scikit-learn 주요 모듈 : 강의
- 다양한 머신러닝 알고리즘을 구현한 파이썬 라이브러리
- 심플하고 일관성 있는 API, 유용한 온라인 문서, 풍부한 예제
- 머신러닝을 위한 쉽고 효율적인 개발 라이브러리 제공
- 다양한 머신러닝 관련 알고리즘과 개발을 위한 프레임워크와 API 제공
- 많은 사람들이 사용하며 다양한 환경에서 검증된 라이브러리
scikit-learn 주요 모듈
| sklearn.datasets | 내장된 예제 데이터 세트 |
|---|---|
| sklearn.preprocessing | 다양한 데이터 전처리 기능 제공 (변환, 정규화, 스케일링 등) |
| sklearn.feature_selection | 특징(feature)를 선택할 수 있는 기능 제공 |
| sklearn.feature_extraction | 특징(feature) 추출에 사용 |
| sklearn.decomposition | 차원 축소 관련 알고리즘 지원 (PCA, NMF, Truncated SVD 등) |
| sklearn.model_selection | 교차 검증을 위해 데이터를 학습/테스트용으로 분리, 최적 파라미터를 추출하는 API 제공 (GridSearch 등) |
| sklearn.metrics | 분류, 회귀, 클러스터링, Pairwise에 대한 다양한 성능 측정 방법 제공 (Accuracy, Precision, Recall, ROC-AUC, RMSE 등) |
| sklearn.pipeline | 특징 처리 등의 변환과 ML 알고리즘 학습, 예측 등을 묶어서 실행할 수 있는 유틸리티 제공 |
| sklearn.linear_model | 선형 회귀, 릿지(Ridge), 라쏘(Lasso), 로지스틱 회귀 등 회귀 관련 알고리즘과 SGD(Stochastic Gradient Descent) 알고리즘 제공 |
| sklearn.svm | 서포트 벡터 머신 알고리즘 제공 |
| sklearn.neighbors | 최근접 이웃 알고리즘 제공 (k-NN 등) |
| sklearn.naive_bayes | 나이브 베이즈 알고리즘 제공 (가우시안 NB, 다항 분포 NB 등) |
| sklearn.tree | 의사 결정 트리 알고리즘 제공 |
| sklearn.ensemble | 앙상블 알고리즘 제공 (Random Forest, AdaBoost, GradientBoost 등) |
| sklearn.cluster | 비지도 클러스터링 알고리즘 제공 (k-Means, 계층형 클러스터링, DBSCAN 등) |
confusion matrix
# model1, Random Forest, confusion matrix
pcm = ConfusionMatrixDisplay.from_predictions(y_val,
y_pred_optimal1,
cmap=plt.cm.Reds)
plt.title(f'Confusion matrix, n = {len(y_val)}', fontsize=15)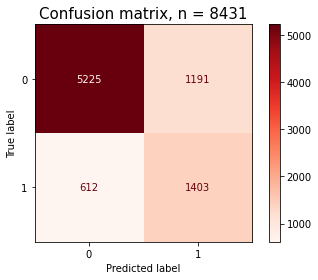
RandomForestClassifier : 참고
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(
n_estimators=500,
criterion="entropy",
random_state=10,
oob_score=True,
# max_depth=3,
# oob_score=True,
# warm_start=True,
# max_features=0.25,
n_jobs=-1
)
)
pipe.fit(X_train, y_train)# roc_curve(타겟값, prob of 1)
y_pred_proba = model1.predict_proba(X_val)[:, 1]
fpr1, tpr1, thresholds1 = roc_curve(y_val, y_pred_proba)
# threshold 최대값의 인덱스, np.argmax()
optimal_idx = np.argmax(tpr1 - fpr1)
optimal_threshold = thresholds1[optimal_idx]
# threshold 최대값으로 설정
y_pred_optimal = y_pred_proba >= optimal_threshold
print(f'auc score:{roc_auc_score(y_val, y_pred_proba)}')
print('검증세트 F1-score', f1_score(y_val, y_pred_optimal))
print(classification_report(y_val, y_pred_optimal))# 테스트 데이터 입력 후 결과 출력
y_pred = model1.predict(X_test)
y_pred_optimal = y_pred >= optimal_threshold
y_pred_optimal = y_pred_optimal.astype(int)
sample_submission['vacc_h1n1_f'] = y_pred
sample_submission.to_csv('submission_op.csv',index=False)XGBClassifier: 참고
from xgboost import XGBClassifier
# xgboost model
model2 = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
XGBClassifier(
n_estimators=3000,
learning_rate=0.01
)
)
model2.fit(X_train, y_train)교차검증(k-fold cross-validation(CV)):참고
