정보 손실은 최소화(가능한 많은 정보를 포함)하면서 중요한 변수만 선택할 수 있다면 어떨까요?머신러닝에서는 이를 위한 다양한 차원 축소 기술들을 연구 중입니다.
차원 축소란 고차원 원본 데이터의 의미 있는 특성을 이상적으로 원래의 차원에 가깝게 유지할 수 있도록 고차원 공간에서 자차원 공간으로 데이터를 변환 하는 것을 말합니다.
- 직관적으로 설명하자면 변수를 줄이는 것입니다.
- 차원의 저주를 방지할 수 있습니다.
차원축소의 목적(필요성)
- 기계학습 측면에서는 차원 축소가 차원의 저주 (Curse of Dimensionality)를 피할 수 있습니다.
- 과적합 (Overfitting) 을 방지하는데에 효과적입니다.
- 과적합이 발생하면, 분석 모형의 신뢰도를 떨어뜨릴 수 있습니다.
- 정보 손실의 최소화하여 가능한 많은 정보를 포함하고 데이터 설명에 중요한 변수만 선택합니다.
- 리소스를 감소시켜 모델의 성능을 향상시킬 수 있습니다.
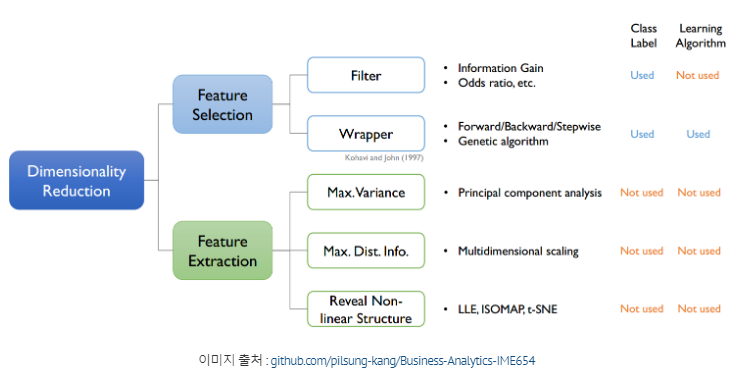
차원 축소의 종류
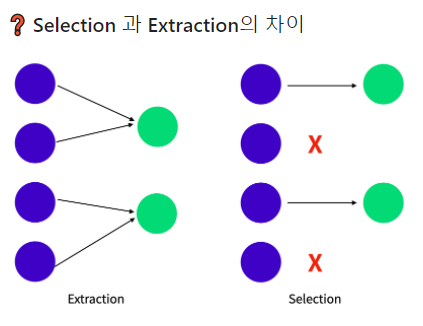
| 차원 선 - selection | 차원 추출 - extraction | |
|---|---|---|
| 장점 | 선택된 feature 해석이 쉽다. | feature들 간의 연관성이 고려됨,feature의 수를 많이 줄일 수 있다. |
| 단점 | feature들간의 연관성은 고려되지 않는다. | 해석이 어렵다. |
| 예시 | SelectKBest, Variance Threshold, RFE... | PCA, LSA, LDA, SVD |

1.feature extraction
- feature의 해석이 쉽다는 장점이 있습니다.
- 데이터셋에서 덜 중요한 feature는 제거하는 방법입니다.
- 분석 목적에 적합한 소수의 기존 feature를 선택합니다.
- feature 간 상관관계를 조합하여 새로운 feateure를 생성합니다.
- 고차원 원본 feature 공간을 저차원의 새로운 feature 공간으로 투영합니다.
- 비정형데이터에 주로 사용합니다.(이미지, 영상 등)
- PCA(principle Componeent Analysis)
- 데이터 분석에 대한 특별한 목적이 없는 경우 가장 합리적인 차원 축소
Feature Extraction 방법은 아래의 2가지 방법으로 분류됩니다.
- Linear methods
- PCA(Principal Component Analysis)
- LDA(Linear Discriminant Analysis)
- 특이값 분해 (Singular Value Decomposition)
- 요인분석 (Factor Analysis)
- Non-linear methods
- AE(AutoEncoder)
- t-SNE
- LLE (Locally-Linear Embedding)
2.Feature Selection
- 기존 feature를 조합하여 사용합니다.
- feature 간 상관관계를 고려하여 조합합니다.
- 새로운 feature가 추출(생성)됩니다.
- 원래 변수들의 선형결합으로 이루어집니다.ex) 집값 데이터셋에서
집 면적,방 개수,화장실 개수를 나타내는 변수를 조합하여크기라는 하나의 변수를 사용합니다.
- feature의 해석이 어렵기 때문에 쉽게 모델을 단순화 시킵니다.
- feature 수를 많이 줄일 수 있습니다.
- 훈련 시간을 감소시킬 수 있고 주로 정형데이터를 다룰 때 사용합니다.
Filtering Method

