자연어 처리에 대해 배우기 시작하는 첫 주 !
머신러닝과 딥러닝을 배울때와 마찬가지로 해당하는 개념을 먼저 배우고 그 개념을 짜놓은 라이브러리를 숙달하는 방식으로 수업이 진행되었다.
정형화된 데이터를 사용하던 머신러닝에서 비정형 값을 데이터로 사용하던 딥러닝에 이어 이제는 자연어를 데이터로 받는다.
당연하게도 컴퓨터는 자연어를 읽고 해석하지 못하기에 이를 분석하기 용이한 형태로 바꿔주는 Cleansing 작업과 Normalizing 작업에 대해 한 주간 배울 수 있었다.
정규표현식
공백 문자와 단어 경계
정규표현식에 대해 배우며 가장 오묘하다고 생각되는 개념 중 하나였다. 공백 문자(\t, \n, 공백)을 표현하는 \s와 공백 문자에 더해 구두점(., , 등)을 기준으로 단어 경계를 나누는 \b는 대체 뭐가 다른가?
바로 \s는 공백 문자 자체를 포함하는데 반해 \b는 아무런 문자를 포함하지 않고 그 단어를 나누는 기준이 될 뿐이었다.
import re
pat = re.compile(r'\s[가-힣]+\s')
pat2 = re.compile(r'\b[가-힣]+\b')
text = '안녕하세요 저는 이름이 땡땡땡 입니다.'
print(pat.findall(text))
>>> [' 저는 ', ' 땡땡땡 ']
print(pat2.findall(text))
>>> ['안녕하세요', '저는', '이름이', '땡땡땡', '입니다']위처럼 \s를 통해 단어를 구분하고자 저렇게 패턴을 설정하면 "공백" 자체를 포함하여 단어쌍을 찾기에 공백이 포함된 "(공백)저는(공백)"과 같은 단어쌍이 나오게 된다.
이에 더해 " 저는 "에서 이미 공백을 사용하였기에 뒤에 오는 "이름이" 는 앞 공백이 없어 추출되지 않는 모습이다.
반면 단어의 경계를 포함하도록 패턴을 설정하면 깔끔하게 나온다는 것을 알 수 있다 !
Match Class....?
배우는 내용에서 새로운 클래스가 나오면 궁금해 참지 못하겠다....
위 코드에서 pat 객체는 re.Pattern 클래스를 가지게 된다. 여기에 .compile()을 통해 패턴을 객체별로 새겨넣는 것이다.
이러한 re.Pattern 객체가 .match(), .search() 메소드를 통해 주어진 텍스트에서 추출해 내는 것이 re.Match 클래스를 가진 객체이다.
해당 클래스는 내부 메소드로 찾은 패턴 자체와 그 시작과 끝 인덱스 등의 정보를 가지고 있다.
NLTK 와 KoNLPy
자연어를 본격적으로 전처리하기 위해 두 가지의 라이브러리를 배우게 되었다.
한국어를 지원하지 않는.... NLTK와 한국어를 위한 KoNLPy 이다.
Cleansing
자연어의 정제로는 알파벳 소문자화, 불용어 사전 및 구두점 제거 등의 방법을 사용해 보았다.
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
from string import punctuation
text = """Beautiful is better than ugly.
Explicit is better than implicit."""
stop_words = stopwords.words('english')
stop_words = stop_words + list(punctuation)
text_lowered = text.lower() # 소문자화
stemmer = PorterStemmer() # 어근 추출 객체 생성
tokens = stemmer.stem(text_lowered) # 토큰화
tokens_cleaned = [token for token in tokens if token not in stop_words]NLTK 에서 제공하는 영어의 불용어 리스트에 구두점을 추가해 이들을 제외하고 토큰화를 진행하였다.
Normalizing
이 정규화 과정은 다르게 생긴 단어임에도 같은 의미를 뜻하는 단어들을 동일하게 보기 위함으로 크게 1) 어간 추출 방법과 2) 원형 복원 방법이 존재한다.