#cross_val_score
from category_encoders import OneHotEncoder
from sklearn.feature_selection import f_regression, SelectKBest
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# (참고) warning 제거를 위한 코드
np.seterr(divide='ignore', invalid='ignore')
target = 'SalePrice'
features = train.columns.drop([target])
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0)
)
# 3-fold 교차검증을 수행합니다.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE ({k} folds):', -scores)# 랜덤포레스트
from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
# TargetEncoder: 범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2)
)
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE for {k} folds:', -scores)TargetEncoder: 참고
범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
enc = TargetEncoder(min_samples_leaf=1, smoothing=1000)
enc.fit_transform(X_train,y_train)['LotShape'].value_counts()하이퍼파라미터튜닝
Randomized Search CV :참고
# ridge 회귀
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='accuracy',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
# 위에서 찾은 최적 하이퍼파라미터를 적용한 모델 생성.
pipe = clf.best_estimator_
# 위 최적 모델에 훈련/검증 데이터 넣고 스코어 추출.
y_val_pred = pipe.predict(X_val)
y_train_pred = pipe.predict(X_train)
print('훈련 f1 score: ', f1_score(y_train, y_train_pred, average='binary'))
print('검증 f1 score: ', f1_score(y_val, y_val_pred, average='binary'))#랜덤포레스트
from scipy.stats import randint, uniform
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=2)
)
dists = {
'simpleimputer__strategy': ['mean', 'median', 'most_frequent'],
'randomforestclassifier__n_estimators': randint(50, 500),
'randomforestclassifier__max_depth': [5, 10, 15, 20, None],
'randomforestclassifier__max_features': uniform(0, 1)
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='accuracy',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)
# 위에서 찾은 최적 하이퍼파라미터를 적용한 모델 생성.
pipe = clf.best_estimator_
# 위 최적 모델에 훈련/검증 데이터 넣고 스코어 추출.
y_val_pred = pipe.predict(X_val)
y_train_pred = pipe.predict(X_train)
print('훈련 f1 score: ', f1_score(y_train, y_train_pred, average='binary'))
print('검증 f1 score: ', f1_score(y_val, y_val_pred, average='binary'))# 위에서 찾은 최적 하이퍼파라미터를 적용한 모델 생성. 특성 중요도(feature importance)
# 특성 중요도(ordinal)
rf_ord = pipe.named_steps['randomforestclassifier']
importances_ord = pd.Series(rf_ord.feature_importances_, X_train.columns)
n = 10
plt.figure(figsize=(10,n/4))
plt.title(f'Top {n} features with ordinalencoder')
importances_ord.sort_values()[-n:].plot.barh();Bayesian Search
- 검증하고자 하는 하이퍼파라미터의 범위 내에서, 이전에 탐색한 조합들의 성능을 기반으로 성능이 잘 나오는 조합들을 중심으로 확률적으로 탐색합니다.
- 랜덤 서치보다 상대적으로 똑똑하고 효율적으로 탐색하는 방법으로, 한정된 자원 내에서 좋은 하이퍼파라미터 조합을 발견할 가능성이 더 높습니다.
sklearn에서는 이 기능을 제공하지 않으며, 일반적으로hyperopt등의 라이브러리를 추가 사용해서 탐색을 진행하게 됩니다.
