지난 한 주를 통해 자연어 텍스트를 쪼개 토큰으로 분류하고, 이 토큰들을 통해 커다란 단어 사전을 만드는 법에 대해 배웠다.
이제 우리는 자연어 텍스트를 입력으로 받으면 이를 숫자 배열로 바꿀 수 있게 되었다.
이번 한 주는 이렇게 쪼갠 단어들을 하나의 벡터로 바꿔주는 방법에 대해 배운다.
각각의 단어가 그저 하나의 숫자로 표현될 때는 그 의미를 분석할 수 없었지만 각각의 단어를 벡터로서 표현할 수 있게 된다면 비로소 그 의미를 분석하고, 자연어를 여러 방법으로 처리할 준비가 될 것이다 !
손코딩 많음 주의..ㅎ
Count-Based Vectorization
단어 사전에 의해 임의의 숫자로 매핑된 토큰들에 의미를 부여하는 가장 단순한 방법은 그 빈도수를 이용하는 것이다.
단어의 그 어떠한 의미도 참조하지 않는 그저 빈도수 자체 !
Count-Based Vectorization 에서는 빈도수가 곧 단어의 전부이며 단어의 중요도를 나타낸다.
그럼 이제 1) Text를 받아 2) 토큰화를 하고 3) 빈도수 값에 매핑하는 예제를 살펴보자.
CountVectorizer 객체 생성 및 학습
from sklearn.feature_extraction.text import CountVectorizer
from nltk import word_tokenizer
cv = CountVectorizer(
tokenizer = word_tokenizer,
stop_words = list('은는이가을를도,.'),
preprocessor = None,
token_pattern = None,
ngram_range = (1, 2)
)
cv.fit(<text>)
>>> CountVectorizer(ngram_range=2, token_pattern=None,
tokenizer=<function word_tokenizer at 0x000002DAEC594E00>)token_pattern은 tokenizer가 따로 주어지지 않았을 때 문서를 어떤 기준으로 토큰화할 것인지에 대한 패턴이다.
ngram_range는 빈도수만으로 토큰의 중요도를 판단하는데에 있어 조금이나마 맥락을 고려하도록 설정된 변수로, 앞 뒤 토큰까지 묶은 토큰의 빈도수를 측정하게 된다.
tokenizer는 문장을 받아 최초로 토큰으로 나누어 줄 callable 함수가 들어와야 한다. CountVectorizer는 문서(문장으로 이루어진 리스트) 를 받아 각각의 문장마다 토큰화를 진행하고 빈도수를 측정하므로 callable 함수를 필요로 하는 것이다.
이 callable 함수는 string 자료를 받아 token 으로 이루어진 리스트를 반환하게 만들면 되므로 아래처럼 사용할수도 있다.
from konlpy.tag import Okt
okt = Okt() # 객체이므로 callable X
def tokenizer(doc): # 함수로 새롭게 정의
return okt.morphs(doc) # return : [token1, token2, ...]
cv = CountVectorizer(
tokenizer=tokenizer
)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
cv = CountVectorizer(
tokenizer=Okt().morphs # 한 번에 정의
)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
from tokenizers import Tokenizer
from tokenizers.pre_tokenizers import Whitespace
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
subword_tok = Tokenizer(BPE(unk_token='[UNK]')) # Tokenizer 파이프라인 생성
subword_tok.pre_tokenizer = Whitespace # 기본 토큰화
trainer = BpeTrainer( # Trainer 객체 생성
vocab_size = 10_000,
min_frequency = 10,
special_tokens = ['[UNK]', '[PAD]']
)
subword_tok.train(<text_train>, trainer=trainer) # 학습
"""
result = subword_tok.encode(<text>)
>>> Encoder 객체 반환
result.tokens
>>> <text> 를 쪼갠 토큰 리스트 반환
"""
def tokenizer(doc):
result = subword_tok.encode(doc)
return result.tokens
cv = CountVectorizer(
tokenizer=tokenizer
)1, 2번째 코드에서는 서브워드를 나누기 이전에 해주는 토큰화도 공백 기준 토큰화보다는 형태소 기반 토큰화가 더 좋은 효율을 보이기에 KoNLPy의 Okt 모델을 사용하여 tokenizer를 구성하였다.
