
Intro
프로젝트를 하다보면 데이터베이스 성능 개선을 위해 최적화를 시도할 때가 종종 있습니다. 인덱싱을 통해 성능 개선을 이루는 경우가 많은데 드라마틱한 변화가 없을 때도 많습니다. 삽입, 삭제, 수정 등 연산이 잦을 경우 오히려 쿼리 성능이 더 나빠지는 경우도 있는데 이런 경우 어떻게 성능을 개선할 수 있을까요?
Oracle을 사용하면 좋겠지만 돈이 없는... 이유로 MySQL로 실행 계획을 통한 성능 최적화 방법에 대해 알아보겠습니다.
SQL이 실행되는 과정
MySQL에서 SQL 성능을 좌우하는 것은 옵티마이저입니다. 실행 계획은 옵티마이저가 여러 실행 전략 중 하나를 선택한 최종 판단 결과라고 볼 수 있습니다.
만약 SQL이 MySQL에 전달되었을 때의 흐름을 간단히 보면 다음과 같습니다.

-
Client/Server Protocol
- 클라이언트 (어플리케이션, CLI, JDBC 등)이 MySQL 서버에 접속해서 SQL 전송
- 네트워크 + 인증 + 세션 영역 -> 전처리기에서 한번 더 이 SQL이 해당 객체를 건드려도 되는지 확인
- 커넥션을 매번 만드는 것이 비싸기 때문이 커넥션 풀을 사용
-
Query Cache
- 같은 SQL 문자열에 대해 과거 계산 결과를 저장한 후 같은 SQL 요청 시 바로 반환
- 테이블 변경 시 문제 발생 ➡️ MySQL 5.7 까지는 기본 = off, 8.0부터는 제거..
-
Parser
- 테이블, 컬럼, 함수 이름 등을 토큰 (MySQL이 인식하는 최소 단위)으로 분해
- 분해 과정에서 SQL 문법이 올바른지 검사
- Parse Tree 생성
-
Preprocessor
- 최적화가 가능하도록 정보 취합
- 객체 해석 (컬럼, 테이블의 실존), Alias, 권한 체크, 타입/상수 처리
- 주로 권한 체크, 컬럼 유무 체크
-
Optimizer
- Parse tree를 보고 어떤 방식으로 실행할지 결정 후 실행 계획 생성
- 어떤 인덱스를 사용할지
- 조인 순서, 방식 (Nested Loop Join 기반으로 어떤 테이블을 먼저, 다음을 어떻게 처리할지)
- WHERE 조건을 언제, 어떻게 적용할지 (조건 푸시다운, 범위 스캔 등)
- GROUP BY, ORDER BY를 인덱스로 해결할지, 정렬/임시테이블 쓸지
- LIMIT 처리 방식
- 참고하는 것 = 테이블 통계 (카디널리티, 인덱스 분포 등), 비용 모델
EXPLAIN사용 시 보이는 내용이 주로 이 결과물 (실행 계획)
- Parse tree를 보고 어떤 방식으로 실행할지 결정 후 실행 계획 생성
-
Query Execution Engine
- 실행 계획을 실제로 수행하는 단계
-
Storage Engines (InnoDB, MyISAM, etc...)
- MySQL = 서버 계층 (파서, 옵티마이저, 실행 엔진) + 스토리지 엔진 계층 (실제 데이터 읽기/쓰기)
- 실제 물리적으로 디스크/버퍼풀에서 데이터를 읽고, 잠금/트랜잭션 처리
예시
SELECT u.id, u.name
FROM users u
WHERE u.email = 'cupwan@velog.io';- parser : 문법 체크 및 parse tree 생성
- preprocessor :
users,email존재 확인, 권한 및 타입 확인 - optimizer :
email인덱스가 있으면 인덱스 레인지 or 포인트 룩업 선택 - execution : 인덱스로 row를 찾고 결과 컬럼만 반환
- storage engine : 인덱스 페이지/데이터 페이지를 버퍼풀에서 찾거나 디스크에서 찾아옴
이렇듯 MySQL의 쿼리 처리 과정을 살펴보면 쿼리 성능 개선은 Optimizer의 실행 계획을 먼저 분석해야함을 알 수 있습니다. 인덱스 선택 방식부터 조인 순서, 접근 방식, 추가 연산 여부까지 모두 실행 계획을 통해 알 수 있습니다.
