
Intro
프로젝트를 진행하면서 채팅 기록을 저장하기 위해 mongo DB를 많이 사용했습니다. 문서형 NoSQL의 주축을 담당하고 있는 mongo DB는 제가 사용했던 채팅이나 대용량 로그, 실시간 피드 등 다양한 도메인에서 사용되고 있습니다. 이번 글에서는 Mongo DB 공식 홈페이지 강의를 들으며 공부한 내용을 정리해보겠습니다.
NoSQL
이전에 작성한 글에 더해 좀 더 자세히 알아보겠습니다.
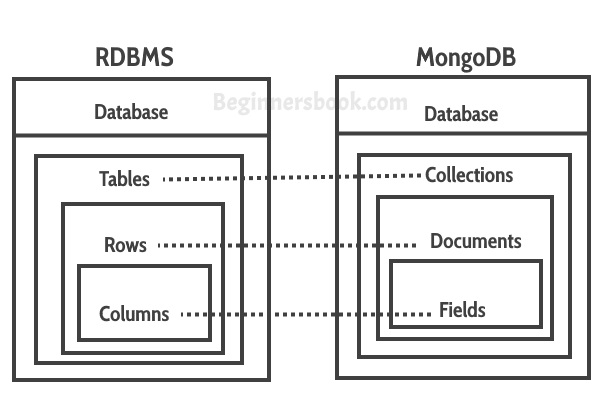
Mongo DB는 NoSQL의 한 종류로 문서형 데이터베이스로 일컬어집니다. 관계형 데이터베이스 (RDBMS)의 한계를 극복하기 위해 등장한 데이터베이스로 기존의 정형화된 테이블 구조 대신, 유연한 스키마와 확장성 중심 설계를 통해 대용량 데이터, 비정형 데이터에 유리합니다
- 스키마가 자유로움 : 구조가 고정되어 있지 않아 변경이 쉽다
- 수평적 확장이 쉬움 : 분산 저장이 기본 전제
- 고속 쓰기 처리에 강점
- CAP 이론에 따라 일관성 대신 가용성을 중시하는 경우가 많다
| 기능 | 관계형 데이터베이스 | NoSQL |
|---|---|---|
| 데이터 모델 | 테이블 형식 (행과 열) | 다양함 (문서형, 키-값, 그래프 등) |
| 확장성 | 수직 확장 용이 / 수평 확장은 복잡함 | 수평 확장이 쉬움 |
| 관계 표현 방식 | 테이블 간 JOIN 사용 | 비정규화하거나 애플리케이션에서 관계 처리 |
| 데이터 무결성 | 제약 조건으로 강력히 보장 | 성능을 위해 무결성 조건이 관계형보다 느슨함 |
| 일관성 | 강한 일관성 보장 | 일반적으로 최종적 일관성 |
| 사용 사례 | 금융 시스템, CRM, ERP | 빅데이터, 실시간 웹 앱 |
| 성능 | 복잡한 쿼리에 강함 | 읽기/쓰기 중심 워크로드에 최적화 |
| 유연성 | 낮음 (스키마 변경이 어렵고 복잡함) | 높음 (데이터 구조 변경이 쉬움) |
| 트랜잭션 | 복잡한 트랜잭션 지원 | 일부는 제한적 트랜잭션 지원 |
| 데이터 크기 | 보통 소~중간 규모 데이터셋 | 매우 큰 데이터셋도 효율적으로 처리 가능 |
| 예시 | MySQL, PostgreSQL, Oracle, SQL Server | MongoDB, Cassandra, Redis, Neo4j |
1. RDBMS ➡️ Document Model
RDB는 정규화, MongoDB는 사용 패턴 (Workloads)이 설계의 중심
이번 프로젝트를 하며 느낀점은 Mongo DB는 RDB와는 데이터 모델링 자체에 대한 철학이 다른 것을 인지해야합니다.
워크로드 기반 설계
Mongo DB에서는 데이터를 어떻게 쓰고, 읽고, 업데이트 할 것인지 실제 사용 패턴을 중심으로 데이터 모델을 설계해야합니다.
- 어떤 데이터를 자주 함께 조회하는가?
- 읽기와 쓰기 중 어떤 작업이 더 많은가?
- 특정 문서의 크기가 계속 커질 가능성이 있는지?
| 항목 | 관계형 데이터베이스 (RDB) | MongoDB (문서 DB) |
|---|---|---|
| 설계 기준 | 정규화 (데이터 중복 제거) | 워크로드 (쿼리 최적화) |
| 구조 | 테이블/행/열 | 문서(JSON-like) |
| 관계 표현 | JOIN | Embedded / Reference |
이러한 설계의 차이는 RDB는 데이터 정합성과 무결성이 중요하고 Mongo DB는 가장 큰 특징인 데이터 중복 허용과 쿼리 효율성 우선시 하기 때문입니다.
모델링 시 고려사항
Mongo DB에서 문서 설계 시 다음과 같은 기준을 고려합니다.