Filtering은 사전적 의미 처럼 도움이 되지 않는 피처들을 걸러내는 작업을 말합니다. 통계적인 측정 방법을 이용하여 피처들의 상관관계를 알아내고 적합한 피처들만 선택하여 알고리즘에 적용하는 방식입니다.
- feature들의 상관관계 파악할 때 사용합니다.
- 상관관계가 높음 -> feaure에 담긴 정보가 중복된다는 뜻으로 해석 가능 -> feature를 줄입니다.
- ex) Correlation Coeffcient, 도메인 지식
대표적인 방법은 아래와 같습니다.
- t-test
- chi-square test
- Information Gain
Embedded Method
Embedded는 Filtering과 Wrapper의 장점을 결함한 방법으로 학습 알고리즘 자체에 feature selection을 넣는 방식입니다.
- Filtering + Wrapper 장점 결함 방식입니다.
- 모델 자체에 Feature Selection 기능 추가할 수 있습니다.
-각각의 Feature 직접 학습 -> 모델 정확도에 기여하는 Feature 선택을 통해- -> 학습 절차 최적화 할 수 있습니다.
- ex) Lasso Regression, Ridege Regression, Decision Tree 등등
- LASSO = L1 regularisation
- RIDGE = L2 regularisation
차원 축소 방법
1. 피드백 루프(Feedback loop) 의 유무에 따라서 구분
- 지도 학습(Supervised learning) vs. 비지도 학습(Unsupervised learning)
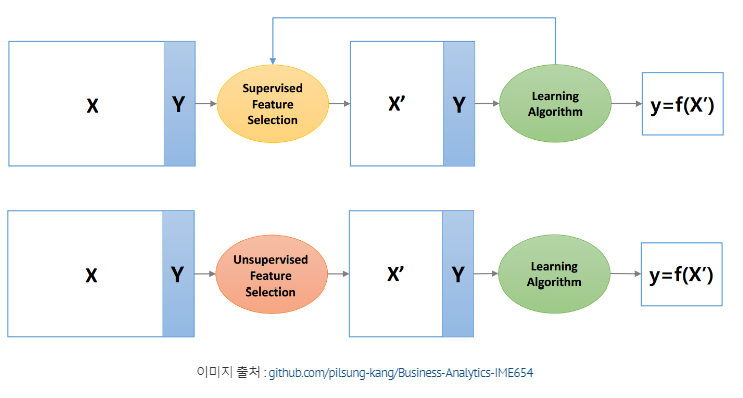
- 지도학습: 분류(classification) 그리고 회귀(regression) 두가지로 다시 나뉩니다
- 분류: 예측하는 결과값이 이산값(discrete value) 일 때 사용 → 예시) 내가 받은 이메일이 스팸인지(true) 스팸이 아닌지(false) 분류할 수 있는 경우
- 회귀: 결과값이 연속값(continuous value) 일때 사용 → 예시) 여러 지표들을 보고 해당 집의 가격을 예측하는 경우
- 분류: 예측하는 결과값이 이산값(discrete value) 일 때 사용 → 예시) 내가 받은 이메일이 스팸인지(true) 스팸이 아닌지(false) 분류할 수 있는 경우
- 비지도학습: 데이터에 대한 레이블이 주어지지 않은 상태에서 컴퓨터가 학습하는 방식. 클러스터링(clustering) 알고리즘
- 데이터의 숨겨진 특징(feature)이나 구조를 발견하는데 사용
2.차원 축소를 실행한 뒤에 나오는 특성의 결과가 어떤 지에 따라서 구분:
- 특성 선택(Feature selection) vs. 특성 추출(Feature extraction)

ENTJ 데이터 분석가 준비중입니다:)