마지막 코드에서는 지난 주 복습도 할겸 Hugging Face의 Tokenizer 파이프라인을 이용해보았다ㅎㅎ;
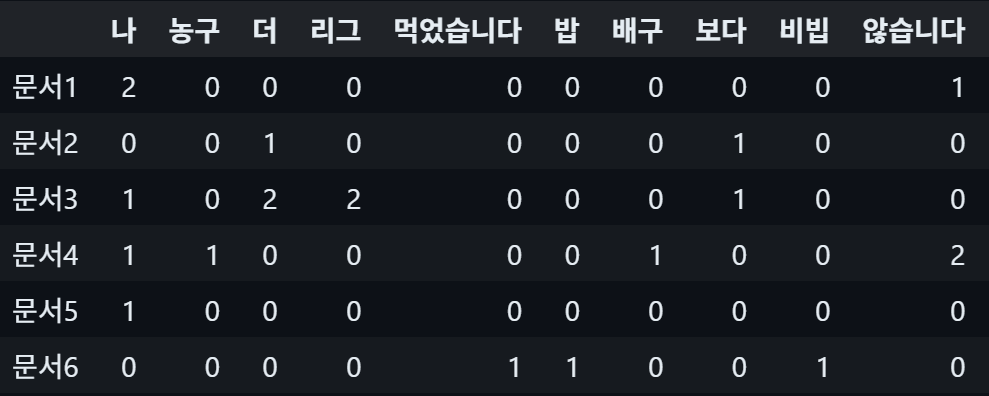
CountVectorizer 속성값 및 DTM 생성
여기까지 왔으면 이제 토큰을 빈도수로 매핑시켜주는 객체를 만들고, 실제로 이를 학습까지 시킨 것이다. 이렇게 학습된 객체는 빈도수에 따라 각 토큰을 나열한 새로운 단어 사전을 가지게 되고 이를 통해 새로운 문서에 대해 적용시킬 수 있게 된다.
cv.vocabulary_
>>> {'나': 5,'는': 9,'야구': 40,'를': 18,'좋아합니다': 56, ...}
cv.get_feature_names_out()
>>> array(['나', '는', '야구', '를', '좋아합니다', ...], dtype=object)
import numpy as np
result = cv.transform(<new_text>)
result
>>> <6x63 sparse matrix of type '<class 'numpy.int64'>'
with 106 stored elements in Compressed Sparse Row format>
import pandas as pd
DTM = pd.DataFrame(
result.toarray(),
columns = cv.get_feature_names_out(),
index = ['문서1', '문서2', ..., '문서6']
)
TF-IDF Vectorizer
그렇지만... 오로지 단어의 빈도수만을 가지고 그 중요도를 판단하고, 이를 통해 문서 전체를 대변하기에는 너무 빈약하지 않나...? 라는 생각에서 나온 것이 TF-IDF 방식이다.
Term Frequency - Inverse Document Frequency 의 약자로 빈도수에 더해 얼마나 적은 문서에서 단어가 등장하였느냐를 통해 그 가중치를 더하는 방식이다. 특정 단어가 여러 문서가 아닌 특정 문서에서만 등장하거나 특히나 적은 단어로 이루어진 문서에서 등장할 경우 해당 단어가 더욱 비중있고 대표되는 단어라고 판단하는 것이다.
from sklearn.feature_extraction.text import TfidfVectorizer를 통해 동일하게 사용할 수 있다 !!
Word Embedding Vectorization
여태까지 단어사전에 임의의 숫자로 매핑된 토큰들에 빈도수에 기반한 값을 할당해주었다. 하지만 각각의 단어가 오직 하나의 값으로 표현되기에는 단어에 함축된 의미나 문맥적인 의미가 너무 방대하다.
그렇게 나온 것이 Word Embedding, 단어를 하나의 값이 아닌 하나의 벡터에 매핑시키겠다는 것이다.