- 한 번의 요청으로 필요한 데이터를 모두 가져올 수 있는지?
- 문서 크기가 16MB (Mongo DB의 단일 문서 크기)를 초과할 위험이 있는지?
이 기준을 통해 문서 간 관계를 Embedding으로 할 지 Referencing으로 할 지 결정됩니다.
{
"userId": "abc123",
"name": "홍길동",
"posts": [
{"title": "첫 글", "createdAt": "..."},
{"title": "두 번째 글", "createdAt": "..."}
]
}MongoDB로 사용자 게시글을 조회한 예시입니다. 자주 같이 조회된다면 예시와 같이 임베딩이 적절하지만 게시글 수가 수천 개 이상으로 커진다면 분리한 후 레퍼런싱 하는 것이 더 적절합니다.
예시를 통해 더 알아봅시다.
- 유저 프로필 + 설정
{
"userId": "123",
"name": "철수",
"settings": {
"theme": "dark",
"notifications": true
}
}name과 settings는 유저 정보를 볼 때 항상 함께 조회됩니다. 따라서 지금처럼 임베딩이 적절합니다.
- 유저 + 게시글
{
"userId": "123",
"name": "철수"
}{
"postId": "999",
"userId": "123",
"title": "MongoDB 잘 쓰는 법",
"content": "..."
}사용자에 대한 정보는 자주 변경되지 않습니다. 하지만 게시글은 개수가 많고 조회, 추가, 삭제가 잦습니다
따라서 유저 데이터를 조회할 때 게시글이 항상 가져올 필요가 없기 때문에 레퍼런싱하는 것이 적절합니다.
2. 스키마 설계 패턴과 안티 패턴
좋은 스키마 설계는 데이터를 저장하는 구조를 넘어 읽기, 쓰기 효율성 + 유지보수성을 좌우합니다.
Mongo DB는 자유로운 구조 덕분에 처음엔 빠르게 개발할 수 있지만, 데이터가 많아지면 조회 성능 저하, 문서 크기 한계, 쿼리 복잡도 증가 등의 문제가 발생합니다. 그래서 데이터의 특성에 맞게 구조를 설계하는 패턴이 필요합니다.
주요 스키마 패턴
1️⃣ Extended Reference Pattern
관계형 DB처럼 모든 것을 분리하면 매번 $lookup (JOIN느낌?) 해야 하므로 비효율적입니다. 따라서 자주 쓰는 필드는 함께 저장해 읽기 성능을 높입니다.
{
"postId": "abc",
"title": "몽고디비 패턴 정리",
"author": {
"userId": "u123",
"name": "철수"
}
}- 게시글 조회 시 name은 자주 보여주기 때문에 포함
- 이메일, 주소 등 자주 사용하지 않는 필드는 참조 (
$lookup사용)
2️⃣ Outlier Pattern
대다수가 작은 용량을 갖지만 소수의 문서가 너무 커서 성능에 문제가 발생할 때 사용하는 패턴입니다. 예외 (Outlier)를 분리해 저장하는 패턴입니다.
[Outlier 적용 ❌]
// 모든 리뷰를 한 문서에 저장한 경우
{
"productId": "P123",
"reviews": [
{"user": "철수", "comment": "좋아요"},
{"user": "영희", "comment": "별로예요"},
...
// 한 제품에 수천 개의 리뷰
]
}- 대부분 제품의 리뷰수는 소수
- 특정 제품이 유명세를 타서 리뷰수가 1만개 이상이 된다면? 특정 한 문서만 크기가 커짐
- Mongo DB는 단일 문서 크기가 16MB 제한이기 때문에 오류 발생 가능
- 조회/ 수정 시 rewrite cost 증가 : 타 문서의 성능에도 영향
[Outlier 적용 ⭕]
// 메인 리뷰 문서
{
"productId": "p123",
"reviews": [
{"comment": "좋아요!", "user": "철수"},
{"comment": "추천합니다", "user": "영희"}
]
}
// 리뷰가 수천 개인 경우 별도 컬렉션
{
"productId": "p123",
"overflowReviews": [
{"comment": "너무 많음", "user": "길동"}
]
}- 기본 문서는 빠르게 조회 가능해짐
- Outlier 문서가 존재하면 필요할 때만 추가 조회 (2단계 쿼리 필요)
이 패턴은 사용 시 분기 처리 및 N 단계의 쿼리가 필요할 수 있기 때문에 적용에 고려가 필요합니다.
3️⃣ Bucket Pattern
시간 기반 로그 데이터는 쌓이면 매우 많이지기 때문에 Bucket이라는 묶음 개념을 사용합니다. 이를 통해 인덱스 수를 줄일 수 있습니다.
{
"sensorId": "abc",
"bucketStart": "2024-01-01T00:00:00Z",
"readings": [
{"ts": "01:00", "value": 23},
{"ts": "01:10", "value": 25},
...
]
}- 로그를 하루 혹은 한 시간 등의 단위로 묶어 저장
- 읽을 때는
$unwind사용
안티 패턴
Mongo DB를 설계 없이 사용하면 발생할 수 있는 패턴입니다.