EXPLAIN 기본
이제 MySQL에서 공식으로 제공하는 Employees 데이터베이스를 활용해서 성능 최적화를 위한 EXPLAIN에 대해 알아보겠습니다.
Employees는 test_db 깃허브에서 다운로드 할 수 있습니다.

Schema Inspection을 통해 Employees의 데이터 크기가 꽤나 큰 것을 확인할 수 있습니다.
데이터가 잘 불러오는지 + EXPLAIN을 위한 예시로 가장 큰 용량을 가진 salaries를 전부 조회해보겠습니다.
EXPLAIN SELECT * FROM salaries;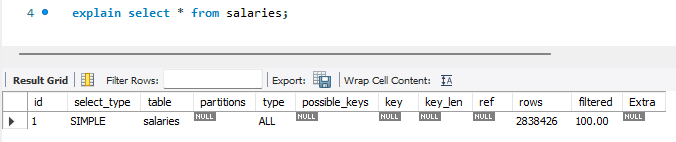
EXPLAIN는 여러 컬럼으로 구성되어 있습니다.
-
select_type: SELECT 성격simple,primary,subquery,derived,union등- 서브쿼리나 UNION 등 사용하면 select의 성격 명시
-
partitions: 파티션 사용 정보- 파티션 테이블일 때, 어떤 파티션만 읽었는지
-
type: 테이블 접근 방식- 해당 테이블을 어떤 방식으로 접근하는지
- 성능 분석에 가장 중요
- 일반적으로 ALL < index < range < ref< eq_ref < const 순으로 좋아짐
- 현재
type = ALL로Full Table Scan을 하고 있다는 의미입니다. 당연히 구리다는 뜻입니다.
-
key: 실제 사용된 인덱스- Key 컬럼은 옵티마이저가 실제로 선택한 인덱스를 의미
- 현재
NULL값으로 인덱스를 사용하지 않습니다. 인덱스 사용 시 해당 인덱스의 이름이 표시됩니다. possible_keys는 인덱스 후보,ref는 인덱스 비교 대상- ➕ 인덱스가 있음에도
key가NULL이라면 옵티마이저는 비용 계산 결과 인덱스를 사용하는 것이 더 비효율적이라고 판단한 것입니다.
-
rows: 예상 조회 건수- 실제 결과 건수가 아닌 옵티마이저의 추정치 입니다.
- 불필요하게 많은 데이터 조회 시, 조인 순서의 효율성, 인덱스 범위 등을 판단하는 용으로 사용됩니다.
- 주로 성능 튜닝의 목표는
rows의 값을 줄이는 방향으로 진행됩니다.
-
Extra: 추가 연산 여부Using where,Using temporary,Using filesort등이 값으로 나옵니다.- 정렬, 그룹 연산으로 인해 추가 비용이 발생하고 있음을 알려줍니다.
성능 최적화
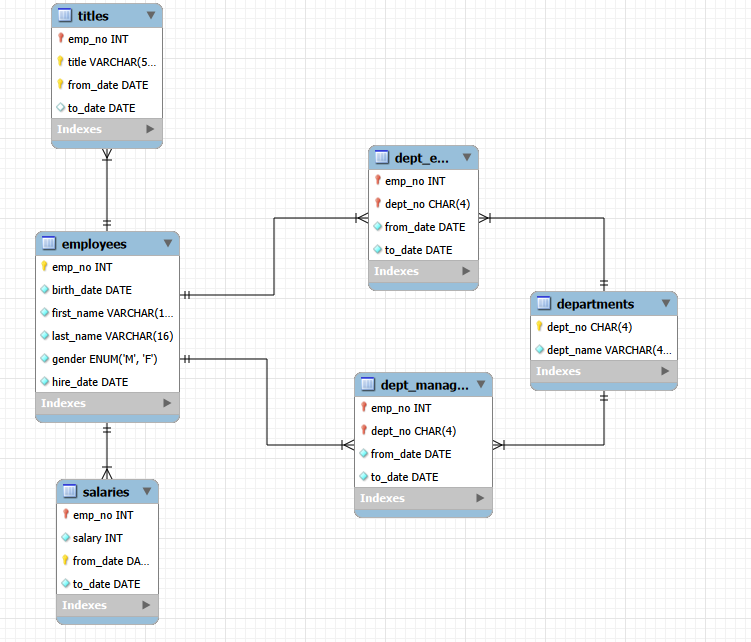
Employees는 이렇게 이루어져 있습니다. 이제 일부러 거지같은 조건을 통해 옵티마이저가 이상한 선택을 하도록 쿼리를 만들어서 성능을 개선해보겠습니다.