영어의 be 동사와 같은 단어는 변형이 크게 일어나는 경향성이 존재하므로 대체로 원형 복원 방법이 더 우수한 성능을 보이지만 단어 하나하나마다 품사를 태깅해주어야 한다는 소요가 존재한다.
from nltk.stem import PorterStemmer
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
text = ['happy', 'happier', 'happiest']
# 어간 추출
stemmer = PorterStemmer()
result = [stemmer.stem(word) for word in text]
print(result)
>>> ['happi', 'happier', 'happiest']
# 원형 복원
lemmatizer = WordNetLemmatizer()
result = [lemmatizer.lemmatize(word, pos=wordnet.ADJ) for word in text]
print(result)
>>> ['happy', 'happy', 'happy']어간 추출의 경우 비교적 많은 변형이 일어나는 비교급을 서로 다른 의미로 분류하는 모습이다.
Text, FreqDist, Wordcloud 객체 ~
이렇게 나누어진 토큰을 여러 방면으로 분석해보는 객체들을 소개해보자. Text 객체는 토큰들의 문맥을 분석하는 클래스이고 FreqDist 객체는 토큰들의 빈도수를 분석해주는 클래스이다. WordCloud는 이렇게 나온 빈도수 분석 결과를 시각화해주는 클래스.
from nltk import Text, FreqDist
from wordcloud import Wordcloud
text_anal = Text(
tokens_cleaned,
name = "토큰 문맥 분석"
)
print(text_anal.count('is')) # 특정 단어 빈도수
>>> 23
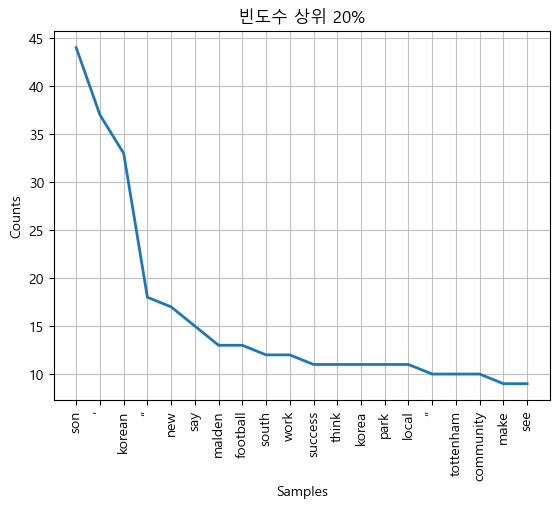
text_anal.plot(20); # 상위 출현 단어 plotting
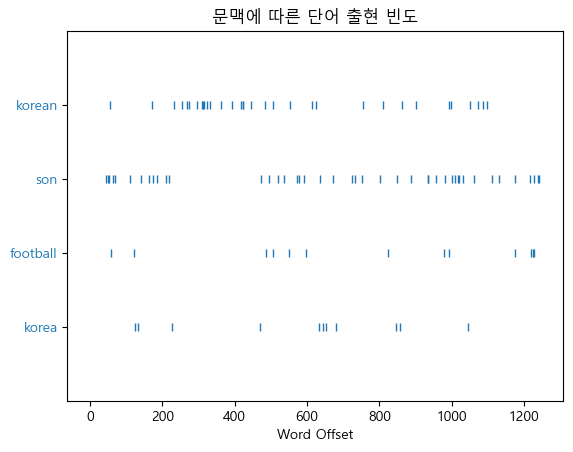
text_anal.dispersion_plot( # 단어 분포도 plotting
['son', 'is', 'better']
)
text_anal2 = FreqDist(tokens_cleaned)
print(text_anal2.B(), text_anal2.N())
>>> 고유 토큰 수 | 전체 토큰 수
print(text_anal2.get(word), text_anal2.freq(word))
>>> word의 빈도 횟수 | word의 출현율
print(text_anal2.most_common(n))
>>> 상위 빈도수 n개이렇게 토큰을 분석하는 것만으로도 다양한 문맥적인, 빈도수를 고려한 분석을 진행할 수 있다는 점은 자연어 처리를 배우는데 있어 생동감을 더해주었다!
서브워드 토큰화
하지만 위처럼 형태소를 기반으로 하는 토큰화에는 큰 한계점이 있었다.
바로 단어안에 존재하는 여러 의미 단위들을 분석하지 못한다는 점 !
예를 들어 영어의 easier과 happier 에는 동일한 문법이 적용되어 ier이라는 비교급 문법 단위가 들어갔지만 형태소 기반 토큰화는 이를 제외하고 원형만을 분석하게 된다.
그래서 나온 것이 Subword 토큰화.
서브워드 토큰화의 종류
수업시간에는 Hugging Face에서 만든 tokenizers 라이브러리를 이용하였다. 여기서 사용할 수 있는 서브워드 토큰화 종류는 1) BPE 방식 2) WordPiece 방식 3) Unigram 방식이 존재한다.
