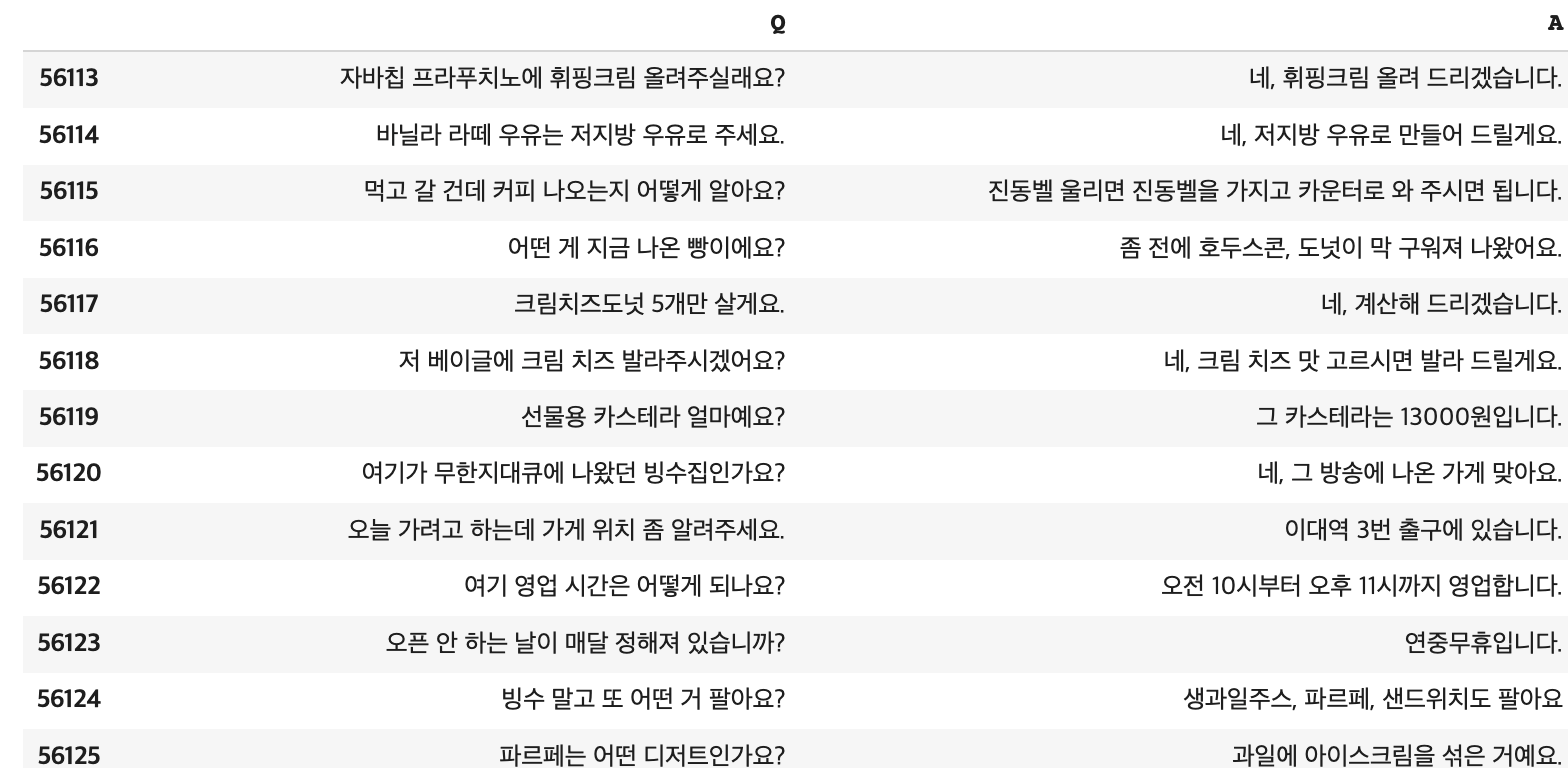
- 위와 같은 결과를 얻은 후 추가적으로 구두점을 없애는 정규표현식 전처리까지 해주었다.
모델 구축 및 학습 과정은 발표 자료의 이미지로 대체한다.


- 참고로 모델 같은 경우 transformer를 사용했는데, 구축할 때 코드는 여기를 참고했다. 시간이 없었기 때문에 모델 구조를 하나하나 다 이해하고 적용하기 보단 구현 자체에 더 집중했다.
결과이다. 모델 평가는 human evaluation으로 했다. 
