
Intro

폭설이 내리지만 3월, 뭐가 됐든 봄이 오긴 했습니다.
저는 새로운 팀원들과 함께 새로운 프로젝트를 시작했는데 굉장히.. 흥미로운 주제를 가지고 진행 중 입니다. 작년부터 마이데이터 2.0 개혁안을 추진 중인 것 알고 계셨나요? 저도 프로젝트 주제 찾다가 알게되었는데 금융 상품 추천, 소비 패턴 분석 등 현재 마이데이터로는 초개인화된 추천이 안된다는 것을 인지하여 더욱 정밀한 설계로 초개인화 금융 비서를 목표로 하고 있다고 합니다.
여담이지만, 마이데이터 초창기에 SI 업계에서는 마이데이터의 이름이 들려오면 당장 회사를 떠나라는 우스개소리가 있었다고 하는데요? 저희는 저희 발로 이 프로젝트에 뛰어들기로 했습니다.
하지만 시작부터 쉽지 않았는데 추천이 중요한데 추천 알고리즘을 그 누구도 해보지 않았습니다. 그래서..! 얕고 넓게 추천 알고리즘에 대해 학습한 내용을 정리해보겠습니다.
0. 기초 지식

저는 정말 아무것도 모르는 상태에서 시작했기 때문에 구현 프로세스를 정확히 알고자 기초 지식을 좀 알아봤습니다. 사실 GPT 헛소리를 거르고 싶어서 공부했습니다.
추천 등장 배경
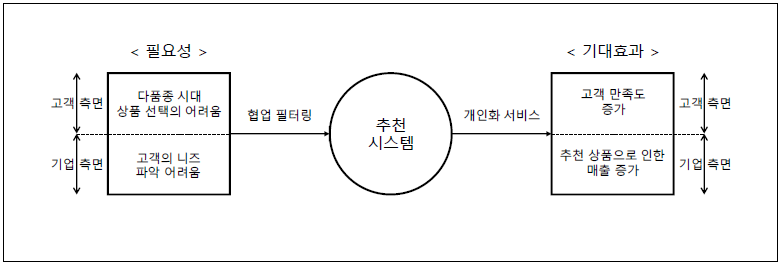
추천 시스템은 정보의 과잉에서 시작됐습니다. 쿠팡에서 평소 사과나 바나나 등 청과를 많이 사는데 막상 보여주는 물건이 티비, 뚜러뻥, 마스킹 테이프 이런 식이면 고객 만족도가 나빠집니다. 또한 각자의 취향이 다르기에 개인화된 추천이 비지니스 관점에서 고객 이탈률을 관리하는데 있어 가장 중요한 포인트가 되었습니다.
2006년, 넷플릭스가 추천 알고리즘을 찾는 대회를 개최하게 되는데 이 대회에서 현재 추천 알고리즘의 기반이 되는 아이디어가 많이 나오게 됩니다. 현재도 많이 사용하는 SVD, SVDpp가 이 대회의 우승팀 작품인데 본격적인 협업 필터링 (CF, collaborative filtering) 발전의 시발점이라 봐도 무방하다 생각합니다.
유사도 (Similarity)

추천은 결국 비슷한 사용자 혹은 비슷한 아이템을 찾는 과정입니다. 결국 유사도가 추천 알고리즘의 성능을 좌우한다 볼 수 있는데 이 유사도를 수치화해 측정하는 방식은 대표적으로 피어슨 상관계수, 코사인 유사도, 자카드 유사도 등이 있습니다.
- 피어슨 상관계수
사용자의 평점 패턴 간의 선형 관계 측정
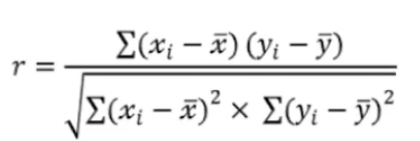
사용자 간 아이템을 평가한 경향이 얼마나 비슷한지 파악할 때 사용됩니다.
값의 범위는 -1 ~ 1로 1에 가까울수록 비슷한 사용자이고 -1에 가까울 수록 반대 성향을 가진 사용자임을 나타냅니다.
- 코사인 유사도
두 벡터 (사용자 or 아이템 간 평점 벡터)의 방향 유사도 측정치 입니다. 크기보다 방향이 유사한지가 중요하기 때문에 평점의 절대값보다 비율적 선호도에 민감합니다.
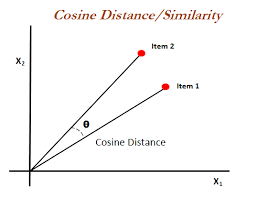
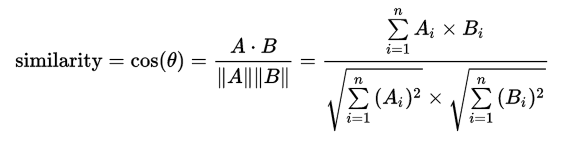
값의 범위는 -1 ~ 1로 1에 가까울수록 같은 성향을 가진 아이템으로 평가됩니다.
주로 사용자/아이템 기반 협업 필터링에서 사용되고 희소한 데이터에 유리하다는 장점이 있습니다.
데이터가 이진값이면 타니모토 계수 사용을 권장합니다.
- 자카드 유사도
두 집합 간의 교집합과 합집합의 비율을 사용해 유사도를 측정합니다. 사용자가 아이템을 사용했는지 여부만 판단할 때 유용합니다.