[hyperopt](http://hyperopt.github.io/hyperopt/getting-started/search_spaces/) 라이브러리
hyperopt라이브러리를 이용해 하이퍼파라미터를 탐색할 때는 하이퍼파라미터 범위를hyperopt라이브러리에서 제공하는stochastic expressions로 지정해 주어야 합니다.- 몇 가지 자주 사용하는
expression들을 소개합니다.hp.choice(label, options): 리스트나 튜플 형태의 선택지 중 하나를 선택합니다.hp.randint(label, upper): [0, upper] 범위 내의 정수값을 랜덤으로 선택합니다.hp.uniform(label, low, high): [low, high] 범위 내의 실수값을 랜덤으로 선택합니다.hp.quniform(label, low, high, q): [low, high] 사이 균등분포에서 q 간격의 일정 지점들로부터 값을 랜덤으로 선택합니다.hp.normal(label, mu, sigma): 평균 mu, 표준편차 sigma를 갖는 정규분포로부터 실수값을 랜덤으로 선택합니다.
- • 자세한 내용은 여기를 참고하세요.
from hyperopt import hp
params = {
"simpleimputer__strategy": hp.choice("strategy", ["median", "mean"]),
"randomforestclassifier__max_depth": hp.quniform("max_depth", 2, 10, 2),
"randomforestclassifier__max_features": hp.uniform("max_features", 0.5, 1.0),
}hyperopt라이브러리 사용 시 학습 및 검증 함수를 직접 작성해 주어야 합니다.hyperopt.fmin은 주어진 함수로부터 loss 정보를 얻고, 이 정보로부터 다음 탐색할 하이퍼파라미터 조합을 선택합니다.- 최종으로
loss를 가장 작게 만드는 하이퍼파라미터 조합을 선택하므로, 클수록 좋은 metric의 경우 -부호를 붙여 반환해 주어야 합니다. - 따라서 학습 및 검증을 위한 함수는 아래와 같이 loss와 status라는 상태를 반환해야 합니다.
fmin의max_evals만큼 fitting을 진행하게 됩니다.
from hyperopt import fmin, tpe, Trials, STATUS_OK
from sklearn.model_selection import cross_val_score
import numpy as np
def get_pipe(params):
params["randomforestclassifier__max_depth"] = int(
params["randomforestclassifier__max_depth"]
) # max_depth는 정수형으로 변환해 줍니다.
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(
n_estimators=500,
random_state=42,
n_jobs=-1,
),
)
pipe = pipe.set_params(**params)
return pipe
def fit_and_eval(params):
pipe = get_pipe(params) # 주어진 params로 파이프라인을 만들어 가져옵니다.
score = cross_val_score(pipe, X_train, y_train, cv=3, scoring="roc_auc")
avg_cv_score = np.mean(score)
# roc_auc는 클수록 좋은 metric이므로, hyperopt.fmin이 roc_auc를 최대화하도록 하기 위해 -부호를 붙여 반환합니다.
return {"loss": -avg_cv_score, "status": STATUS_OK}
trials = (
Trials()
) # Trials() 객체를 fmin에 함께 넣어 실행하면, 실행되는 매 fit의 학습 정보 및 학습 결과가 해당 객체에 모두 저장됩니다.
best_params = fmin(
fn=fit_and_eval, trials=trials, space=params, algo=tpe.suggest, max_evals=10
) # max_evals 횟수만큼 하이퍼파라미터 조합을 탐색합니다.trials.trials # 모든 trial 정보에 대해 직접 접근할 수 있습니다.print("최적 하이퍼파라미터: ", trials.best_trial["misc"]["vals"])
print("최적 AUC: ", -trials.best_trial["result"]["loss"])
ENTJ 데이터 분석가 준비중입니다:)