1️⃣ Unbounded Arrays
말 그대로 끝도 없이 배열이 늘어지는 경우입니다.
{
"userId": "123",
"likedPosts": ["a", "b", "c", ..., "z", "aa", "ab", "ac", ...]
}- 배열이 무제한으로 커지기 때문에 검색 성능 및 문서 크기 문제 발생 야기
- 일정 개수 이상이 되면 분리하거나
Bucket Pattern활용으로 해결 가능
2️⃣ Growing Document
이 또한 말 그대로 문서가 계속 커지는 경우입니다. 주로 임베딩 구조에서 나타나며 필요 시 설계를 다시한 후 데이터베이스를 수정해야합니다.
- 문서가 16MB 크기 제한을 넘음
- 수정 시 rewrite cost 증가
- 임베딩을 레퍼런싱으로 변경하여 별도 컬렉션으로 저장하여 해결 가능
3. MongoDB 인덱스 설계 전략
MongoDB를 사용하면서 체감했던 점은 스키마 설계만큼이나 인덱스 설계가 성능에 큰 영향을 준다는 것입니다.
앞에서 살펴본 것처럼 MongoDB는 워크로드 기반 설계가 핵심이며, 인덱스 역시 “어떤 쿼리가 가장 많이 실행되는가”를 기준으로 설계해야 합니다.
MongoDB 인덱스의 기본 개념
MongoDB의 인덱스는 RDBMS와 마찬가지로 조회 성능을 향상시키기 위한 자료구조이지만, 문서형 데이터베이스 특성에 맞는 인덱스들이 존재합니다.
- 단일 필드 인덱스
- 복합 인덱스 (Compound Index)
- Multikey Index (배열 필드 인덱싱)
- TTL Index (자동 만료 인덱스)
- Text Index (문자열 검색)
단일 필드 인덱스
하나의 필드에 대해 인덱스를 생성하는 가장 기본적인 형태입니다.
db.users.createIndex({ userId: 1 })- 특정 ID 기반 조회에 적합
- 단건 조회 성능이 매우 빠름
- 기본적으로
_id필드는 자동 인덱싱됨
복합 인덱스
MongoDB에서는 여러 조건을 함께 사용하는 쿼리가 매우 빈번하기 때문에, 복합 인덱스 설계가 중요합니다.
db.messages.createIndex({ roomId: 1, createdAt: -1 })이 인덱스는 다음과 같은 쿼리를 효율적으로 처리합니다.
db.messages
.find({ roomId: "room123" })
.sort({ createdAt: -1 })
.limit(50)- 특정 채팅방의 메시지 조회
- 최신 메시지부터 N개 조회
- 채팅, 로그, 피드 도메인에서 매우 자주 등장하는 패턴
인덱스 필드 순서의 중요성
복합 인덱스에서는 필드의 순서가 매우 중요합니다
{ roomId: 1, createdAt: -1 }MongoDB는 인덱스를 왼쪽(prefix)부터 순차적으로 사용합니다
따라서 아래와 같은 쿼리는 인덱스를 제대로 활용하지 못할 수 있습니다
db.messages.find({
createdAt: { $gte: ISODate("2024-01-01") }
})👉 인덱스는 반드시 실제 쿼리 패턴의 필터 → 정렬 순서를 기준으로 설계해야 합니다.
Multikey Index (배열 인덱스)
MongoDB는 배열 필드에 대해서도 자동으로 인덱스를 생성할 수 있습니다.
{
"userId": "123",
"tags": ["mongodb", "nosql", "backend"]
}
db.posts.createIndex({ tags: 1 })- 배열 요소 각각이 인덱스로 관리됨
$in,$all조건 검색에 유리- 태그 기반 검색, 관심사 필터링 등에 활용 가능
단, 배열의 크기가 계속 증가하는 경우 인덱스 크기 증가 및 성능 저하로 이어질 수 있으므로
앞에서 다룬 Unbounded Array 안티 패턴과 함께 고려해야 합니다.
TTL Index – 로그와 세션 데이터 관리
TTL(Time To Live) 인덱스는 특정 시간이 지나면 문서를 자동으로 삭제하는 인덱스입니다.
db.sessions.createIndex(
{ createdAt: 1 },
{ expireAfterSeconds: 60 * 60 * 24 }
)- 세션 데이터
- 임시 인증 정보
- 오래된 로그 데이터
TTL 인덱스를 활용하면 별도의 배치 작업 없이도 데이터 수명 주기가 자동으로 관리됩니다.
로그나 채팅 시스템처럼 데이터가 빠르게 쌓이는 구조에서 유용합니다.
Outro
채팅 기능을 구현하게 된다면 한번쯤 고려해보게 되는 몽고 DB에 대해 간략하게 소개해봤습니다. NoSQL을 다룬다면 반드시 알아야 하는 CAP 이론으로 다시 찾아뵙겠습니다.