그럼 어떤 기준을 가지고? 모든 단어의 의미는 그 단어가 존재하는 문맥속에서 찾을 수 있다 라는 분산 표현에 기반하여 단어의 벡터화를 진행한다.
그러기 위해서는 우선 단어 사전에 존재하는 모든 단어(토큰)에 대해 원-핫 인코딩을 진행해주어야 한다.
One-Hot-Encoding 을 통해 단어들을 1차적으로 벡터화 할 수 있으며, 각 단어들의 수직성을 유지할 수 있다.
그럼 기존에 학습해놓은 단어가 총 1만 개 존재한다고 치자.
원-핫 인코딩을 진행하면 각 단어들은 1만 개의 차원을 가진 벡터로 표현된다. 10만 개면 10만 차원... 얼마나 비효율적인가 ! 희소 행렬이긴 하지만
원-핫 인코딩된 벡터와 다르게 우리가 만들 Embedding Vector 는 각 차원별로 0과 1말고도 다양한 값을 지닐 수 있기에 이 단어들은 100 개의 차원을 지닌 벡터로서 충분히 표현될 수 있을 것이다.
예를 들어 [ 밤 , 낮 , 어둠 , 빛 , 형광등 ] 이라는 5개의 단어가 있다고 해보자.
초기 단어 사전에 등록될 때 이들은 다음과 같이 등록되었을 것이다.
{'밤':0, '낮':1, '어둠':2, '빛':3, '형광등':4} - - - - - - - - - - - < 단어 사전 >이를 원-핫 인코딩해보자.
{
'밤' : [1, 0, 0, 0, 0],
'낮' : [0, 1, 0, 0, 0],
'어둠' : [0, 0, 1, 0, 0],
'빛' : [0, 0, 0, 1, 0],
'형광등' : [0, 0, 0, 0, 1]
}이들을 밝고 어두움, 시간이냐 빛의 세기냐, 사물이냐 등의 기준에 따라 3차원의 벡터로 표현해보자.
{
'밤' : [0, 0, 0], # 어두움 / 시간 / 사물 X
'낮' : [1, 0, 0], # 밝음 / 시간 / 사물 X
'어둠' : [0, 1, 0], # 어두움 / 빛의 세기 / 사물 X
'빛' : [1, 1, 0], # 밝음 / 빛의 세기 / 사물 X
'형광등' : [1, .5, 1] # 밝음 / 빛의 세기 / 사물 O
}물론 우리가 할 딥러닝 모델은 Black-Box 모델로 벡터의 각 차원이 명확한 의미를 가지지는 않겠지만 이런 식으로 더 낮은 차원으로 매핑시킬 수 있다는 것이다.
Word Embedding의 원리
초기에 모든 단어를 원-핫 인코딩하여 각 단어의 수직성을 보장시켜준다. 이를 통해 모든 단어로 하여금 별개의 의미를 지닐 수 있도록 해주는 것이다.
이후 동일하게 모든 단어에 대해 정해진 차원 수, embedding_dim 값에 맞는 랜덤한 벡터를 부여해준다. 랜덤한 가중치를 부여해 초기값을 설정해주는 것이다.
이후 입력으로 주어지는 문서들을 읽으며 비슷한 문맥에서 나오는 단어들끼리 비슷한 벡터값을 가지도록 하게끔 그 가중치를 천천히 학습시켜주는 것이다.
CBOW (Continuous Bag of Words) 방식
이 방식은 주변에 나오는 단어들을 통해 중심 단어를 추측하도록 만든 방식으로 연속된 단어들을 순서없이 한움큼 집어 중심 단어를 추측한다고 이런 이름이 붙었다.
