
최근에 프로젝트 회의를 진행하다가 아키텍처 패턴에 대한 궁금증이 생겼습니다.
구글 권장 아키텍처는 정확히 뭐지?
클린 아키텍처와 구글 권장 아키텍처는 어떤 차이가 있지?
왜 클린 아키텍처라는 좋은 구조가 있음에도 구글 권장 아키텍처가 나왔을까?
나는 정말 클린 아키텍처를 적용하고 있을까..
이런 다양한 궁금증들을 해소하기 위해 공부하면서 글을 작성하려고 합니다.
클린 아키텍처
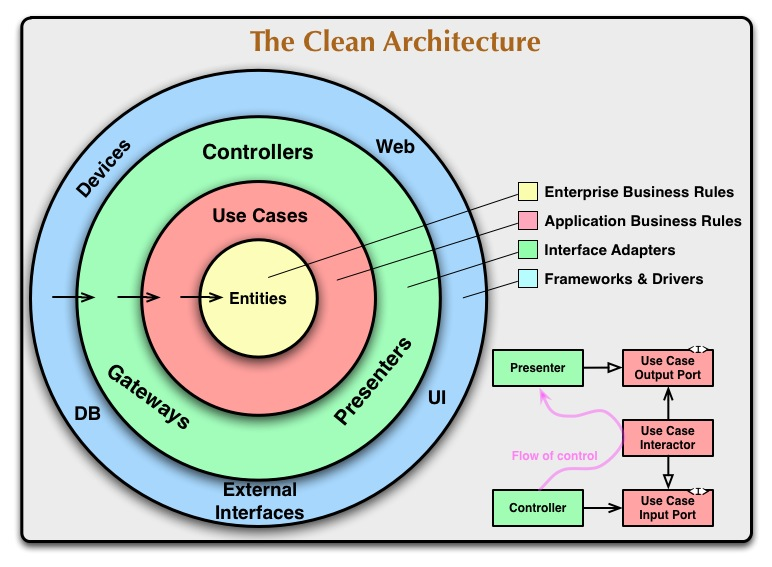
클린 아키텍처는 로버트 C. 마틴이 제안한 아키텍처 패턴입니다.
위의 구조도는 많이 보셨을 것이라고 생각합니다.
이러한 클린 아키텍처는 왜 등장했을까요?
등장 배경
1. 프레임워크와 강하게 결합된다
안드로이드 앱 개발을 한다고 하면 안드로이드 프레임워크에 의존하고,
백엔드 개발을 한다고 하면 스프링이나 JS와 관련된 프레임워크에 의존하게 됩니다.
이러한 경우를 생각해보겠습니다.
- Android의 Activity 혹은 Fragment에 비즈니스 로직이 집약됨
- 프레임워크의 생명 주기나 API가 전체 구조를 지배함
- ORM의 엔티티 모델이 도메인 모델을 대체함
- etc..
작성한 코드가 특정 프레임워크와 강하게 결합되면 업데이트나 교체가 어렵습니다.
특정 시점부터 소프트웨어 개발은 프레임워크에 의존하는 경향이 강해졌습니다.
2. 소프트웨어의 구조가 불안정하다
대부분의 시스템은 시간이 지날수록 여러 이유로 인해 개발하기 힘든 상태로 변합니다.
- 기능이 추가될수록 기존의 코드와 얽힘
- 빠르게 개발하는 것이 우선시되면서 구조가 무너짐
- 핵심 비즈니스 로직이 특정 계층에 의존함
이러한 경우를 소프트웨어 부패라고 표현합니다.
위의 문제 중 일부는 많이들 경험해보셨을 것이라고 생각합니다.
3. 테스트하기 어렵다
1, 2번의 문제에서 비롯된 문제입니다.
비즈니스 로직이 특정 프레임워크, UI, DB에 의존하게 되다 보니
각 기능에 대한 단위 테스트가 어려워집니다.
만약 비즈니스 로직이 안드로이드의 Activity에 집약되어 있다면,
Activity 생명 주기를 고려하면서 테스트를 작성해야 할 것입니다.
이러한 여러 문제를 해결하기 위해 클린 아키텍처가 등장했습니다.
결국 클린 아키텍처는 유지보수, 확장성 등을 고려하고,
각 계층의 관심사를 분리하기 위한 수단이라고 할 수 있습니다.
특징
다시 클린 아키텍처의 구조도로 돌아가보겠습니다.
클린 아키텍처는 크게 4개의 계층으로 구성되어 있습니다.