-- 실행할 쿼리, 약 6초 소요
SELECT
d.dept_name,
COUNT(*) AS headcount,
AVG(s.salary) AS avg_salary
FROM departments d
JOIN dept_emp de
ON de.dept_no = d.dept_no
JOIN salaries s
ON s.emp_no = de.emp_no
WHERE de.to_date = '9999-01-01'
AND s.to_date = '9999-01-01'
GROUP BY d.dept_name
ORDER BY avg_salary DESC;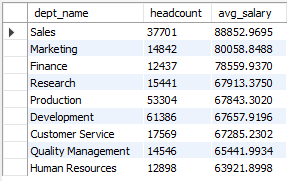
[EXPLAIN]

[EXPLAIN ANALYZE (MySQL 8.0+)]
'-> Sort: avg_salary DESC (actual time=4673..4673 rows=9 loops=1)
-> Stream results (cost=91044 rows=9) (actual time=340..4673 rows=9 loops=1)
-> Group aggregate: count(0), avg(s.salary) (cost=91044 rows=9) (actual time=340..4673 rows=9 loops=1)
-> Nested loop inner join (cost=87460 rows=35834) (actual time=14.3..4465 rows=240124 loops=1)
-> Nested loop inner join (cost=42230 rows=37254) (actual time=14.2..1367 rows=240124 loops=1)
-> Covering index scan on d using dept_name (cost=1.9 rows=9) (actual time=0.239..0.266 rows=9 loops=1)
-> Filter: (de.to_date = DATE\'9999-01-01\') (cost=599 rows=4139) (actual time=13.9..149 rows=26680 loops=9)
-> Index lookup on de using dept_no (dept_no=d.dept_no) (cost=599 rows=41393) (actual time=13.9..139 rows=36845 loops=9)
-> Filter: (s.to_date = DATE\'9999-01-01\') (cost=0.252 rows=0.962) (actual time=0.0111..0.0125 rows=1 loops=240124)
-> Index lookup on s using PRIMARY (emp_no=de.emp_no) (cost=0.252 rows=9.62) (actual time=0.00676..0.0108 rows=10.5 loops=240124)'Nested loop inner join ... rows=240124가 문제입니다.- salaries를 24만 번 조회하는 부분이 전체 시간의 대부분을 잡아먹고 있습니다.
- 순서
- department d : 부서 9개 읽기
- dept_emp de : 부서별 현재 재직자 뽑기
dept_no인덱스로 부서 전체 이력을 가져오고- 그 중
to_date='9999-01-01'만 남김
- salaries s : 직원별 급여 이력에서 현재 급여 1개 찾기
- 직원 1명당 급여 이력 평균 10.5건 읽고
- 그 중 현재 1건만 남김
- 이 과정을 24만번 반복 중;;
그럼 이제 salaries를 효율적으로 개선해보겠습니다.
- PK로만 붙어서 직원 이력 전체 조회
- 우리가 원하는 것 =
to_date='9999-01-01'단 하나의 행
인덱스를 추가하기 위해 salaries의 인덱스 상황을 확인합니다.

혹시라도 따라 하지 마세요!!! 이 인덱스 설정은 잘못됐습니다!!