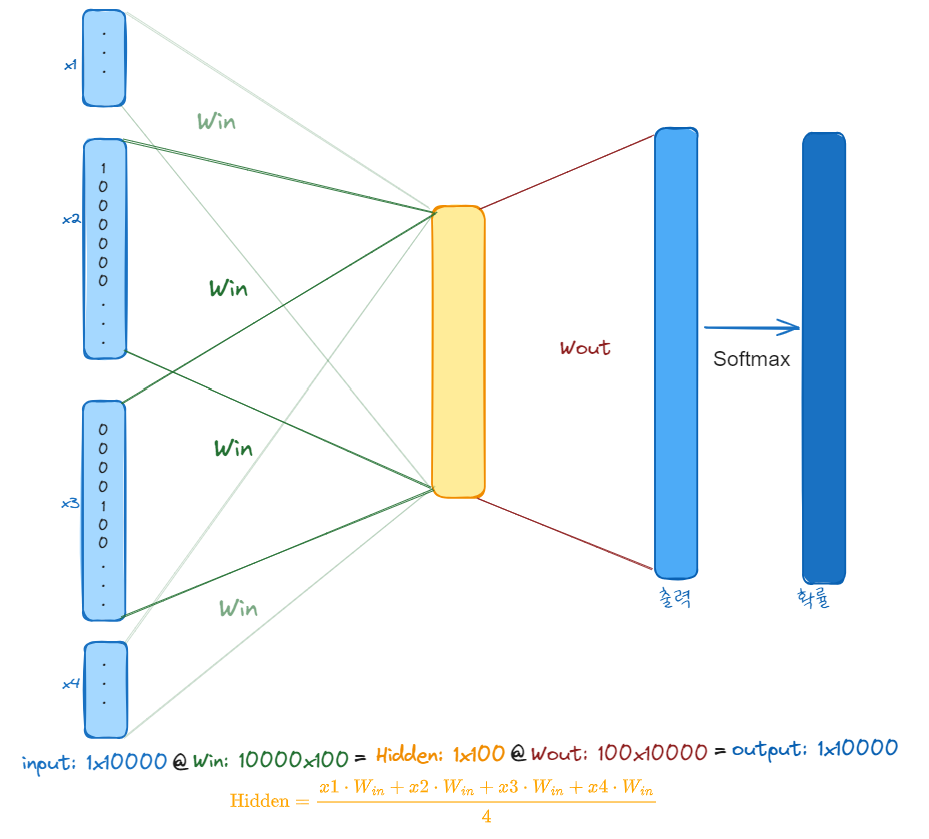
각 단어들의 원-핫 인코딩된 벡터에 가중치를 곱해 embedding dimension, 여기서는 100개의 차원을 가진 벡터를 뽑아내는 그림이다. 여기서는 4개의 단어를 토대로 중심단어의 원-핫 인코딩된 벡터를 추출할 수 있도록 모델이 가중치를 학습하는 중이다.
이렇게 학습된 Weight_in 을 각 원-핫 인코딩된 벡터에 곱해주면 비로소 각 단어의 Embedding Vector를 구해낼 수 있을 것이다.
Skip-gram 방식
주변 단어들의 Embedding Vector 의 평균으로 중심 단어의 Embedding Vector 를 추측하는 CBOW 방식과 다르게, Skip-gram 방식은 중심 단어의 Vector 를 가지고 주변 단어의 Vector 를 추측해낸다.
CBOW의 역과정으로 학습을 진행하는 대신, 주변 단어들의 평균을 예측해내는 것이 아니라 각각의 주변 단어를 따로 예측하도록 학습하는 알고리즘에 의해 더 어려운 문제이고 더 많은 데이터셋을 필요로 하지만 더 좋은 분산표현을 보인다.
Word2Vec 객체 생성 및 학습
앞서 토큰화는 Hugging Face, Count-Based Vectorization 의 경우 sklearn 패키지를 이용하였지만 Word2Vec은 여기서 지원해주지 않기에..! Gensim 패키지 를 이용해보았다.
Word2Vec은 토큰화된 단어들을 벡터화시키는 작업이기에 입력으로 토큰 리스트를 받아 토큰-Embedding Vector 꼴의 Keyed Vector 자료형을 뱉어낸다.