또한 각 계층 간의 의존 방향은 바깥쪽에서 안쪽을 향합니다.
Entities
엔티티는 어플리케이션의 핵심 규칙을 갖고 있는 계층입니다.
여기에는 아래와 같은 요소가 포함될 수 있습니다.
- 도메인 객체
- 정책, 규칙, 계산 로직
해당 계층은 그 어느 계층에도 의존해서는 안되며,
따라서 외부의 변경 사항에 영향을 받지 않습니다.
Use Cases
어플리케이션이 수행해야 하는 일을 정의하는 계층입니다.
즉, 엔티티를 이용해서 무엇을 할 것인가를 결정합니다.
엔티티를 제외한 외부 계층에 의존해서는 안됩니다.
Interface Adapters
위의 도메인 계층 (엔티티, 유즈 케이스) 은 항상 순수하게 존재해야 합니다.
하지만 우리는 프레임워크의 기능을 사용해야만 할 때가 있습니다.
어댑터 계층은 프레임워크와 순수한 계층 사이에서 필요한 데이터를 변환합니다.
다음과 같은 예시를 들 수 있을 것 같습니다.
- Controller
- Presenter
- ViewModel
Frameworks & Drivers
모든 세부 구현 사항이 존재하는 계층입니다.
데이터베이스, UI 프레임워크, 네트워크 등이 포함됩니다.
구체적인 구현이 존재하기 때문에 변경 가능성이 매우 높고,
그렇기에 순수한 계층으로부터 최대한 멀리 떨어져야 합니다.
안드로이드에서의 클린 아키텍처?
안드로이드 개발을 하면서 클린 아키텍처를 지향하셨다면
앱 아키텍처 구조는 위에서 소개한 클린 아키텍처와 조금 다르다는 것을 알 수 있습니다.
실제 안드로이드 환경에서는 어떻게 적용하고 있는지 알아보겠습니다.
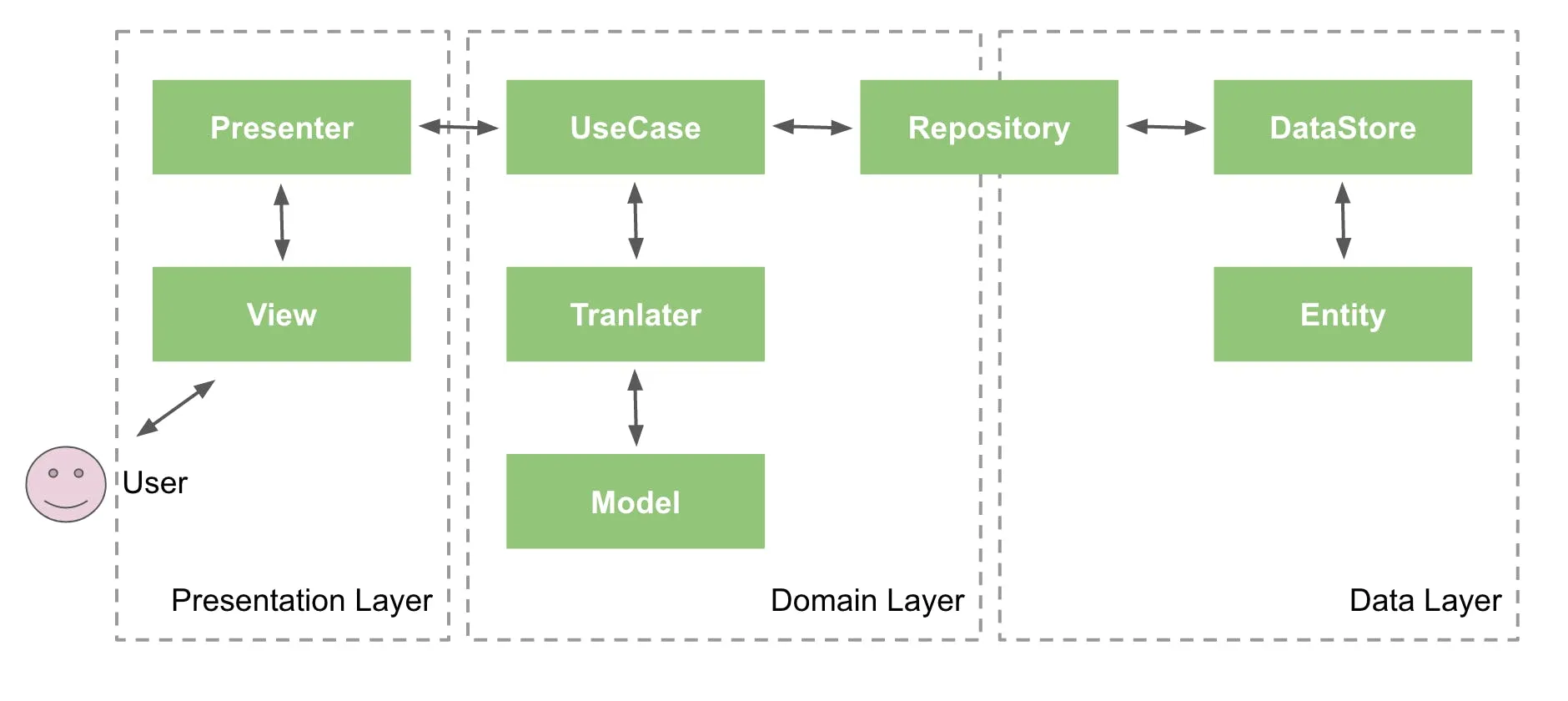
간단하면서도 명확하게 이해할 수 있는 그림이 있어서 가져왔습니다.