ALTER TABLE salaries ADD INDEX idx_salaries_to_date_emp (to_date, emp_no);
'-> Sort: avg_salary DESC (actual time=10246..10246 rows=9 loops=1)\n -> Stream results (cost=77534 rows=9) (actual time=686..10246 rows=9 loops=1)\n -> Group aggregate: count(0), avg(s.salary) (cost=77534 rows=9) (actual time=686..10246 rows=9 loops=1)\n -> Nested loop inner join (cost=73808 rows=37254) (actual time=9.54..10110 rows=240124 loops=1)\n -> Nested loop inner join (cost=48661 rows=37254) (actual time=9.5..1657 rows=240124 loops=1)\n -> Covering index scan on d using dept_name (cost=1.9 rows=9) (actual time=1.09..2.15 rows=9 loops=1)\n -> Filter: (de.to_date = DATE\'9999-01-01\') (cost=1313 rows=4139) (actual time=7.52..182 rows=26680 loops=9)\n -> Index lookup on de using dept_no (dept_no=d.dept_no) (cost=1313 rows=41393) (actual time=7.51..175 rows=36845 loops=9)\n -> Index lookup on s using idx_salaries_to_date_emp (to_date=DATE\'9999-01-01\', emp_no=de.emp_no) (cost=0.575 rows=1) (actual time=0.0344..0.0349 rows=1 loops=240124)\n'어이쒸 왜 10초로 늘었지;; ➡️ 이 과정을 반복하는 것이 최적화의 길이겠지요...
그래도 분석 결과를 보니 Secondary Index로 해결이 안되고 (당연함. PK로 한번 더 들어감.) Join 구조를 변경해야할 것 같습니다.
즉, 인덱스를 추가해서 해결될 것 같았지만? 조인 구조가 Nested Loop이고 반복 횟수가 매우 커서 1회 탐색 비용이 더 큰 인덱스를 타게 되기 때문에 오히려 늦어짐을 알 수 있었습니다.
제.. 생각엔 현재 급여만 먼저 한 번 뽑아서 조인해보는 방법을 시도해봤습니다.
EXPLAIN ANALYZE
SELECT
d.dept_name,
COUNT(*) AS headcount,
AVG(cs.salary) AS avg_salary
FROM departments d
JOIN dept_emp de
ON de.dept_no = d.dept_no
AND de.to_date = '9999-01-01'
JOIN (
SELECT emp_no, salary
FROM salaries
WHERE to_date = '9999-01-01'
) cs
ON cs.emp_no = de.emp_no
GROUP BY d.dept_name
ORDER BY avg_salary DESC;'-> Sort: avg_salary DESC (actual time=9519..9519 rows=9 loops=1)
-> Stream results (cost=68140 rows=9) (actual time=925..9519 rows=9 loops=1)
-> Group aggregate: count(0), avg(salaries.salary) (cost=68140 rows=9) (actual time=925..9519 rows=9 loops=1)
-> Nested loop inner join (cost=64415 rows=37254) (actual time=6.91..9352 rows=240124 loops=1)
-> Nested loop inner join (cost=44986 rows=37254) (actual time=6.88..1928 rows=240124 loops=1)
-> Covering index scan on d using dept_name (cost=1.9 rows=9) (actual time=0.026..0.46 rows=9 loops=1)
-> Filter: (de.to_date = DATE\'9999-01-01\') (cost=905 rows=4139) (actual time=7.35..212 rows=26680 loops=9)
-> Index lookup on de using dept_no (dept_no=d.dept_no) (cost=905 rows=41393) (actual time=7.35..204 rows=36845 loops=9)
-> Index lookup on salaries using idx_salaries_to_date_emp (to_date=DATE\'9999-01-01\', emp_no=de.emp_no) (cost=0.422 rows=1) (actual time=0.03..0.0306 rows=1 loops=240124)'더 느려졌습니다! 10초로 늘었는데 이유를 보아하니 옵티마이저가 파생 테이블을 그냥 원래 쿼리로 병합해서 비슷한 흐름으로 실행을 하게 되네요. 그래서 24만번 lookup을 다시..하고 있습니다.
진짜 모르겠다. 이거 어떻게 최적화 하냐... 해서 GPT한테 물어봤습니다. 죄송합니다.
기존 인덱스를 삭제 후 새로운 인덱스를 생성합니다. 9999-01-01인 데이터들이 디스크 상 한 블록에 모일 수 있도록; 살짝 강제로 최적화를 진행합니다.