# 특수문자(구두점 포함) 제거
sentences = ["깊은 밤, 작은 마을은 어둠 속에 잠겼다.",
"한 소년이 깜빡이는 형광등 아래에서 책을 읽으며 꿈을 키웠다.",
"그리고 어느 낮, 그는 세상을 밝히는 새로운 빛을 만들어 냈다."]
import re
from konlpy.tag import Okt
okt = Okt()
tokens = [okt.morphs(re.sub(r'[^\w\s]', '', sentence)) for sentence in sentences]
>>> [['깊은', '밤', '작은', '마을', '은', '어둠', '속', '에', '잠겼다'], ...
tokens_set = set(token for sentence in tokens for token in sentence)
len(tokens_set)
>>> 32 # 고유 토큰 개수
# Word2Vec 객체 생성 + 학습
# %pip install gensim
from gensim.models import Word2Vec
word2vec = Word2Vec(
sentences=tokens,
vector_size=10,
window=3,
min_count=1,
epochs=10
)
word2vec
>>> <gensim.models.word2vec.Word2Vec at 0x1cd35b71f70>konlpy 의 Okt 모델을 이용하여 토큰화를 진행, word2vec 모델을 만들어주었다. 특이하게도 생성시에 sentences 와 epochs 파라미터를 이용해 생성과 동시에 학습을 시켜줄 수 있었다.
주요 파라미터로는 그래서 단어를 몇 차원으로 표현할건데? 의 vector_size와 문맥을 얼마나 고려할건데? 의 window를 설정해주었다.
조금 의외였던 점은 파라미터로 전체 단어 사전의 개수, vocab_size 와 같은 변수를 따로 지정해주지 않는다는 점이었는데 Word2Vec 자체가 전체 단어 사전에 해당하는 임베딩 벡터를 만드는 과정이므로 입력으로 받은 sentences 에서 자체적으로 전체 단어 사전 개수를 구할 수 있다는게 그 이유였다.
set 자료형을 이용해 고유 토큰 수를 살펴본 결과 32개, vector_size 를 10으로 지정해주었으니 위 모델은 32*10 크기의 가중치 벡터를 학습시켰을 것이다.
KeyedVector 클래스
그 가중치 벡터만을 따로 뽑아 이런 짓 저런 짓 해보자...!
word2vec.wv # KeyedVector
>>> <gensim.models.keyedvectors.KeyedVectors at 0x1cd64b1cc80>
word2vec.wv.vectors # 가중치 벡터
word2vec.wv.vectors.shape
>>> (32, 10)
word2vec.wv.key_to_index # 단어 사전
>>> {'을': 0, '냈다': 1, '아래': 2, '밤': 3, '작은': 4, ..., }
# "밤" 의 Embedding Vector 구해보기
from numpy import dot
word2vec.wv['밤']
>>> array([-0.07511582, -0.00930042, 0.09538119, -0.07319167, -0.02333769,
-0.01937741, 0.08077437, -0.05930896, 0.00045162, -0.04753734], dtype=float32))
word = [0 for _ in range(32)]
word[3] = 1
dot(word, word2vec.wv.vectors)
>>> array([-0.07511582, -0.00930042, 0.09538119, -0.07319167, -0.02333769,
-0.01937741, 0.08077437, -0.05930896, 0.00045162, -0.04753734], dtype=float32))KeyedVector 를 통해 찾은 "밤" 의 Embedding Vector 와 직접 가중치를 곱해 구한 "밤"의 Vector 와 동일함을 확인할 수 있었다 !
그럼.... 토큰화를 통해 단어사전을 만들 때 nltk의 Text, FreqDist 객체 등을 이용하여 여러 분석을 했었는데 여기서는?
word2vec.wv.most_similar("밤", topn=5)
>>> [('책', 0.7671473026275635),
('새로운', 0.535477876663208),
('읽으며', 0.39180904626846313),
('키웠다', 0.31842607259750366),
('어둠', 0.29426178336143494)]
word2vec.wv.similarity("밤", "어둠")
>>> 0.2942618단어의 등장 빈도수를 기반으로 했던 이전 분석들과 다르게 Embedding Vector 를 다루기에 그 단어들간의 유사도를 판단하는 메소드를 제공해준다. 학습 데이터가 작아 "밤" 과 "어둠" 이 크게 유사하게 나오지 않았지만...ㅠ
참고로 벡터간의 유사도이기에 그 계산은 코사인 유사도 를 따른다 !