이 그림을 보면 위에서 설명한 클린 아키텍처와는 다르게
3개의 레이어로 구성되어 있다는 것을 알 수 있습니다.
Presentation Layer
프레젠테이션 계층은 사용자와의 직접적인 상호작용을 담당합니다.
상위 계층에서 전달한 데이터를 화면에 출력하거나,
사용자의 입력을 상위 계층으로 전달합니다.
클린 아키텍처에서의 Interface Adapters + Frameworks가 공존합니다.
- Interface Adapters: ViewModel
- Frameworks: View System, Compose
물론 이 두 계층 사이의 의존 관계는 클린 아키텍처와 동일합니다.
또한 변경 가능성이 매우 높은 계층이기도 합니다.
Domain Layer
클린 아키텍처의 Entities, Use Cases에 해당합니다.
- Model: 앱에서 사용하는 핵심 데이터 모델 (비즈니스 로직 포함)
- UseCase: 비즈니스 로직
- Repository: 비즈니스 로직에 필요한 데이터 처리
'Repository는 말 그대로 저장소인데, 이게 왜 도메인 계층에 있어야 하지?' 라는 의문점이 생길 수 있습니다.
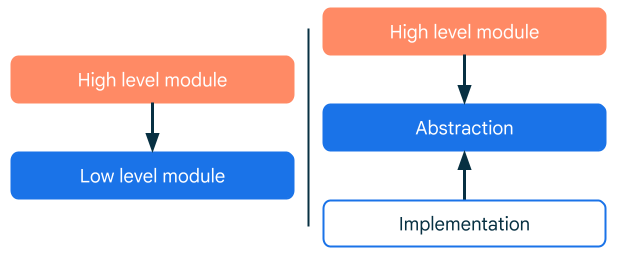
도메인 계층에 존재하는 Repository는 인터페이스로 세부 구현이 존재하지 않습니다.
실제 구현체는 아래에서 설명할 데이터 계층에 존재하는데,
도메인 계층에서는 의존관계 역전 원칙을 통해 두 계층 사이의 의존성을 유지함과 동시에 필요한 데이터를 가져옵니다.
도메인 계층(비즈니스 로직)은 항상 순수하게 유지되어야 하며 다른 계층에 의존하지 않는다는 클린 아키텍처의 설계 원칙을 철저히 따르기 위함입니다.
이러한 특징은 클린 아키텍처와 추후 설명할 구글 권장 아키텍처의 가장 큰 차이점이기도 합니다.
Data Layer
앱에 필요한 데이터를 다루는 계층입니다.
개발 환경마다 구성이 다를 수 있는데, 저의 경우는 아래와 같습니다.
- Repository 구현체
- DataSource: 단 하나의 데이터 원천에 접근
- 그 외: Retrofit 구현체, Room 혹은 DataStore와 같은 로컬 저장소
데이터 계층에서 중요한 개념은 바로 SSOT입니다.
SSOT(Single Source of Truth)란 어떤 데이터를 다루는 것은 단 하나여야만 한다는 것입니다.
이는 데이터의 변경이 일어나는 지점을 하나로 지정하여 데이터의 일관성과 안정성을 보장하기 위함입니다.
위와 같은 구조에서는 DataSource가 SSOT를 보장해주고 있습니다.