- 위에 적었던 것처럼 고객이 채팅기반 플랫폼을 통해 질문을 남기면, 점원의 입력창에는 과거 상담 데이터를 기반으로 해 답변이 자동완성되어있고, 점원은 그걸 확인하고 엔터만 누르면 되는 것이다.
- 왜 바로 답변하지 않고 점원의 확인 및 엔터를 누르는 과정을 넣었다면, 이루다 이슈에서 보았던 문제가 생길 수도 있기 때문이다. 즉, 이 자연어 처리 기술은 완벽하지 않고 DB의 질문-답변 데이터를 기반으로 하기 때문에 오답변이 나갈 수 있는 가능성 때문이다.
다음은 향후 과제로 잡은 내용이다.
- 한계점 및 향후 과제에 넣은 것처럼 내가 구현한 부분은 처음 구상했던 전체 기능 중에 극히 초입은 모델 구현 정도에만 그쳤다. 그 점이 아쉬웠지만, 플랫폼 서비스 구축까지 하는 건 이번 딥러닝 프로젝트 범위에서 벗어나는 것이기도 하고 얼마 남지 않은 시간 내에 하기도 무리라고 생각해 진행하지 않았다.
4. 발표 자료 준비 및 제출
- 스토리텔링의 시간이었다. 프로젝트 시작 전에 이전 기수에서 잘한 발표라고 해서 한 5개 정도 영상을 보여줬는데, 솔직히 기술 구현 자체가 대단하다고 느낀 것들은 있었지만 왜 그 기술을 썼고 어떤 맥락에서 그 기술이 의미가 있는지를 설명하는 부분에서는 공감이 가는게 하나도 없었다. 그래서 나는 더더욱 내가 위에서 생각했던 이 기술의 의미를 잘 녹여내기 위해 스토리텔링에 특히 신경써야겠다고 생각했다.
- 발표 순서는 처음
요식업 자영업자의 현실이라고 해서 내가 새로운 채팅기반의 플랫폼을 생각한 이유에 대해서 설명했고, 그러한 플랫폼 내에서 자연어 처리 기술이고객과 소통의 보조도구로써 어떤 의미가 있는지를 강조했다.- 이게 딥러닝 기술 구현 자체만 보려는 사람에게는 불필요하다고 느껴질 수 있을거다. 하지만 난 딥러닝 기술도 그저 문제를 해결하는 도구 중 하나일뿐이며, 이번 프로젝트에서도 그런 의미를 잊지 말아야 한다고 생각했다.
- 발표 슬라이드를 여기 옮겨두고 싶지만,, 혹시 이 회고를 보시는 분 중에 궁금하신 분이 계시다면 프로필에 있는 주소로 메일 주시면 보내드리도록 하겠습니다.
이전에는 발표 자료 만들 때 한 슬라이드 만들고 바로 그 슬라이드에서 말할 스크립트도 적어두는 식으로 했는데, 이번에는 스크립트는 따로 어디에 적으면서 하지는 않았다.
- 발표 자료 만들면서 전체적인 플로우와 하고 싶은 말을 생각해두는 것만으로도 충분했다. 오히려 플로우를 더 잘 짤 수 있다는 면에선 장점도 있는 듯? 하고 싶은 말이 머릿속에 잘 정리되어 있어 그런지 스크립트가 없다고 발표영상 찍을 때 힘들거나 하지는 않았다. 물론 9분 30초짜리 영상 찍는데 2시간 가까이 쓰긴 했지만 여튼 다행..
맺음말
- 이번 프로젝트는 지금까지 했던 프로젝트 중 가장 힘들었다. 처음 패션 카테고리로 하다가 망했을 때는 그냥 포기할까라는 생각까지도 해봤다. 전처리를 그렇게 죽어라 했는데 결과적으론 내가 생각했던 목표의 반의 반에도 가지 못했으니 말이다.
- 그래도 다행히 카페 카테고리로 잘 피봇할 수 있었고, 더 다행히도 그 덕분에 기술 자체만을 바라보는 것이 아니라 내가 구현하고 싶은 서비스 내에서 이 기술이 어떤 의미를 가질 수 있는지 고심해볼 수 있는 계기가 될 수 있었다. 다시 한 번 딥러닝이건 뭐건 어떤 기술이건 기술 자체만이 중요한 것이 아니라는 생각을 할 수 있었다.
- 오늘의 회고는 이에 대한 스티브잡스의 말로 마무리한다. 수고 많았다!
You've got to start with the customer experience and work backwards to the technology. You can't start with the technology and try to figure out where you're gonna try to sell it.
출처