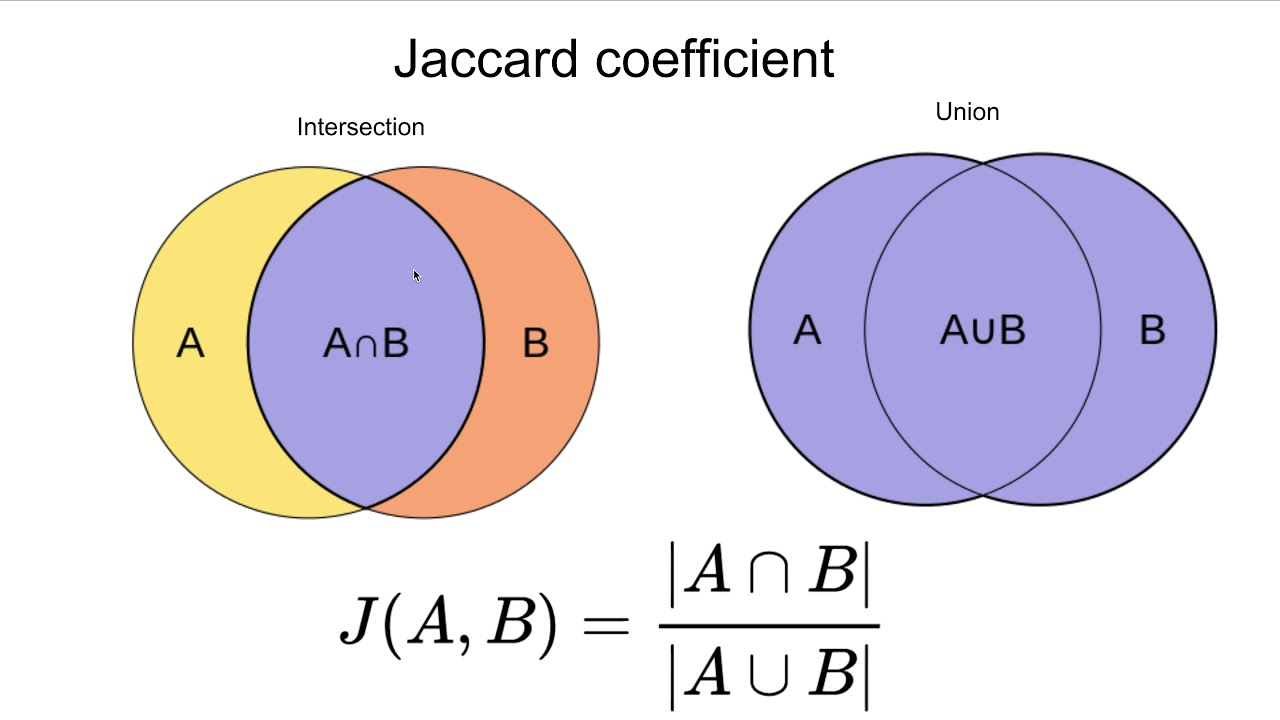
타니모토 계수의 변형으로 이진수 데이터에 유리합니다.
암시적 피드백 (조회, 클릭, 구매 여부 등) 기반 추천에서 자주 사용합니다.
평가 지표
추천을 얼마나 잘했는지도 저희가 알아야 하기 때문에 해당 추천을 평가하는 지표가 있습니다. 크게 예측 정확도 기반 평가와 Top-K 추천 품질 평가로 나눌 수 있습니다.
이 글은 정말 가볍게 다루기에 자세히 알고 싶은 분은 Confusion matrix에 대해 찾아보시길 추천합니다.
- RMSE (Root Mean Sqared Error), MAE (Mean Absolute Error)
예측 정확도 기반 평가 방법으로 사용자가 부여한 평점 값과 알고리즘이 예측한 평점 값의 차이를 계산하는 방식입니다.
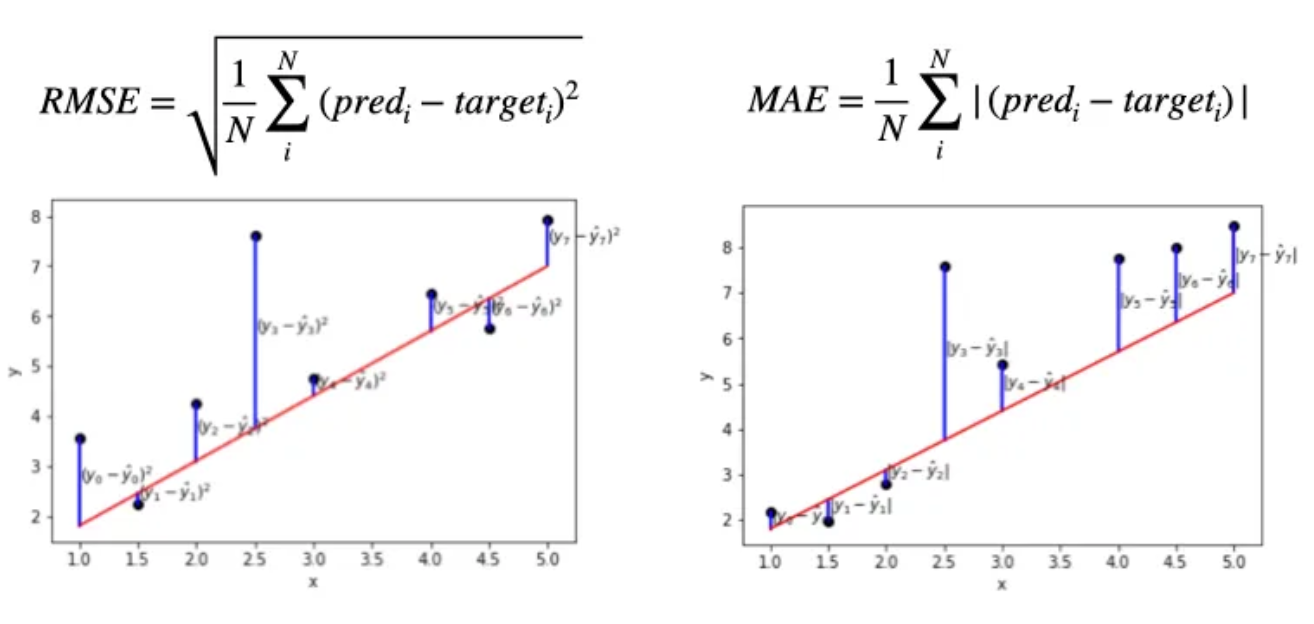
RMSE는 실제 평점과 예측 평점의 제곱 오차 평균의 제곱근으로 오차가 클수록 더 큰 패널티를 주기 때문에, 민감한 평가가 필요할 때 유용합니다.