이러한 구조가 된 이유
가장 많이 영향을 받은 헤이딜러의 클린 아키텍처
각 계층 간의 분리, 의존성 등은 로버트 C. 마틴이 제안한 클린 아키텍처와 같은데,
크게 3개의 계층으로 구분한 이유에 대해 고민해보았습니다.
1. 모바일 앱은 프레임워크에 의존할 수 밖에 없다
프레임워크는 도구일 뿐이며, 무시할 수 있어야 합니다.
클린 아키텍처에서는 프레임워크와 순수 프로그래밍 언어로 작성한 코드 사이의 강결합에 의해 발생하는 문제를 해결하고자 했습니다.
하지만 앱 환경에서 UI는 안드로이드 OS의 생명주기와 분리될 수 없습니다.
서버나 웹과는 다르게 극도로 한정된 자원에서 실행되는 모바일 어플리케이션은 언제든지 OS에 의해 실행이 중단되거나 종료될 수 있습니다.
따라서 이론대로 UI와 Presenter(ViewModel)를 완전히 분리하여 별도의 계층으로 두기보다는, 프레젠테이선 계층에서 모두 관리하는 것이 훨씬 효율적이라고 생각합니다.
2. 오버 엔지니어링이 될 수 있다
모바일 어플리케이션은 상대적으로 규모가 큰 서버 시스템에 비해
비즈니스 로직의 복잡도가 상대적으로 낮을 수 밖에 없습니다.
이러한 상황에서 계층을 더욱 엄격하게 나눈다면
단순히 데이터를 전달하기만 하는 보일러플레이트 코드가 반복될 것입니다.
또 새로운 기능 요구 사항이 생기면 엄청나게 많은 파일이 추가됩니다.
3. 중요한 것은 모듈 사이의 경계이다
해당 글을 작성하기 위해 자료를 찾아보던 중,
강사룡님의 클린 아키텍처에 관한 글을 보게 되었습니다.
해당 글에서는 모바일 앱에 클린 아키텍처를 도입하려고 노력하는 과정에서
각 모듈 사이의 경계를 구분짓는 것을 가장 중요시 여겼다고 합니다.
특정 모듈의 변경이 다른 모듈에 영향을 미치지 않도록,
같은 모듈 내에서는 일관되고 응집력 있는 결합을 제공하도록 계층을 구분했다고 적혀 있습니다.
구글 권장 아키텍처
안드로이드 공식 문서: Guide to app architecture
안드로이드에서 클린 아키텍처와 함께 항상 거론되는 키워드가 있습니다.
바로 구글 권장 아키텍처입니다.
사실 소프트웨어를 설계하면서 이러한 패턴이 얽매이는 것이 좋지는 않은데,
구글에서는 대놓고 권장하고 있습니다.
먼저 구글 권장 아키텍처가 등장한 배경에 대해 알아보겠습니다.
등장 배경
1. 안드로이드 초창기
초기 안드로이드 문서와 예제는 모든 코드를 Activity 하나에 다 작성하고 있었습니다.
이러한 방법을 God Activity Architecture.. 줄여서 GAA라고 부릅니다.
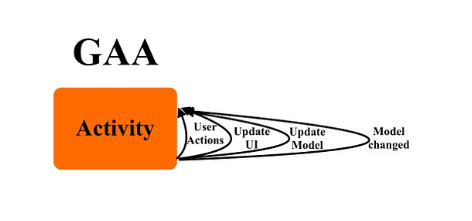
이런 식으로 코드를 작성했을 때의 문제점은 클린 아키텍처의 등장 배경의 설명만으로도 충분할 것 같습니다.
가장 큰 문제는 역시 생명 주기와 여러 로직이 강하게 결합된 것이었습니다.
2. 여러 시도
안드로이드 개발자들은 이 문제를 해결하기 위해 다양한 시도를 했습니다.
- 클린 아키텍처
- MVP, MVVM
- VIPER
- Redux, MVI
클린 아키텍처를 설명할 때도 알 수 있듯이 문제를 해결할 수는 있었습니다.
하지만 방법이 너무 다양해져서 팀 사이의 코드 컨벤션이 일치하지 않거나,
신입 개발자가 들어오면 프로젝트 구조를 파악하는 데 너무 많은 시간을 할애해야 했습니다.
그래서 구글은 Google I/O 2017에서 AAC를 발표함과 동시에,
아키텍처 가이드라인을 제시하게 됩니다.