애초에 모든 글자를 나누어놓고 가장 자주 결합되는 글자쌍을 묶어나가는 것이 BPE 방식이라면, 그저 자주 결합되기만 하는 것이 아니라 등장 횟수 대비 자주 결합되는 글자쌍을 묶어나가는 방식이 WordPiece 방식이다. BPE 방식에 비해 조금 더 의미론적인 서브워드를 추출해 낼 수 있다는 것이 장점.
["easier", "happier"] 토큰들을 ["e", "a", "s", "i", "r", "h", "p"] 로 먼저 쪼갠 뒤 가장 많이 등장하는 쌍인 "ie", "er" 을 추가, 이후 "ie"+"r" = "ier"을 다시 추가하는 방식
반면 위 두 가지의 방식은 모든 글자를 나누어놓고 하나 하나 붙여나가기에 의미없는 서브워드들이 단어 사전에 등록될 수 있다.
이 단점을 보완한 것이 Unigram 방식. 기본적으로 토큰화된 단어들을 여러가지 방법으로 쪼개어보고 그 중 가장 잘 쪼갠 서브워드들을 단어 사전에 등록한다.
"hug" 단어를 ["h", "u", "g", "hu", "ug", "hug"] 로 쪼갠 뒤 ["h", "u", "g"] 혹은 ["hu", "g"] 등의 조합을 비교해 최적의 조합을 선택한다.
예제
손으로 짜보는 코딩
from tokenizers import Tokenizer
from tokenizers.pre_tokenizer import Whitespace
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
tokenizer = Tokenizer(
model = BPE(unk_token='[UNK]')
)
tokenizer.pre_tokenizer = Whitespace()
trainer = BpeTrainer(
vocab_size = 10_000,
min_frequency = 10,
special_tokens = ['[UNK]', '[PAD]', '[SEP]']
)
tokenizer.train(<text>, trainer=trainer)Tokenizer 는 전체 과정을 아우르는 pipeline의 역할을 하며 기본적으로 서브워드를 나눌 알고리즘, model 변수를 필수적으로 받는다.
BPE 모델은 후에 입력받는 text를 나눌 직접 토큰화할 모델로 후에 단어 사전에 등록되지 않은 토큰을 unk_token 변수를 통해 '[UNK]' 로 바꾸기로 하였다.
위 pipeline은 생성과정에서 pre_tokenizer을 등록하는 과정이 없으므로 후에 속성으로 추가해주어야 한다.
BpeTrainer를 통해 모델을 학습시킬 때의 조건을 정해주는데 미리 special_tokens 값을 지정해주어 단어 사전에 위 토큰들을 넣기로 하였다.
처음에 이 부분에서 든 의문은 왜 '[UNK]' 토큰을 두 번이나 적용시켜주는거지? 라는 의문이었다.
# tokenizer 부분만을 바꿀 경우
tokenizer = Tokenizer(
model = BPE(unk_token='?')
)
~
tokenizer.encode('뷃') # 단어 사전에 없는 단어를 Encoding 할 시
>>> ['?'] 라는 토큰으로 변하게 된다.위 경우 '뷃' 이라는 모르는 단어는 실제 '?' 와 같은 의미를 가지는 토큰으로 해석된다.
# trainer 부분만을 바꿀 경우
trainer = BpeTrainer(
vocab_size = 10_000,
min_frequency = 10,
special_tokens = ['뷃', '[PAD]', '[SEP]']
)
tokenizer.encode('뷃')
>>> ['[UNK]'] 라는 토큰으로 변하게 된다.위 경우 모르는 단어가
'[UNK]'토큰으로 변하기는 했지만 이special_token이 단어 사전에 등록되어 있지 않으므로 오류가 발생하게 된다.
Exception: Unk token[5]not found in the vocabulary
그래서?
이런저런 라이브러리들을 짧은 시간내에 배우는 것이 쉽지는 않은 것 같다.
그렇다고 ~~하는 라이브러리가 있다~ 정도로 끝내기에는 후에 다시 사용하고자 할 때 와닿지 않을 것 같다고 해야하나...?
직접 손으로 짜보는 코딩을 전부 하고 싶지만 시간적 여유가 없던 것이 가장 큰 아쉬움이다.
이제 진짜 LLM 시작이 코앞이다.... 여름아 조금만 늦게 오길 ㅜ