MAE는 실제 값과 예측 값의 절대 오차 평균으로 RMSE 보다 덜 민감하고 해석이 직관적입니다.
[예제 코드 - sklearn]
# RMSE
from sklearn.metrics import mean_squared_error
import numpy as np
true = np.array([4, 5, 3])
pred = np.array([3.5, 4.5, 2])
rmse = np.sqrt(mean_squared_error(true, pred))
print(rmse)# MAE
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(true, pred)
print(mae)- Precision@K, Recall@K
Top-K 추천 품질 평가 방식으로 실제 서비스에서 Top-K 추천 목록 중 적절한 항목이 있는지?를 판단합니다.
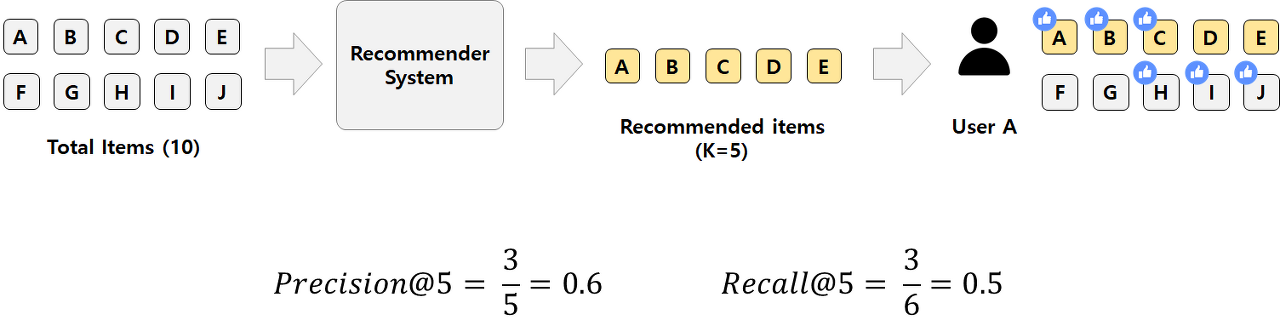
Precision@k 는 정확도 중심의 평가 지표입니다. 추천한 K개의 아이템 중 실제로 좋아한 아이템의 비율을 평가합니다.
위 그림에서 (사용자가 관심있는 추천 아이템 수) / (추천한 아이템 수) 가 Precision으로 Precision@5 = 3/5=0.6 이 됩니다.
Recall@k는 Coverage 중심의 평가 지표입니다. 사용자가 좋아한 전체 아이템 중 추천한 목록에 몇 개가 포함되었는지 (= 사용자의 취향을 얼마나 커버했는가)를 의미합니다.
위 그림에서 (사용자가 관심있는 추천 아이템 수) / (사용자가 실제 관심있는 모든 아이템 수) 가 Recall로 Recall@5 = 0.5가 됩니다.
1. 추천 알고리즘의 종류
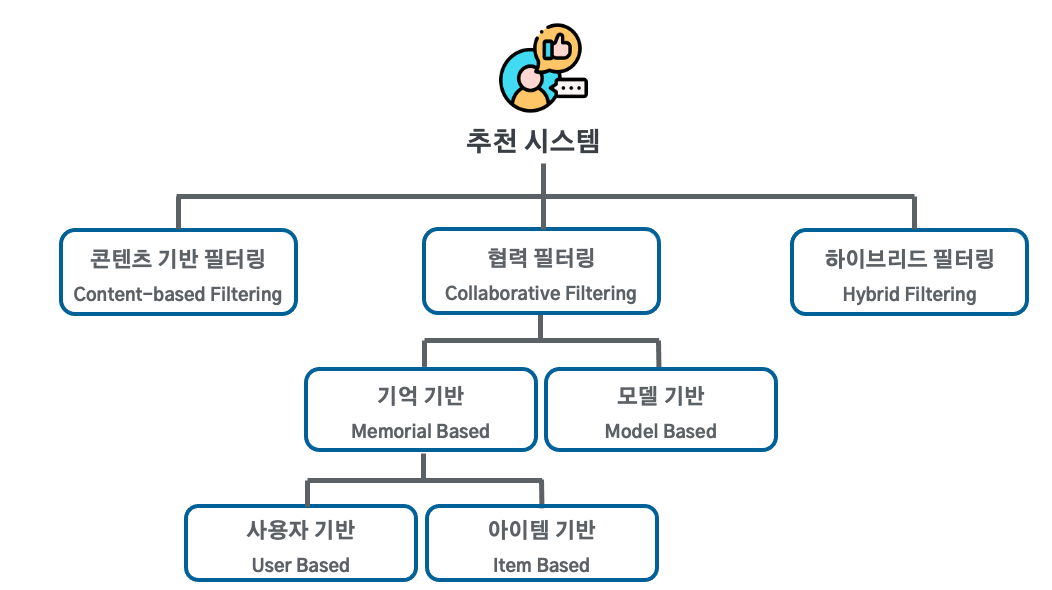
추천 시스템을 구현할 때 가장 먼저 하는 고민이 "어떤 방식으로 추천할까?" 입니다. 보통 입력 데이터의 유형(사용자 / 아이템)에 따라 그리고 사용자 행동 패턴을 어떻게 활용할지에 따라 유형이 크게 컨텐츠 기반 필터링, 협업 필터링, 하이브리드 필터링 으로 나뉩니다.