원칙
우선 공식 문서에서 설명하고 있는 원칙들을 살펴보겠습니다.
1. 관심사의 분리
구글 권장 아키텍처 또한 여느 아키텍처 패턴과 마찬가지로,
관심사의 분리를 가장 중요하게 여기고 있습니다.
우선 액티비티 또는 프래그먼트에 모든 코드를 작성해서는 안된다고 하고 있습니다.
이들의 가장 중요한 역할은 앱의 진입점입니다.
안드로이드 OS는 해당 요소들의 생명 주기를 제어하게 되는데,
사용자의 액션에 의해 구성 변경이 발생하거나 메모리가 부족한 경우 인스턴스를 제거하거나 재생성할 수 있습니다.
때문에 해당 클래스에 데이터나 상태를 저장하는 코드를 작성하게 되면
컴포넌트가 재생성됐을 때 데이터가 유실됩니다.
데이터를 영구적으로 보장하고 사용자 경험을 안정적으로 제공하기 위해서는
컴포넌트 별로 관심사를 분리해야 합니다.
2. 적응형 레이아웃
앱은 구성 변경에 유연하게 대응할 수 있어야 합니다.
화면이 회전되거나, 앱 윈도우의 사이즈가 변경되었을 때
UI가 불안정하게 동작하는 것은 사용자 경험에 나쁜 영향을 끼치게 됩니다.
때문에 적응 가능한 표준 레이아웃을 구현하여, 다양한 폼팩터에 대응할 수 있게끔 해야 합니다.
특히 최근에 들어서는 디바이스의 해상도, 비율 등 디스플레이 스펙이 다양해지고 있기 때문에 앱 개발에서 중요하게 여겨야 할 요소 중 하나가 아닐까 싶습니다.
갤럭시 폴드 개발이 그렇게 힘들다고 하던데..
3. 데이터 모델 기반 UI
데이터 모델은 앱이 사용자에게 보여주어야 하는 데이터를 담고 있습니다.
UI는 이러한 영구적인 데이터 모델로부터 도출되어야 합니다.
데이터 모델은 UI와 분리되어 있지만, ViewModel과 같은 곳에 저장하게 되면 OS에 의해 프로세스가 종료되었을 때 데이터가 유실될 가능성이 있습니다.
때문에 데이터를 영구적으로 저장하는 방법을 충분히 고려해야 합니다.
데이터를 영구적으로 저장하면 아래와 같은 상황에서도 앱이 작동할 수 있습니다.
- OS에 의해 앱의 프로세스가 종료되는 경우
- 네트워크 연결이 끊긴 경우
이러한 데이터 모델을 기반으로 한 앱 아키텍처는 앱을 견고하게 만들어줍니다.
4. Single Source of Truth
앱에 새로운 데이터 타입이 추가되면 해당 데이터에 SSOT를 추가해야 합니다.
SSOT는 데이터의 주인이고, SSOT만이 데이터를 변경할 수 있습니다.
이를 위해 SSOT는 불변 타입을 통해 데이터를 노출시킵니다.
또한 외부에서 호출할 수 있는 메소드나 이벤트를 이용합니다.
이렇게 했을 때 다음과 같은 장점이 있습니다.
- 데이터의 변경이 한 곳에서만 일어난다
- 외부에서 데이터를 임의로 변경할 수 없도록 보호한다
- 데이터 변경에 대한 추적이 쉬워진다
오프라인에서 사용할 수 있는 앱은 데이터베이스가 SSOT 역할을 하게 되고,
ViewModel 또한 SSOT가 될 수 있다고 설명하고 있습니다.
5. UDF (단방향 데이터 흐름)
SSOT 원칙은 단방향 데이터 흐름 패턴에서 주로 사용됩니다.
데이터의 흐름은 오직 한 방향으로 움직이며, 부모 컴포넌트에서 자식 컴포넌트로 움직입니다.
또한 데이터를 수정할 수 있는 이벤트는 반대 방향으로 움직입니다.
안드로이드에서도 상태와 데이터가 상위에서 하위로 내려가고,
하위 컴포넌트에서 발생한 이벤트가 상위로 올라갑니다.
앱의 데이터는 SSOT 역할을 하는 DataSource 혹은 Repository에서 UI로 흐르고, 사용자에 의해 발생한 이벤트(예: 버튼 클릭)가 UI에서 데이터 계층으로 흘러 SSOT로 전달됩니다.