ALTER TABLE salaries ADD INDEX idx_salaries_final (to_date, emp_no, salary);그 후 쿼리도 CTE를 활용해서 현재 연봉 테이블과 현재 부서 테이블을 미리 전처리한 후 합치는 구조로 변경합니다.
WITH current_salaries AS (
SELECT emp_no, salary
FROM salaries
WHERE to_date = '9999-01-01'
),
current_dept_emp AS (
SELECT emp_no, dept_no
FROM dept_emp
WHERE to_date = '9999-01-01'
)
SELECT
d.dept_name,
COUNT(*) AS headcount,
AVG(cs.salary) AS avg_salary
FROM current_dept_emp de
JOIN current_salaries cs
ON cs.emp_no = de.emp_no
JOIN departments d
ON d.dept_no = de.dept_no
GROUP BY d.dept_name
ORDER BY avg_salary DESC;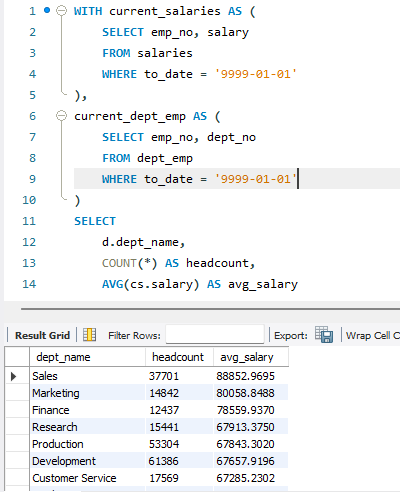
드디어 기존 6초 -> 1.3초로 최적화가 이루어졌습니다. 제가 한 건 아니지만ㅜ
-> Sort: avg_salary DESC (actual time=1362..1362 rows=9 loops=1)
-> Stream results (cost=86935 rows=9) (actual time=149..1362 rows=9 loops=1)
-> Group aggregate: count(0), avg(salaries.salary) (cost=86935 rows=9) (actual time=149..1362 rows=9 loops=1)
-> Nested loop inner join (cost=83209 rows=37254) (actual time=14.4..1278 rows=240124 loops=1)
-> Nested loop inner join (cost=42230 rows=37254) (actual time=14.4..674 rows=240124 loops=1)\
-> Covering index scan on d using dept_name (cost=1.9 rows=9) (actual time=0.0437..0.0605 rows=9 loops=1)
-> Filter: (dept_emp.to_date = DATE\'9999-01-01\') (cost=599 rows=4139) (actual time=9.24..73.3 rows=26680 loops=9)
-> Index lookup on dept_emp using dept_no (dept_no=d.dept_no) (cost=599 rows=41393) (actual time=9.23..68.8 rows=36845 loops=9)
-> Covering index lookup on salaries using idx_salaries_final (to_date=DATE\'9999-01-01\', emp_no=dept_emp.emp_no) (cost=1 rows=1) (actual time=0.00182..0.00233 rows=1 loops=240124)\n'- salaries 조회는 그대로 24만번;;
- covering index를 사용해 필요한 컬럼이 다 들어있으면 테이블로 다시 안가고 인덱스에서 바로 값을 꺼내옴
- 반복 시간이 이전에 비해 감소 (0.03ms -> 0.0017ms 수준)
Outro

사실 Oracle 에서 /* index hint */ 를 통해 최적화 하는 방법을 보고 꽂혀서 MySQL에서도 인덱싱 강제해서 최적화 하는 그런 쿼리를 가져오고 싶었으나 실패했습니다.
그리고 Explain을 통해 쿼리 성능 최적화에 대해 알아보고 싶었으나 어찌 마지막은 생성형 AI가 최적화도 잘하는 것을 알게 되었네요ㅠ
하지만! 실무에서는 복잡한 상황을 인간만이 적용할 수 있기에 이렇게 간단한 최적화가 아니라면 Explain, Explain Analyze 등을 사용해 볼 기회가 있을 것입니다.
다음엔 더 알차게 돌아오겠읍니다. 감사합니다.