컨텐츠 기반 필터링
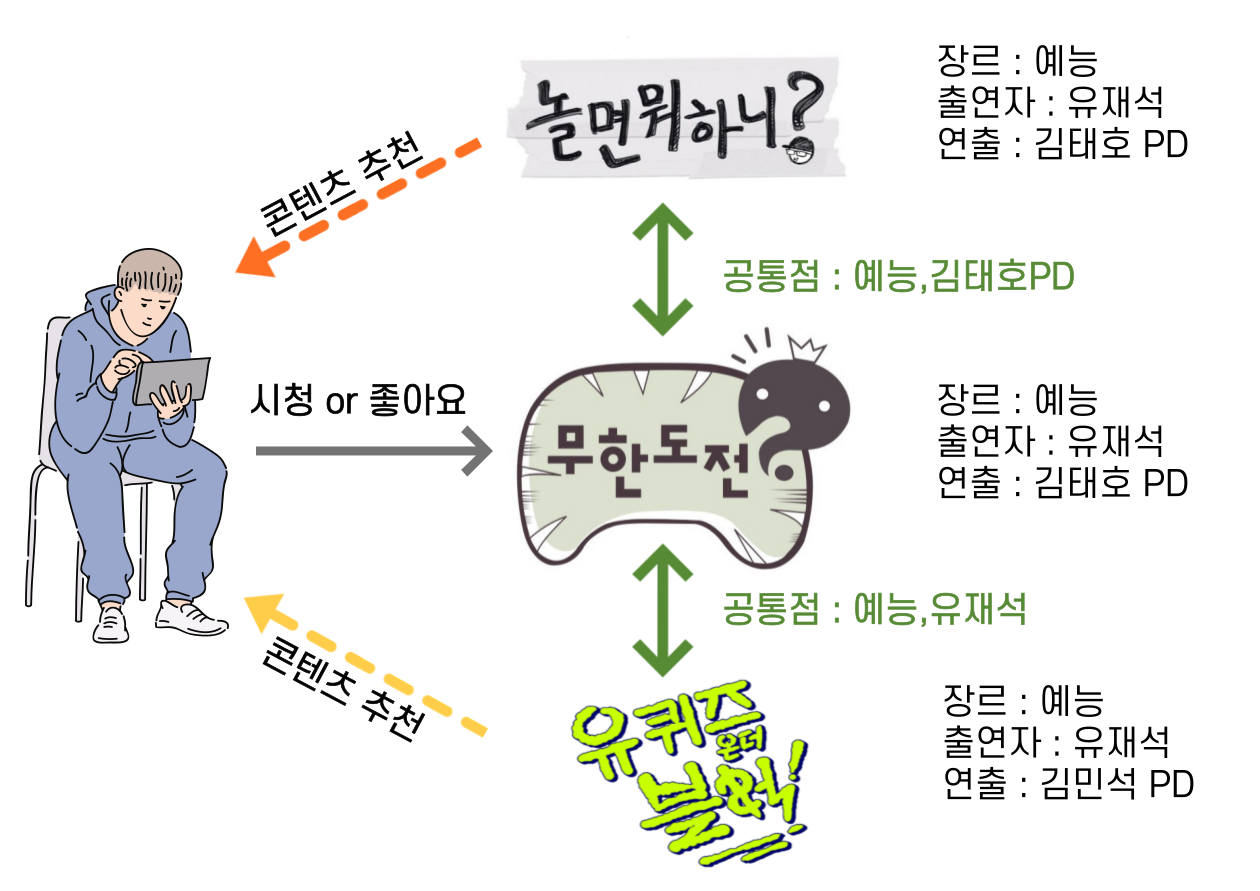
아이템 속성 정보에 기반해 사용자가 좋아한 아이템과 유사한 특성을 가진 다른 아이템을 추천
- 작동 원리
- 사용자 A가 선호한 아이템의 특징을 벡터화
- 추천 대상 아이템들과 유사도를 계산 후 점수화
- 유사도 높은 아이템 순으로 추천
# TF-IDF + Cosine Similarity 예시
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
items = ["액션 판타지 모험", "로맨틱 코미디", "스릴러 범죄 액션"]
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(items)
cos_sim = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix) # 첫 번째 아이템 기준
print(cos_sim)- 장점
- Cold Start에 유리함 (컨텐츠 유사도는 이미 존재하기 때문)
- 개인 취향 반영에 유리
- 단점
- 추천에 다양성이 떨어짐 - 알고리즘의 확증편향 문제 야기
- 아이템에 대한 정형화된 특징 필요 (태그 등)
협업 필터링
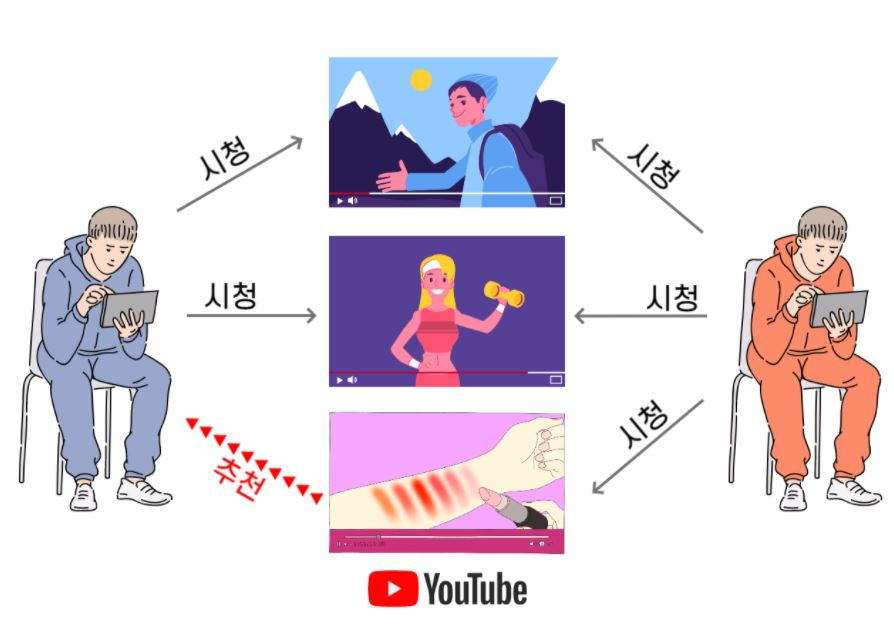
나와 비슷한 사람 혹은 평가 패턴이 유사한 사용자의 행동을 기반으로 추천
-
작동 원리
- 각 사용자의 평점 데이터 간 유사도 분석
- 사용자 간의 벡터 거리(유사도)를 계산하여 가장 근접한 이웃 간 추천
- A와 B가 유사한 행동을 할 때 A의 평가가 없고 B의 평가가 있는 컨텐츠가 있으면 A에게 해당 컨텐츠를 추천함
-
장점
- 컨텐츠 정보 없이 추천 가능