특징
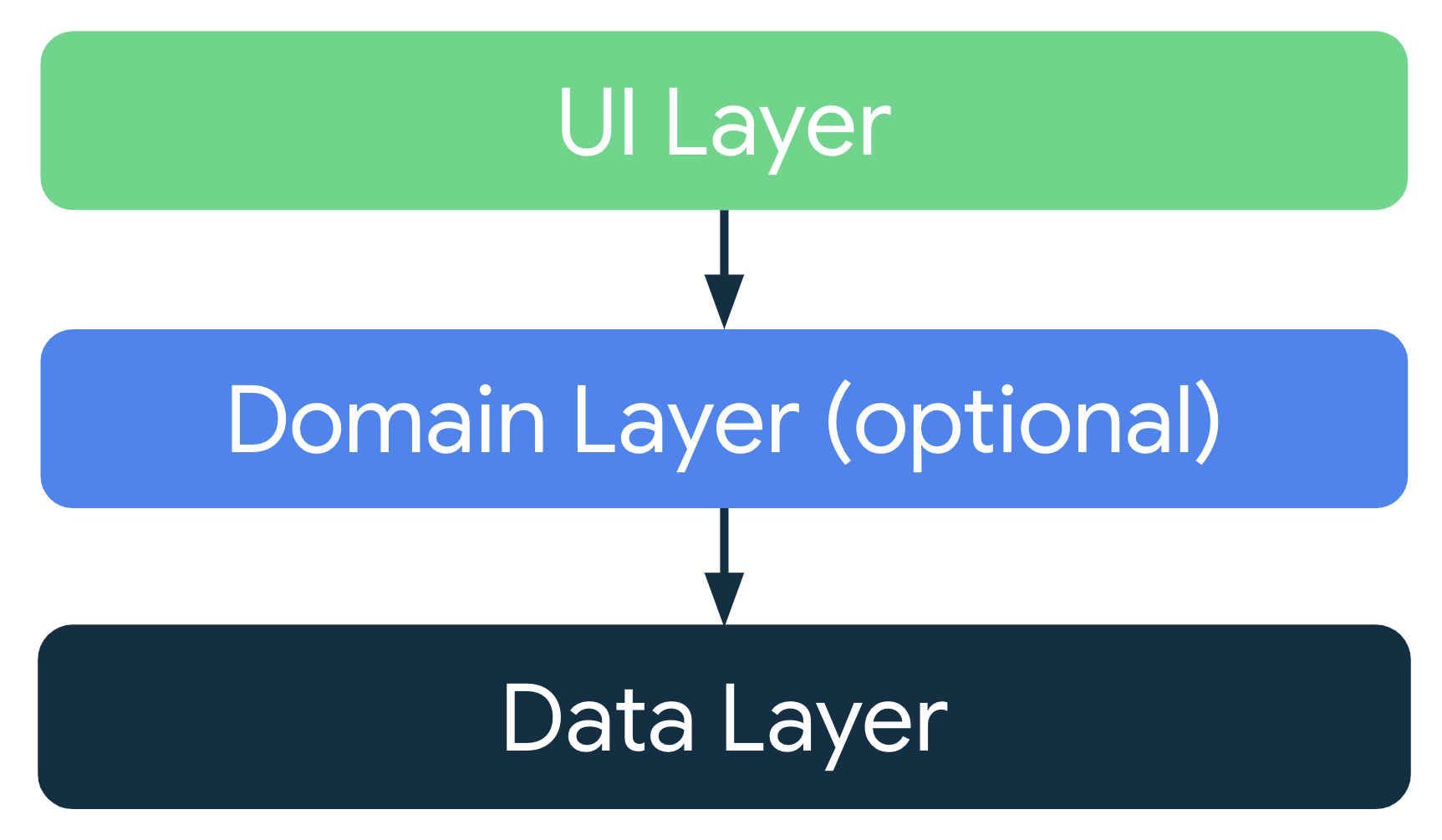
위 그림은 공식 문서에 나와 있는 다이어그램입니다.
클린 아키텍처와 마찬가지로 3개의 레이어로 구성되어 있습니다.
다른 점은 의존성이 단방향으로 구성되어 있고,
도메인 계층이 선택 사항이라는 것입니다.
도메인 계층?
클린 아키텍처를 포함한 다른 아키텍처를 보면,
도메인 계층은 비즈니스 로직과 도메인 객체를 모두 포함하고 있습니다.
위에서도 언급했듯이, 도메인 계층은 순수해야 하며 다른 계층에 의존해서는 안됩니다.