- 의외의 결과 (Serendipity (positive)) 발생 가능 ➡️ 나도 모르는 나의 취향 발견 가능
-
단점
- Cold Start 문제 : 산규 사용자는 데이터가 없기 때문에 유사도 분석이 어려워 추천이 힘들어짐
- 데이터 희소성 문제 (Sparsity) : 사용자가 사용하거나 평가하지 않은 컨텐츠가 훨씬 많기 때문에 발생하는 문제
하이브리드 필터링
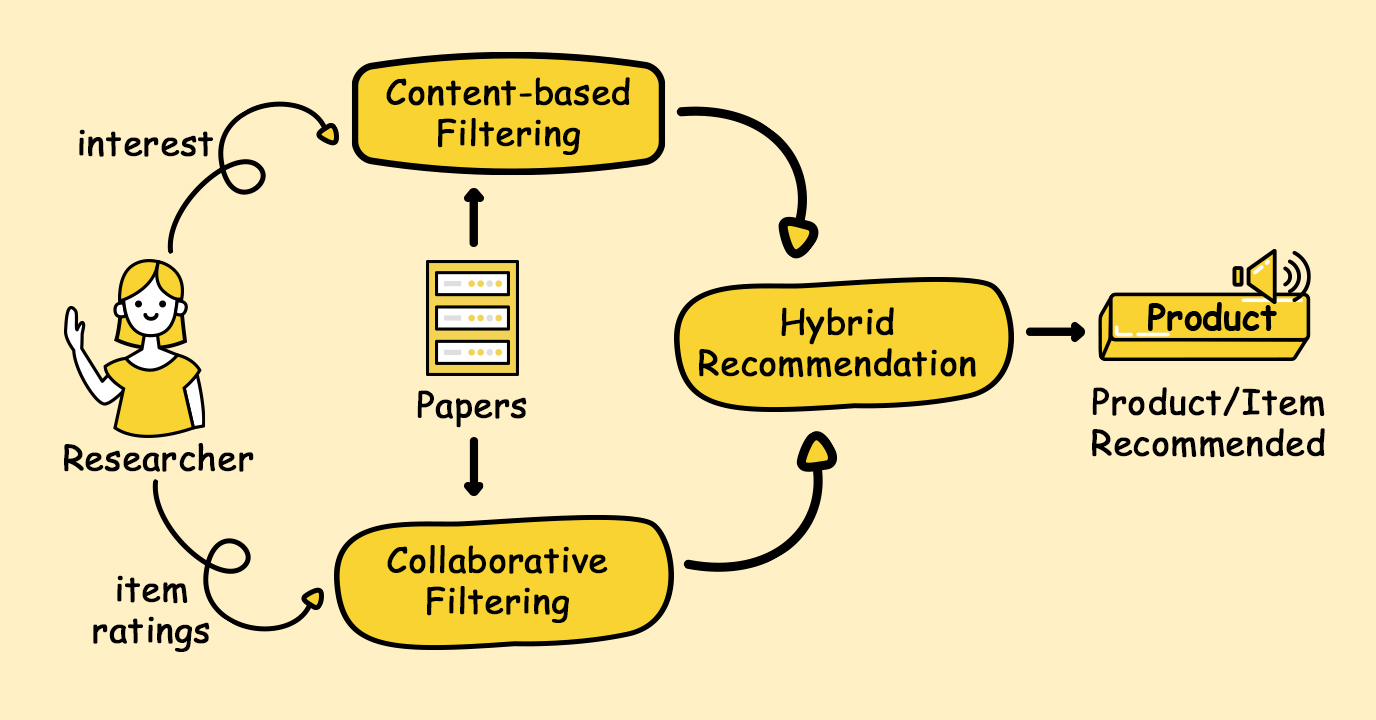
현실 서비스에서 단일 알고리즘으로는 Cold Start, 다양성 부족, 예측 정확도 등 다양한 문제 커버가 힘들기 때문에 컨텐츠 기반 + 협업 필터링의 장점을 결합해 정확도와 다양성을 확보하는 방식
- 작동 원리
- 가중치 기반 결합
- 컨텐츠 기반 점수와 협업 필터링 점수를 일정 비율로 섞음
- 가중치를 어떻게 줄지가 성능의 지표가 되기에 중요
- 전환 방식
- 사용자 상태나 상황에 따라 두 방식 중 하나 선택
- ex) 신규 사용자 : 컨텐츠 기반 필터링 / 기존 사용자 : 협업 필터링
- 단계적 결합
- 하나의 알고리즘으로 후보군 추린 후 다른 알고리즘으로 재정렬 or 필터링 하는 방식
- 가중치 기반 결합
- 장점
- Cold Start, 희소성 문제에 대응 가능
- 추천 다양성과 예측 정확도 확보 가능
- 단점
- 구현..이 힘듬
- 가중치, 전환 기준 등 다양한 케이스를 시도해야하기 때문에 리소스가 크게 증가
2. 협업 기반 필터링의 종류
협업 기반 필터링은 그 중에서도 메모리 기반, 모델 기반, 딥러닝 기반으로 나뉘고 메모리 기반에서 또 다시 한번 유저 기반, 아이템 기반으로 종류가 나뉩니다. 각 방식에 대한 장단점이 있고 어떤 상황에서 사용해야할지를 알아야하기에 정리해보겠습니다.
메모리 기반 협업 필터링 (Memory-Based CF)
기존 사용자-아이템 평점 데이터를 그대로 사용해 유사성 계산 후 추천을 수행하는 방식
-
사용자 기반 추천 (User-based CF)
- 유사한 사용자를 찾아 타인이 좋아하는 아이템을 추천받음
- 유사도는 피어슨 or 코사인 유사도로 계산 추천
- Cold Start
-
아이템 기반 추천 (Item-based CF)
- 사용자가 평가한 아이템과 유사한 아이템을 찾아 추천
- 아이템 간 평점 패턴이 얼마나 유사한지를 분석
- 서비스 규모가 커질수록 효율적, 캐싱에 유리
-
예시 코드
MovieLens 100K 사용,
Python의Surprise패키지 사용
[User-based CF]
from surprise import Dataset
from surprise import KNNBasic
from surprise.model_selection import cross_validate, GridSearchCV
import pandas as pd
# MovieLens 100k 데이터셋 사용
data = Dataset.load_builtin('ml-100k')
# 사용자 기반: user_based=True
sim_options = {
'name': 'cosine', # 유사도 측정 방식 (cosine, pearson)
'user_based': True
}
algo_user = KNNBasic(sim_options=sim_options)
cross_validate(algo_user, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)
# 아이템 기반: user_based=False
sim_options = {
'name': 'cosine',
'user_based': False
}
algo_item = KNNBasic(sim_options=sim_options)
cross_validate(algo_item, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)
# GridSearch로 유사도 비교
def run_knn_grid_search():
param_grid = {
'k': [20, 40, 60],
'sim_options': {
'name': ['cosine', 'pearson', 'msd'],
'user_based': [True, False]
}
}
print("KNNBasic 유사도 방식 + 추천 방식(grid search) 실험 시작 \n")
gs = GridSearchCV(KNNBasic, param_grid, measures=['rmse', 'mae'], cv=3, n_jobs=-1)
gs.fit(data)
# 최고 성능 조합 출력
print("Best RMSE score:", round(gs.best_score['rmse'], 4))
print("Best parameters:", gs.best_params['rmse'])
print()
# 전체 결과 테이블 출력
results_df = pd.DataFrame.from_dict(gs.cv_results)
results_df = results_df[['param_k', 'param_sim_options', 'mean_test_rmse', 'mean_test_mae']]
results_df = results_df.sort_values(by='mean_test_rmse')
print(results_df.head(6))
return results_df
grid_results = run_knn_grid_search()-
KNNBasic
- K-Nearest Neighbors 방식 추천
- 사용자 or 아이템 간 유사도 계산 (유사도 선택 가능 : cosine, pearson, msd 등)
- 사용자 or 아이템에 대해 K개의 가장 유사한 이웃 탐색 (k 값 조절 가능, default=40)
- 이웃들이 남긴 평점 기반으로 예측 평점 계산 후 그 결과 바탕으로 추천
-
성능 추적
- 이전에 최적의 추천을 받을 수 있는 파라미터를 어떻게 구할지 정하는 것이 고민
surprise의GridSearchCV를 사용해 최적의 성능을 추적 가능- 데이터 볼륨에 따라 매우.. 오래걸릴 수 있으니 적당한 설계가 매우 중요
모델 기반 필터링 (Model-Based CF)
평점 행렬을 모델로 학습해 잠재 요인 추출 후 추천을 수행하는 방식
- 작동 원리
- 사용자-아이템 평점 행렬은 대부분 희소 행렬
- 희소 행렬을 두 개의 잠재 요인 행렬로 분해 (Matrix Factorization)
- 분해된 행렬을 통해 아직 평가하지 않은 아이템의 예측 평점을 계산해 추천
- 대표 알고리즘
SVD: 특이값 분해, 선형 대수..에서는 직교 행렬과 대각 행렬로 분해하는 방법을 의미SVDpp: SVD에 암시적 피드백까지 반영하는 방법NMF: 음수 미포함 행렬 분해로 SVD보다 데이터 구조를 좀 더 잘 반영 가능, SVD는 feature들 간의 직교성이 보장되는데 이런 성질이 데이터 구조를 잘 반영하지 못하게 될 수 있어 양음수를 포함하지 않는 (픽셀 단위 데이터) 경우 NMF의 성능이 좋음ALS: Matrix Factorization의 학습 속도를 향상시킨 최적화 방법, Spark에서 주로 사용
- 장점
- 희소 데이터에 유연하게 대응 가능
- 대규모 데이터에 적합
- 유사도 계산을 직접하지 않음
- 단점
- 해석이 어려움 (잠재 요인의 의미가 명확하지 X)
- 학습 시간이 오래 걸리고 하이퍼파라미터 튜닝 필요
- 예측 평점 성능은 우수하지만 Top-K 추천의 다양성이 떨어짐4
- 예제 코드
[기초 SVD]
from surprise import Dataset, SVD
from surprise.model_selection import cross_validate
# MovieLens 100k 내장 데이터셋 로딩
data = Dataset.load_builtin('ml-100k')
algo_svd = SVD()
# 성능 평가
results = cross_validate(algo_svd, data, measures=['RMSE', 'MAE'], cv=3, verbose=True)- surprise 패키지의 가장 기본적인 SVD 활용 코드
cross_validate()교차 검증을 이용해 모델 평균 성능 측정
Evaluating RMSE, MAE of algorithm SVD on 3 split(s).