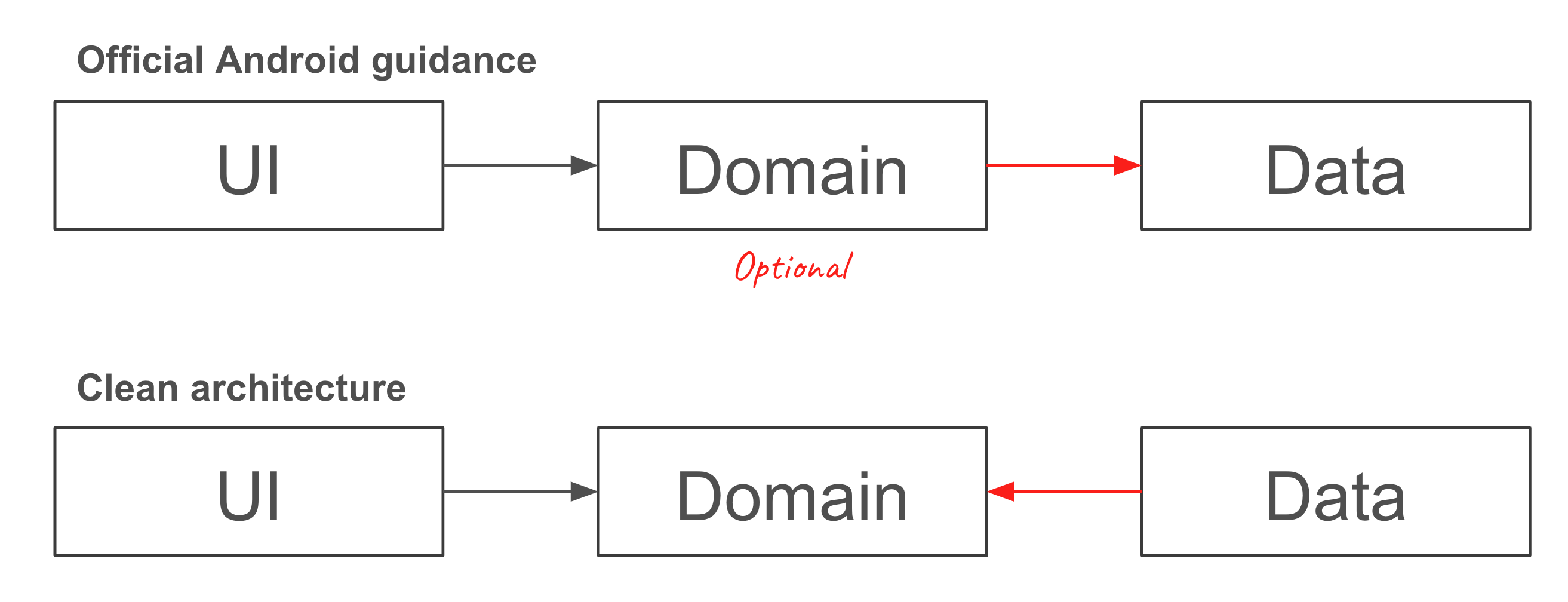
구글 권장 아키텍처는 이러한 클린 아키텍처의 원칙을 위배하고 있습니다.
근데 이게 문제가 되냐? 라면 아니라고 생각합니다.
이와 관련된 토론에서도 비슷한 주제로 이야기를 나누고 있습니다.
I open the dependencies and see that domain layer depends on data. Which has no sense if your definition of the domain is the same as canonical definition of pure business logic layer.
일반적인 도메인의 정의에 따르면 비즈니스 로직 계층은 순수해야 하는데,
구글 권장 아키텍처를 기반으로 설계된 Now in Android는 그렇지 않다는 것입니다.
Or you may use other title for your layer because the domain logic can not depends on the data source implementation. E.g. "logic" layer, but not domain. It's very confusing because you substitute widely known definition of the domain layer with your own one and it gives wrong direction for those who can't argue against the huge Google authority.
고로 구글 권장 아키텍처의 도메인은 기존에 통용되던 도메인과는 다르다고 주장하고 있습니다.
Now in Android 개발자의 답변은 다음과 같습니다.
Many apps aren't complex enough to justify having a domain layer. This is why in the official guidance the domain layer is optional. You can build your app with the UI layer dependent on the data layer, then introduce the domain layer later if the need arises. Ultimately we feel that the official guidance offers the best approach for most Android apps.