Fold 1 RMSE: 0.9321 MAE: 0.7362
Fold 2 RMSE: 0.9275 MAE: 0.7328
Fold 3 RMSE: 0.9298 MAE: 0.7345
------------------------------
Mean RMSE: 0.9298 MAE: 0.7345이런 식의 결과가 나오게 됩니다. RMSE 기준으로 생각보다 성능이 좋음;;
[하이퍼 파라미터 튜닝]
from surprise.model_selection import GridSearchCV
# 실험할 파라미터 그리드 정의
param_grid = {
'n_factors': [50, 100], # 잠재 요인 개수
'lr_all': [0.002, 0.005], # 전체 학습률
'reg_all': [0.02, 0.1] # 전체 정규화 파라미터
}
# SVD 모델에 대해 그리드 탐색 수행
gs = GridSearchCV(SVD, param_grid, measures=['rmse'], cv=3)
gs.fit(data)
# 결과 출력
print("Best RMSE score:", round(gs.best_score['rmse'], 4))
print("Best parameters:", gs.best_params['rmse'])Best RMSE score: 0.9214
Best parameters: {'n_factors': 100, 'lr_all': 0.005, 'reg_all': 0.02}기본 파라미터로도 괜찮은 성능이 나오지만 최적화를 위해 GridSearchCV를 사용해 하이퍼파라미터를 튜닝하면서 가장 좋은 파라미터를 찾을 수도 있습니다
위 예제에서는 잠재 요인 개수, 학습률, 정규화 개수 세 개의 파라미터에 대해 수행한 결과입니다
3. 하이브리드 필터링 Hybrid Filtering

저는 이번 프로젝트에서 하이브리드 필터링을 쓸거야!!!라고 선언해버렸습니다. 저질렀으니 수습을 해야하는데 정말 벌써부터 과거의 제가 싫어집니다. 그래도 이미 저지른 거 예제를 통해 자세히 알아보겠습니다.
가중치 기반 결합
[TF-IDF + SVD 가중 평균]
import pandas as pd
from surprise import Dataset, Reader, SVD
from surprise.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import MinMaxScaler
class HybridRecommender:
def __init__(self, alpha=0.5, top_n=10):
self.alpha = alpha
self.top_n = top_n
# Load data
self.movies = pd.read_csv("data/movies.csv") # itemId, title, genres
self.ratings = pd.read_csv("data/ratings.csv") # userId, itemId, rating
# 학습용 SVD 모델 준비
self.svd_model = self._train_svd_model()
# 콘텐츠 기반 TF-IDF 유사도 행렬 생성
self.cosine_sim_matrix = self._compute_content_similarity()
def _train_svd_model(self):
reader = Reader(rating_scale=(0.5, 5.0))
data = Dataset.load_from_df(self.ratings[['userId', 'itemId', 'rating']], reader)
trainset, _ = train_test_split(data, test_size=0.2)
algo = SVD()
algo.fit(trainset)
return algo
def _compute_content_similarity(self):
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(self.movies['genres'])
cosine_sim = cosine_similarity(tfidf_matrix)
return cosine_sim
def _get_content_scores(self, target_movie_id):
idx = self.movies.index[self.movies['itemId'] == target_movie_id].tolist()[0]
sim_scores = list(enumerate(self.cosine_sim_matrix[idx]))
return sorted(sim_scores, key=lambda x: x[1], reverse=True)
def recommend(self, user_id):
# 추천할 대상: 사용자가 보지 않은 영화
user_rated = self.ratings[self.ratings['userId'] == user_id]['itemId'].tolist()
candidates = self.movies[~self.movies['itemId'].isin(user_rated)]
content_scores = []
cf_scores = []
for _, row in candidates.iterrows():
movie_id = int(row['itemId'])
# 콘텐츠 기반 유사도: 대상 영화와의 장르 유사도 평균
sim_list = self._get_content_scores(movie_id)[1:11] # 유사한 영화 10개 기준
sim_movie_ids = [i for i, _ in sim_list]
sim_score = sum([self.cosine_sim_matrix[movie_id - 1][i] for i in sim_movie_ids]) / len(sim_movie_ids)
content_scores.append((movie_id, sim_score))
# 협업 필터링 기반 예측 평점
pred_rating = self.svd_model.predict(str(user_id), str(movie_id)).est
cf_scores.append((movie_id, pred_rating))
# 정규화
df = pd.DataFrame(content_scores, columns=['itemId', 'content_score'])
df['cf_score'] = [score for _, score in cf_scores]
scaler = MinMaxScaler()
df[['content_score', 'cf_score']] = scaler.fit_transform(df[['content_score', 'cf_score']])
# 가중 평균 점수 계산
df['hybrid_score'] = self.alpha * df['content_score'] + (1 - self.alpha) * df['cf_score']
# Top-N 추천
top_items = df.sort_values(by='hybrid_score', ascending=False).head(self.top_n)
merged = top_items.merge(self.movies, on='itemId')
return merged[['itemId', 'title', 'genres', 'hybrid_score']]alpha: 컨텐츠 기반 점수를 얼마나 반영할지 결정하는 가중치top_n: 최종 추천 개수trainset, _ = train_test_split(data, test_size=0.2): 80% = 학습용, 20% = 테스트용으로 분할tfidf_matrix: genres 컬럼이 문자열이라 TF-IDF로 벡터화 ➡️ 코사인 유사도로 유사도 행렬 생성- 최종 점수 = 가중 평균 계산 : 초기 설정한
alpha= 컨텐츠 기반 영향력 /1-alpha= 협업 기반 영향력 - alpha를
GridSearchCV로 최적의 가중치 비율을 찾는 것이 중요!
전환 기반 결합
[사용자 평점 수 기준 알고리즘 전환]
def switch_based_recommendation(user_id, user_rating_count, threshold=5):
if user_rating_count < threshold:
print(f"User {user_id} → 콘텐츠 기반 사용")
return "Content-Based"
else:
print(f"User {user_id} → 협업 기반 사용")
return "Collaborative Filtering"
switch_based_recommendation('u3', 2)
switch_based_recommendation('u1', 10)- 정말 별 거 없습니다.
- Cold Start를 해결하기 위해 컨텐츠 기반 필터링을 신규 유저에게 강제 선물하는 방식
switch_based_recommendation의 필터링을 선택하는 기준을 잘 나누는 것이 중요.- 어디까지 신입인가?
단계적 결합
[TF-IDF로 후보 생성 후 SVD로 재정렬]
# TF-IDF로 유사한 콘텐츠 5개 추천
content_candidates = [101, 102, 103, 104, 105]
# SVD 예측 점수로 재정렬
from surprise import SVD, Dataset, Reader
import pandas as pd
# 평점 데이터
ratings = pd.DataFrame({
'user': ['u1', 'u1', 'u2', 'u2'],
'item': [101, 102, 103, 104],
'rating': [5, 3, 4, 2]
})
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(ratings, reader)
trainset = data.build_full_trainset()
algo = SVD()
algo.fit(trainset)
# 후보군 점수 계산
sorted_candidates = sorted(
content_candidates,
key=lambda x: algo.predict('u1', x).est,
reverse=True
)
print("추천 순위:", sorted_candidates)- 후처리 최적화용으로 사용
- 네이버, 쿠팡 등 대규모 서비스에서 후보 생성 모델 (뭔가 복잡하겠죠?)에 마지막으로 정렬 모델을 추가해서 사용
성능 비교
[Top-N 추천 후 성능 비교]
# 예시: 추천 결과와 실제 클릭한 아이템 비교
def precision_at_k(recommended, ground_truth, k=5):
recommended_k = recommended[:k]
relevant = set(recommended_k) & set(ground_truth)
return len(relevant) / k
# 사용자 u1의 ground truth (사용자가 좋아하는 아이템)
u1_true = [101, 105, 109]
# 각 방식으로 추천된 아이템 (실제로는 아마 코드 돌리겠죠?)
recommend_weighted = [101, 106, 108, 102, 110]
recommend_switch = [105, 104, 101, 106, 112]
recommend_cascade = [109, 101, 107, 103, 115]
print("Weighted : ", precision_at_k(recommend_weighted, u1_true))
print("Switching : ", precision_at_k(recommend_switch, u1_true))
print("Cascade : ", precision_at_k(recommend_cascade, u1_true))- 성능을 어떤 것으로 비교할지 선택하는 논리가 필요
Outro

사실 글 하나에 끝날 내용이 절대 아니지만 그래도 최대한 압축해서 작성해봤습니다. 배운대로 아는대로 작성하긴 했는데 이론적인 깊은 내용을 (잘 몰라서) 빼고 보니 설명이 부실해보이고 막 그러네요. 힘들어서 마지막에 막.. 엄청... 짧아지고 그랬는데 그래도 힘냈습니다. 솔직히 저 부분 정확히 돌려보고 결과값이 있어야 내용이 더 보충될 것 같은데 아직 데이터도 못구한 상태라 쓸 수가 없었습니다.
추천 알고리즘이 뿜 했다가 사악 사그라진 것 같으면서도? 사실 우리 곁에 항상 있는 기능이다보니 기회가 된다면 깊게 공부해보고 싶네요. 공부해보니 ML/DL 개념도 엄청 섞여있기 때문에 AI 분야까지 공부가 되지 않을까 싶습니다. 물론 몰라서 이번 글엔 다 뺐지만.
다음엔 더 좋은 글로 찾아뵙겠습니다.
출처
https://maily.so/marsinmarine/posts/gd5ry0y1o1w
https://abluesnake.tistory.com/117
https://blog.skby.net/%ED%98%91%EC%97%85-%ED%95%84%ED%84%B0%EB%A7%81-collaborative-filtering/
https://blog.nerdfactory.ai/2021/09/23/recommend-system-classification-metric-1.html
https://datadoctorblog.com/2023/08/04/Py-ML-Evaluation-Model-Classification/