대부분의 앱은 도메인 계층을 분리할 만큼 비즈니스 로직이 복잡하지 않기 때문에 도메인 계층이 선택적이며, UI 계층이 직접 데이터 계층에 의존하는 것 또한 가능하다는 것입니다.
공식 문서에는 데이터 계층에 대해 다음과 같이 설명하고 있습니다.
The data layer of an app contains the business logic. Business logic is what gives value to your app—it comprises rules that determine how your app creates, stores, and changes data.
설명에 따르면 구글 권장 아키텍처에서는 데이터 계층에 비즈니스 로직이 존재합니다.
또한 도메인 계층의 설명은 아래와 같습니다.
The domain layer is responsible for encapsulating complex business logic or simpler business logic that is reused by multiple view models. The domain layer is optional because not all apps have these requirements. Use it only when needed, for example, to handle complexity or favor reusability.
복잡한 비즈니스 로직을 캡슐화하거나 간단하지만 재사용될 수 있는 로직을 포함한 계층이라는 것입니다.
하지만 이 설명에서도 알 수 있듯이 모든 앱들이 복잡한 비즈니스 로직을 필요로 하고 있지는 않기 때문에 필요할 때만 도메인 계층을 추가해야 한다고 합니다.
결국 클린 아키텍처의 도메인 계층과 구글 권장 아키텍처의 도메인 계층은 완전히 동일한 개념이 아니라고 생각할 수 있을 것 같습니다.
안드로이드 환경에 최적화
구글 권장 아키텍처가 등장한 배경에 설명했듯이,
구글은 앱 개발의 통일성과 러닝 커브를 낮추기 위해 가이드라인을 제시했습니다.
따라서 클린 아키텍처처럼 도메인 독립성을 엄격하게 요구하면
오히려 진입 장벽이 증가하고, 레이어의 수가 급격하게 늘어나는 등 앱 개발에 있어서 많은 어려움을 겪게 될 것입니다.
구글이 생각했을 때 중요한 것은 도메인의 순수함이 아니라는 것이죠.
만약 요구사항이 추가되어 복잡한 비즈니스 로직이 필요하다면,
그 때 도메인 계층을 기존의 두 계층 사이에 추가하면 됩니다.
무엇을 사용해야 할까?
제가 진행하고 있는 프로젝트는 클린 아키텍처를 지향하고 있습니다.
가장 널리 쓰이는 아키텍처 패턴이기도 하지만, 비즈니스 로직을 다른 계층으로부터 격리시키는 것이 중요하다고 생각했기 때문입니다.
하지만 간단한 기능을 추가해도 시간이 걸리거나, 오히려 계층 구조가 복잡해져서 코드의 가독성이 떨어지는 등 불편한 점도 겪었습니다.
그렇다고 구글 권장 아키텍처가 정답이 될 수는 없을 것 같습니다.
클린 아키텍처는 비즈니스 로직이 아예 격리되어 있어서 변경에 용이하며 다른 계층에 비즈니스 로직이 존재하지 않기 때문에 이는 큰 장점입니다.
또한 멀티 모듈을 프로젝트에 적용했다면 도메인 로직이 포함된 모듈은 순수 코틀린 모듈이기 때문에 플랫폼 확장에도 유리할 것입니다.
그래서 이 두 아키텍처의 특징을 적절히 섞어서 사용하는 곳도 많습니다.
사실 중요한 것은 각 컴포넌트들의 책임과 역할의 분리이며,
정형화된 아키텍처 패턴에 매몰되면 안된다고 생각합니다.
구글에서도 가이드라인을 제시하고 있을 뿐, 반드시 이렇게 해야한다는 것은 아닙니다.
때문에 개발 환경, 요구 사항, 팀 내부 컨벤션 등 여러 요인을 고려하여 적절한 구조를 설계해야 합니다.
결론
이번 글에서는 클린 아키텍처와 구글 권장 아키텍처에 대해 알아봤습니다.
구글에 검색해보면 알 수 있듯, 개발자마다 의견이 갈리는 주제입니다.
(실제로 위의 토론도 불과 1년 전에 진행되었습니다)
아키텍처 구조는 개발자라면 반드시 고민하게 되는 주제같습니다.
저도 완전히 이해하지 못했기 때문에 충분히 찾아보고 고민해보시길 바랍니다.
잘못된 부분이 있으면 댓글로 지적해주세요.
긴 글 읽어주셔서 감사합니다.

너무 좋습니다!